하이퍼파라미터 튜닝..... 가물가물하게 기억이 난다
대충 모델 돌릴 때 왜인지는 모르겠지만 어떤 값을 집어넣으면 정확도가 올라갔던 알 수 없는 현상이 생겼는데
사실 그 모델이라는게 뭔지도 잘 모르겠고 그냥 전반적으로 아는 게 없어서 일을 좀 키워봤다
과제 마감이 today 오후 2시라는 게 함정
달려 ~~
*그래놓고 과제 에러랑 씨름하다가 넉다운..... 다음에 할래
https://www.youtube.com/watch?v=eVxGhCRN-xA
이걸 참고했다
근데 API라는게 도대체 뭐인가?
라이브러리에 접근하기 위한 규칙들을 정의한 것을 API라고 하는데 Application Program Interface 즉, 프로그래머가 라이브러리가 제공하는 여러 함수를 이용하여 프로그램을 작성할 때 해당 함수의 내부 구조는 알 필요없이 단순히 API에 정의된 입력 값을 주고 결과 값을 사용할 수 있게 해줍니다.
[네이버 지식백과] API [Application Program Interface] (소프트웨어 어휘다지기 - 중등)
우리는 식당에 가면 메뉴판을 보고 음식을 골라 직원에게 주문합니다.
직원은 주문받은 메뉴를 주방에 전달하죠.
이때 주방을 라이브러리, 메뉴판을 API, 직원은 이를 연결해 주는 역할을 한다고 볼 수 있죠.
우리가 모든 음식을 만들어 먹을 수는 없지만, 감사하게도 우리를 대신해 맛있는 요리는 만드는 전문 요리사가 있습니다. 전문요리사에게 주방을 맡기고 우리는 먹고 싶은 음식을 메뉴판에서 골라 주문한다면 음식을 만드는 복잡한 절차를 거치지 않고도 맛있는 음식을 먹을 수 있답니다.
세상에는 많은 식당과 메뉴가 있듯 우리에게도 많은 라이브러리와 API가 존재합니다.
Open API는 특정 서비스를 제공하는 서비스 업체가 자신들의 서비스에 접근할 수 있도록 그 방법을 외부에 공개한 것으로 해당 서비스로 접근하기 위한 규칙을 정의한 것이라 할 수 있습니다.
예를 들어, 페이스 북에서 로그인 API를 공개했기 때문에 다른 웹 사이트에서 “페이스 북 로그인” 기능을 사용할 수 있고 그 덕분에 우리는 매번 회원가입을 하지 않아도 됩니다.
이처럼 기존의 API를 이용해 새로운 프로그램을 만드는 것을 매쉬업(mashup)이라고 하는데 가장 대표적인 사례가 구글의 하우징 맵스 서비스입니다. 이 서비스는 구글지도와 부동산 매물 정보가 결합되어 만들어졌습니다.
국내에도 다양한 Open API 들이 제공되고 있습니다.
[네이버 지식백과] API [Application Program Interface] (소프트웨어 어휘다지기 - 중등)
중등 백과사전의 글을 빌려 왔다.. 이것이 요즘 중딩 수준!?
https://terms.naver.com/entry.naver?docId=4383195&cid=59941&categoryId=59941
링크는 여깄다...
뭐 와닿진 않지만 식당에서 메뉴를 골라 주문하는 우리네 모습이 바로 API를 이용하는 그것이 아닐까 싶다..
그러어언데..
도대체 feature가 무엇인가???? target은 알겠는데...
라는 생각이 들어서 검색해보니 이런 게 있더라
https://www.youtube.com/watch?v=2VPFth2UqoI
근데 강의가 좋은 것 같아서 자료를 다운받으려고 하니 회원가입을 하래서 정말 귀찮았으나 실습데이터까지 제공돼서 좋은 듯..?
https://kbig.kr/portal/kbig/datacube/onl_edu_class/python?bltnNo=11583395295645
여기서 다운 가능
어쨌든 이해한 결과
X: 2차원 배열 사용 ->이 2차원 배열을 특징 행렬이라고 함
(만약 자료가 1차원이면, 2차원으로 만들어 줘서 사용)
y: 1차원 배열 사용(주로 numpy, Series)
특징행렬에서 한 행을 표본이라고 하는데,
이 표본 수와 각 표본들에 대응하는 y의 수가 같다(당연하겠지?)
앞으로 다룰 변수는 X와 y가 되시겠다.
이제 다시 보던 강의를 보자(이수안씨의 강의)
https://colab.research.google.com/drive/10yp9-8ZtDjfVuh0H1lU5N9nA1y60eLzj
여길 들어가면 강의 내용이 정리되어 있음
그러면 데이터에서 종속변수를 분리하고 특징행렬을 만드는 것이 먼저인가
아니면 표본 데이터 세트 형성이 먼저인가??
->라는건 의미가 없었다~~ 어차피 표본에는 타겟 데이터가 따로 있다.
이제 중요! 학습용 데이터와 test용 데이터를 분리해야 함
분리 후 어떤 모델에 넣을 것인가가 매우매우 중요해 보임
https://machinelearningmastery.com/hyperparameter-optimization-with-random-search-and-grid-search/
hyper opt 내용은 아래를 참고했다
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html?highlight=logistic%20regression#sklearn.linear_model.LogisticRegression
https://teddylee777.github.io/thoughts/hyper-opt
https://github.com/hyperopt/hyperopt/wiki/FMin
https://www.programcreek.com/python/example/98791/hyperopt.fmin
https://stackoverflow.com/questions/53844629/ap-uniform-sampler-missing-1-required-positional-argument-high-in-ray-tune
http://hyperopt.github.io/hyperopt/getting-started/minimizing_functions/#the-trials-object
https://towardsdatascience.com/optimise-your-hyperparameter-tuning-with-hyperopt-861573239eb5
뭘 이렇게 많이 봤냐 하면
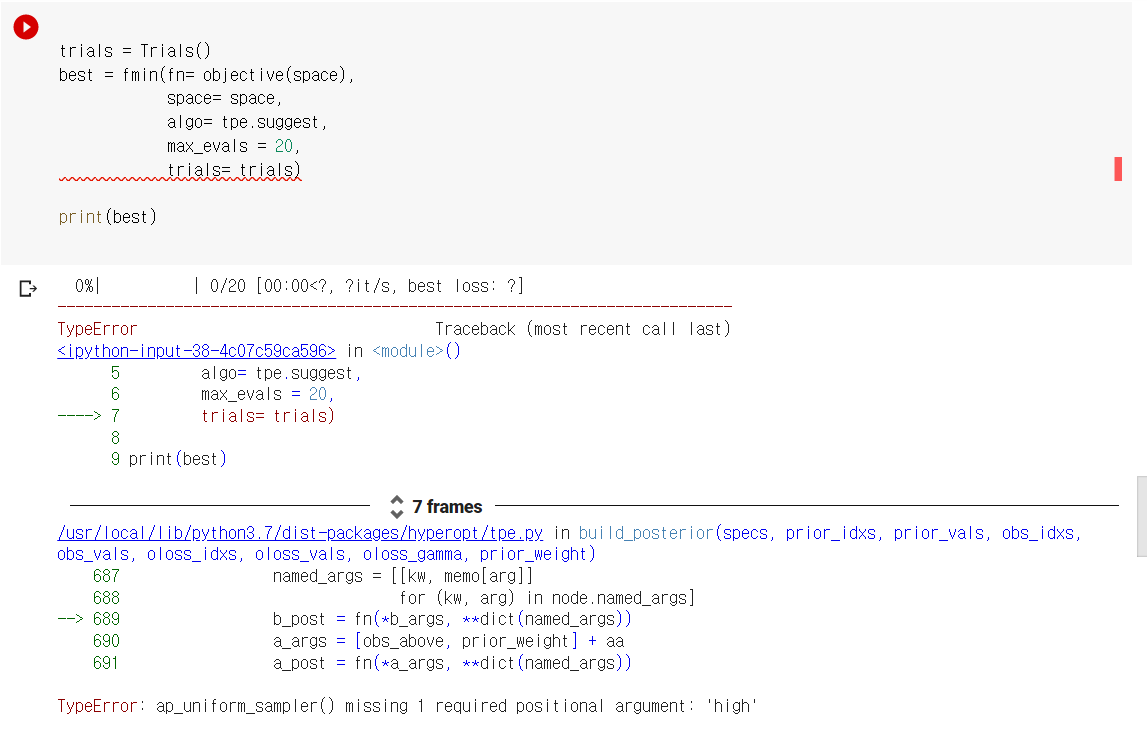
이것 때문이다 ㅎㅎㅎㅎ;;;;
덕분에.... 다양한 방법이 있다는 건 알게 됐지만
내가 머신러닝을 너무 모르는 것 같아서
조금씩이라도 공부해야겠다는 생각이 들었다 ㅠㅠ
