
BigQuery란?
- 대용량 데이터 셋(최대 몇 십억 개의 행)을 대화식으로 분석할 수 있는 웹 서비스
- 대규모 데이터 저장 및 분석 플렛폼으로 일종의 데이터 웨어하우스 (Data Warehous)
- Data Warehous : 축적된 데이터를 모아서 관리하는 곳
BigQuery 구성
- Project : 데이터를 담는 최상위 개념으로, 하나의 프로젝트에 여러 개의 데이터 셋이 포함된다.
- Dataset : RDB에서의 DataBase 개념으로, 하나의 데이터 셋에 여러 개의 테이블이 포함된다. 주어진 클라우드 프로젝트 내에서는 BigQuery 데이터 셋이 고유하다.
- Table : RDB에서 테이블과 동일한 개념이다. 지정된 데이터 셋 내에서 BigQuery 테이블은 고유하다.
- Job : BigQuery 상의 모든 명령어를 의미한다. BigQuery가 사용자 대신 load data, export data, query data, copy data를 실행하는 작업이다.
BigQuery 특징
- 클라우드 서비스이므로 설치 및 운영이 필요 없다.
- 로그인 후 SQL 수행만 진행하면 된다.
- SQL 언어와 호환이 된다.
- 클라우드 스케일의 인프라를 활용하므로 대용량 기반의 빠른 성능을 지원한다.
- 다수의 CPU, 하드디스크, 네트워크를 사용할 수 있다.
- 데이터 복제를 통해 안정성이 보장된다.
- 3개의 복제본이 서로 다른 데이터 센터에 분산되어 저장된다.
- Batch(배치)와 Streaming(스트리밍)을 모두 지원한다.
- 한 번에 데이터를 로딩하는 배치 기능과 실시간으로 데이터를 입력할 수잇는 스트리밍 기능을 제공한다.
- 주문형 분석 가격 책정 (공식문서)
- 1번의 쿼리를 실행(주문형)할 때 비용은 1TB 당 $5.00의 과금이 부과된다.
- 8,800개의 CPU와 3,600개의 디스크를 사용하는 대규모 인프라를 활용하여 1,000억 개의 레코드에 대한 질의를 약 30초 만에 수행한다.
- OLAP(OnLine Analytical Processing: 온라인 분석 처리)로, 강력한 데이터 분석을 수행할 수 있다.
- SELECT에 최적화 되어 있다.
BigQuery의 SQL 사용
- BigQuery는 Legacy SQL과 Standard SQL을 모두 제공한다.
- Legacy SQL은 초기부터 사용된 문법이고, 2.0 버전 이후에는 Standard SQL이 지원한다.
- 초창기에는
#standardSQL을 선언해야 BigQuery의 표준 SQL과 호환이 됐었다. - 날짜가 partition 방식으로,
_PATRITIONTIME으로 지정해야 한다.
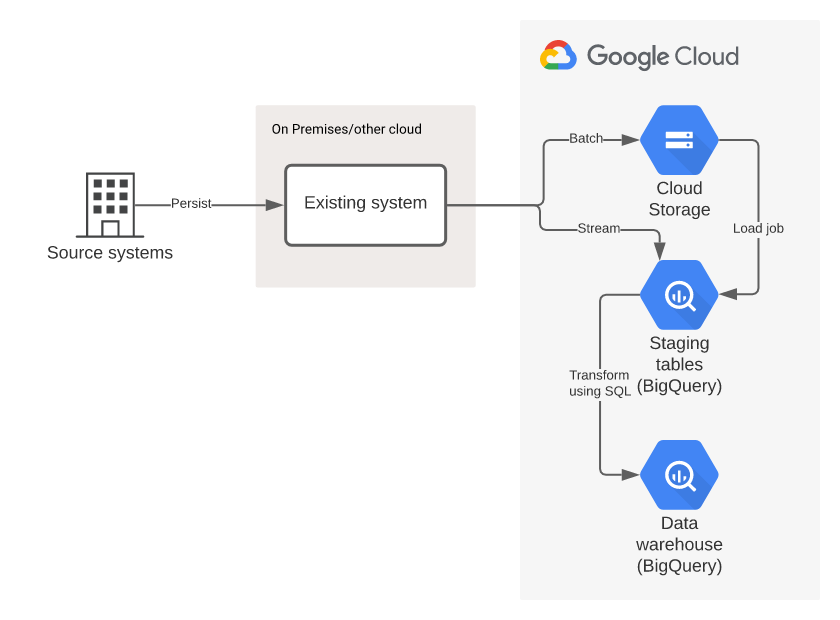
BigQuery의 ETL 순서도
ETL 순서도(절차)에 따라 그린 data processing diagram(flow diagram)
RDB vs. BigQuery
데이터 규모, 성능(제한적인 update,delete)에 대해 자세히 비교 구분 해본다.
- BigQuery: chunk 단위, 블럭단위로 dump, upload 된다.
- 실시간 BigQuery의 조건 : 최대 소요 시간/chunk 단위 용량(size)
- 실시간의 예시는 kafka에서 flink로 listener가 실시간으로 청취하는 것.
