이 논문은 open ai에서 나온 논문이고, RETRO를 제안한 논문입니다.
Intro
- large data 기반으로 학습하여 performance를 높인 연구가 많다
- 본 논문은 computation resource를 증가시키지 않으면서
- 기존 DB의 retrieval을 통해 massive text에 대한 information, prior와 같은 knowledge를 학습하는 방식 사용
- retrieval transformer (RETRO)
- input을 chunk단위
- reetrieval 모델로 embedding vector 얻음
- 본 모델의 cross encoding에 사용
- contrinbution
- RETRO
- 모델과 DB 사이즈 키워서 성능 올릴 수 있다
- train/test dataset을 어떻게 evaluate 할 것인지 : BPB
Method
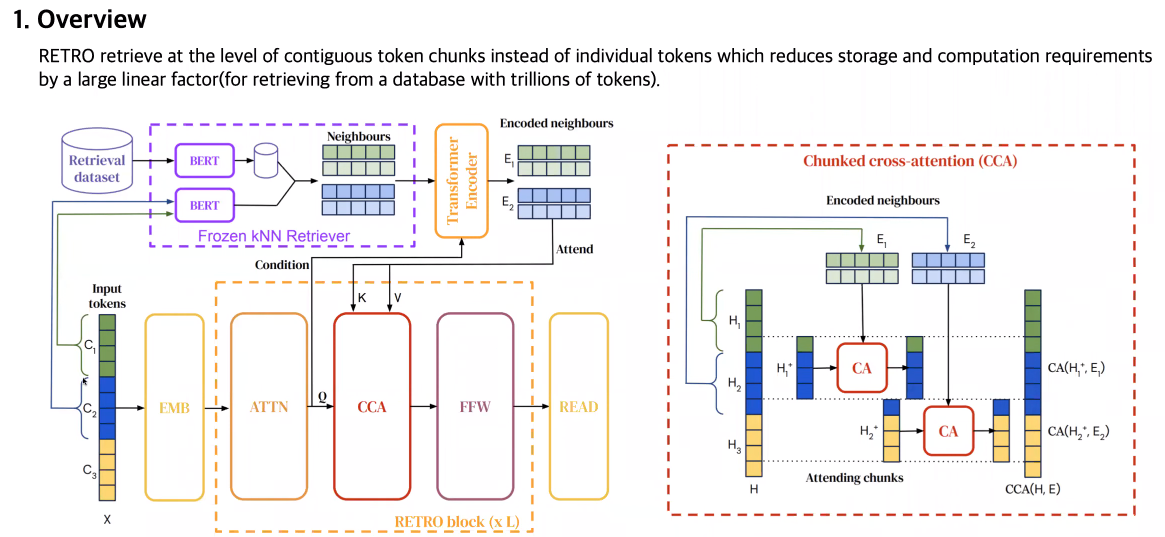
- input token을 chunk로 자름(특정 사이즈)
- retrieval model(neighbor embedding)
- chunk 단위로 encoding 됨
- 맨 마지막 제외하고, Cross attention을 chunk 단위로 함.
- retrieval은 pretrained BERT 기반으로 neighbor search
- training dataset : massive text, jaccard similarity
- 학습 : auto-regressive
- RETRO는 encoding된 feature를 attended 하고, retrieval된 embedding과 함께 cross attention하고, feed forward해서 구함
- 기존의 cross, self-attentionn 부분을 chunked cross attention으로 바꿈
- quantifying data leakage exploitation
- training과 retrieval dataset 간의 누수
- BPB가 threshold를 넘으면 제외하기
- training dataset과 유사한 값은 날림
- 차이
- token, prompt 기반 → chunk
- retrieval : LSTM, Transformer 사용 → BERT 사용
- retreival integration : CA, Extrative QA → CCA
- 실험
- dataset : C4, Wikitext, Massive Text
- 비교군 : Jurassic, Gopher과 비교, 몇몇만 improved
- perplexity↓,BPB↓
- 결론
- retreival 모델로 많은 데이터 기반으로 별도의 computation 없이 성능 향상
- 모델 사이즈를 키우거나 데이터 셋 크기 키울 수록 성능 향상
이게 지금 뭘 한거지?
: QA 테스크와 같은 곳에 chunk단위로 나누고, 외부 knowledge 이용하여 성능 높임
- 토큰 여러개가 한 묶음인 chunk단위로 retrieval attention 진행
- chunk attention이 진행되는 CCA라는 구조가 Decoder에 포함
- chunk 간 일부 overlap을 진행한 결과와 retrieval 결과를 임베딩하여 decoder에 입력
- 외부의 Knowledge base(KB)의 도움을 받게된다면 비교적 적은 수의 파라미터로도 언어 모델의 성능을 크게 향상시킬 수 있다는 발상
- 해당 텍스트의 BERT 임베딩과 L2 거리가 nearest neighbor인 k개의 key들을 이웃으로 간주
- MassiveText를 전부 사용한 경우에 valid 성능이 큰 폭으로 오르는 것은 위에서 언급한대로 train 데이터셋과 데이터가 겹치는 dataset leakage 현상

2023년 기록, 2023년 계획 : 연구, 블로그, 컨트리뷰션