AI>ML>DL
딥러닝 - 신경망, 계층이 많은 특정 모델을 사용
Tom Mitchell's definition
T(class of task)
- classification, regression, detection
P(performance measure) - error rate, accuracy, likelihood, margin
E(expericence) - data
기계학습의 최대 목표
Generalization
- 수많은 예제들의 공통점을 파악해 일반화, 추상화 하는 것
- Training data로부터 패턴을 학습하기
- A form of abstraction where common properties of specific instances are formulated as general concepts or claims
No Free lunch Theorem for ML
- 매번 새로운 task, data를 찾을 때마다 최적의 알고리즘을 찾는 과정을 수행
- 알고리즘의 복잡도에 따라 모델이 달라짐 (Resnet같은 경우도)
Types of Learning
1. supervised learning
- 알고리즘에게 정답을 가르쳐주는 것 (input- output)
classificatino은 y가 categorical(범주형)value
regression은 y가 continuous(실수) value
x는 multi-dimensional vector
2. unsupervised learning
clustering, anomaly detection, density estimation
3. Semi-supervised learning
supervised learning과 unsupervised learning의 중간
몇몇 데이터는 x와 y를 주고 (사람이 레이블링) , 몇몇 data는 그냥 x만 주는 것
LU learning - 몇몇 데이터는 label주고 , 그 외의 데이터들은 label 안 주는 경우
PU learning - One- class classification의 일종, 특정 class에 대한 data만 주어지기 때문
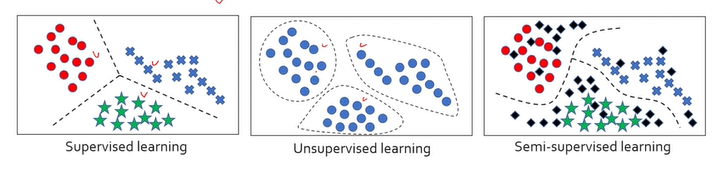
검은색 데이터가 label되지 않은 데이터
Reinforcement learning (강화 학습)
- Dataset대신 환경이 주어짐
- Agent과 환경과 interaction하며 학습하는 경우
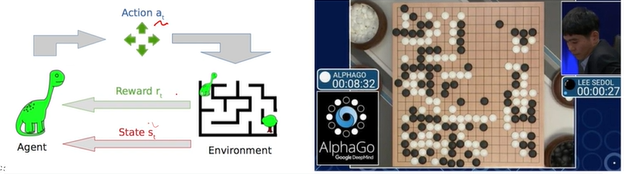
- state에서 action에 따라 reward
- reward가 이후에 주어지는 경우 어려움

- training set과 test set은 다른 sample, universal set에서 sampling
True distribution: P(x,y)
- Data x와 Label y와의 모든 상관관계를 표현하고 있는 분포
- 관측이 불가능
- Train,test set 모두 True distribution에서 sampling된 것
- Assumption: iid (데이터 하나하나를 얻는 과정이 독립적, 샘플링하는 과정에서 분포가 바뀌지 않는 것

- Expectation은 어떤 분포를 가지는 값을 하나의 숫자로 요약한 것, loss를 하나의 숫자로 요약
- 위 Generalization Error 수식: x와 y가 true distribution을 따를 때 loss의 평균값, 기댓값
- Overfitting은 training error가 Generalization error보다 적을 때, 과하게 학습 데이터에 적합
- Underfitting은 Generalization error가 training error보다 작을 때
- Overfitting보다 Underfitting이 더 안 좋은 상황 , Underfitting은 학습조차 제대로 시키지 못한 상황, 정답이 주어진 경우 training error를 줄이는 게 더 쉬움
- 1차 목표는 overfitting이 나도록, 즉 학습 모델은 잘 찾을 수 있도록
- Training error를 줄일 수 있을 때까지 줄여보는 것
- Validation error와 training error 사이 간극이 커질 경우 Regularization등의 방법으로 training error을 조금 손해보더라도 Validation error, test error을 낮춤
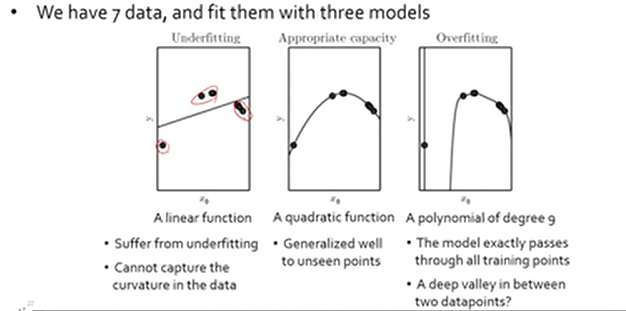
- 언더피팅의 경우 모델의 capacity가 너무 낮아 데이터 상에 존재하는 Curvature를 표현할 수 없음
Occam's Razor
- 현상을 설명할 수 있는 모델이 두 세개 있다면 가장 간단한 모델이 최적
- 경험에 대한 것이지 정답에 대한 내용X
Typical Relation between Capacity and Error
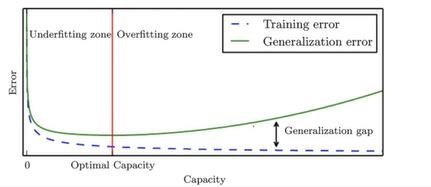
- 모델의 Capacity를 높일 수록 무조건 Training error는 줄어듬
- 일반화 에러를 줄이는 게 목저기기 때문에 녹색 그래프가 최소되는 지점을 찾아야 함
- 파란색 실선은 학습 과정에서 쉽게 그릴 수 있음
- Cross Validation등의 기법으로 일반화 에러 실험해봄
Regularization 정규화

- 특정 솔루션에 대한 preference
- 학습 과정동안 최적화, 목적 함수, loss가 minimize되도록 함
- 과적합에 빠지지 않도록 regularization term을 추가
- 낮은 차수를 사용하는 것이 좋음
- model의 capacity도 minimize하도록 regularization
- regularization term에는 hyperparameter(일반 파라미터는 학습을 통해 배우는 변수들, hyperparameter는 주어야 하는 변수)을 줌
- 보통 hyperparameter은 cross validation(교차 검증) 과정을 통해 결정하게 됨
- regularization의 목표는 generalization error를 낮추겠다는 것(Training error X)
- training error를 낮출거면 regularization을 아예 쓰지 않는 게 좋음
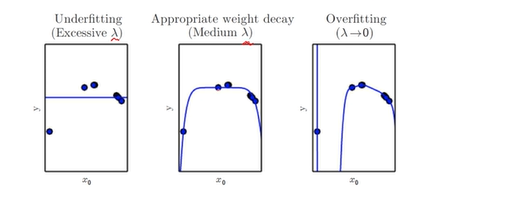
- 람다 값에 따라 모델의 capacity변함
- 최적의 capacity를 가지는 모델을 찾는 것도 하나의 방법, 최적의 capacity보다 좀 더 높은 capacity를 가진 모델을 활용하고 대신 regularization을 활용할 수 있음
Bias / Varaince Decomposition
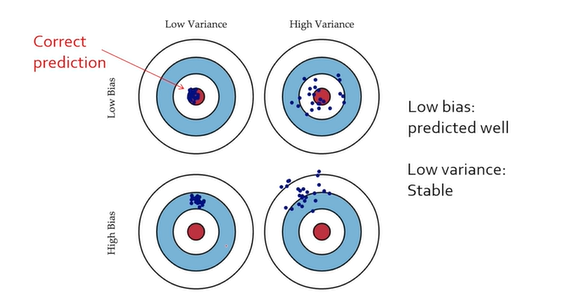
- 학습이 잘되려면 Bias, Variance 둘다 낮아야함
- Bias는 예측의 평균값과 True값의 차이
- Variance는 x와 u사이 제곱의 평균

- Bias와 Variance사이 tradeoff가 존재
- 이 둘을 해결하기 위한 방법이 Ensemble learning

- 모델의 복잡도가 올라갈수록 (overfitting) variance가 커짐
- 가장 좋은건 데이터를 최대한 빈틈없이 모아서 overfitting시키는 것, 데이터가 적을 경우 overfitting시키고 regularizatinon
- overfitting은 데이터를 넣어주면 해결이 되는데 High Bias model의 경우 데이터를 넣어줘봐야 데이터를 표현할 수 있는 능력이 없기 때문에 많이 나아지지 않음
Part 3. Recent Progress of Large Language Models
GPT-3 model
- GPT 3 부터는 오픈소스X, 사이트에서 API Call, 토큰 별로 과금
Insturct GPT ==GPT 3.5
- 언어 이해는 완벽한 상태에서 사람의 지시를 유용하게, 안전하게(차별적인 언행 등에 주의)
- RLHF(Reinforcement learning from human feedback- 사람의 피드백으로부터 강화학습)
- 여러 응답을 답변해 사용자가 선호하는 답변을 학습
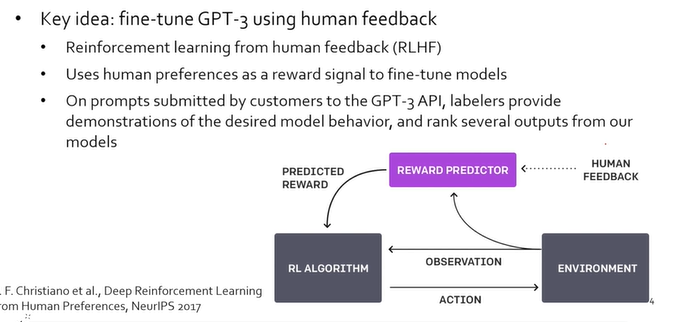
- GPT3는 언어 이해만 가능함 지시 수행은 X
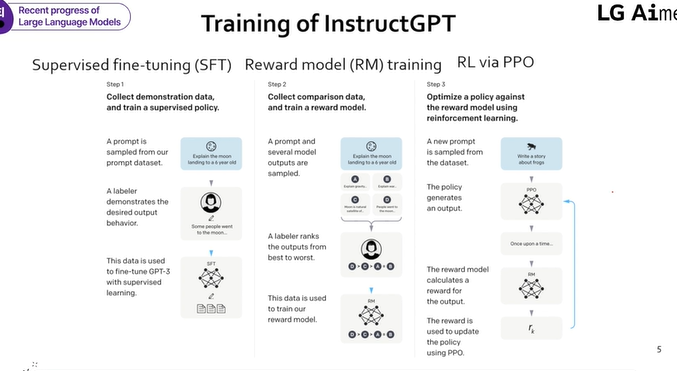
- Step1) 우선 사람을 통해 학습, GPT3에 사람들이 지시한 것들을 모음. 각 질문별로 사람들에게 어떻게 응답해야하는지 물어봄 -> supervised learning
- Step2) Reward Model -> 하나의 질문에 대해 A,B,C,D 네 가지 응답을 만듬, 네 개의 응답 중 사람이 어떤 응답을 선호하는지 랭킹을 매김, 이 랭킹으로 reaward model(질문과 응답에 대한 ranking score을 매기는 모델) 을 학습
- Step3) 스텝1에서 fine tunning된 모델로 질문과 응답이 주어지면 ranking score을 예측할 수 있음. 해당 score을 강화학습의 보상으로 활용하여 InstructGPT를 학습
- 질문이 state,응답이 action, reward를 maximize하도록 학습
- PPO는 OpenAI사에서 만든 강화학습 알고리즘
ChatGPT
- IntsturctGPT에 Coversational UI, 대화 user interface를 추가한 것
GPT-4
- large multimodal language model - 음성, 사진, 비디오 등 다양한 정보 형식을 이해
- 사진 올리기 기능도 O
- No technical details- 모델 사이즈, 아키텍처, 하드웨어 등을 공개X
- context length-이전 대화를 기반하여 대화
- MMLU : 자연어처리 연구 분야에서 쓰이는 Banchmark 중의 하나, test set을 다양한 언어로 번역한 뒤 학습해보는 것
- input으로 이미지도 가능
- limitation

Anthropic AI사의 Claude 모델
Google의 Bard 모델 - 구글 검색 내에 있음. 구글 언어 모델 중 가장 유명한 것은 PaLM 모델

Meta의 OPT LLaMA(Large Language Model Meta AI) 언어모델
- Self instruct Tuning, LLaMA의 성능을 높이려면 instruction set(질문-답) 데이터 쌍으로 학습시킴
LMsys의 Vicuna 모델
- 라마를 가지고 ShareGPT.com사이트(ChatGPT에 대한 재미있는 응답들을 모아둔 사이트)로 가서 50만개 정도의 데이터를 학습.

- 상용 LLM과 오픈소스 LLM이 존재
