OPERA: Alleviating Hallucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation
Abstract
- OPERA, a novel MLLM decoding method grounded in an Over-trust Penalty and a Retrospection-Allocation strategy, serving as a nearly free lunch to alleviate the hallucination issue without additional data, knowledge, or training.
- most hallucinations are closely tied to the knowledge aggregation patterns manifested in the self-attention matrix
- MLLMs tend to generate new tokens by focusing on a few summary tokens, but not all the previous tokens.
- Such partial overtrust inclination results in the neglecting of image tokens and describes the image content with hallucination.
- OPERA introduces a penalty term on the model logits during the beam-search decoding to mitigate the over-trust issue, along with a rollback strategy that retrospects the presence of summary tokens in the previously generated tokens, and re-allocate the token selection if necessary.
Introduction
- we delve into the challenge of mitigating MLLMs’ hallucination during inference, without introducing additional data, models, or knowledge.
- Our investigation commences with a noteworthy ‘partial over-trust’ observation found while visualizing self-attention maps for decoded sequences.
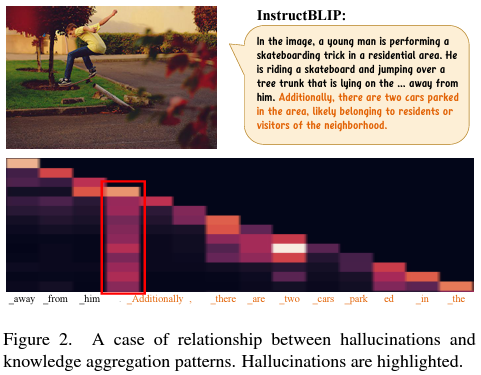
- As illustrated in Figure 2, we discern a recurring pattern where the inception of many hallucinated contents aligns with the subsequent tokens generated after a columnar attention pattern.
- Notably, these columnar attention patterns often manifest on tokens that lack substantial informativeness
- Intuitively, this peculiarity reveals a weird fact that, a token exhibiting a columnar attention pattern typically possesses limited information, yet exerts a pronounced influence on the prediction of all subsequent tokens.
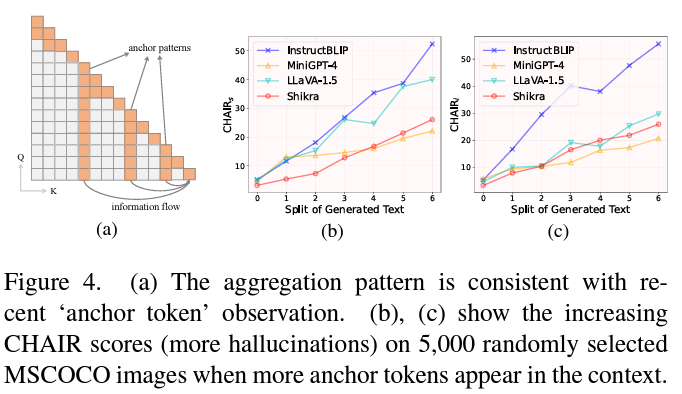
- ‘Aggregation pattern’ seems to be the nature of LLM.
- ‘Aggregation pattern’ leads to hallucination of current MLLMs.
- the subsequent tokens may ignore the forehead image tokens and over-trust the closer summary tokens via their stronger attention attended, leading to hallucinations raised by the model bias
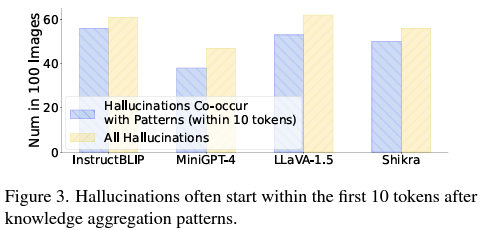
- the more summary tokens appear, the more easily MLLM hallucinations are induced.
- To prove it, we split the long responses of MLLMs based on the position of summary tokens, and calculate the CHAIR scores for different splits separately.
- OPERA, a novel MLLM decoding approach grounded in an Over-trust Penalty and a Retrospection-Allocation strategy
- The over-trust penalty introduces a weighted score for the candidate selection step in the Beam Search [3, 16, 37], so that the candidate with an over-trust pattern will have lower priority to be selected.
- Specifically, for each decoding token, we investigate the local window segmented on the self-attention map of the decoded sequence, and devise a column-wise metric to calculate the intensity of knowledge aggregation patterns.
- This metric produces a value that indicates the over-trust degree between in-window tokens and the summary tokens.
- It is naturally incorporated with the model logits predicted for the next token in the Beam Search and penalizes the appearance of over-trust patterns.
- retrospection-reallocation strategy to help the decoding process roll back to the position of the summary token and reselect better candidates that can avoid such a pattern.
- Such retrospection is triggered when the location overlap of the maximum of in-window penalty scores reaches a threshold.
Decoding strategy in language models
- Greedy Decoding simply selects the most likely next word at each step.
- Top-k Sampling adds randomness to the generation process by randomly selecting from the top-k likely next words, introducing diversity in the output but can sometimes produce less coherent results.
- Nucleus Sampling is an evolution of Top-k, Nucleus sampling considers a dynamic number of words that cumulatively reach the probability p. This method provides a balance between randomness and relevance, often leading to more coherent and interesting outputs than Top-k sampling.
- DoLa decoding is a recently proposed decoding method that aims to mitigate the hallucinations in MLLMs, which contrasts the logits of mature layer and pre-mature layers and rescale the increments as the output.
Method
