Anomaly Detection 분야에서 예전의 방법론인 SVDD를 신경망에 활용하여 개선하는 논문
· Anomaly detection의 종류 (Train set이 어떻게 구성되어 있는지에 따라 구분됨)
1. Supervised anomaly detection [ Train set: normal/abnormal으로 이루어져 있고, 각각이 normal인지 abnormal인지 label 되어있는 data ]
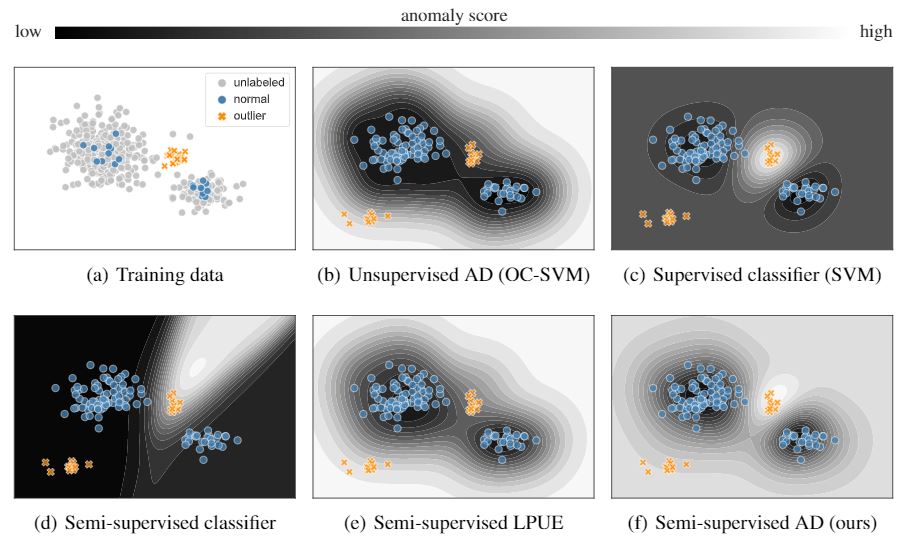
2. Semi-supervised anomaly detection [ Train set : unlabeled되어 있는 normal data(多), normal/abnormal인지 labeled되어 있는 data(少) ]
3. Unsupervised anomaly detection [ Train set: unlabeled data (데이터의 대부분이 normal이라고 가정) ]
Deep SAD --> Deep SVDD에 semi supervised learning을 접목시킨 것
다시 Deep SVDD --> SVDD을 deep learning화한 모델
Anomaly Detection의 종류 중 정상 데이터만을 가지고 학습을 시킨 후 비정상 데이터를 분류하는 방법 중 대표적인 모델: SVDD
· 정상 데이터를 둘러싸는 가장 작은 구를 구한 후 구 밖에 있는 데이터를 비정상 데이터로 분류
· kernel을 사용해 data를 feature space로 mapping했다.
Deep SVDD
· neural network를 통해 input을 feature space로 mapping한 후, Feature Space에서 정상 데이터를 둘러싸는 가장 작은 구를 찾고, 그 경계를 기반으로 abnormal data를 탐지하는 방법이다. 정상 데이터의 각 데이터 point가 구의 중심에 가깝게 mapping되도록 하는 모델을 설계하고, 구의 경계를 넘어가는 data를 abnormal로 판정한다.
· CNN과 Auto Encoder을 이용해 representation을 생성함으로써 feature space로 mapping 한다.
Deep SAD
· Semi-supervised learning을 도입해 Deep SVDD의 일반화된 방법론을 구축
· Auto Encoder와 유사한 Information Bottleneck Principle을 이용, Auto Encoder는 원본을 복원할 수 있는 Latent Variable을 찾는 반면, Information Bottleneck Principle은 원본 데이터의 Label을 맞출 수 있는 압축된 Latent Variable을 탐지한다.
· Deep SAD에서는 Information Bottleneck Principle을 Mutual Information 관점에서 해석하여, unsupervised learning 상황에서 input variable X를 latent variable Z 로 최대한 압축하는 representation을 수행한다. 최종적으로는 labeled 데이터를 활용하여 사영된(representation) 공간안에서의 중심으로부터 normal 데이터인 부분은 가까이, abnormal데이터는 멀리하는 목적식을 학습하게 된다.
· abnormal 데이터를 소량 사용함으로써 구의 부피를 최소화하되, normal data와 abnormal data를 모두 학습하여 normal은 구의 중심에 가깝게, abnormal은 구의 중심에서 멀어지게 학습한다.
원래 anomaly detection에서 주를 이루었던 unsupervised 관점과는 달리, 위 논문은 semi-supervised의 관점에서 활용된 방법론이라서 의미가 있다.
