Contrastive Decoding: Open-ended Text Generation as Optimization
Abstract
- maximum probability is a poor decoding objective for open-ended generation, because it produces short and repetitive text.
- On the other hand, sampling can often produce incoherent text that drifts from the original topics.
- The contrastive objective returns the difference between the likelihood under a large LM and a small LM, and the constraint ensures that the outputs are plausible
- CD is inspired by the fact that the failures of larger LMs (e.g., repetition, incoherence) are even more prevalent in smaller LMs, and that this difference signals which texts should be preferred.
Intro
-
Contrastive Decoding works because many failure modes of language models are more under smaller LMs than under larger LMs.
-
contrastive decoding generates outputs that emphasize the best of the expert LM and remove its amateur tendencies.
-
we find that better performance is achieved when the scale difference between expert and amateur is larger
-
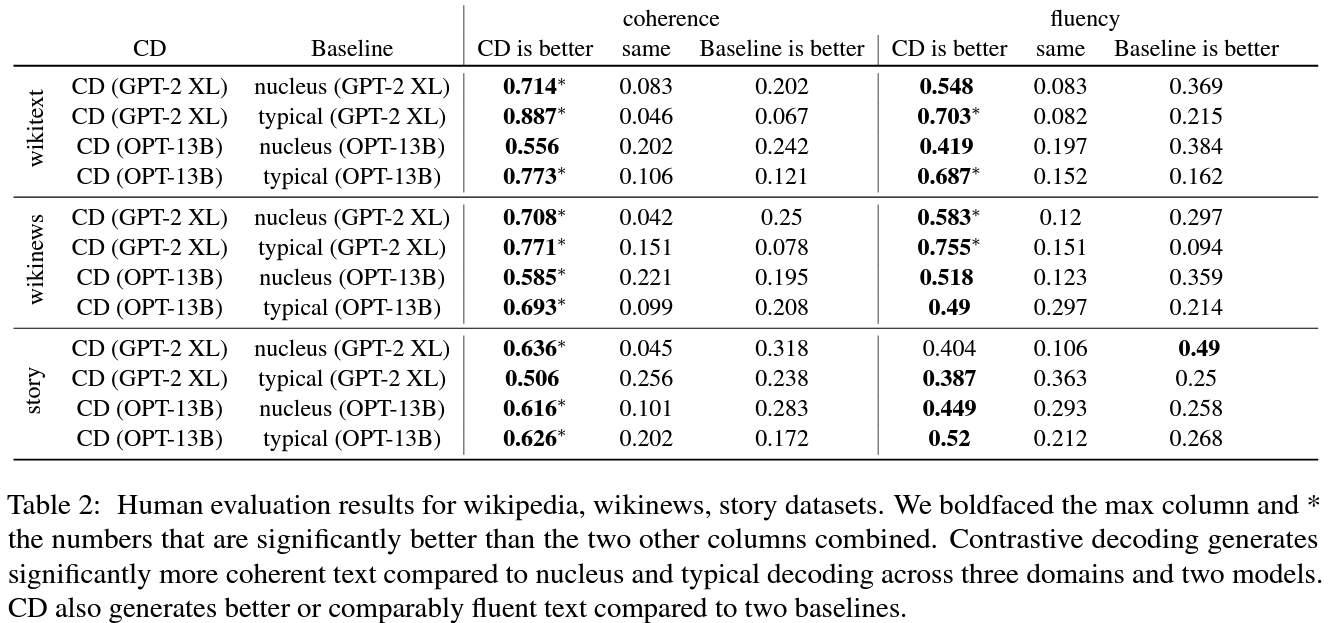
Compared to four decoding baselines (nucleus sampling, top-k, typical decoding and SimCTG) our contrastive decoding method signif icantly improves the coherence of generated text, and improves or maintains the same fluency levels, according to both human evaluation and automatic metrics.

Contrastive Decoding
Contrastive Decoding

- However, amateur LMs are not always mistaken: small language models still capture many simple aspects of English grammar and common sense (e.g., subject verb agreement).
- Thus, penalizing all behaviors from amateur LMs indiscriminately would penalize these simple aspects that are correct (False negative), and conversely reward implausible tokens (False positive).
Adaptive Plausibility Constraint
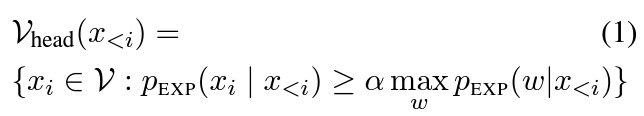
- exploits the confidence level of the expert LM to restrict the effect of the contrastive objective when the expert LMis highly confident
- This adaptive plausibility constraint corrects for both false positive and false negative failures of the contrastive objective
- To handle the false positive problem, Vhead filters out low probability tokens and only keeps high probability tokens in the candidate pool. (hallucination, low probability 없앰)
- the correct token that achieves high probability under both amateur LM and expert LM may receive a low score under the contrastive objective.
- Our constraint keeps as few as one token in the candidate pool when the expert is highly confident about this token
Full Method
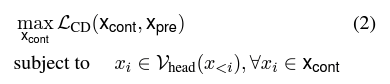
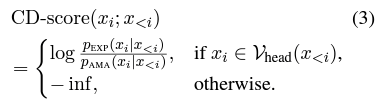
- beam search to optimize CD-score, by first filtering tokens based on plausibility constraints Vhead(x<i), eliminating tokens that fail to achieve sufficiently high probabilities under the expert LM
- we score the remaining tokens based on the amount of contrast they demonstrate
Choice of Amateur
- Scale
- smallest model
- Temperature
- applying a high temperature (τ > 1) to the amateur LM results in flatter distributions; applying a low temperature (τ close to 0) highlights the mode of the amateur distribution, which is more prone to errors (e.g. repetition)
- Context window
- We can also weaken capacity by restricting the context window of the amateur LM
- By conditioning the amateur LM only on partial prompts, the coherence of the amateur LM is weakened, and contrastive decoding produces more coherent text by highlighting the coherence nature of the expert LM
Special Cases of Contrastive Decoding
- If we use the same LM as both amateur and expert and restrict the context window of the amateur LM, our method is equivalant to the MMI decoding objective
Experimental Setup
- Diversity: A low diversity score suggests the model suffers from repetition
- MAUVE: A low diversity score suggests the model suffers from repetition
- Coherence: cosine similarity between the sentence embeddings of prompt xpre and generated continuation xcont, pre-trained SimCSE sentence embedding
- Human Eval: fluency and coherence
- Baseline
- three sampling methods, each with the recommended hyperparameters
- nucleus sampling (p = 0.95) → standard approach
- top-k sampling (k = 50)
- typical decoding (Meister et al., 2022) (τ = 0.95) → recent
- two search-based methods
- greedy decoding
- contrastive search
- three sampling methods, each with the recommended hyperparameters
- Model
- Expert LM: GPT-2 XL (1.5B), OPT (6.7B), OPT (13B)
- Amateurs: GPT-2 small (100M) and OPT (125M)
Results
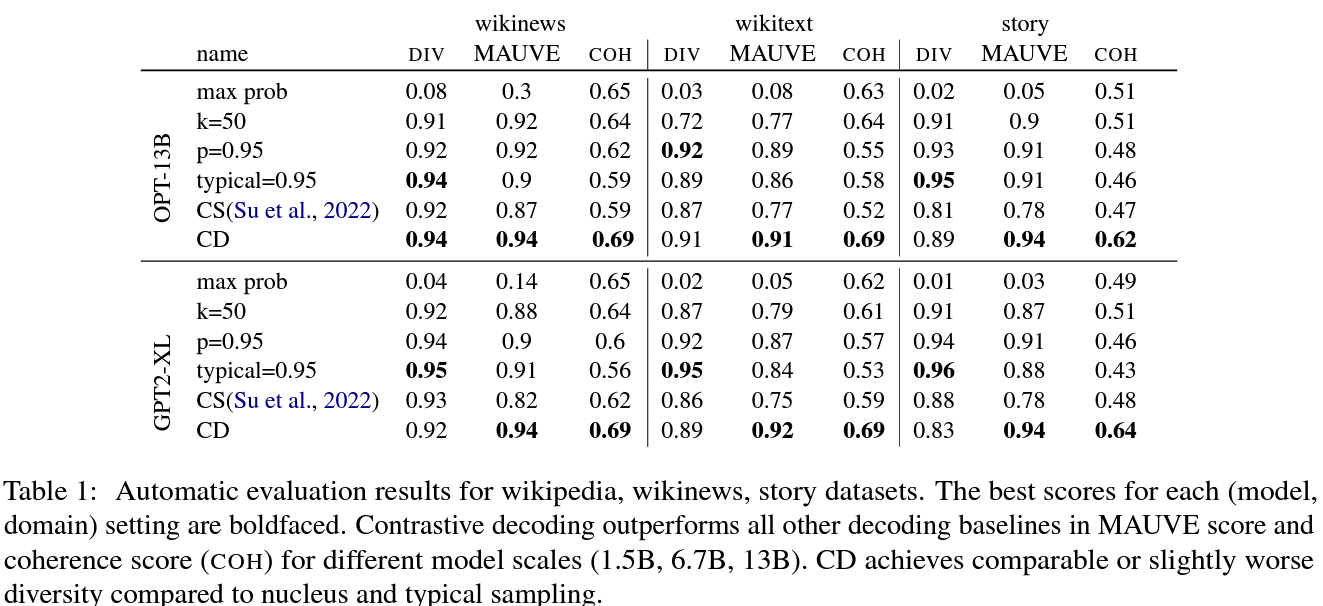
- Typical decoding and nucleus sampling produce lexically diverse text by choosing low probability tokens, at the expense of topic drift.
- Greedy decoding achieves good coherence despite being highly repetitive, because always repeating the same sentence is a degenerate way to circumvent topic drift.
topic drift
- our gain in coherence comes from three aspects
- (1) CD searches to optimize our objective, avoiding the topic drift that can happen by chance in sampling-based generation techniques.
- (2) Our contrastive objective implicitly rewards coherence, because large LMs are typically more coherent than smaller LMs.
- (3) Finally, we restrict the context length of the amateur LM(§3.4), further encouraging CD to reward text that is connected with the prompt
- Qualitative
- CD produces more coherent text both in content and style, where as nucleus sampling produces text that suffers from topic and style drifts.
- The Impact of Amateur Temperature
- Large τ brings the amateur distribution closer to the uniform distribution, which makes contrastive decoding generate repetitive text, as repetition is no longer penalized.
- Small τ makes the amateur LM more spiky and emphasizes undesired amateur behaviors, leading to better outputs from contrastive decoding.

