Part1. SL Foundation
Machine Learning
- 데이터로부터 내재된 패턴을 학습하는 과정
- Machine Learning: Bianary classification, Multiclsass Classification, Regression
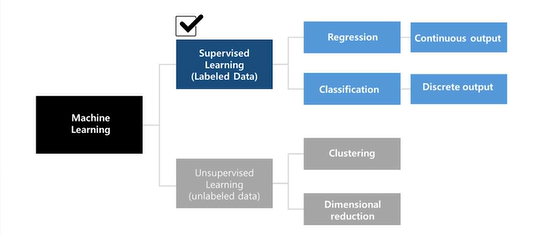
- supervised learning 문제에는 답(label)이 주어지며 regression과 classification 문제가 있음
- supervised learning에서는 입력x와 정답y로 이루어져 있음, x에서 y로 가는 함수 h를 학습함
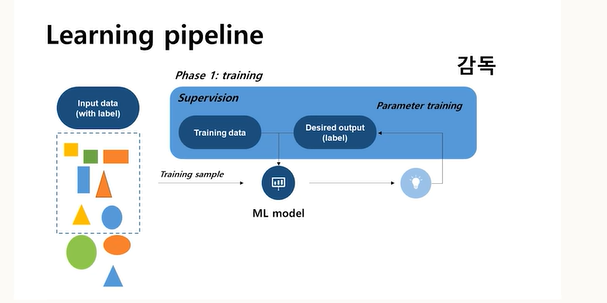
supervised learning은 크게 두 가지 과정
1) training
-
머신러닝 모델이 정답을 학습하는 과정, 모델의 파라미터를 변경해나감. 모델의 output과 정답의 차이인 error를 줄여가며 학습
2) 모델이 실제 환경에 적용 -
이때의 테스트 정확도가 진정한 모델의 성능
-
input feature
Target function

-
Target function은 입력x를 target f로 mapping 하는 함수
-
제한된 수의 데이터로 target f에 근접한 함수 Hypothesis H라 정의
-
머신러닝은 이러한 함수의 역할. 목적은 target function f를 모사하는 것
-
모델 학습과정에서는 feature selection, model selection, optimization 과정을 거침
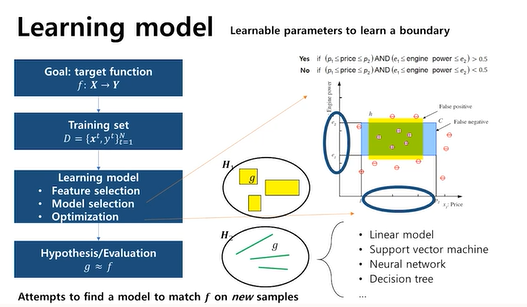
model selection
- 풀고자 하는 문제에 가장 적합한 모델을 선택하는 과정
- 선형 모델, neural network와 같은 비선형 모델도 O
머신러닝 모델 학습 과정에서 가장 중요한 건 Generalization
관찰하지 못한 데이터, 샘플에 대해서도 우수한 성능을 제공할 수 있어야 함
모델의 일반화된 성능을 측정하기 위한 measurement로 Generalization error E 사용
- training error, validation error, test error를 통해 generalization error를 최소화 하려는 노력을 하게 됨

- 에러는 샘플 별로 pointwise별로 계산
- 대표적인 error함수로는 squared error, binary error가 있음
- overall error를 cost function, loss fuction이라고도 부름
training error
-모델을 주어진 데이터셋에 맞추어 학습하는데 사용하는 에러. 주어진 샘플에서 모델 파라미터를 최적화하도록 사용
testing error
- 전체 데이터셋에서 일부 샘플을 따로 빼서 test sample로 정의. 이 샘플에서 나타나는 에러가 testing error

1) testing error가 training error와 가까워지도록 학습 - 모델이 일반적인 성능(variance가 작은)을 제공하도록 하는 기능, overfitting을 방지하는 것
2) training error가 0에 가까워지도록 학습 - 모델의 정확도 향상. bias가 낮아짐. underfitting을 방지하는 것(발생 시 더 복잡한 모델 사용)
모델의 정확도 향상
- bias 낮춤
- variance 낮춤
- model의 일반성 향상
모델이 복잡해지면 overfitting, variance 높아짐
모델이 간단해지면 underfitting, bias 높아짐
variance와 bias를 조절하여 generalization error를 최소화
복잡도 증가 속도 > 데이터셋 샘플 수
overfitting 문제 증가 -> cursion of dimension(모델의 차원이 높아지면 샘플도 많아져야하는데 이를 충족하기가 어려움)
overfitting을 피하는 방법
**- Data augumentation
- Regularization
- Ensemble
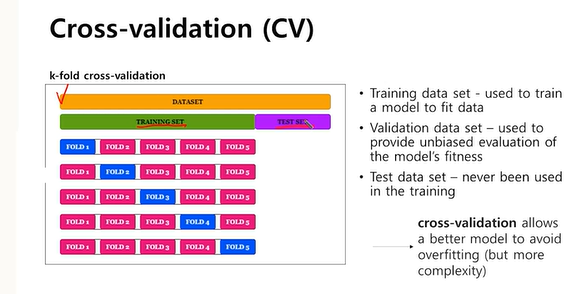
Cross-validation** - training set을 k개의 그룹으로 나눔. k-1개 그룹을 training set으로 활용, 남은 하나를 validation set으로 사용
- validation은 모델의 최적화에 사용
Part 2. Linear Regression model
regression은 모델의 출력이 연속적인 값, 레이블이 있는 데이터셋을 사용
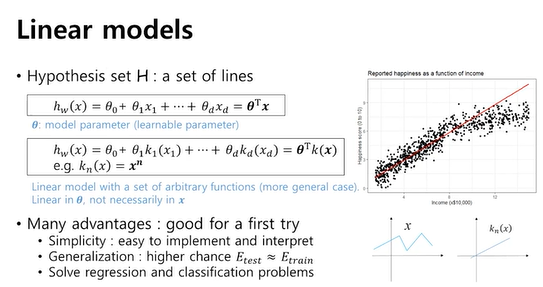
Linear models
- 선형 모델이라고 해서 입력 변수가 선형일 필요 x
- 입력 변수가 출력 변수에 어느 정도의 영향을 미치는지를 테스트해볼 수 있음
- regression이나 classification에 사용할 수 있음

-
입력 feature로부터 세타와의 linear combination을 통해 hypothesis 함수를 구성할 수 있게 됨
-
regression은 supervised leaning에 포함
-
y가 연속적인 값
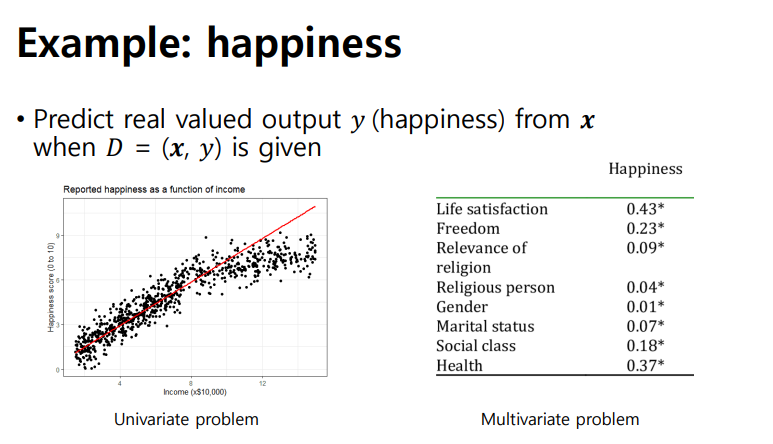
Multivariative problem
- 다양한 변수를 고려한 것
linear regression
- 주어진 입력에 대해 출력과의 선형적인 관계를 추론하는 문제
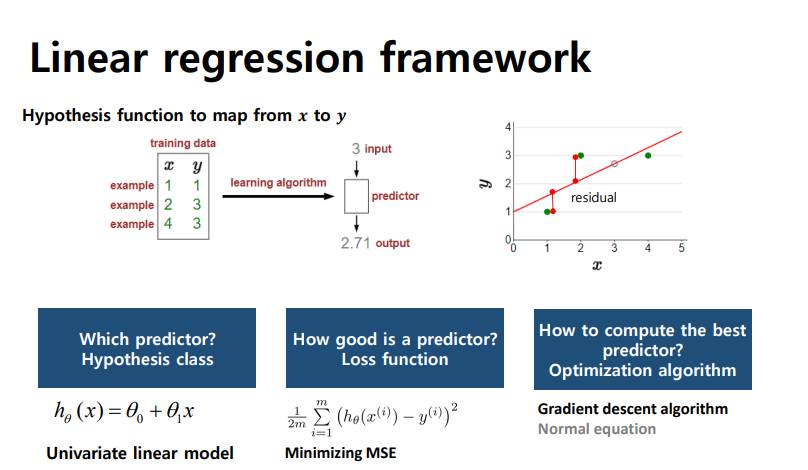
- (Hypothesis model) Univariate linear model(입력변수 x 하나) -> (Loss function) Minimizing MSE -> (파라미터 구함) Gradient descent이나 Normal equation
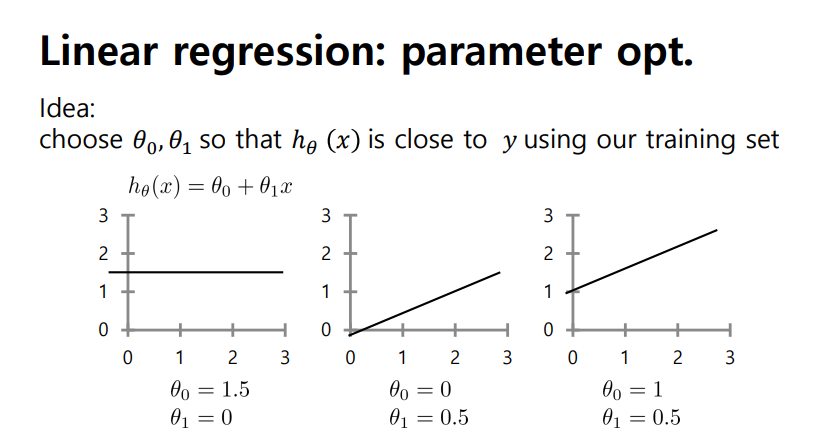
- 모델 파라미터가 달라짐에 따라 주어진 데이터에 fitting을 하는 과정에서 오차가 발생
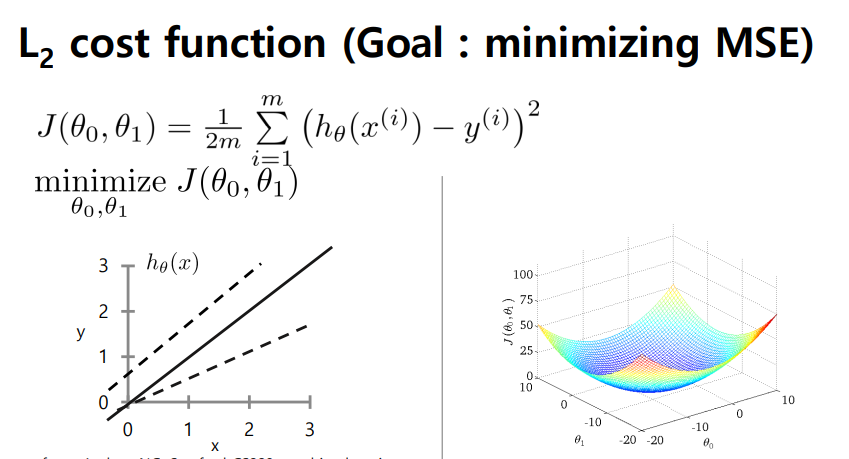
- 해당 loss function은 모델 파라미터에 의한 것, 해당 cost function을 최소화하는 파라미터 값을 찾아야 함
위 파라미터를 찾기 위해서는 파라미터 최적화
최적화 파라미터 세타는 cost fuction을 가장 최소화하는 것
- 입력 데이터는 matrix 형태

- X와 세타를 곱한 값 Score를 계산할 수 있음
- y와 score 차이를 계산하여 loss를 구할 수 있음
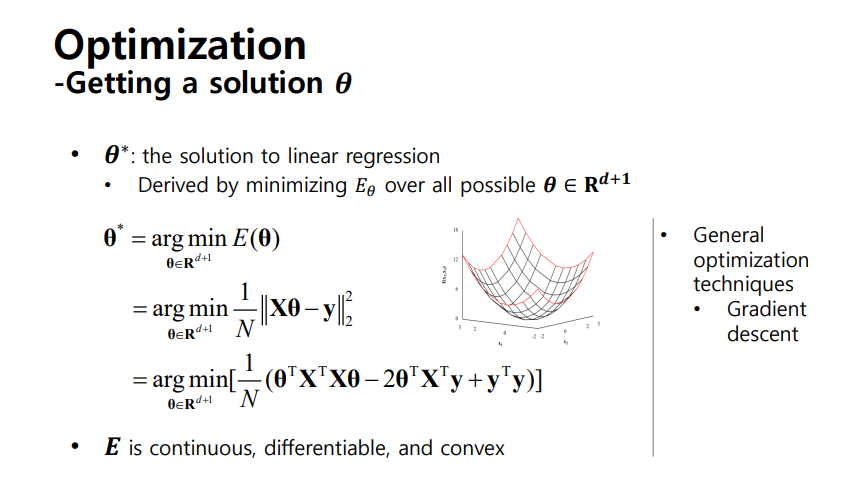
- 위 수식을 풀기 위해 세타에 대한 derivative term을 구한 뒤 0이 되도록 하는 세타 값을 구하면 최적화된 파라미터 값을 구할 수 있음
- 해당 과정을 Least Square Problem이라고 하며, 방정식을 Normal Equation이라고 함
- 이때 loss function이 differentiable하고 convex해야한다는 가정이 있음

- 그러나 normal equation을 통해 구하는 것은 최근 데이터 샘플 수가 늘어나는 경우 비효율적 -> matrix의 inverse를 구하기 어렵고, 없는 경우도 존재 -> 해결 방법: Gradient Descent
Gradient descent
- iterative하게 최적 파라미터 세타를 찾아가는 과정
- Gradient: 함수를 미분하여 얻는 term으로 해당 함수의 변화하는 정도를 표현하는 값

- error surface에서 최소인 포인트를 찾아가는 것이 목적, 값이 최소인 포인트의 특징은 gradient가 0
- gradient(함수의 변화도)가 가장 큰 방향으로 이동

- 알파는 스텝 사이즈(파라미터 업데이트 속도, 작으면 수렴하는데 오래걸림) 변화도 가장 가파른 방향으로 업데이트
- gradient descent algorithm은 경우에 따라 local optimum(지역적으로 최소지만, 전체 영역에서는 최소X)만 달성하기 쉬움

- 사전에 설정한 파라미터는 hyperparameter(step size 알파), gd를 통해 학습하고자 하는 파라미터 세타는 learnable parameter


- gradient descent는 반복적인 과정을 수행하여 해를 얻음
- normal equation은 1step으로 해를 구함, sample size가 커지는 경우 inverse matrix를 구하기 어려움
Part 3. Gradient Descent
- objective 함수를 최소화하는 세타 값을 구해야함


- step size 알파는 hyperparameter, 세타는 learnable parameter
Batch gradient descent
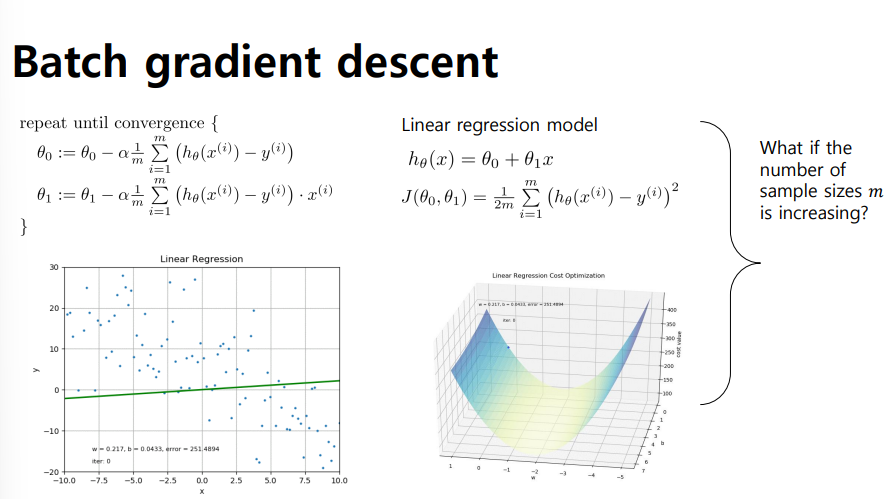
- 세타, 세타 제로를 업데이트하는 과정에서 전체 샘플 m개를 고려해야한다는 단점
Stochastic gradient descent (SGD)
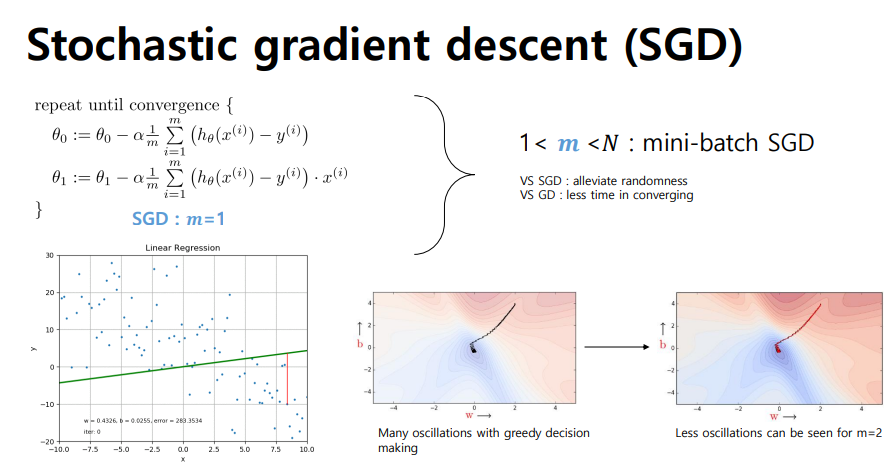
- 빠른 iteration, 샘플 하나마다 계산하기 때문에 노이즈의 영향을 많이 받음
- m을 1로 줄인 알고리즘
local minumum 문제를 해결하기 위해
-> Momentum: 과거의 Gradient가 업데이트 되어오던 방향 및 속도를 어느 정도 반영해서 현재 포인트에서 Gradient가 0이 되더라도 계속 학습을 진행할 수 있는 동력을 제공하는 것
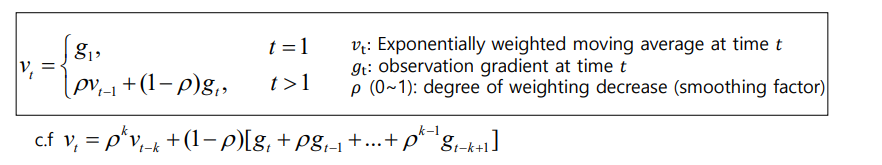
- Exponentially weighted moving average: 먼 과거의 값은 더 많이 적어짐, 비교적 가까운 과거는 조금 적어짐. saddle point나 noise point에 보다 안정적으로 수렴할 수 있도록 함
Nestrov Momentum
- 앞의 방식과 달리 gradient를 먼저 평가하고 업데이트
- lookeahead gradient step을 이용
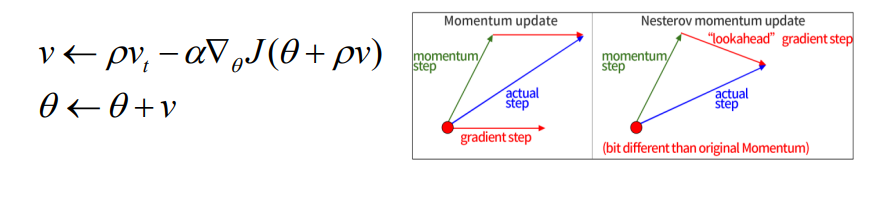
- 미리 momentum만큼 이동한 지점에서 lookahead gradient step을 계산
Adagrad
- 각 방향으로의 learning rate를 적응적으로 조절하여 학습 효율 높임
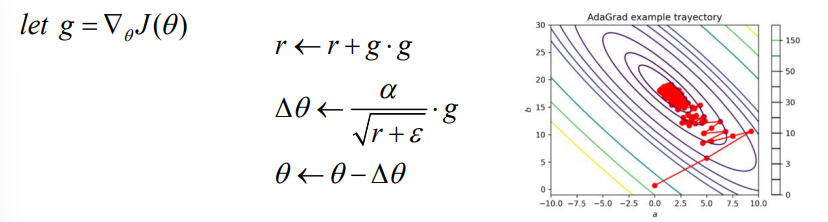
- 한 방향의 gradient가 크다는 것의 의미는 그 방향으로 이미 학습이 많이 진행되었다는 뜻
- gradient가 커지면 learning rate 낮추고 , gradient가 작아지면 learning rate를 키움
- accumulated gradient 값을 통해 learning rate를 조절하게 됨
- gradient값이 누적됨에 따라 learning rate 값이 작아진다는 단점
RMSprop
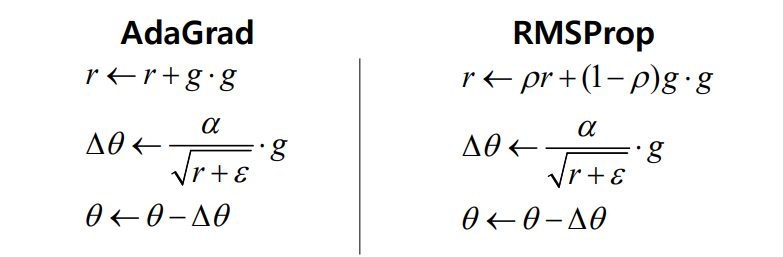
- gradient 값이 누적됨에 따라 세타값이 극단적으로 줄어드는 것이 아니라 어느 정도 완충된 형태로 학습 속도가 줄어듬
Adam (Adaptive moment estimation)
- RMSProp+Momentum 방식

Learning rate scheduling
- 학습 단계마다 수렴적으로 조절 가능, 하이퍼파라미터 알파를 조정
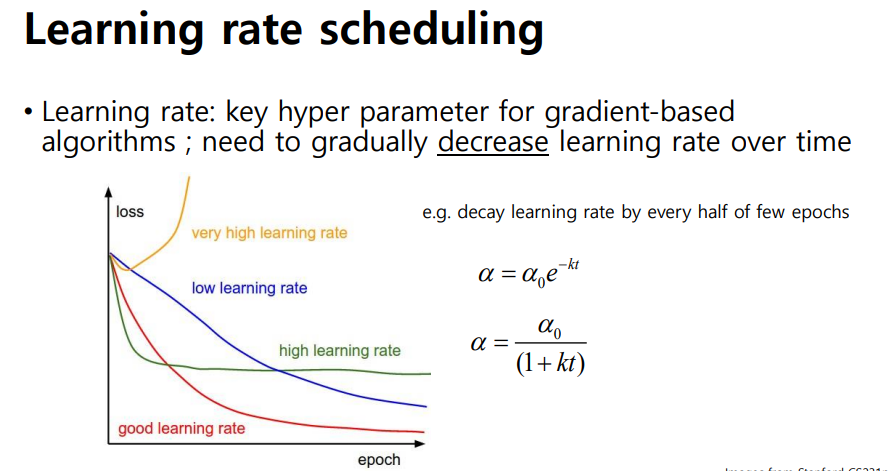
- 학습 과정마다 learning rate를 점점 줄여 나감
Model 과적합 문제
- model이 지나치게 복잡하여 학습 파라미터의 숫자가 많아서 제한된 학습 샘플에 너무 과하게 학습이 되는 것
- 입력 feature의 수가 많아짐 -> 파라미터 수가 많아짐 -> curse of dimesion problem에 의해 데이터 수가 많아짐 -> 데이터를 충분히 늘릴 수 없기 때문에 overfitting 발생
- 이러한 문제를 해결하는 대표적인 방법 -> Regularization
- 모델의 복잡도에 대한 패널티를 주어 overfitting을 피하도록 함
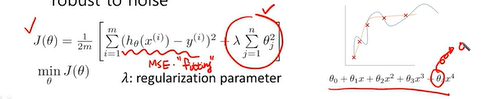
- 가능한 세타를 쓰지 않으면서 loss를 최소화 하게 됨 -> 특정 세타값이 덜 중요하면 0이 됨-> 파라미터 개수가 줄어듬-> 모델의 복잡도가 줄어듬
Part 4. Linear classification
- classification은 모델의 출력이 discrete한 값을 가지게 됨
- 입력의 카테고리를 분류하고 결정하기 위해

- hyperplane을 구해 데이터셋에 있는 positive 샘플과 negative 샘플을 linear combination에 의해 구분하는 것이 목적
multiclass classification
- target function f를 approximation하는 hypothesis h를 학습하는 것이 목표
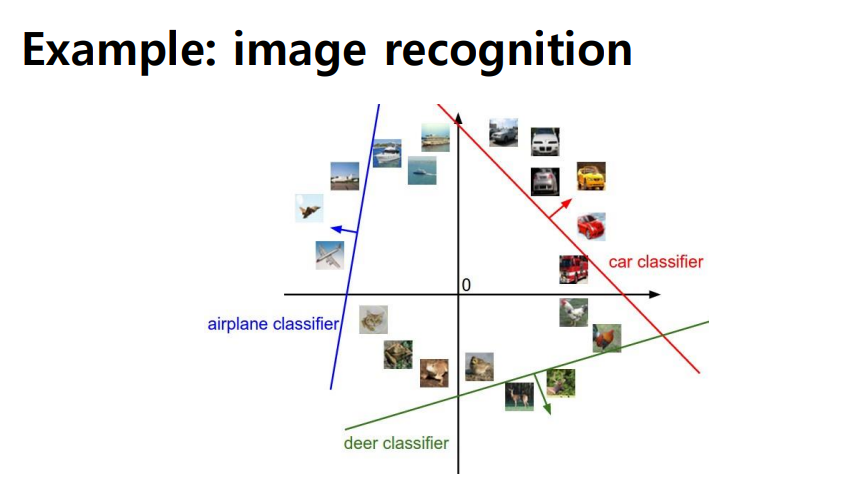
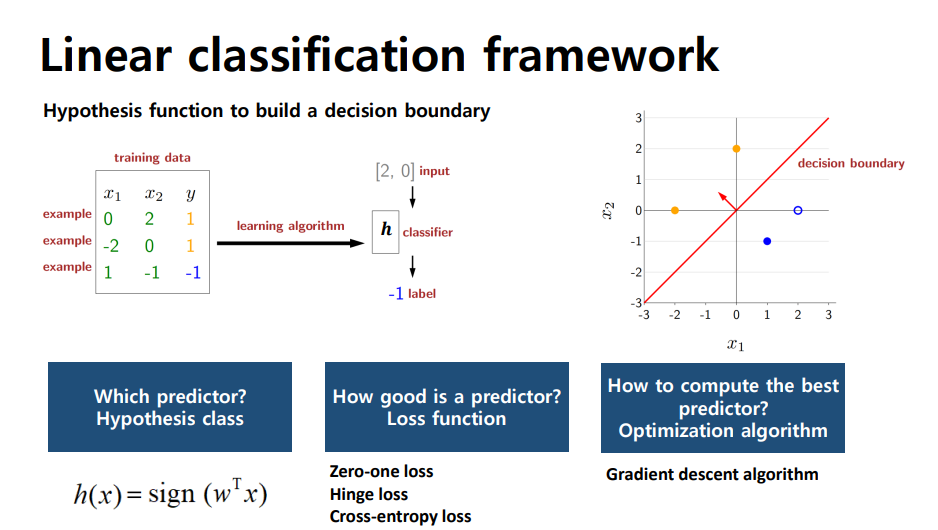



Zero-One Loss
- 내부의 logic을 판별하여 맞으면 0, 틀리면 1을 출력하는 함수
Score
-
모델이 classification을 수행하는 동안 classification을 통해 판별
-
score은 모델이 얼마나 confident한지 측정할 수 있음
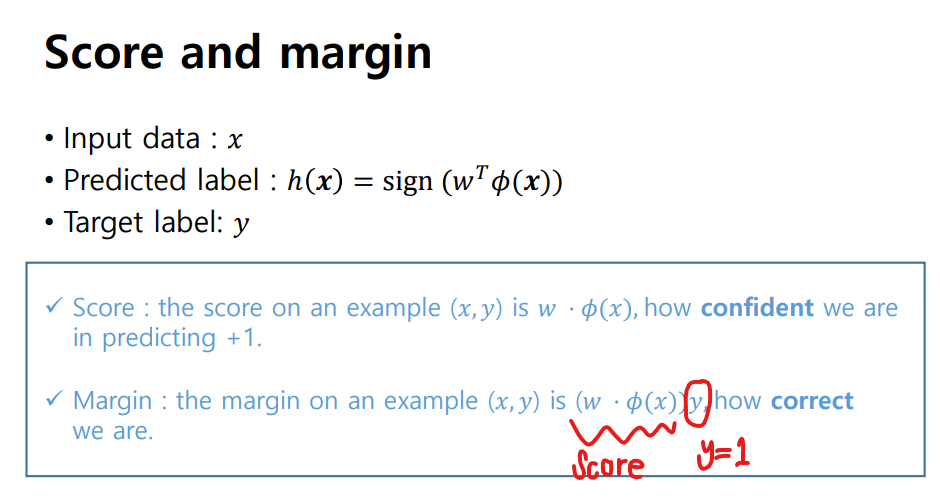
-
score가 +라면 모델의 prediction이 positive sample을 의미함을 알 수 있음, y가 1인 경우 정답을 맞췄다 볼 수 있음
-
score가 -1이고, y가 -1를 갖게되는 것은 negative sample로 판별하고, y가 -1이기 때문에 정답을 맞췄다 볼 수 있음
-
위 두 경우는 margin이 증가
-
zero one loss function을 gradient descent에 적용하려면 partial derivative term을 구해야함 -> 그러나 미분하면 gradient가 모두 0이 되어 버림
-
대신 Hinge loss를 사용
Hinge loss
- max값을 사용
- 정답을 잘 맞추고 있다면 강한 negative값을 가지게 되어 0과 max값을 비교하면 loss도 0을 가지게 됨
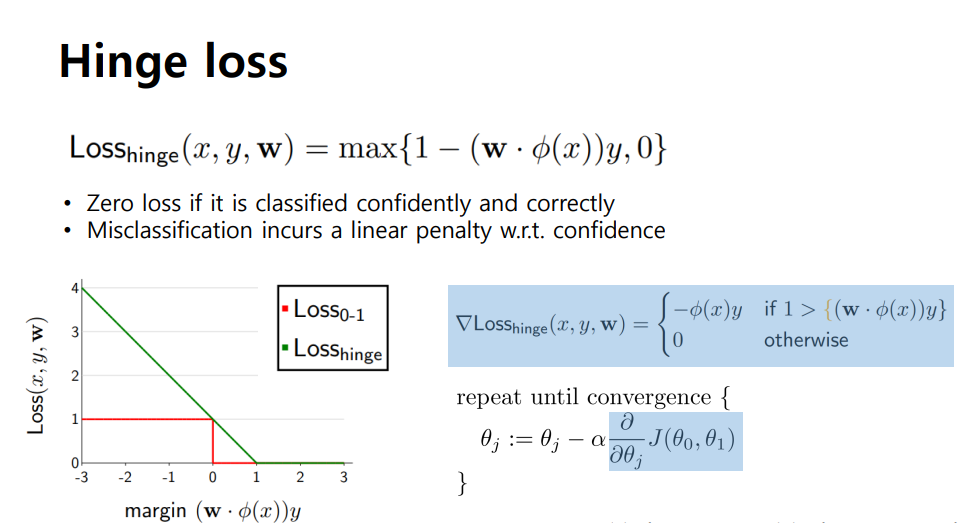
Cross-entropy loss

- 두 개의 서로 다른 pmf사이 dissimilarity
- 두 개의 서로 다른 pmf p와 q가 유사한지 아닌지에 따라 에러 정도가 바뀜, p와 q의 차이가 클수록 loss가 올라감
- score 값은 실수값인데 cross entropy는 확률값, 실수 값을 확률함수(Sigmoid)를 통해 mapping해야함
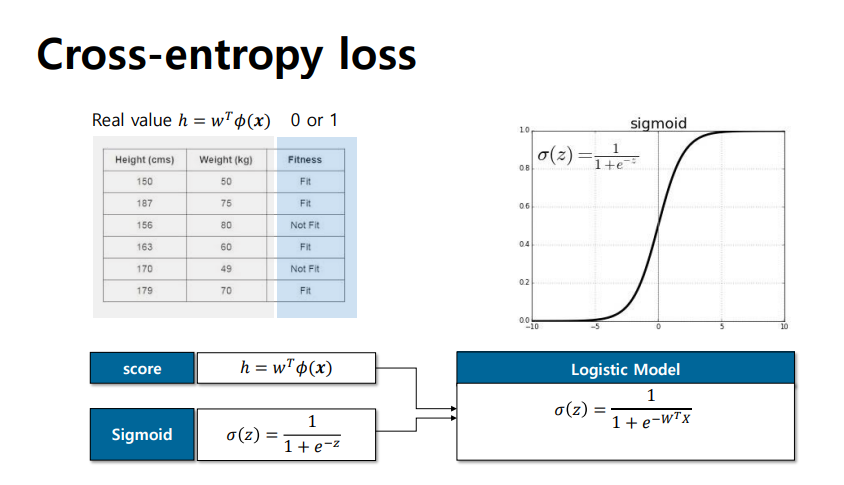
- 0부터 1로 실수값을 mapping한 형태 ->logistic model
- Sigmoid: 실수값을 0에서 1사이 값으로 mapping

linear classifier가 실제 gradient descent 알고리즘에 사용되는 방식

Multiclass classification
-
입력 이미지들의 카테고리를 맞추는 문제
-
n차원 space에서 입력들을 구분 가능한 hyperplane을 찾아냄

-
binary classification을 Multiclass classification로 확장하는 경우도 O
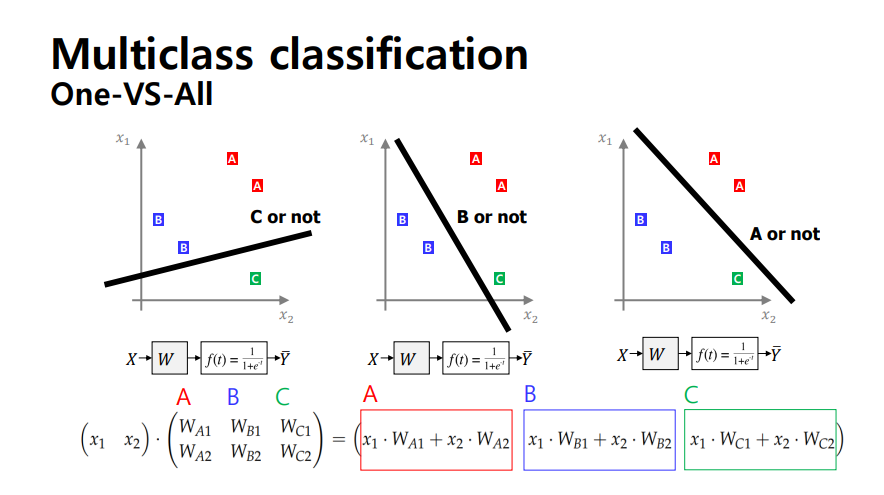
-
해당 문제에서 구한 score에 sigmoid 적용하여 확률값 얻을 수 있음
label 지정할 땐
One Hot Encoding
- 두 개의 서로 다른 표 사이에 거리를 가깝게 하면서 학습
- 각 벡터마다 1,0,0,1 등 해당 위치에 1을 signaling하면서 label의 정보를 기록하는 것
linear classification
-처음 시도하기에 적합한 모델
-단순, 구현 쉬움
-interpretability(해석 가능성) - 요소가 변할 때마다 전체 score가 어떻게 변하는지 확인하면서

linear classification에는 cross-entropy loss를 주로 사용, 확률값을 계산한 이후에 두 개의 서로다른 확률값의 dissimilarity를 계산해서 에러로 하여금 hyperplane을 학습
multi-classification 문제는 one-vs-all과 같은 방식으로 binary classification을 확장하여 사용 가능
Part 5. Advanced Classification
- hyperplane을 구성하는 model parameter가 w이면 hyperplane의 normal한 방향으로 hyper parameter w vector을 구성하게 됨
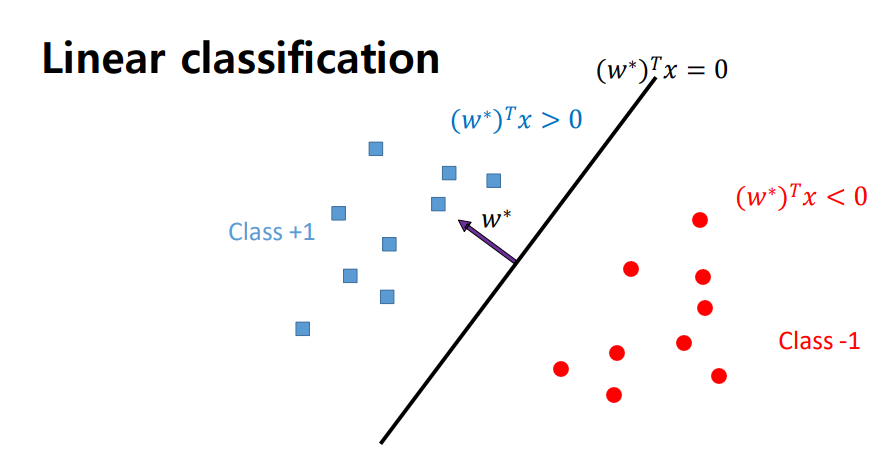
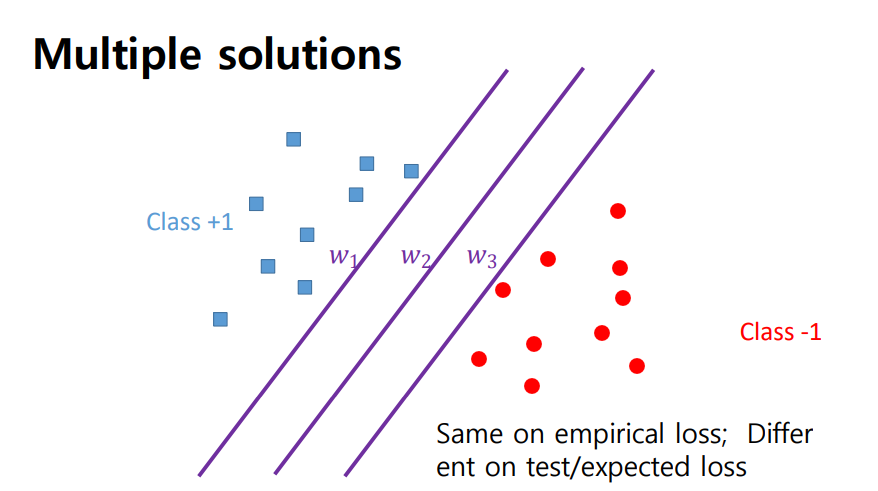
- 다양한 경우의 수가 존재하게 되고 각각 다른 기능을 수행하게 됨
- w1고 같이 모델을 만들었다면 positive sample 근처에 새로운 test data가 들어오게 되어도 negative sample로 분류할 가능성이 높음
- positive sample과 negative sample의 중간에 hyperplane을 긋는 것이 가장 이상적
SVM - margin을 정의
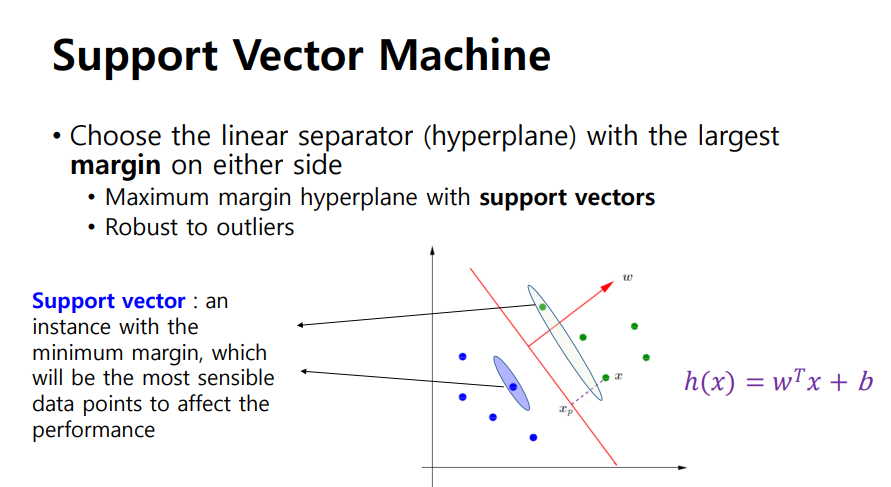
- Support vector: postive, negative와 가장 가까운 곳에 vector
- Support vector들 끼리의 거리를 최대로 늘리는 것이 목표
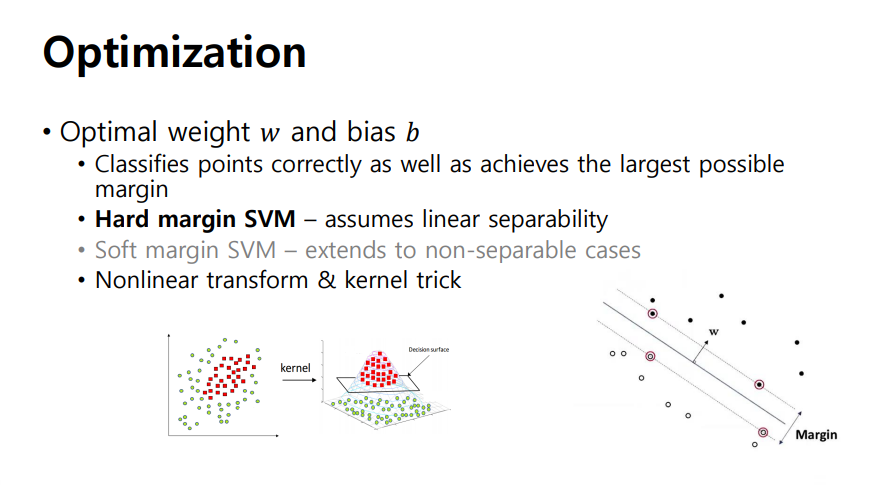
- Hard margin SVM : margin에 어떠한 샘플도 용인 X
- Sord margin SVM : margin 사이 어느 정도 샘플들을 용인
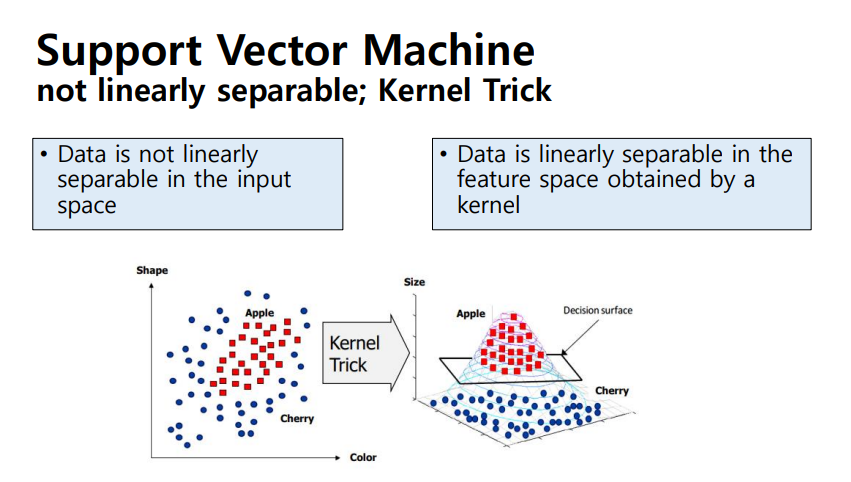
- nonlinear transform, kernel trick : 2차원 sample들을 고차원 sample들로 mapping하여 분할, 구분할 수 있음
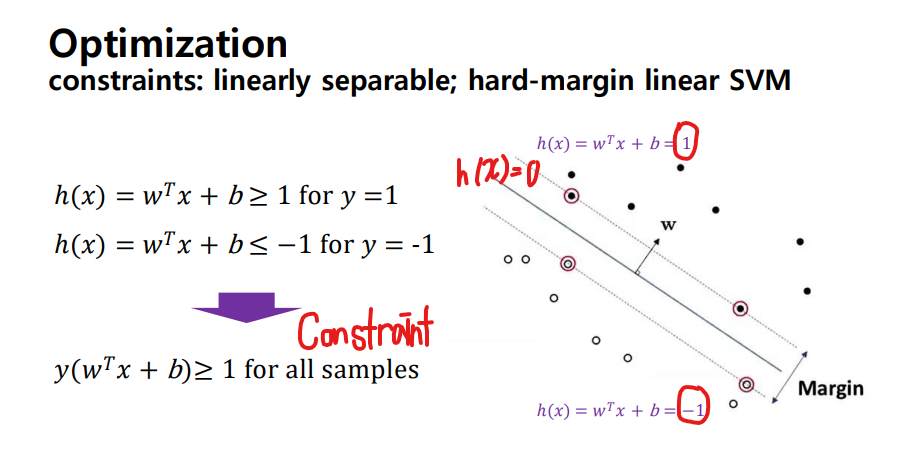

- w norm 제곱을 최소화하는 것이 설정한 optimization문제
- Kernal 함수 : linearly sepeable 하지 않은 data sample들이 있다고 할 때 그 차수를 높여 linearly sepable하게 만드는 과정
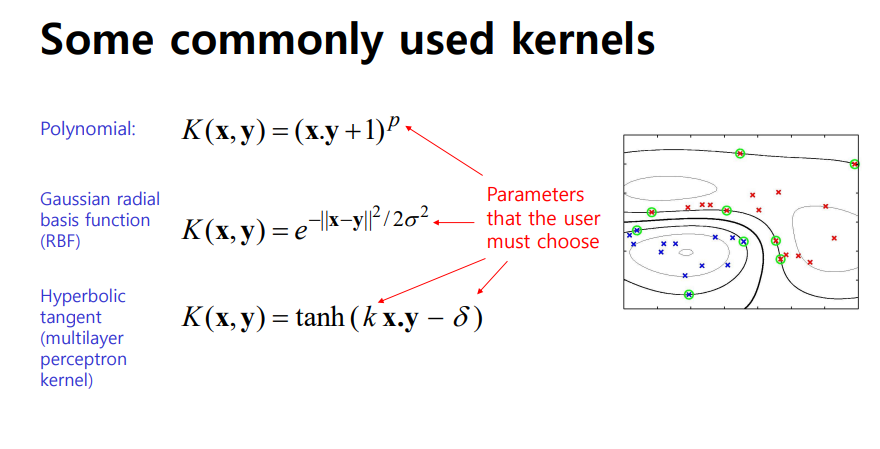
- kernel 함수의 종류 : Polynomial 함수, Gaussian radial basis function(RBF), Hyperbolic tangent(multilayer percetron kernel)->이러한 함수들에는 parameter을 설정할 수 있도록 구성되어 있음
ANN (Artificial Neural Network)
- Nonlinear Classification Model
- Deep Neural Network(DNN)의 기본
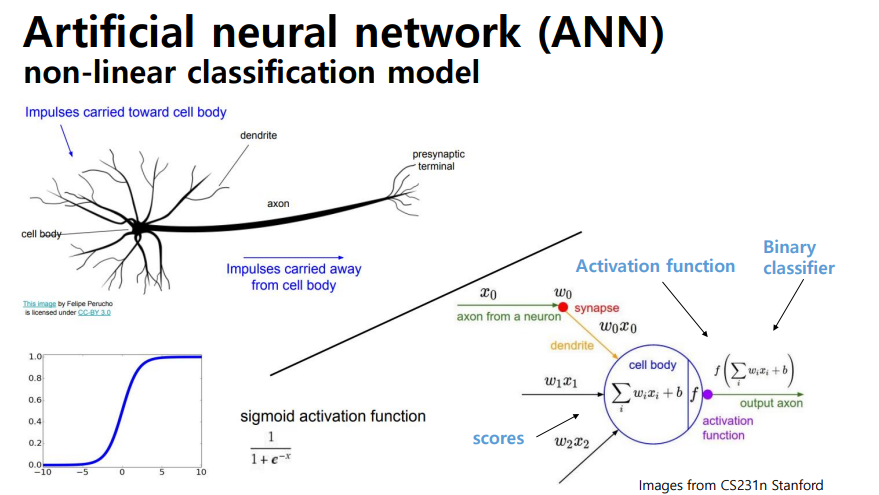
- 사람의 뇌 신경을 모사한 형태
- 이전의 노드에 w, w1과 같은 파라미터를 곱해 linear combination으로 score값을 만듬. 해당 score값을 activation fuction의 입력으로 받아 nonlinear한 관계로 mapping

- ANN에서 자주 사용하는 activation function -> sigmoid는 깊이가 깊어지면 효율적이지 못하기 때문에 주로 ReLU (미분하더라도 gradient term이 1)를 사용
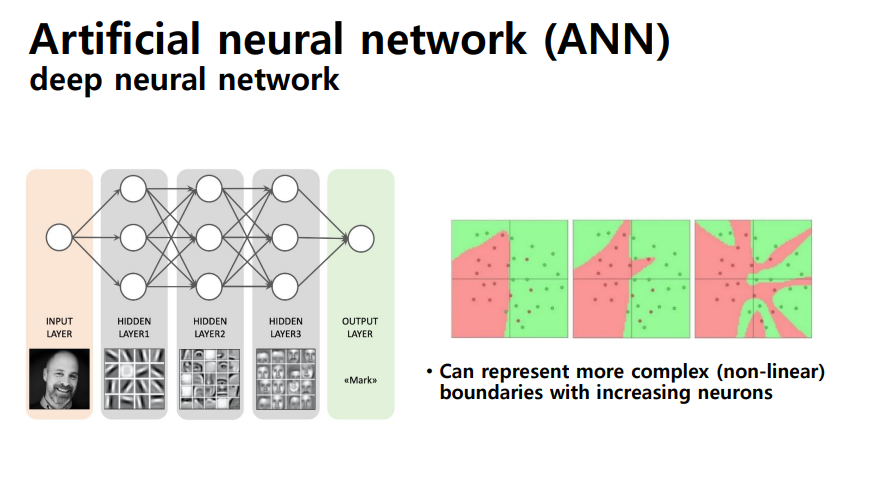
- ANN에 계층을 깊이 쌓게 되면 DNN이 됨 , multilayer perceptron
multilayer perceptron
- XOR problem (nonlinear problem)을 풀 수 있게 됨
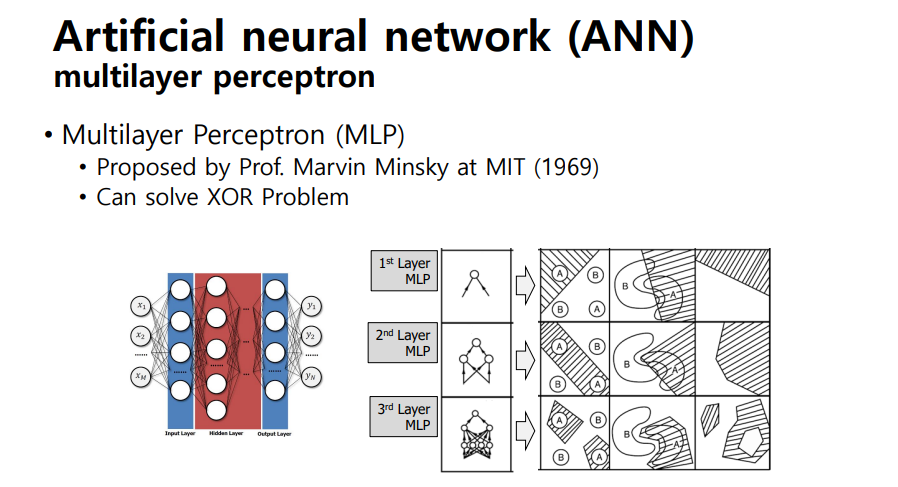

- ANN은 다차원, 고차원의 문제, 이미지, 비디오 등에 적용되어 Computer Vision, Image Recognition과 같은 연구에 활용되고 있음
- 학습 과정에서 Chain Rule을 통해 해결하게 되는데 이때 Gradient Vanishing Problem이 발생하게 됨, 깊어질수록 gradient 값이 줄어들어서 학습이 효과적으로 진행되지 않음

Convolutional neural network
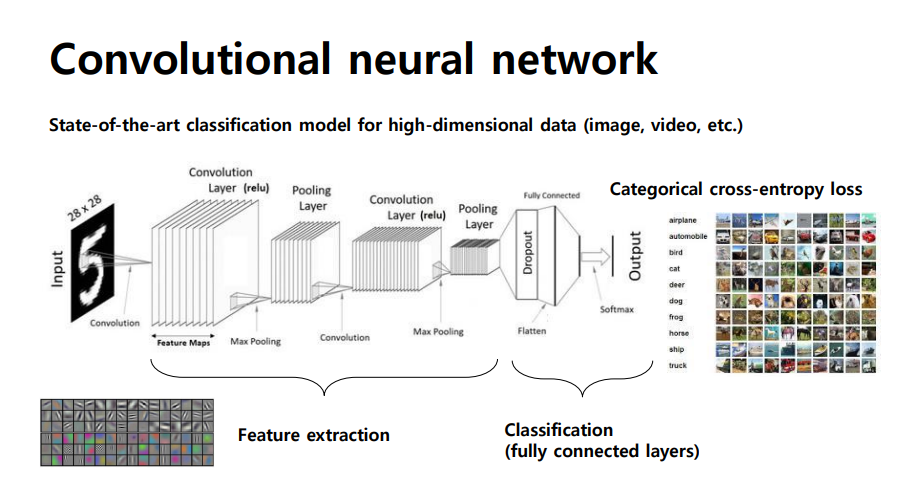
- ANN에서 고도화, 고차원의 신호를 효과적으로 다룸
https://www.deeplearningbook.org/
요약)
SVM
- hyperplane을 긋고, linear classification 가능, nonlinear 문제에도 Kernal transform과 같은 기술로 대응 가능
Neural network (NN) - non-linear classification framework, activation function에 의해 non-linear 문제를 풀 수 있게 됨
Part 6. Ensemble
Ensemble Learning
- 여러 다른 모델을 함께 모아 예측 모델의 집합으로 사용, 다양한 모델의 장점을 살려 예측 성능을 향상시킬 수 있음
- 이미 사용하고 있거나 개발한 알고리즘의 간단한 확장
- Supervised learning task에서 성능을 올릴 수 있는 방법
- 앙상블 방식: 머신러닝에서 알고리즘의 종류와 상관업시 서로 다르거나, 같은 매커니즘으로 동작하는 다양한 머신러닝 모델을 묶어 함께 사용하는 방식
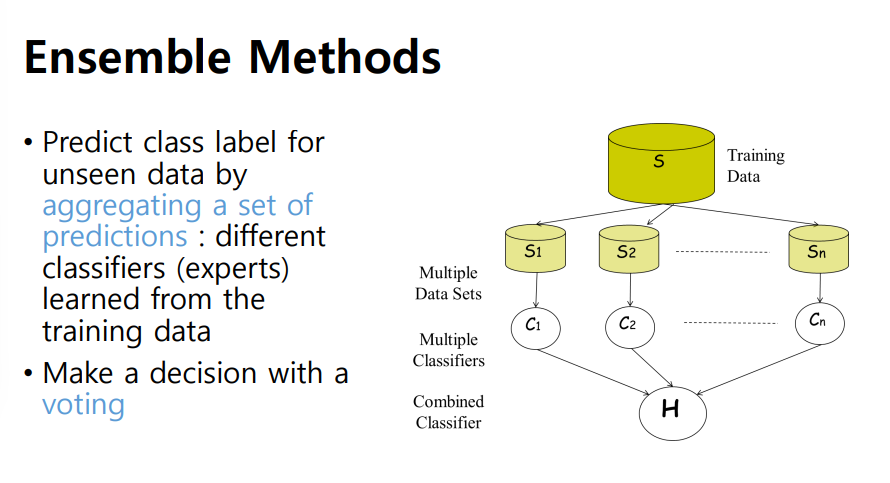
- 같은 모델을 여러 개 사용할 수도 있기 때문에 같은 학습 데이터를 사용하는 것은 지양해야함
- Ensemble을 구성하는 가장 기본적인 요소 기술은 bagging 과 boosting이 있음
장점
- 안정적으로 예측 향상, 쉽게 구현 가능, 모델 ㅍ라미터의 튜닝이 많이 필요없음 (독립적으로 수행되기 때문에)
Bagging (Bootstrapping+aggregating)
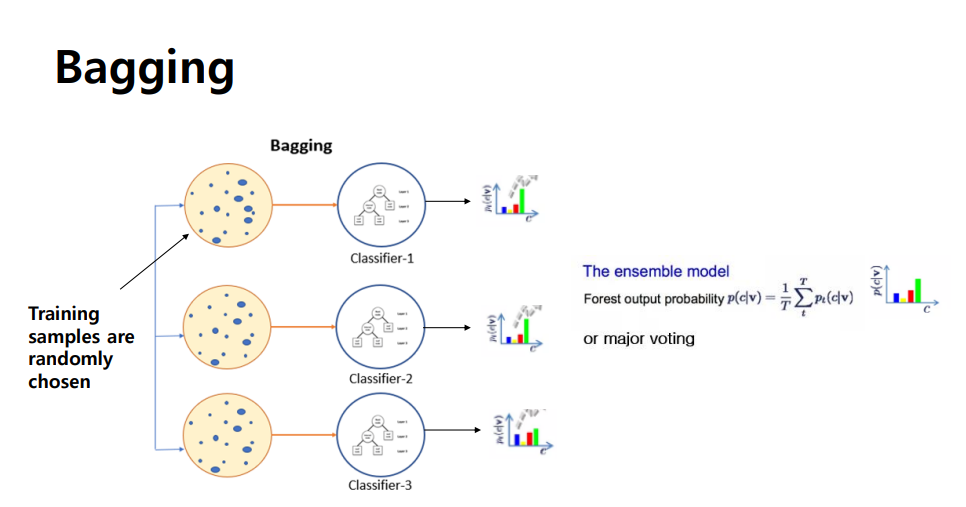
- 학습 과정에서 training sample을 랜덤하게 나누어 선택해 학습
- 각 샘플들이 병렬적으로 학습됨, 서로 영향을 미치지 않기 때문
- low variance를 제공하는데 효과적
- 샘플을 랜덤하게 선택하는 과정에서 data augumentation 효과를 가져옴
Bootstrapping
- 다수의 샘플 데이터셋을 생성해 학습하는 방식을 의미
- 이러한 과정을 m번 반복하게 되면 m개 데이터셋을 사용하는 효과가 있음 -> noise에 robust
- 같은 모델은 다른 샘플 데이터셋, 다른 모델은 같은 샘플 데이터셋을 사용해도 됨

Boosting
- Sequential하게 동작
- 이전 classifier의 결과를 현재 classifer의 성능을 향상시키는 데 사용
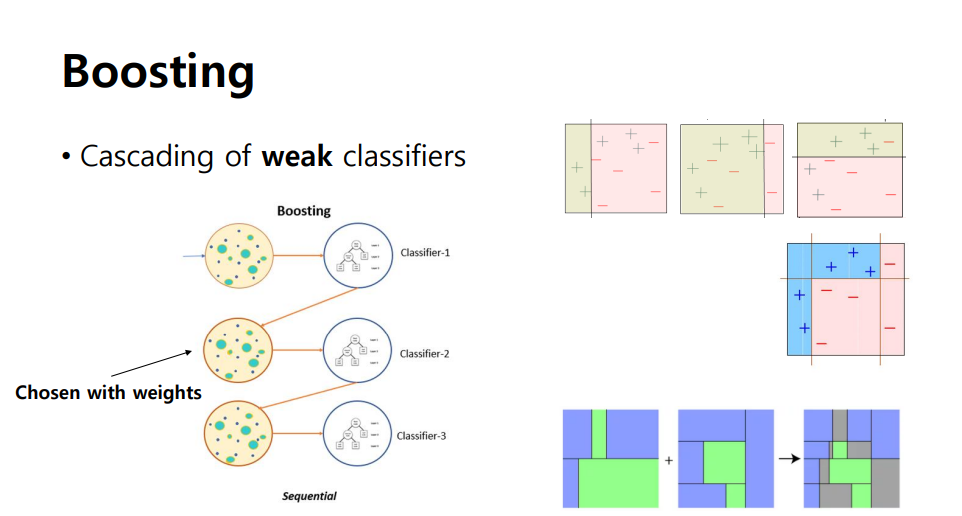
- Weak Classifier(bias가 높은 classifier, 모델 자체가 단순)의 Cascading
- 대표적인 boosting 알고리즘 -> Adaboost ( base classifier에 의해 오분류된 샘플에 대해 높은 가중치를 두어 다음 학습에 사용할 수 있게 함)
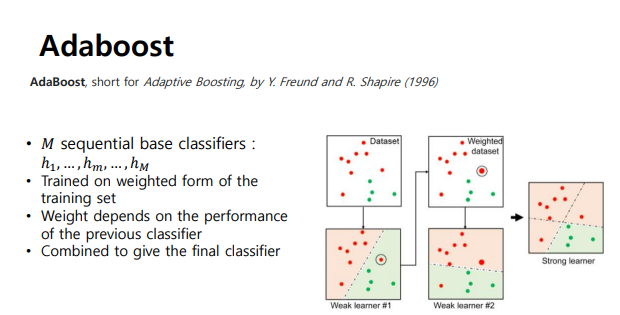
Random Forest

- Bagging과 Boosting을 활용, 대표적인 알고리즘
- descision tree의 집합
- 서로 다르게 학습된 descsion tree의 결과로 예측을 수행
Supervised learninig에서 모델의 성능 평가하는 방법
- 모델의 accuracy(정확도) 측정
- Confusion matrix: 각 경우에 대해 오차가 얼마나 있었는지 판단하는 방법
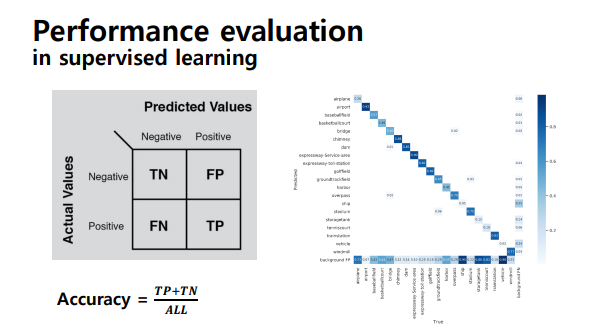
- 대각 성분 합한 값을 전체 값으로 나눠줌
- false positive: 실제로는 negative인데 positive로 판정한 경우
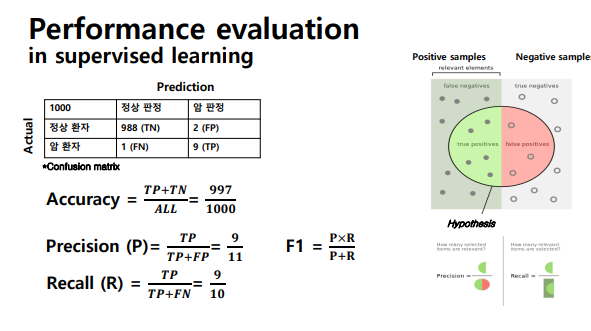
-Precision (정밀도): 모델이 true로 분류한 것 중에 실제 true인 것의 비율, 날씨 예측 모델이 맑다로 예측했는데, 실제 날씨가 맑았는지를 살펴보는 지표
-Recall (재현율) : 실제 True인 것 중에 모델이 True 로 예측한 것의 비율 , hit rate라는 용어로도 사용, 실제 날씨가 맑은 날 중에 모델이 맑다고 예측한 비율을 나타낸 지표 - unbalance 데이터의 경우 accuracy 말고도 precision과 recall값을 살펴봐야 성능을 제대로 확인할 수 있음
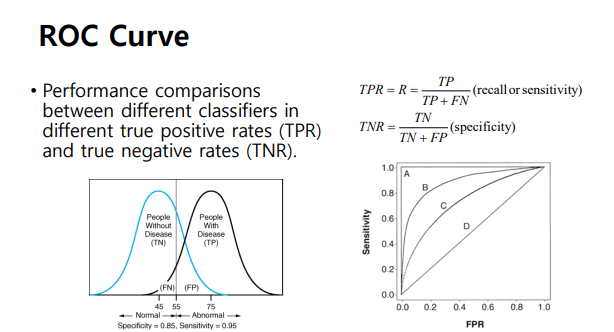
ROC Curve
- 서로 다른 classifier의 성능을 측정하는 데 사용하는 curve
- 가로축은 FPR (1-TPR) , 세로축은 Sensitivity
- 여러 ROC Curve를 그렸을 때 왼쪽 상단에 있는 커브일수록 성능이 좋음
Supervised learning의 예제들
- Object detection/localization -> R-CNN

- SNL, LSTM(출력)- 단어의 연속적인 문장을 구성
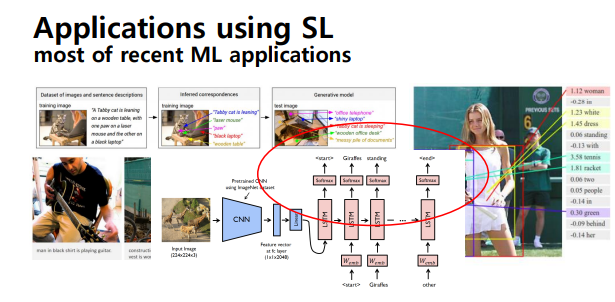
- 주어진 입력에 대해 가장 잘 description하는 문장을 생성

- Semantic segmantation
- Face detection
- Face recognition, pose estimation
- Super resolution
