PR-380: Textless Speech Emotion Conversion using Discrete and Decomposed Representations
PR12 Season4 정리
목록 보기
2/6
- task는 gt로 prompt를 주면 이어서 자연스럽게 AI가 생성, 비언어적 표현, 웃음소리도 포함해서
- textless nlp : 장점으로는 발화자의 감정 실림(비언어적 요소)
- GSLM : 발화
- encoder : contrastive learning, HuBERT(deep cluster로)
- discretize
- decoder : gan 기반, HiFiGAN
- HuBERT : 스피치 language modeling
- MFCC를 clustring - pseudo label로 supervision줘서 self-supervised learning
- encoder : speech signal을 self supervise learning으로 잘 represent함
- HiFiGAN : speech synthesis, 카카오 엔터프라이즈, vocode sota
- generator, 복수개의 discriminator
- sound의 특징으로 다양한 주기 패턴을 갖는다는 것 때문
- fundamental frequency, harmonic frequency가 basis로 존재하여 그것의 조합으로 구성됨
- multi-period discriminator
- MRF : residual connection 복수개, 다양한 resolution에 대한 정보 취합하고, 마지막에 summation
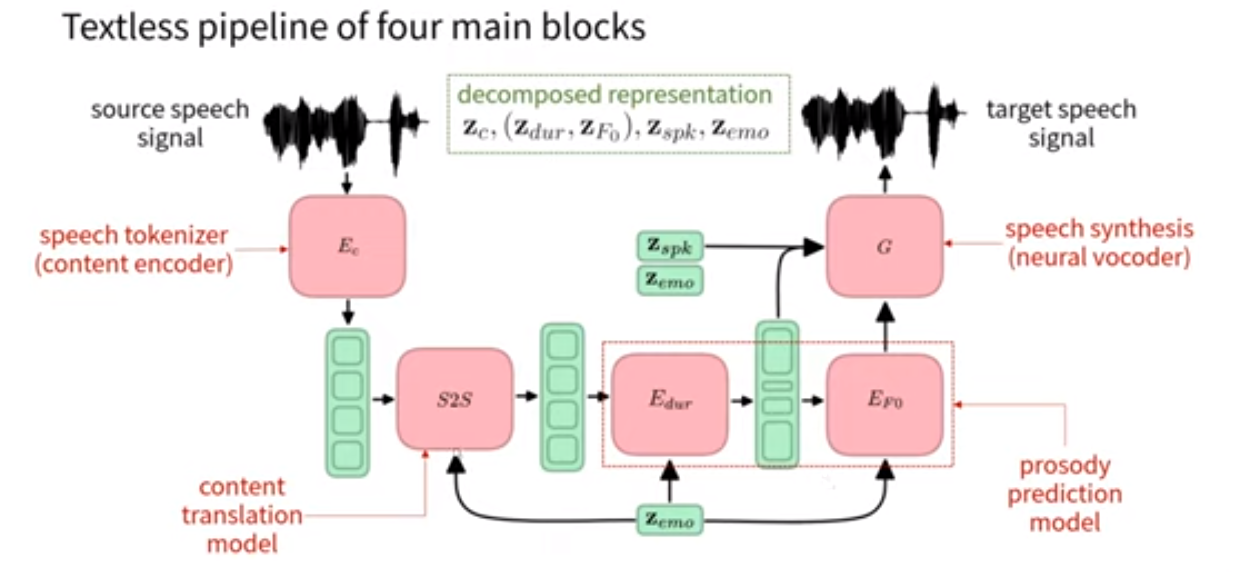
1. Phonetic : content extraction (HuBERT)
- text를 거치지 않은 speech signal로 ssl 학습, 비언어적 요소 다 들어있음
- audio waveform - discretized representation
- nlp쪽 기술들이 많이 사용
- wave form x →(ft) z' →(clustering) quantized unit z_c
- audio waveform - discretized representation
2. Speaker representation(speaker id)
- 마지막 decoder에 input으로 들어감, 중간에도 condition으로 사용됨
- utterance를 DNN을 거쳐서 d vector로 추출하여 lookup table 만듦, 이것으로 speaker를 구분
3. emotion label representation
- EmoV의 5가지 감정
4. Unit Translation : 감정 translation
- target emotion을 input으로 주면, target unit을 예측
- Bart와 같은 구조
- encoder 는 bert처럼 bidirectional
- decoder 는 gpt처럼 autoregressive
- 둘 다 감정별로 나눠서 학습
- 나눠서 학습했을 때 lexical한 info는 유지하면서 감정 translation 잘됨
5. Prosody prediction
- 운율 : 성조, 강세, 리듬
- duration과 pitch(fundamental frequency) 예측
- duration prediction, F0 prediction
- frequency bin을 만들어서 f0 candidate으로 표현
- YAAPT로 pitch extract하고 normalize 해서 GT로 사용
6. HiFi-GAN으로 speech synthesis
- reconstruction loss : output과 gt의 melspectrogram간의 loss
- discriminator loss : layer-wise representation을 l1 distance로 최소화
실험
- 실험에서는 LibriSpeech, Blizzard 2013, EmoV로 pretraining
- 비교군 text to speech model : Seq2seq-EVC, Tacotron2
- Evaluation metric
- eMOC : 감정분류
- MOC (Mean opinion score) : 얼마나 자연스럽게 들리나
- ASR based로 WER, PER
결론
장점
- speech emotion conversion을 spoken language의 translation problem으로 해결
- discrete한 speech representation으로 NLP advance leverage
- Nonverbal한 요소들을 textless로 다 모델링하여 생성
- 최종적인 평가에서는 baseline보다 좋음
단점
- not end-to-end training(HuBERT, Vocode)
- parallel corpus dataset이 많이 필요
- Scalability를 위해 lookup table이 아니라 좀더 genralized된 버전으로 speaker representation을 관리할 필요가 있음
- 일단 이 논문은 스피치의 감정을 바꾸는 태스크를 스피치의 언어를 바꾸는 문제처럼 해결한 논문.
- 모델을 보자면, speech의 representation 추출은 HuBERT로
- HuBert는 text를 거치지 않은 speech signal로 ssl 학습, 비언어적 요소 다 들어있음
- HuBert도 speech representation을 discrete하게 만들기 때문에 language랑 비슷한 특성을 가지게 함.
- 거기에 추가할 감정과 personal한 infomation 등을 추가한 후에 hifi gan이라는 vocoder sota model을 이용하여 speech synthesis.
- 이 논문의 novelty는 textless로 모델을 학습한 것과 HuBERT를 이용해서 speech representation을 discrete하게 해서 Language와 비슷한 특성을 가지게 했다는 것.

2023년 기록, 2023년 계획 : 연구, 블로그, 컨트리뷰션