GAN ensemble을 이용한 anomaly detection
GAN
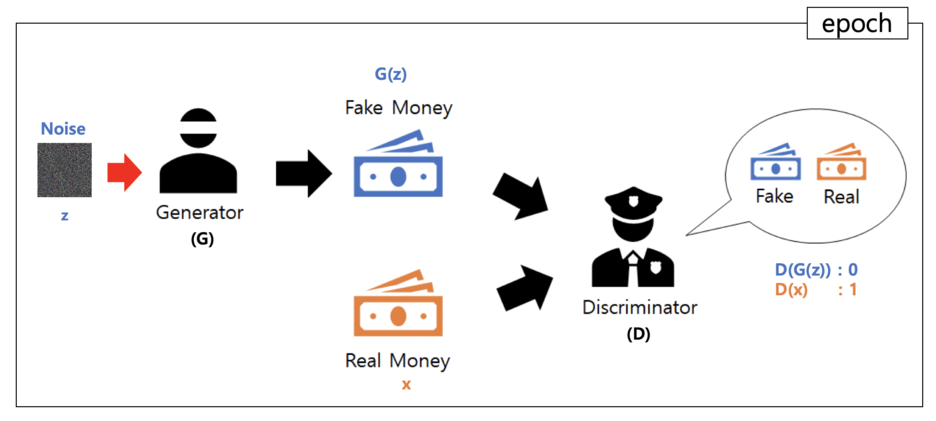
· Generator(image를 만들어 내는 역할, Discriminator을 속여야 함)와 Discriminator(그것을 평가함)로 구성되어 있다. 서로 대립하며, 서로의 성능을 점차 개선시키는 방법. Discriminator가 real과 fake를 잘 맞추도록 훈련을 한 다음, generator가 만들어낸 fake가 discriminator에서 real로 나오도록 하는 학습과정
· Generative model G는 갖고 있는 data x의 distribution을 알아내려고 노력, 만약 G가 정확히 data distribution을 모사할 수 있다면 거기서 뽑은 sample은 완벽히 data와 구별 할 수 없게 된다. 반면 Discriminator model D는 현재 자기가 보고 있는 sample이 training data에서 온 것인지 G로부터 만들어진 것인 지를 구별하는 역할을 한다.
GAN ensemble
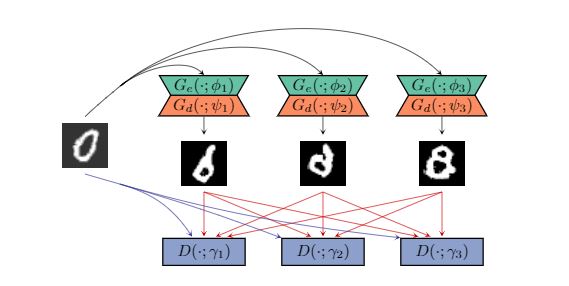
· Anomaly detection을 하기 위해 GAN-based anomaly model에 ensemble learning을 도입한 것이다.
· Generator 그룹과 discriminator 그룹이 함께 train되고, 모든 generator는 여러 discriminator로부터 피드백을 받고, 그 반대도 마찬가지가 된다.
· GAN ensemble은 다양한 encoder-decoder와 discriminator로 구성되어 있으며 무작위로 짝 지어지고, adversarial training을 통해서 훈련된다. Anomaly score은 모든 encoder-decoder과 discriminator의 pair로부터의 계산된 anomaly scores의 평균값이 된다. Generator로 encoder-decoder을 갖고 discriminator로 classifier의 구조를 갖는다.
Proposed Approach
· GAN adversarial training process에서는 generator은 모든 discriminator로부터 비판 받고, discriminator은 generator로부터 synthetic samples을 받는다.
· GAN ensemble에서는 모든 generator와 모든 discriminator을 충분하게 train하기를 원하는 것이므로, weights을 사용하지 않는다.
· Generators와 Discriminators의 여러 쌍으로, adversarial loss와 discriminative loss는 모든 generator-discriminators pairs로부터 계산된다.
· Generators을 train시키기 위해 모든 losses들의 합을 최소화시키는 반면 discriminators을 train시키기 위해 adversarial losses의 합은 최대화 시킨다.
· Batch training : 한 번의 training iteration에서는 모든 generators와 discriminators을 update하는 대신에 한 쌍의 generator-discriminator만을 업데이트 한다. 특히 generator와 discriminator를 무작위로 선택하고 무작위 batch of training data로 손실을 계산한다.
· Anomaly detection에서 GAN discriminator의 역할이 중요하다고 강조, GAN training objective에 따라 discriminator는 실제 데이터와 거리가 먼 synthetic 샘플에는 작은 값을 제공해야 한다. 실제로 GAN은 연속 생성 분포를 사용하여 이산 데이터 분포를 기본적으로 근사치로 추정한다. 수렴 시 discriminator는 실제로 training 샘플에 큰 값을 제공하고 멀리 떨어진 샘플에는 작은 값을 제공한다. Training 샘플과 매우 다른 generated된 sample은 positive sample이 된다.
train 샘플과 매우 다르게 생성된 샘플은 discriminator에 대한 anomalies의 “positive samples”이 되며, discriminator는 이러한 샘플에 작은 값을 부여하도록 훈련된다.
예를 들면, 샘플 0이 abnormal class 이고, 이것의 reconstructions은 더 normal samples과 비슷 할 것이다. 그러면 discriminator가 그 reconstruction과 anomaly에 다른 값들을 준다. 이 값들은 마지막 layer의 hidden vector의 linear transformation이라서 anomaly의 hidden vector은 reconstruction과는 다르다.
그래서 GAN에서는 discriminator의 역할이 중요하다.
실험 및 결과 분석
· 첫 번째 실험: 다양한 dataset을 이용하여, f-AnoGAN, GANomaly 등등 네 개의 base model과 four types의 ensembles을 비교했다. 그 결과 ensemble methods가 상응하는 base models보다 우수한 performance를 보였다.
· 두 번째 실험: ensemble size만 변경시키고 ensemble size와 performance에 어떤 영향을 주는지를 측정하였다. 그 결과, ensemble size가 3일 때가 best였다.
· ensemble이 base model의 performance를 왜 향상시키는지를 이해하기 위해 정상 비정상 샘플들의 encoding vectors와 hidden vectors을 분석했다. [Encoding vector sample이 GAN에 있을 때 encoder로부터 encoding vector를 얻고, discriminator의 마지막으로 숨겨진 layer에서 hidden vector을 얻음] 이를 통해 ensemble이 discriminator을 더 잘 train한다는 것을 알 수 있었음
이유 : Training sample과 test sample의 representation이 매우 유사, abnormal samples의 hidden vectors가 test normal samples과 멀리 떨어짐, abnormal sample의 reconstruction이 normal sample과 유사
그 결과 ensemble이 discriminator training과 anomaly scores을 향상시킨다는 것을 보임.
