
[1] pivot() :
df = pd.DataFrame({'num': ['one', 'one', 'one', 'two', 'two', 'two'],
'alpha': ['A', 'B', 'C', 'A', 'B', 'C'],
'n': [1, 2, 3, 4, 5, 6],
's_alpha': ['x', 'y', 'z', 'q', 'w', 't']})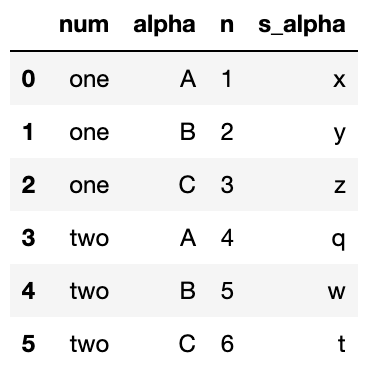
# 'num'컬럼을 인덱스로, 'alpha'컬럼을 컬럼으로, 값은 'n'컬럼의 값들로 채운다.
df.pivot(index='num', columns='alpha',values='n')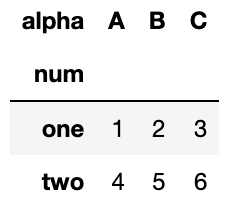
# 'num'컬럼을 인덱스로, 'alpha'컬럼을 컬럼으로, 값은 'n'컬럼의 값들로 채운다.
df.pivot(index='num', columns='alpha')['n']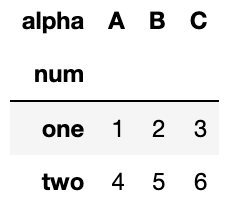
# 'num'컬럼을 인덱스로, 'alpha'컬럼을 컬럼으로, 값은 'n'컬럼과 's_alpha'컬럼의 값들로 채운다.
df.pivot(index='num', columns='alpha',values=['n', 's_alpha'])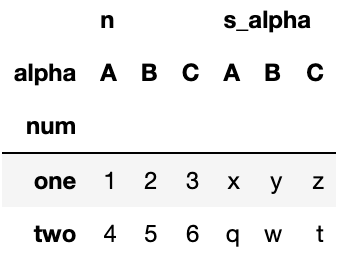
[2] pivot_table() :
df = pd.DataFrame({'num': ['one', 'one', 'one', 'two', 'two', 'two'],
'alpha': ['A', 'B', 'C', 'A', 'B', 'C'],
's_alpha': ['x', 'y', 'z', 'q', 'w', 't'],
'n': [1, 2, 3, 4, 5, 6],
'nn': [7, 8, 9, 10, 11, 12]})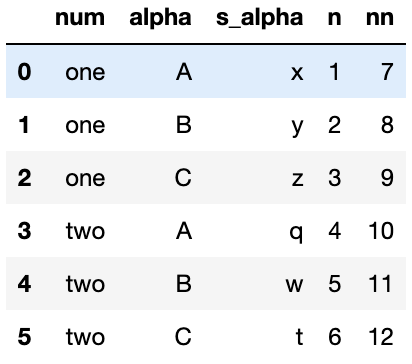
# 인덱스는 'num'열과 's_alpha'열, 컬럼은 's_alpha'열, 값은 'n'열, 'n'열의 덧셈값 배치
pd.pivot_table(df, values='n', index=['num', 'alpha'], columns=['s_alpha'], aggfunc=np.sum)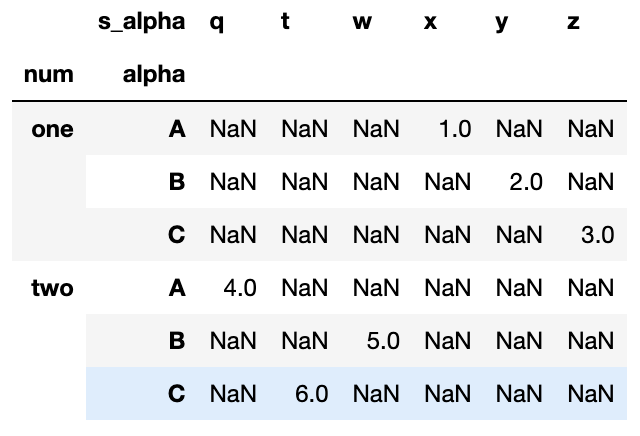
# 인덱스는 'num'열과 's_alpha'열, 컬럼은 's_alpha'열, 값은 'n'열, NaN값 0으로 채워줌
df2 = pd.pivot_table(df, values='n', index=['num', 'alpha'], columns=['s_alpha'], aggfunc=np.sum, fill_value=0)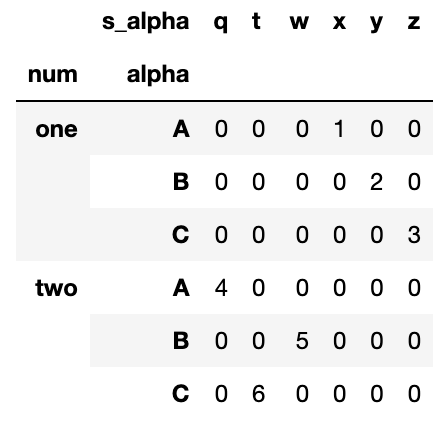
# 인덱스는 'num'열과 's_alpha'열, 값은 'n'열과 'nn'열, 'n'열과 'nn'열의 평균값 배치
df2 = pd.pivot_table(df2, values=['n', 'nn'], index=['num', 's_alpha'], aggfunc={'n': np.mean, 'nn': np.mean})# 인덱스는 'num'열과 's_alpha'열, 값은 'n'열과 'nn'열, 'n'열은 평균값, 'nn'열은 최솟값/최댓값/평균값 각각 배치
pd.pivot_table(df, values=['n', 'nn'], index=['num', 's_alpha'], aggfunc={'n': np.mean, 'nn': [min, max, np.mean]})data.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
# index : index 색인으로 사용될 컬럼
# columns : column 색인으로 사용될 컬럼
# aggfunc : 데이터 축약 시 사용할 함수 (mean, sum, count ...)
# margins : 행/열별 총 합그래서,
- pivot() : 데이터의 형태만 바꿈
- pivot_table() : aggfunc을 통해 연산도 함
