GCP에서 polyglot-ko 12.8B를 LoRa 로 fine-tune하기
환경
- server : GCP (google cloud platform)
- GPU : L4 (VRAM : 24GB)
- backbone mode : https://huggingface.co/EleutherAI/polyglot-ko-12.8b
- python 3.10.12
학습환경 구성
할당량 수정하기
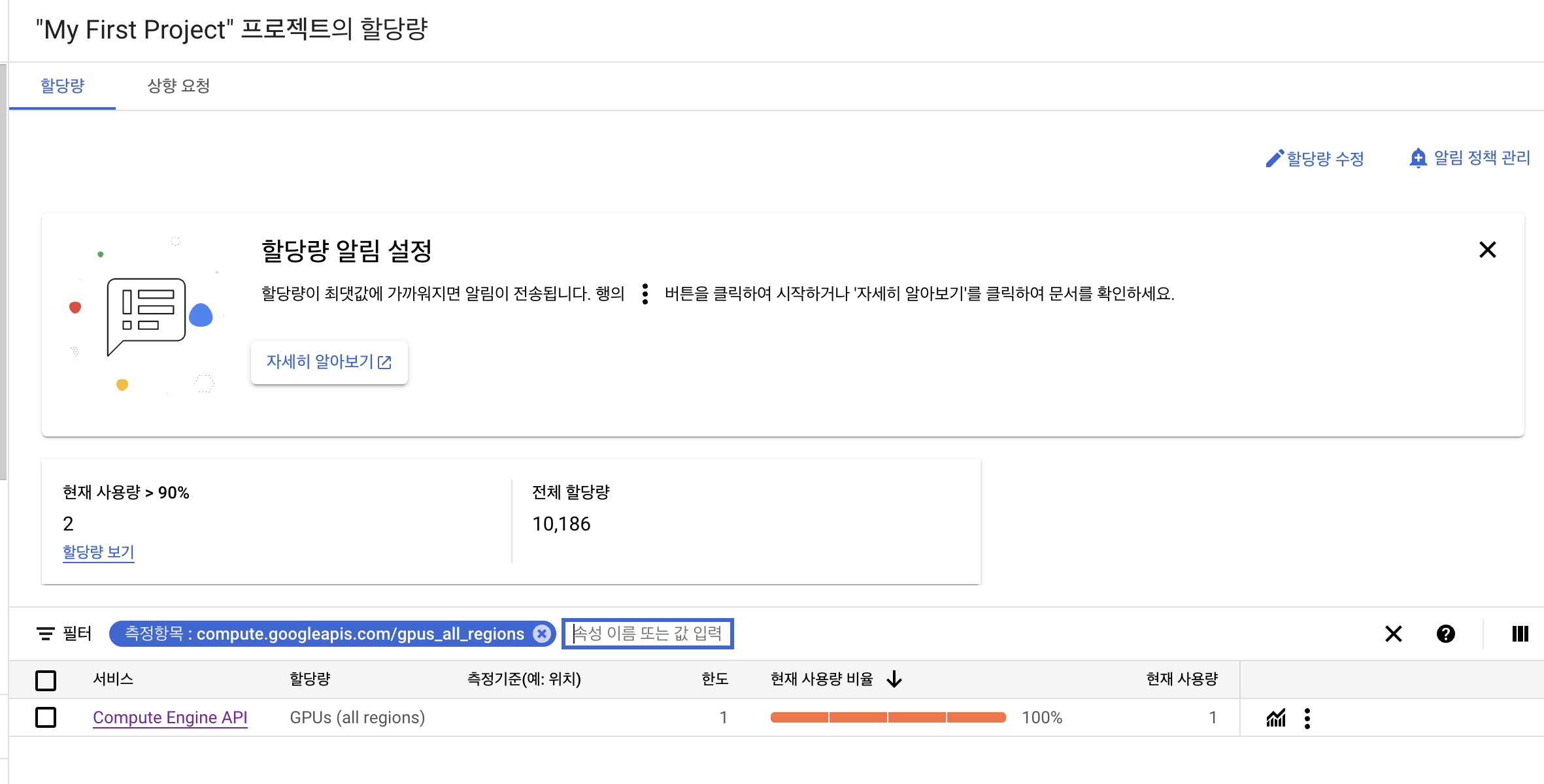
초기에 l4 gpus_all_regions의 할당값이 0으로 되어있기 때문에 할당량 수정에서 0->1 로 할당량 증가 요청을 해줍니다.
(아마 1개는 바로 할당해주는걸로 알고있습니다.)
인스턴스 만들기
comput engine -> VM instance -> instance만들기를 눌러줍니다.
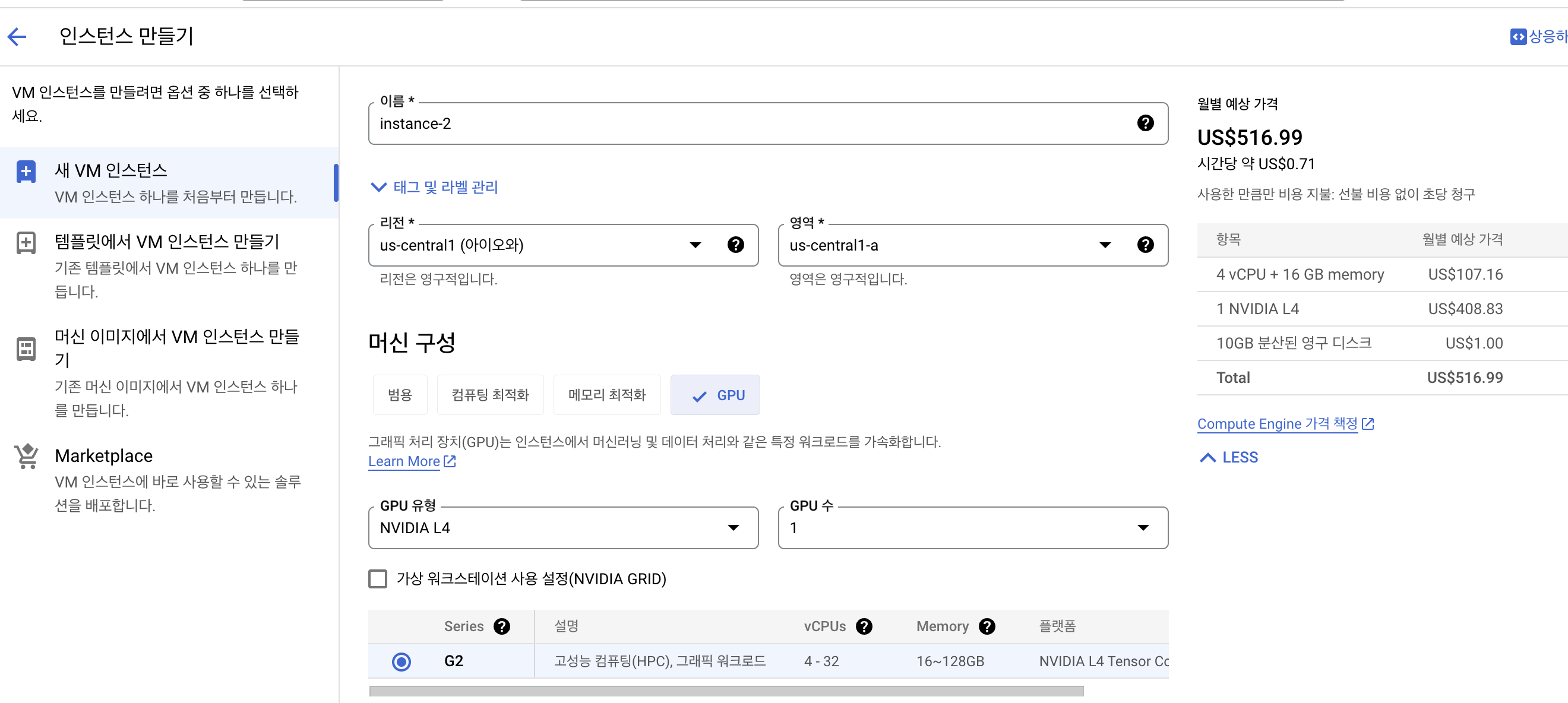
머신구성 -> GPU
NVIDIA l4 GPU를 사용할거기 떄문에 머신유형 NVIDIA l4를 눌러줍니다.
region은 가능한 곳에서 해주면됩니다(https://cloud.google.com/compute/docs/gpus/gpu-regions-zones)
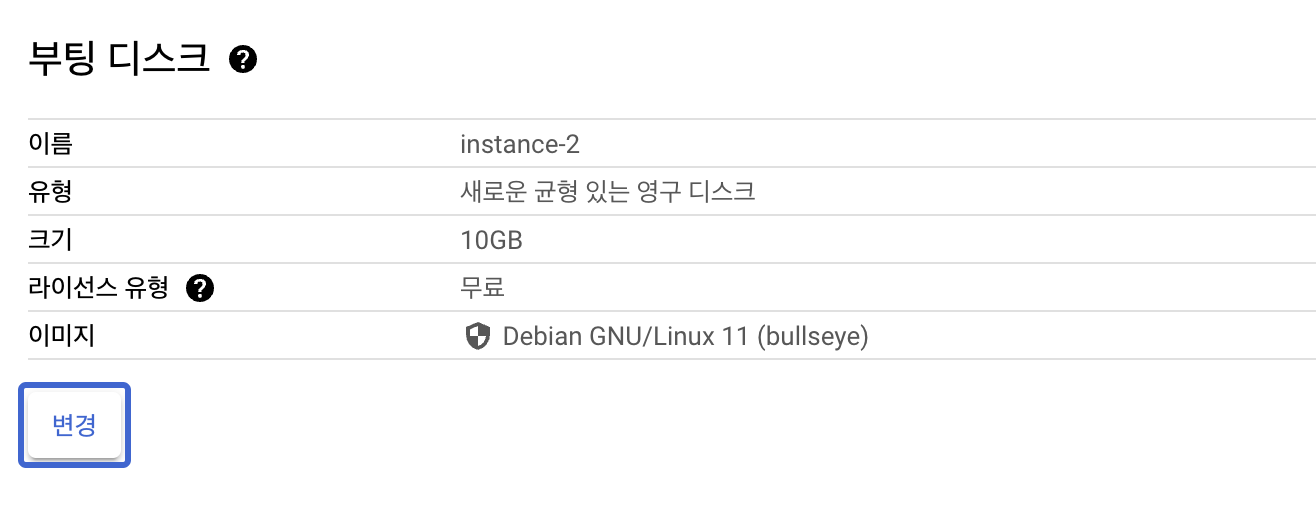
부팅 디스크에서 변경 버튼을 눌러줍니다.
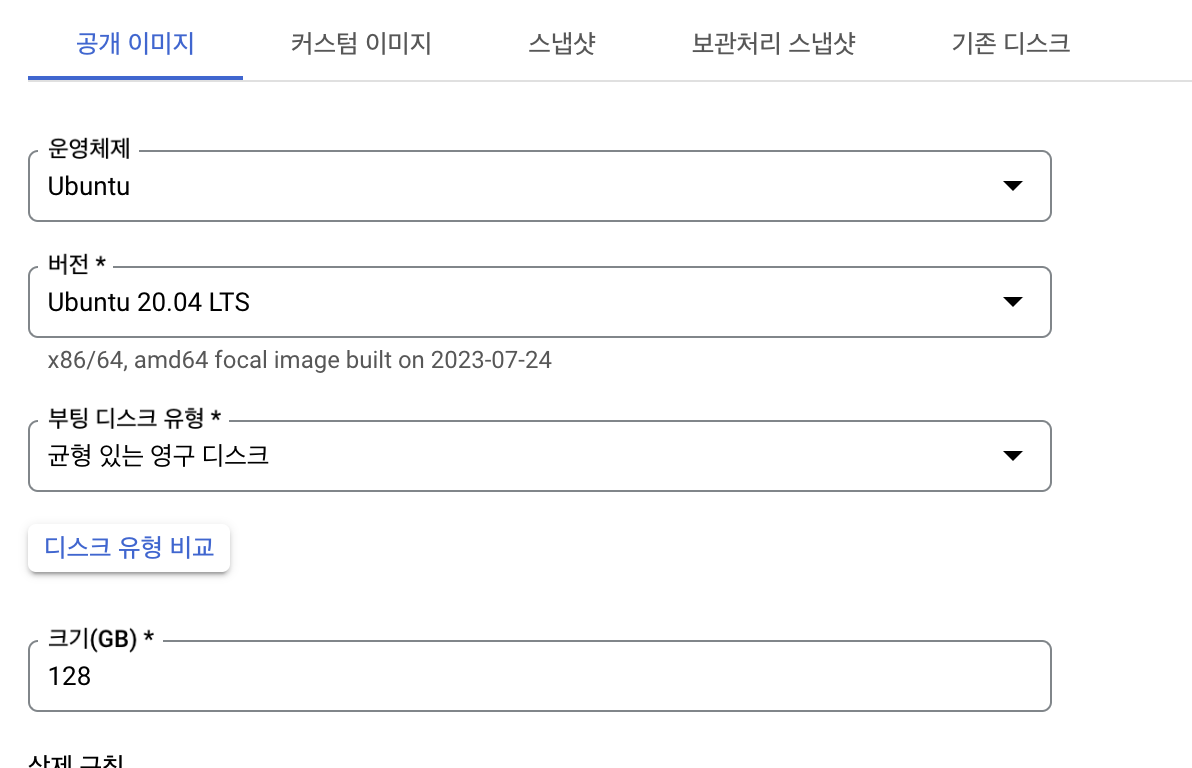
- 운영체제 : Ubuntu
- 버전 : Ubuntu 20.04 LTS
- 크기 : 128GB
참고
자동으로 Deep learning학습에 필요한 GPU driver나 toolkit들을 설치하는 프로세스를 밟아주는 Deep learing on Linux 운영체제가 있는데 l4 GPU에서는 nivida-smi로 확인해보았을때 GPU가 정상적으로 인식이 안 되어서 Ubuntu운영체제로 진행했습니다.
(V100같은 다른 gpu는 Deep learning on Linux로 했을때 잘됨,,혹시 이유를 알면 댓글부탁드립니다.)
설정이 완료되었다면 만들기 버튼을 눌러주면됩니다.

잘 생성이 되었으면 이렇게 VM인스턴스에 뜹니다. 그 후 SSH 버튼을 눌르면 웹상에서 SSH접속이 됩니다.
CUDA TOOLKIT 설치
https://cloud.google.com/compute/docs/gpus/install-drivers-gpu
공식 홈페이지를 참고하여 CUDA TOOLKIT을 설치해줍니다.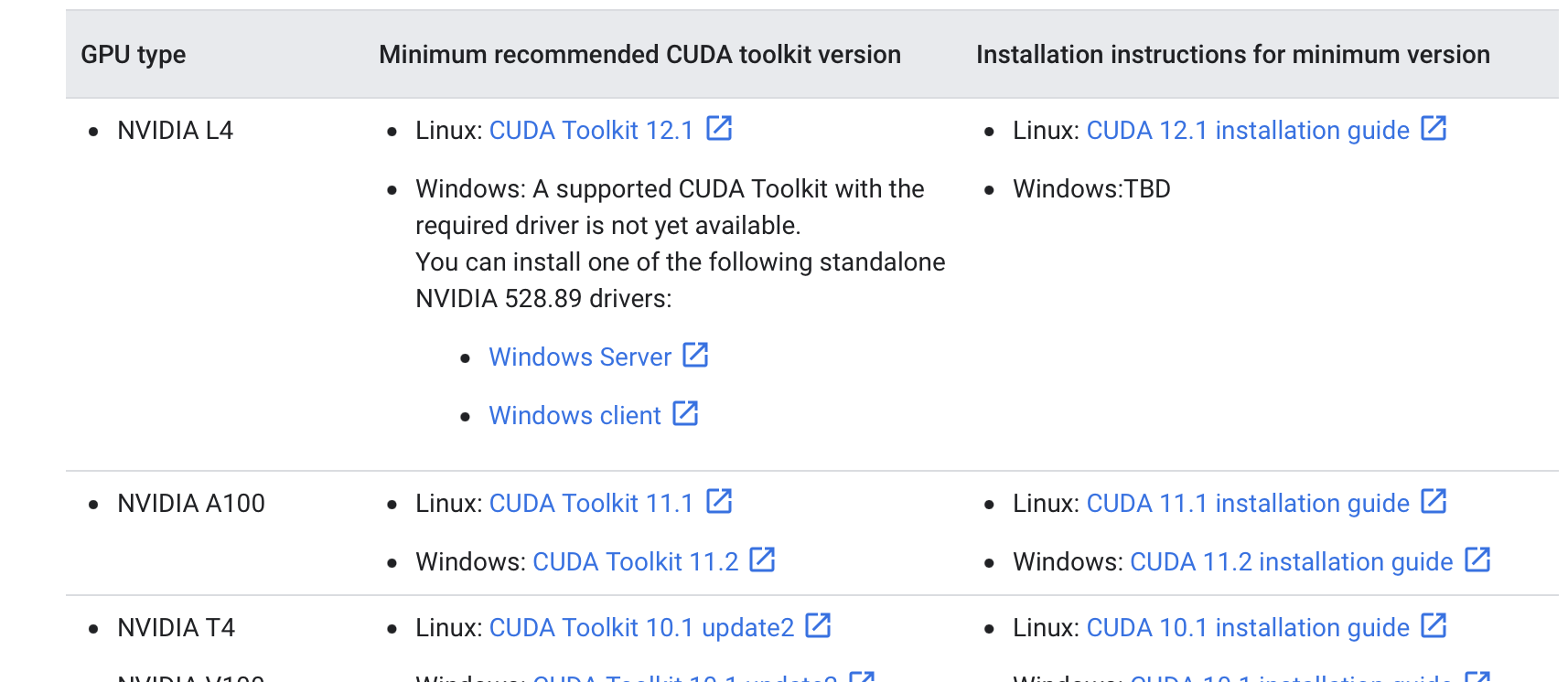
Linux: CUDA Tookit 12.1 (https://developer.nvidia.com/cuda-12-1-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=20.04&target_type=deb_network)

installation instructions에 있는대로 터미널에 입력해주시면 됩니다.
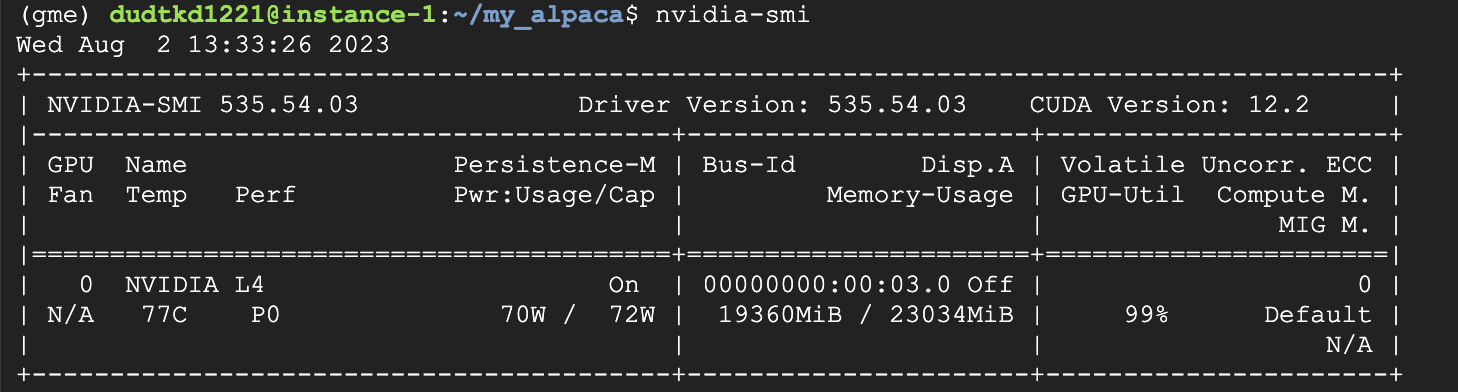
nvidia-smi정상적으로 설치되었을때
CONDA 설치
python 버전 및 라이브러리 관리를 위해 conda를 설치합니다.
https://velog.io/@tube-jeonghoon/Ubuntu에-anaconda-설치하기
위 블로그를 참고하여 설치했습니다.
설치가 완료되었으면
source anaconda3/bin/activateconda를 활성화해줍니다.
(base) user@instance-1:~$이런식으로 활성화 되어야합니다.
conda create -n "가상환경이름" python="version"위 환경은 python 3.10.12에서 진행했으므로
python=3.10.12를 적어주시면됩니다.
conda activate "가상환경이름"저장소
git clone https://github.com/yeongsang2/my_alpacahttps://github.com/tloen/alpaca-lora
https://github.com/nlpai-lab/KULLM
해당 프로젝트에 있는 코드는 위에있는 저장소를 참고하였습니다.
라이브러리 설치
pip install - requirements.txt의존하는 하는 라이브러리들을 설치해줍니다.
wandb 연동
wandb와의 연동을 원한다면
https://wandb.ai/site에 가입하여 API KEY를 발급받으면 됩니다.
wandb loginterminal에 wandb login을 입력후 발급받은 API KEY를 입력하면 됩니다. (한번 입력하면 로컬저장소에서 캐싱하여 로그인이 필요할시 자동으로 로그인 됩니다.)
관리자 권한 실행
관리자 권한으로 실행안할시 permission 관련 error 발생하기 때문에,,(저는)
관리자 권한의 계정으로 변경해줍니다.
비밀번호 설정
sudo passwd권한 변경
su권항 변경시 conda가 비활성화된다면 source anaconda3/bin/activate로 다시 활성화 해주면 됩니다.
학습 실행
python finetune_lora.py
SSH 연결이 끊기더라도 학습을 유지하기 위해 nohup ~ & 로 파일을 실행시켜줍니다.
nohup python finetune_lora.py \
--base_model 'EleutherAI/polyglot-ko-12.8b' \
--data_path 'data_path' \
--output_dir output/ \
--prompt_template_name cbnu \
--batch_size 128 \
--micro_batch_size 2 \
--num_epochs 5 \
--learning_rate 3e-4 \
--optim "adamw_torch" \
--cutoff_len 1024 \
--val_set_size 1000 \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--lora_target_modules "[query_key_value, xxx]" \
--train_on_inputs \
--logging_steps 10 \
--save_steps 100 \
--eval_steps 100 \
--warmup_steps 100 \
--lr_scheduler_type "linear" \ &위 hyperparameter로 실행하면 19GB(VRAM)정도 사용합니다.
cutoff_len과 miciro_batch_size 설정값에 의해 학습가능여부가 달라집니다. cutoff_len 1024 기준 micro_batch_size를 4이상으로 설정하면 OOM(out ot memory)가 발생합니다. (24GB VRAM기준)
모니터링
학습을 모니터링하기 위해선
cat nohub.out또는
wandb(https://wandb.ai/site)에서 모니터링 하면 됩니다.
예시
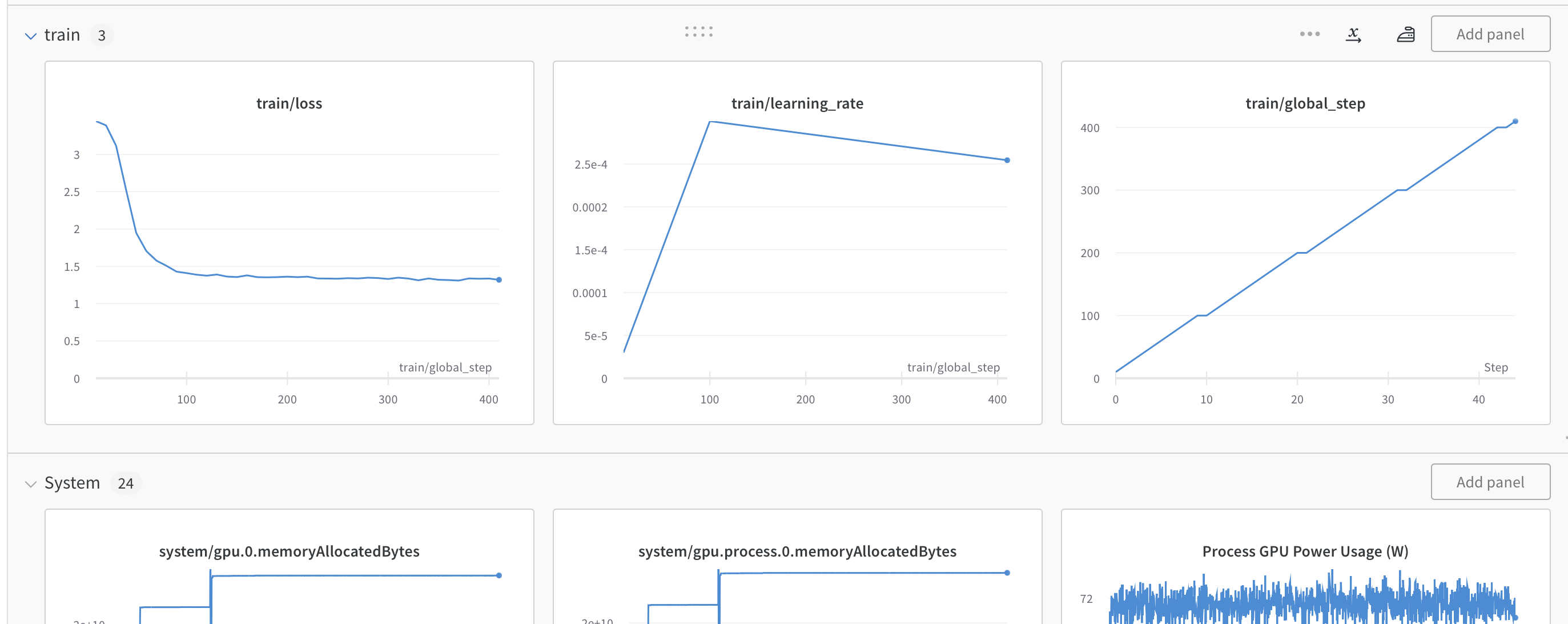
참고

글 잘 봤습니다.