babyAgi
babyAgi는 작업 기반 자율 에이전트(Task-driven Autonomous Agent)로 GPT같은 LLM(대규모 언어모델)과 협력하여 자율적으로 해야할 태스크들을 생성해내고 우선순위를 지정하여 특정 목적(objective)를 향해 작업을 합니다.
자율 에이전트란?
자율 에이전트는 목표가 주어지면 스스로 작업을 생성하고, 작업을 완료하고, 새 작업을 생성하고, 작업 목록의 우선순위를 재조정하고, 새로운 상위 작업을 완료하고, 목표에 도달할 때까지 반복할 수 있는 강력한 AI 기반 프로그램입니다.
agent?
agent란 작업을 완료하고, 완료된 결과를 기반으로 새로운 작업을생성, 우선순위 지정을 하는 일종의 관리자이며
babyagi에서는 다음과 같은 3가지 agent가 존재합니다.
- Execution Agent
- Task Creation Agent
- Prioritization Agent
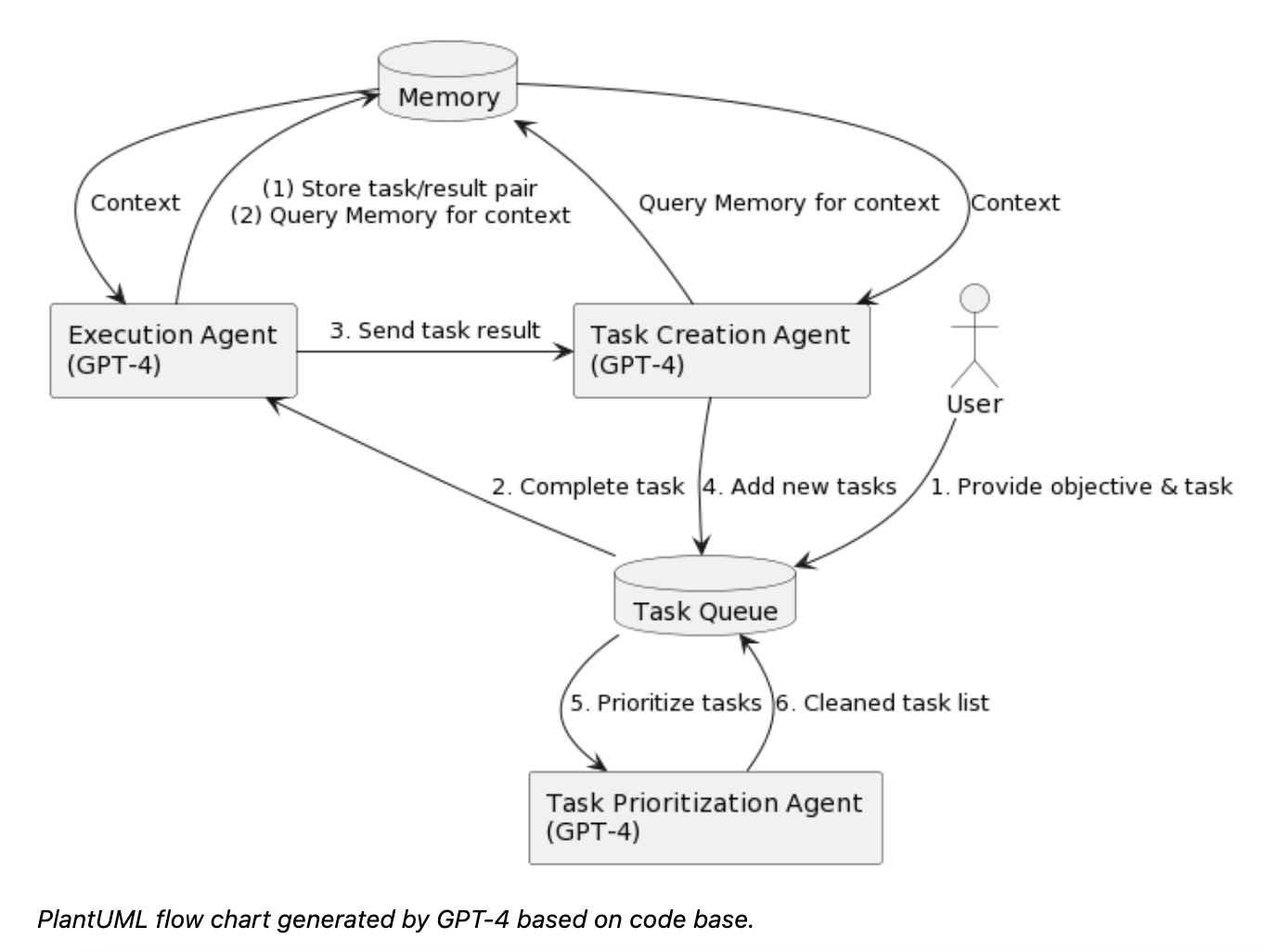
3가지 Agent에 대해 설명하기 앞서 알아야할 agent가 참조하는 두 가지의 저장소가 있습니다.
Storage
Context memory
해당 저장소는 vector 기반 database로 작업과 관련 내용, 제약사항, 작업 결과 등을 (필요시 보강하여) 저장되는 저장소로 https://github.com/yoheinakajima/babyagi#supported-models 에서는 default로 Chroma db가 사용되며 weaviate, pinecone 을 지원합니다.
Task Storage
이 구조는 dequeue(double-ended queue)자료구조 형태이며, agent가 생성한 작업 목록들을 유지 관리합니다.
Agent
Execution Agent
사용자가 Execution Agent에게 objective 와 task를 전달해주면 해당 objective, objective, context를 기반으로 한 프롬프트로 OpenAI api를 호출함으로서 작업을 진행합니다.
Task Creation Agent
Task Creation Agent는 사용자가 준 정보 (objective, 마지막 작업 결과, 작업내용, 작업리스트) 를 기반으로 한 프롬프트로 OpenAI api를 호출하고, 응답값으로 새로운 task가 추가된 결과값을 받습니다.
Prioritizaiton Agent
Prioritizaiton Agent 는 새로운 task list가 생성된 후 실행되며, 우선순위를 배치하라는 프롬프트로 open api를 호출함으로서 task들의 우선순위를 재배치 합니다.
작동흐름
langhcain framework 에서 babyagi를 사용하는 방법도 있지만(https://python.langchain.com/docs/use_cases/autonomous_agents/baby_agi.html)
여기에서는 https://github.com/yoheinakajima/babyagi#supported-models 에 존재하는 babyagi.py에서의 작동방식을 설명하겠습니다.
init
실행하기 앞서 .env파일에서 설정을 해줍니다. 우선 OpenAI의 모델을 사용하기 때문에 api key값이 필요로하며, 그 외에 어떤 LLM모델을 사용할건지 등의 설정이 필요합나디. pinecone 을 사용하려면 pinecone api key도 필요로 합니다.
..
LLM_MODEL=gpt-3.5-turbo
OPEN_API_KEY = ''
OPEN_TEMPERATURE = '0.0'
..
OBJECTIVE=Solve world hunger # 목적
INITIAL_TASK=Develop a task list # 초기 task
result storage
class DefaultResultsStorage:
def __init__(self):
logging.getLogger('chromadb').setLevel(logging.ERROR)
# Create Chroma collection
chroma_persist_dir = "chroma"
chroma_client = chromadb.Client(
settings=chromadb.config.Settings(
chroma_db_impl="duckdb+parquet",
persist_directory=chroma_persist_dir,
)
)
metric = "cosine"
if LLM_MODEL.startswith("llama"):
embedding_function = LlamaEmbeddingFunction()
else:
embedding_function = OpenAIEmbeddingFunction(api_key=OPENAI_API_KEY)
self.collection = chroma_client.get_or_create_collection(
name=RESULTS_STORE_NAME,
metadata={"hnsw:space": metric},
embedding_function=embedding_function,
)
def add(self, task: Dict, result: str, result_id: str):
# Break the function if LLM_MODEL starts with "human" (case-insensitive)
if LLM_MODEL.startswith("human"):
return
# Continue with the rest of the function
embeddings = llm_embed.embed(result) if LLM_MODEL.startswith("llama") else None
if (
len(self.collection.get(ids=[result_id], include=[])["ids"]) > 0
): # Check if the result already exists
self.collection.update(
ids=result_id,
embeddings=embeddings,
documents=result,
metadatas={"task": task["task_name"], "result": result},
)
else:
self.collection.add(
ids=result_id,
embeddings=embeddings,
documents=result,
metadatas={"task": task["task_name"], "result": result},
)
def query(self, query: str, top_results_num: int) -> List[dict]:
count: int = self.collection.count()
if count == 0:
return []
results = self.collection.query(
query_texts=query,
n_results=min(top_results_num, count),
include=["metadatas"]
)
return [item["task"] for item in results["metadatas"][0]]위에서 언급한 작업한 관련 내용이나 제약사항 등의 context가 저장되는 저장소를 초기화해줍니다. (default : chroma)
SingleTaskStorage
class SingleTaskListStorage:
def __init__(self):
self.tasks = deque([])
self.task_id_counter = 0
def append(self, task: Dict):
self.tasks.append(task)
def replace(self, tasks: List[Dict]):
self.tasks = deque(tasks)
def popleft(self):
return self.tasks.popleft()
def is_empty(self):
return False if self.tasks else True
def next_task_id(self):
self.task_id_counter += 1
return self.task_id_counter
def get_task_names(self):
return [t["task_name"] for t in self.tasks]위 클래스는 위에서 말한 task storage로 deque형태로 구현되어있으며 작업 목록들을 관리하는 클래스입니다.
babyagi.py
실행파일인 babyagi.py 에서 main loop는 다음과 같이 작동합니다.
- step1 : 미완료된 가장 첫번째 task를 가져온뒤 execution agent에게 context를 기반으로 task를 완성하도록 지식합니다.
- step2 : 완료된 task의 결과를 보강하고(필요하다면) result storage에 저장합니다.
- step3 : task creation agent가 현재 task list와 직전 task 결과값을 기반으로 새로운 task를 생성하고 태스크들의 우선순위를 재배치 합니다.
위 3가지 step이 task storage 가 남아있을 때 까지 반복하게되며 최종적으로 objective를 달성하게 됩니다.
step1
# Step 1: Pull the first incomplete task
task = tasks_storage.popleft()
print("\033[92m\033[1m" + "\n*****NEXT TASK*****\n" + "\033[0m\033[0m")
print(str(task["task_name"]))
# Send to execution function to complete the task based on the context
result = execution_agent(OBJECTIVE, str(task["task_name"]))
print("\033[93m\033[1m" + "\n*****TASK RESULT*****\n" + "\033[0m\033[0m")
print(result)deque 자료구조 형태의 tasks_storage에서 첫번째 task를 가져온뒤 objective, task를 매개변수로 excution_agent를 호출합니다.
excution_agent()
def execution_agent(objective: str, task: str) -> str:
...
context = context_agent(query=objective, top_results_num=5)
...
prompt = f'Perform one task based on the following objective: {objective}.\n'
if context:
prompt += 'Take into account these previously completed tasks:' + '\n'.join(context)
prompt += f'\nYour task: {task}\nResponse:'
return openai_call(prompt, max_tokens=2000)context를 prompt에 추가해 context기반으로 task를 실행하도록 합니다.
이때 openai api를 호출합니다.
context_agent()
def context_agent(query: str, top_results_num: int):
...
results = results_storage.query(query=query, top_results_num=top_results_num)
...
return resultsopenai_call()
elif not model.lower().startswith("gpt-"):
# Use completion API
response = openai.Completion.create(
engine=model,
prompt=prompt,
temperature=temperature,
max_tokens=max_tokens,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
)
return response.choices[0].text.strip()step2
# Step 2: Enrich result and store in the results storage
# This is where you should enrich the result if needed
enriched_result = {
"data": result
}
result_id = f"result_{task['task_id']}"
results_storage.add(task, result, result_id)결과값을 보강(필요하다면, 여기선 하지 않음)하여 result storage 에 task, result, result_id 를 저장합니다.
step3
# Step 3: Create new tasks and re-prioritize task list
# only the main instance in cooperative mode does that
new_tasks = task_creation_agent(
OBJECTIVE,
enriched_result,
task["task_name"],
tasks_storage.get_task_names(),
)objective, 이전 task에 대한 결과값과 설명, 그리고 task_list를 매개변수로 새로운 task를 만들어 내는 task_creation_agent()를 호출합니다.
task_creation_agent()
def task_creation_agent(
objective: str, result: Dict, task_description: str, task_list: List[str]
):
prompt = f"""
You are to use the result from an execution agent to create new tasks with the following objective: {objective}.
The last completed task has the result: \n{result["data"]}
This result was based on this task description: {task_description}.\n"""
if task_list:
prompt += f"These are incomplete tasks: {', '.join(task_list)}\n"
prompt += "Based on the result, return a list of tasks to be completed in order to meet the objective. "
if task_list:
prompt += "These new tasks must not overlap with incomplete tasks. "
prompt += """
Return one task per line in your response. The result must be a numbered list in the format:
#. First task
#. Second task
The number of each entry must be followed by a period. If your list is empty, write "There are no tasks to add at this time."
Unless your list is empty, do not include any headers before your numbered list or follow your numbered list with any other output."""
print(f'\n*****TASK CREATION AGENT PROMPT****\n{prompt}\n')
response = openai_call(prompt, max_tokens=2000)
print(f'\n****TASK CREATION AGENT RESPONSE****\n{response}\n')
new_tasks = response.split('\n')
new_tasks_list = []
for task_string in new_tasks:
task_parts = task_string.strip().split(".", 1)
if len(task_parts) == 2:
task_id = ''.join(s for s in task_parts[0] if s.isnumeric())
task_name = re.sub(r'[^\w\s_]+', '', task_parts[1]).strip()
if task_name.strip() and task_id.isnumeric():
new_tasks_list.append(task_name)
# print('New task created: ' + task_name)
out = [{"task_name": task_name} for task_name in new_tasks_list]
return outpromt내용은 다음과 같습니다. objectvie, 마지막으로 수행한 task의 결과와 설명, 그리고 아직 완수하지못한 task list를 추가한뒤 이것에 기반하여 새로운 태스크를 추가하여 출력하라고 합니다.
새롭게 추가된 task들을 [{"task_name": task_name}] 딕셔너리값을 같은 배열로 만들어 return 합니다.
for new_task in new_tasks:
new_task.update({"task_id": tasks_storage.next_task_id()})
print(str(new_task))
tasks_storage.append(new_task)새롭게 추가된 task들을 task_storage에 task_id와 함께 추가합니다.
if not JOIN_EXISTING_OBJECTIVE:
prioritized_tasks = prioritization_agent()
JOIN_EXISTING_OBJECTIVE가 false라면 prioritization_agent를 호출하여 우선순위를 재배치 합니다.
prioritization_agent()
def prioritization_agent():
task_names = tasks_storage.get_task_names()
bullet_string = '\n'
prompt = f"""
You are tasked with prioritizing the following tasks: {bullet_string + bullet_string.join(task_names)}
Consider the ultimate objective of your team: {OBJECTIVE}.
Tasks should be sorted from highest to lowest priority, where higher-priority tasks are those that act as pre-requisites or are more essential for meeting the objective.
Do not remove any tasks. Return the ranked tasks as a numbered list in the format:
#. First task
#. Second task
The entries must be consecutively numbered, starting with 1. The number of each entry must be followed by a period.
Do not include any headers before your ranked list or follow your list with any other output."""
print(f'\n****TASK PRIORITIZATION AGENT PROMPT****\n{prompt}\n')
response = openai_call(prompt, max_tokens=2000)
print(f'\n****TASK PRIORITIZATION AGENT RESPONSE****\n{response}\n')
if not response:
print('Received empty response from priotritization agent. Keeping task list unchanged.')
return
new_tasks = response.split("\n") if "\n" in response else [response]
new_tasks_list = []
for task_string in new_tasks:
task_parts = task_string.strip().split(".", 1)
if len(task_parts) == 2:
task_id = ''.join(s for s in task_parts[0] if s.isnumeric())
task_name = re.sub(r'[^\w\s_]+', '', task_parts[1]).strip()
if task_name.strip():
new_tasks_list.append({"task_id": task_id, "task_name": task_name})
return new_tasks_list프롬프트는 task list와 objective 를 기반으로 우선순위에 맞게 재배치하여 작업 목록을 반환하라는 내용이 담겨있으며, 새롭게 재배치된 작업 목록을 return 합니다.
if prioritized_tasks:
tasks_storage.replace(prioritized_tasks)
...
def replace(self, tasks: List[Dict]):
self.tasks = deque(tasks)
기존의 작업목록을 새로운 작업 목록으로 재배치합니다.
def main():
loop = True
while loop:
# As long as there are tasks in the storage...
if not tasks_storage.is_empty():
....
time.sleep(5)
else:
print('Done.')
loop = False위 step을 task storage에 작업이 남아있을 때까지 반복하여 설정한 목적에 도달하게 됩니다.
refence

다음 업로드는 언제인가요?