Linked List
Linked List(연결 리스트)란?
데이터 구조의 하나로 여러 개의 값을 저장하기 위한 구조이다.
데이터와 포인터가 한 쌍으로 구성되었으며, 포인터가 다음 데이터의 메모리 위치를 가리킨다.
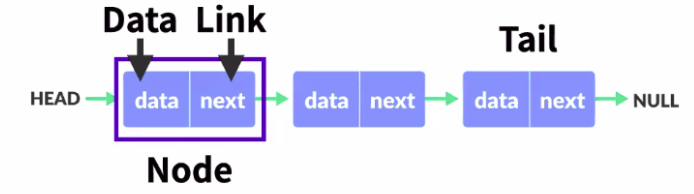
ex) 플레이 리스트, 이미지 뷰어 등
Linked List 종류
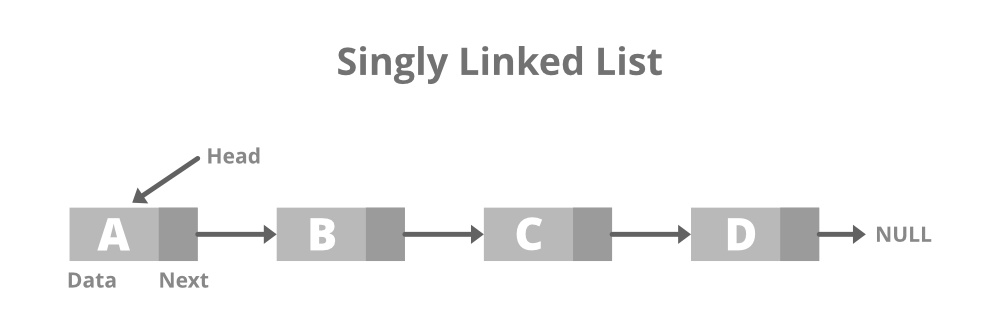
단일 연결 리스트(Singly-Linked List)
각 노드에 자료 공간과 1개의 포인터 공간이 있으며 각 노드의 포인터는 다음 노드를 가리킨다. 단방향이다.
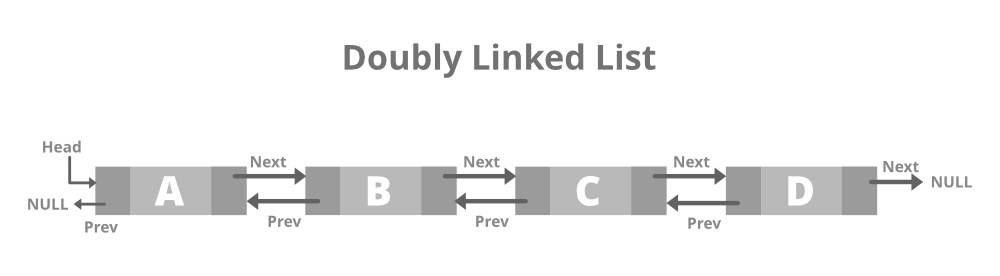
이중 연결 리스트(Doubly-Linked List)
구조는 단일 연결 리스트와 비슷하나 포인터 공간이 2개이고, 각각의 포인터는 앞의 노드와 뒤의 노드를 가리킨다.
양방향이다.
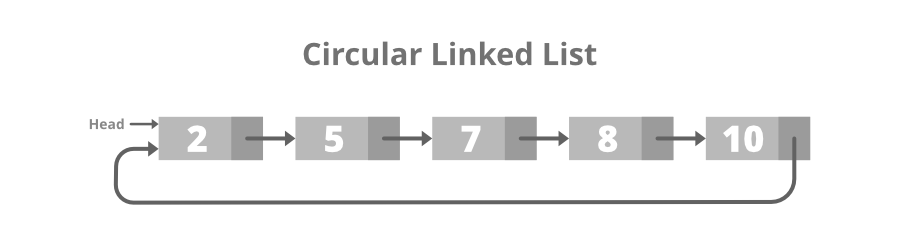
원형 연결 리스트(Circular-Linked List)
일반적인 연결 리스트에 마지막 노드와 처음 노드를 연결시켜 원형으로 만들었다.
Linked List의 특징
- 메모리상에 원소들이 연속적으로 위치하지 않는다.
- 데이터의 추가/삭제가 용이하다.
- 특정 위치의 데이터를 검색하기 위해서 처음부터 끝까지 순회해야 한다.
Linked List 코드구현
class Node {
constructor(value) {
this.value = value;
this.next = null;
}
}
class LinkedList {
constructor() {
this.head = null;
this.tail = null;
this._size = 0;
}
addToTail(value) {
// node 생성
// head에 값이 없으면 head와 tail에 node 연결
// head의 값이 있으면 다음 tail에 node 연결, 새 tail에도 node 연결
// size는 1씩증가
}
remove(value) {
// head 변수선언(비교기준) - 임시head(사본)
// 찾아낼 이전값
// head에 value가 있을경우
// prev가 없으면 현재값이 head이다.
// 첫번째값이면 head를 next로 변경해준다.- 진짜head(원본)
// 그것도아니면 prev와 next를 접합시켜서 head를 변경해준다.(속성만바꿔줌)
// size 1씩감소
// 못 찾을경우 계속 search 하기 위한 할당 쓰기
}
getNodeAt(index) {
// head 변수선언
// index가 size보다 크면 undefined
// index가 size보다 작으면 for문돌려서 1번변수는 1번변수의 다음변수
// index가 size보다 작으면 for문돌려서 1번변수는 1번변수의 다음변수
// 해당 index 리턴
}
contains(value) {
// head 변수선언
// 변수가 있을때까지 돌려서 변수의 value가 value와 같다면 true
// 아니면 변수는 그 다음 변수에 지정
// 전부아니면 false 리턴
}
indexOf(value) {
// head 변수선언
// 인덱스카운트 0부터.
// 변수가 있을때까지 돌려서 변수의 value가 value와 같으면 그 인덱스카운트 리턴
// 아니면 인덱스카운트 증가, 변수는 그 다음 변수에 지정
// 전부 없으면 -1 리턴
}
size() {
// this._size 리턴
}
}Hash Table
Hash Table(해시 테이블)이란?
키-값 쌍을 저장하고 있는 자료 구조로, 해시함수(Hash Function)를 사용하여 변환한 값을 색인(index)으로 삼아 키(key)와 데이터(value)를 저장한다.
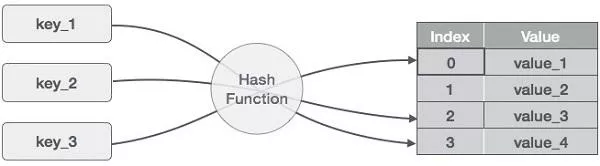
해시 테이블의 특징
- 필요할 때에만 메모리 크기를 늘리고, 가능한 작은 크기를 유지한다.
- 해싱된 키를 가지고 배열의 인덱스를 사용하여 검색하기 때문에 탐색(Search), 삽입(Insert), 삭제(Delete)가 쉽고 빠르다.
- 크기가 정해져있다.
Hashing(해싱)이란?
임의의 길이의 값을 해시함수(Hash Function)를 사용하여 고정된 크기의 값으로 변환하는 작업
Hash Function(해시함수)의 정의와 세가지 특징
입력 값에서 테이블 내의 주소를 계산해내는 것
- 값이 항상 배열크기 범위 내에서만 나와야 한다.
- 언제든지 일정한 값이 나와야한다.
- 어떠한 저장도 할 수 없다.
Hash Function(해시함수)의 알고리즘 종류
1. Division Method(나눗셈법)
입력 값을 테이블의 크기로 나누고 그 나머지를 테이블의 인덱스로 이용한다.
Index(해시값) = 입력값 % 테이블의 크기2. Digit Folding(자릿수 접기)
숫자의 각 자릿수를 더해 해시값을 만든다.
ex) 324 -> 3+2+4 = 9(해시값)
Hash Collision(해시 충돌)이란?
해시함수가 서로 다른 두 개의 입력값에 대해 동일한 출력값을 내는 상황을 의미한다.
ex) key-value pairs가 다른데 같은 인덱스에 있을경우
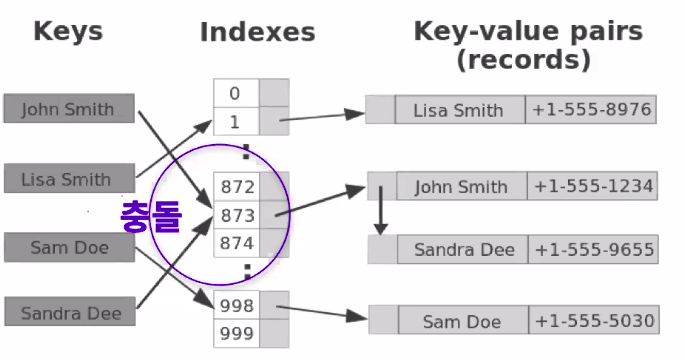
해시 충돌을 피해야 하는 이유: 해시 함수를 이용한 자료구조나 알고리즘의 효율성을 떨어뜨리기 때문이다.
해시 충돌 해결법
1. Open Addressing(개방 주소법)
해시 테이블의 주소 바깥에 새로운 공간을 할당하여 문제를 해결하는것
-
선형 조사법(Linear Probing) : 해시 주소값이 충돌하면 현재 주소에서 고정 폭만큼 다음주소로 이동

-
이차 조사법(Quadratic Probing) : 해시 주소값이 충돌하면 현재 주소에서 이동폭이 제곱수만큼 이동

-
이중 해쉬(Double Hash) : 해시 함수에 키를 입력해서 얻어낸 주소에서 충돌이 일어나면 새로운 조소를 향해 이동하게 하여 이때의 이동폭을 제2의 해시함수로 계산

별도의 저장공간이 필요없어 별다른 작업이 필요치 않으나, 해시 함수에 따라 성능 차이가 생길 수 있고 데이터 길이가 많이 늘어나는 것에 대한 별도의 준비를 해야 한다.
2. Chaining(체이닝)
해시 함수가 다른 키에 대해 같은 주소값을 반환하여 충돌하면 각 데이터를 해당 주소에 있는 Linked list에 삽입하여 문제를 해결하는 것
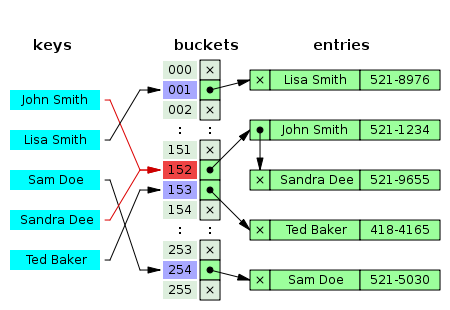
해시함수의 의존도가 비교적 낮아지고 상대적으로 메모리 사용량이 낮고 공간을 확보할 필요가 없지만, 클러스터 현상이 생겨 검색속도가 낮아질 수 있고 Linked List 공간이 따로 필요하다.
해시 테이블 용어정리
1. storage
데이터들을 저장하는 공간이며 배열이다.
2. bucket
한 개의 데이터가 들어갈 공간
3. tuple
데이터들을 담고 있는 곳.
Hash Table 코드구현
class HashTable {
constructor() {
this._size = 0;
this._bucketNum = 8; // 저장공간의 크기
this._storage = LimitedArray(this._bucketNum); // 해시테이블 : 저장공간(보통은 배열형태고 크기가 정해져있다.)
}
// 튜플 : 키-값 쌍
// 버켓 : [인덱스/엔트리s]
// 엔트리 : 버켓의 값(튜플형태)
insert(key, value) { // 삽입
const index = hashFunction(key, this._bucketNum);
// 임시버켓
// 엔트리가 내가 찾는 인덱스의 값에 있냐?
// 없어?
// 엔트리 만들기
//인덱스에 값으로 엔트리(튜플형태) 넣어줘
// 있어?
// 그거 가져와(복사해)서 임시버켓에 넣어줘
// 플래그 추가(플래그를 추가하는 이유는 플래그가 없으면 푸쉬가 여러번 일어나기 때문에)
// 임시버켓에 뭐가들었는지 순회해보자
// 내가찾는 key를 가진 엔트리가 있어?
// 그 엔트리의 value 바꿔
// 엔트리 갯수가 많아지면 중복된 튜플이 입력되기 때문에 한번이라도 푸시된 적이 있다면 플래그값으로 식별한다.
// 엔트리 추가해
}
retrieve(key) { // 조회
const index = hashFunction(key, this._bucketNum);
// 해당 인덱스의 버킷 사본만들기
// 사본이 없으면
// 조회 안된거니까 undefined;
// 사본이 있음
// 엔트리들 순회
// 엔트리의 key가 내가 찾는 key라면
// value 반환
}
}
}
}
remove(key) { // 삭제
const index = hashFunction(key, this._bucketNum);
// 해당 인덱스의 버킷 사본만들기
// 튜플의 0번째인덱스가 삭제하고하는 키와 같다면
// 해당 엔트리 자체를 잘라버림
}
_resize(newBucketNum) { // 해시테이블의 최대저장공간을 조절(순회시 효율성때문에)
// 현재 저장소의 사본
// 새로운 크기의 저장소
// 사이즈 속성 0으로 초기화
// 새로운 제한 크기를 적용
// 기존저장소를 돌면서 새로운 저장소로 추가해야한다.
// each를 이용하면 기존저장소를 순회가능
// 저장소안의 버킷도 다시 순환해야 한다.
// 엔트리들을 하나씩 빼내서 insert 해주면 새로운 저장소로 이사가 완료됨
}