Data Structure - Graph & Tree & Binary Search Tree
Graph
Graph(그래프)란?
노드(Node)와 노드를 연결하는 간선(Edge)을 하나로 모아놓은 자료 구조이다.
그래프의 유형
1. 방향 그래프
정점을 연결하는 선에 방향이 있는 그래프
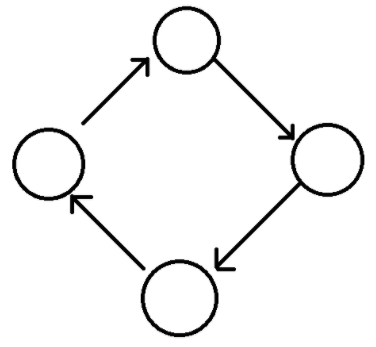
n개의 정점으로 구성된 방향 그래프의 최대 간선 수 : n(n-1)
2. 무방향 그래프
정점을 연결하는 선에 방향이 없는 그래프
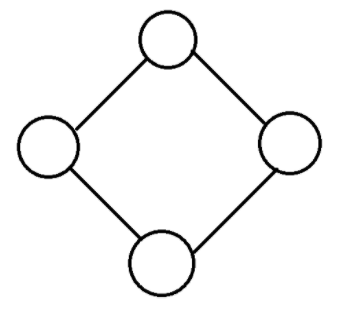
n개의 정점으로 구성된 무방향 그래프의 최대 간선 수 : n(n-1)/2
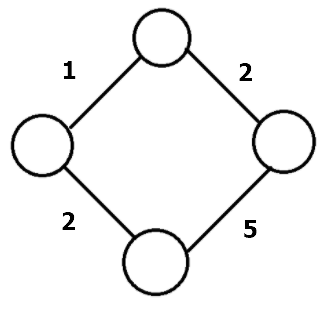
3. 가중치 그래프
두 정점을 이동할때 비용이 드는 그래프
4. 완전 그래프
모든 정점이 간선으로 연결되어 있는 그래프
그래프 용어 정리
| 용어 | 설명 |
|---|---|
| 정점(vertice) | 노드(node)라고도 하며 데이터가 저장된다. |
| 간선(edge) | 링크(link)라고도 하며 노드간의 관계를 나타낸다. |
| 인접정점(adjacent vertex) | 선에 의해 연결된 정점 |
| 단순경로(simple-path) | 경로 중 반복되는 정점이 없는 경로 |
| 차수(degree) | 무방향 그래프에서 하나의 정점에 인접한 정점의 수 |
| 진출차수(out-degree) | 방향 그래프에서 외부로 향하는 간선의 수 |
| 진입차수(in-degree) | 방향 그래프에서 외부에서 들어오는 간선의 수 |
그래프의 특징
- 그래프는 네트워크 모델이다.
- 순회는 DFS(깊이 우선 탐색), BFS(너비 우선 탐색)로 이루어진다.
- 루트 노드, 부모-자식 관계라는 개념이 없다.
- 노드들 사이에 무방향/방향에서 양방향 경로를 가질 수 있다.
- self-loop 뿐 아니라 loop/circuit 모두 가능하다.
그래프의 구현 방식
1. 인접 행렬 방식
그래프의 노드를 2차원 배열로 만든 것
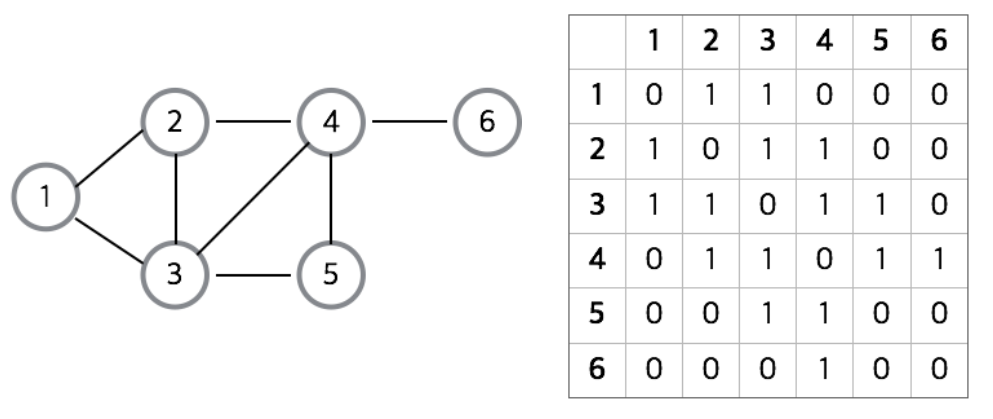
완성된 배열의 모양은 정점을 연결하는 노드에 다른 노드들이 인접 정점이라면 1, 아니면 0을 넣어준다.
| 장점 | 단점 |
|---|---|
| 2차원 배열 안에 모든 정점들의 간선 정보를 담기 때문에 배열의 위치를 확인하면 두 점에 대한 연결 정보를 조회할 때 O(1) 의 시간 복잡도면 가능하다. |
모든 정점에 대해 간선 정보를 대입해야 하므로 O(n²) 의 시간복잡도가 소요된다. |
| 구현이 비교적 간편하다. | 무조건 2차원 배열이 필요하기에 필요 이상의 공간이 낭비된다. |
2. 인접 리스트 방식
그래프의 노드들을 리스트로 표현한것
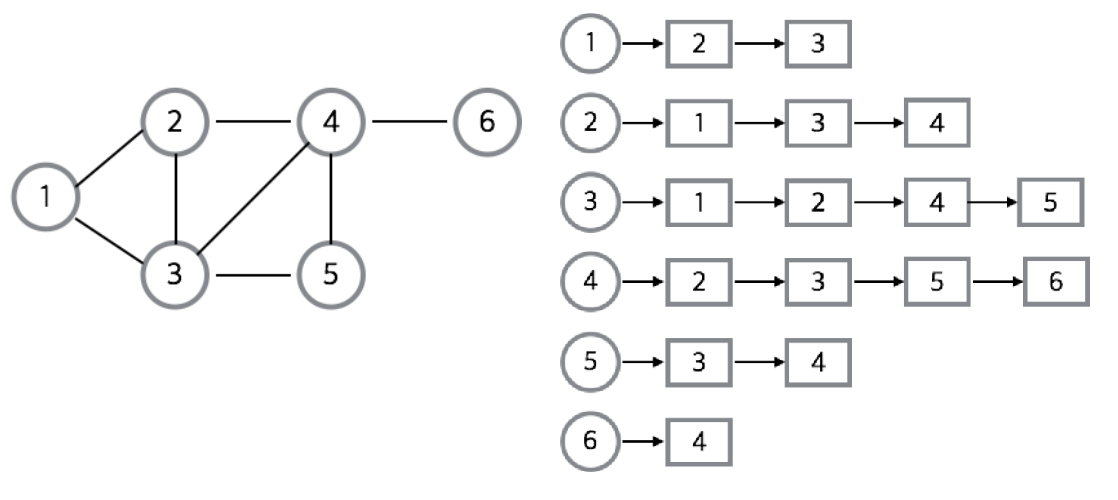
주로 정점의 리스트 배열을 만들어 관계를 설정해줌으로써 구현한다.
| 장점 | 단점 |
|---|---|
| 정점들의 연결 정보를 탐색할 때 O(n) 의 시간이면 가능하다. (n: 간선의 갯수) |
특정 두 점이 연결되었는지 확인하려면 인접행렬에 비해 시간이 오래 걸린다. (배열보다 search 속도느림) |
| 필요한 만큼의 공간만 사용하기때문에 공간의 낭비가 적다. | 구현이 비교적 어렵다. |
Graph 코드구현
class Graph {
// nodes {
// node[키형태] 1 : edge[배열형태]
// node[키형태] 2 : edge[배열형태]
// }
constructor() {
this.nodes = {};
}
addNode(node) { // 노드를 추가
this.nodes[node] = this.nodes[node] || [];
// 그래프 안에 노드를 찾는데 찾고자하는 노드가 원래 있다면 그대로두고 없다면 빈배열로 추가해줘라;
}
contains(node) { // 노드 여부 검사
// 노드안에 찾으려는 노드가 있으면 true 없으면 false
}
removeNode(node) { // 노드를 삭제
// 전체 노드 순회하면서 삭제하려는 노드는 연결해제해준다.
// 삭제하려는 노드를 그냥 delete하면 된다.
}
hasEdge(fromNode , toNode) { // 엣지의 포함여부를 확인
// 찾고자하는 노드조차 없으면 처음부터 false;
// 찾고자하는 노드에 엣지가 있으면 true, 없으면 false
}
addEdge(fromNode , toNode ) { // 엣지를 추가
// 시작노드에 끝노드를 엣지로 추가
// 끝노드에 시작노드를 엣지로 추가
}
removeEdge(fromNode, toNode) { // 엣지를 제거
// 시작노드에 들어가서 엣지(끝노드)를 찾아 제거한다.
// 끝노드에 들어가서 엣지(시작노드)를 찾아 제거한다.
}
}Tree
Tree(트리)란?
노드로 구성된 계층적 자료구조로 최상위 노드(루트)를 만들고, 루트 노드의 child를 추가하고, 그 child에 또 child를 추가하는 방식으로 트리 구조를 구현할 수 있다.
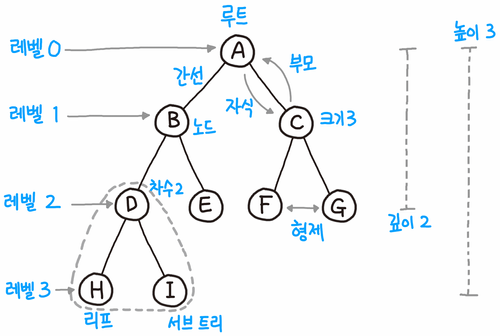
트리 용어 정리
| 용어 | 설명 |
|---|---|
| 루트 노드(root node) | 부모가 없는 노드, 트리는 하나의 루트 노드만을 가진다. |
| 단말 노드(leaf node) | 자식이 없는 노드, ‘말단 노드’ 또는 ‘잎 노드’라고도 부른다. |
| 내부(internal) 노드 | 단말 노드가 아닌 노드 |
| 간선(edge) | 노드를 연결하는 선 (link, branch 라고도 부름) |
| 형제(sibling) | 같은 부모를 가지는 노드 |
| 노드의 크기(size) | 자신을 포함한 모든 자손 노드의 개수 |
| 노드의 깊이(depth) | 루트에서 어떤 노드에 도달하기 위해 거쳐야 하는 간선의 수 |
| 노드의 레벨(level) | 트리의 특정 깊이를 가지는 노드의 집합 |
| 노드의 차수(degree) | 하위 트리 개수 / 간선 수 (degree) = 각 노드가 지닌 가지의 수 |
| 트리의 차수(degree of tree) | 트리의 최대 차수 |
| 트리의 높이(height) | 루트 노드에서 가장 깊숙히 있는 노드의 깊이 |
트리의 특징
- 그래프의 한 종류이며 ‘최소 연결 트리’ 라고도 불린다.
- 계층 모델 이다.
- DAG(Directed Acyclic Graphs, 방향성이 있는 비순환 그래프)의 한 종류이다.
- loop나 circuit이 없다. 당연히 self-loop도 없다.
- 노드가 N개인 트리는 항상 N-1개의 간선(edge)을 가진다.
즉, 간선은 항상 (정점의 개수 - 1) 만큼을 가진다. - 두 개의 정점 사이에 반드시 1개의 경로만을 가진다.
- 한 개의 루트 노드만이 존재하며 모든 자식 노드는 한 개의 부모 노드만을 가진다.
- 부모-자식 관계이므로 흐름은 top-bottom 아니면 bottom-top으로 이루어진다.
- 순회는 Pre-order, In-order 아니면 Post-order로 이루어진다. 이 3가지 모두 DFS/BFS 안에 있다.
Tree 코드구현
class TreeNode {
constructor(value) {
this.value = value; // 찾고자하는 value
this.children = []; // 배열
}
insertNode(value) { // 노드추가
}
contains(value) {
// 플래그 추가
// 배열안에서 순회
// 찾으려는 value가 있으면 true로 탈출
// true로 바뀜
// 배열안에 배열이 또 있으면 계속 파고들면서 찾는다.
search(this.children); // 아래 주석처리의 모양을 갖는다.
// {
// value:0,
// children: [{value:0,children: []},
// {value:0,
// children: [{value:0, children: []},
// {value:0, children: []}]
// }]
// }
}
}그래프와 트리의 차이점 비교
| 그래프 | 트리 |
|---|---|
| 2개 이상의 경로가 가능하며 노드들 사이에 무방향/방향에서 양방향 경로를 가질 수 있다. | 두 개의 정점 사이에는 반드시 1개의 경로만을 가진다. |
| self-loop 뿐 아니라 loop/circuit 모두 가능하다. | loop나 circuit이 없으니 self-loop도 없다. |
| 루트 노드라는 개념이 없다. | 한 개의 루트 노드만이 존재하며 모든 자식노드는 한 개의 부모노드 만을 가진다. |
| 부모-자식 관계라는 개념이 없다. | 부모-자식 관계이므로 흐름은 top-bottom 아니면 bottom-top으로 이루어진다. |
| 순회는 DFS나 BFS로 이루어진다. | 순회는 Pre-order, In-order 아니면 Post-order로 이루어지며 이 3가지 모두 DFS/BFS안에 있다. |
| Cyclic 혹은 Acyclic이다. | DAG(Directed Acyclic Graphs, 사이클이 없는 방향 그래프)의 한 종류이다. |
| 방향 그래프, 무방향 그래프 | 이진트리, 이진탐색트리, AVL 트리, 힙 |
| 간선의 유무는 그래프에 따라 다르다. | 간선은 항상 정점의 개수 - 1 만큼을 가진다. |
| 네트워크 모델 | 계층 모델 |
그래프와 트리의 탐색법
1. 깊이 우선 탐색(DFS, Depth-First Search)
루트 노드(혹은 다른 임의의 노드)에서 시작해서 다음 분기(branch)로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법으로 넓게(wide) 탐색하기 전에 깊게(deep) 탐색하는 것이다.
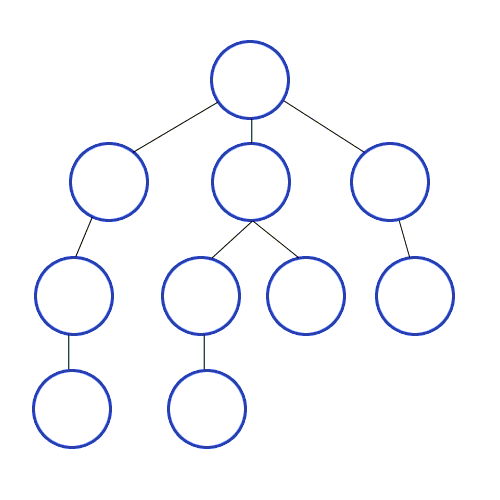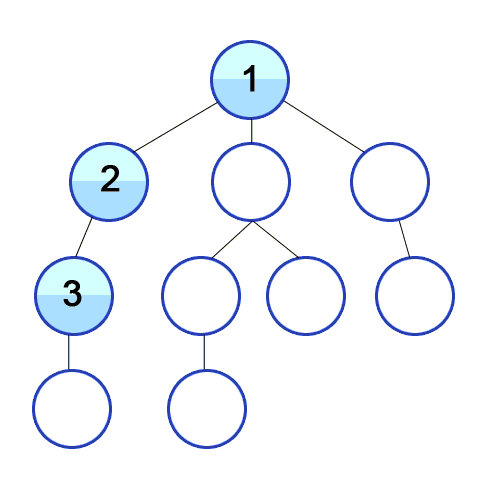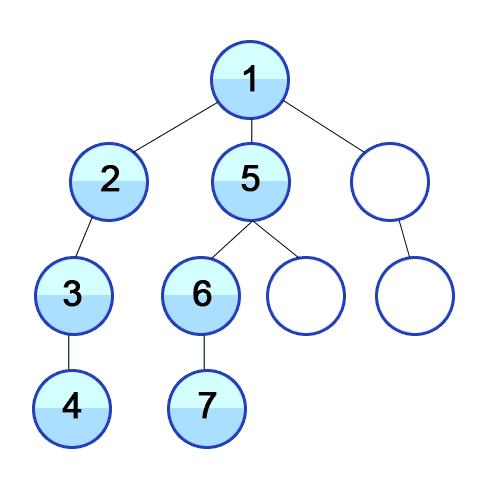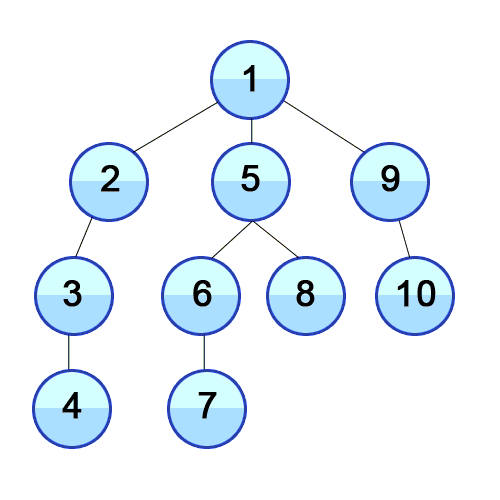
깊이 우선 탐색(DFS)의 특징
- 자기 자신을 호출하는 순환 알고리즘의 형태 를 가지고 있다.
- 전위 순회(Pre-Order Traversals)를 포함한 다른 형태의 트리 순회는 모두 DFS의 한 종류이다.
- 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사 해야 하며 이를 검사하지 않을 경우 무한루프에 빠질 위험이 있다.
깊이 우선 탐색(DFS)의 장단점
| 장점 | 단점 |
|---|---|
| 현재 경로상의 노드들만 기억하면 되므로, 저장 공간의 수요가 비교적 적음 | 단순 검색 속도는 너비 우선 탐색(BFS) 보다 느림 |
| 목표 노드가 깊은 단계에 있는 경우 해를 빨리 구할 수 있음 | 해가 없는 경우에 빠질 가능성이 있음 (사전에 임의의 깊이를 지정한 후 탐색하고, 목표 노드를 발견하지 못할 경우 다음 경로를 탐색하도록 함) |
| 구현이 너비 우선 탐색(BFS) 보다 간단함 | 깊이 우선 탐색은 해를 구하면 탐색이 종료되므로, 구한 해가 최단 경로가 된다는 보장이 없음 (목표에 이르는 경로가 다수인 경우 구한 해가 최적이 아닐 수 있음) |
2. 너비 우선 탐색(BFS, Breadth-First Search)
루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법으로 깊게(deep) 탐색하기 전에 넓게(wide) 탐색하는 것이다.
주로 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 이 방법을 선택한다.
너비 우선 탐색(BFS)의 특징
- 시작 노드에서 시작해서 거리에 따라 단계별로 탐색한다.
- 재귀적으로 동작하지 않는다.
- 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사 해야 하며 이를 검사하지 않을 경우 무한루프에 빠질 위험이 있다.
- 방문한 노드들을 차례로 저장한 후 꺼낼 수 있는 자료 구조인 큐(Queue)를 사용한다.
즉, 선입선출(FIFO) 원칙으로 탐색한다.
너비 우선 탐색(BFS)의 장단점
| 장점 | 단점 |
|---|---|
| 노드의 수가 적고 깊이가 얕은 경우 빠르게 동작할 수 있다. | 재귀호출의 DFS와는 달리 큐에 다음에 탐색할 정점들을 저장해야 하므로 저장공간이 많이 필요하다. |
| 단순 검색 속도가 깊이 우선 탐색(DFS)보다 빠름 | 노드의 수가 늘어나면 탐색해야하는 노드 또한 많아지기에 비현실적이다. |
| 너비를 우선 탐색하기에 답이 되는 경로가 여러개인 경우에도 최단경로임을 보장한다. | |
| 최단경로가 존재한다면 어느 한 경로가 무한히 깊어진다해도 최단경로를 반드시 찾을 수 있다. |
Binary Search Tree
Binary Search Tree(BST, 이진 탐색 트리)란?
자식노드를 최대 2개 가지며 모든 노드가 왼쪽 자식노드가 루트노드보다 작고, 오른쪽 자식노드가 루트노드보다 큰 속성이 있는 이진 트리
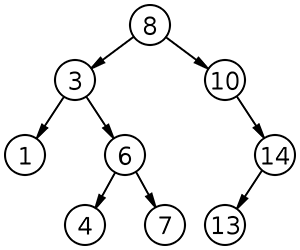
BST 순회방법
| 구분 | 개념도 | 순회방법 |
|---|---|---|
| 전위 순회 (Pre-order Traversal) |
 |
루트 -> 왼쪽 -> 오른쪽 |
| 중위 순회 (In-order Traversal) |
 |
왼쪽 -> 루트 -> 오른쪽 |
| 후위 순회 (Post-order Traversal) |
 |
왼쪽 -> 오른쪽 -> 루트 |
BST의 종류
| 구분 | 개념도 | 설명 |
|---|---|---|
| 정 이진 트리 (Full Binary Tree) |
 |
모든 노드의 차수가 0 또는 2인 트리 |
| 완전 이진 트리 (Complete Binary Tree) |
 |
왼쪽 자식노드부터 채워지며 마지막 레벨을 제외하고는 모든 자식노드가 채워져있는 트리 |
| 포화 이진 트리 (Perfect Binary Tree) |
 |
모든 레벨에서 0개 혹은 2개의 자식노드를 가진 노드가 꽉 채워진 트리 |
Binary Search Tree 코드구현
class BinarySearchTreeNode {
constructor(value) {
this.value = value;
this.left = null;
this.right = null;
}
insert(value) { // 삽입
// 임시노드만들기
// 삽입하려는 값이 기존값보다 작으면
// 왼쪽이 null이면
// 왼쪽값에 임시노드할당
// null 아니면
// 왼쪽노드로 이동하여 삽입실행
// 삽입하려는 값이 기존값보다 크면
// 오른쪽이 null이면
// 오른쪽값에 임시노드할당
// null 아니면
// 오른쪽노드로 이동하여 삽입실행
}
contains(value) { // value존재 여부확인
// 들어온 값이 현재 노드의 value 라면
// true를 리턴하면된다.
// 만약에 왼쪽이나 오른쪽 둘다 null이면
// false
// 만약에 들어온값이 현재의 노드의 값보다 작으면?
// 현재값에서 왼쪽으로 이동해서 검색 실행
// 반대면?
// 현재값에서 오른쪽으로 이동해서 검색실행
}
inorder(callback) { // 중위순위(왼쪽 -> 부모 -> 오른쪽)
// 노드가 있다 = 값이있다.
// 왼쪽에 노드가 있으면 왼쪽으로 이동해서 실행
// 함수에 현재노드의 value를 넣어서 실행시키는 부분
// 오른쪽에 노드가 있으면 오른쪽 이동해서 실행
}
}

대단하십니다!!