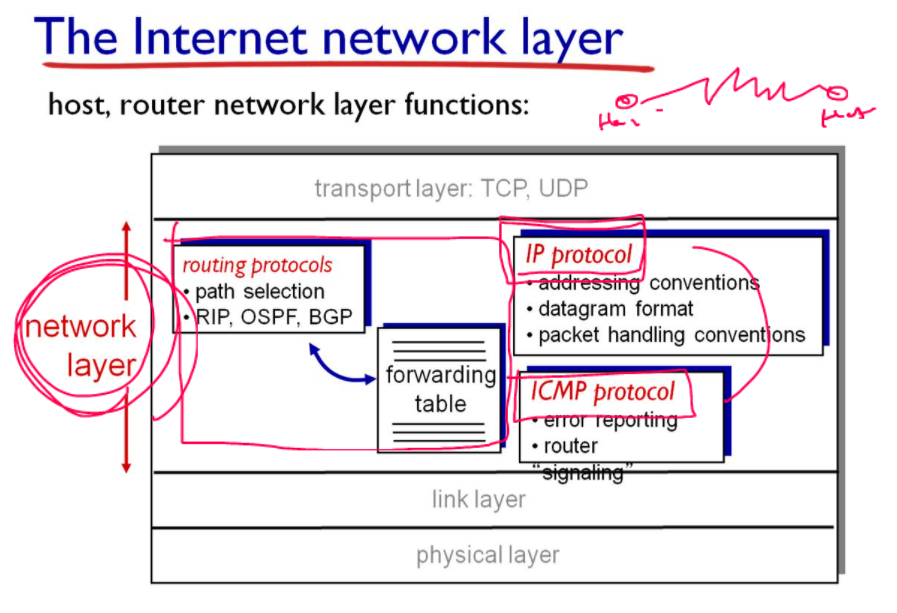
3계층에서, 라우팅에 문제가 발생했을 때 이 문제를 제어해주는 프로토콜이 ICMP 프로토콜이다. (error reporting)
3계층의 핵심은, 호스트에서 호스트까지 최적의 경로를 찾아주는 일이다. 이 3계층의 기능을 구현해놓은 것이 IP프로토콜이고, 이 IP프로토콜에 문제가 발생했을 때 컨트롤하는 프로토콜이 ICMP프로토콜이다.
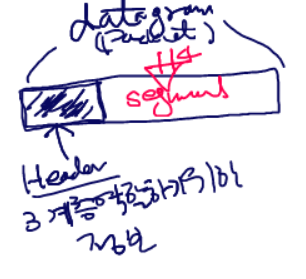
4계층에서 데이터를 부르는 말로는, TCP의 경우
세그먼트UDP의 경우데이터그램
3계층에서 데이터를 어떻게 부르냐면,패킷또는데이터그램
2계층에서는 데이터를프레임이라고 부른다.

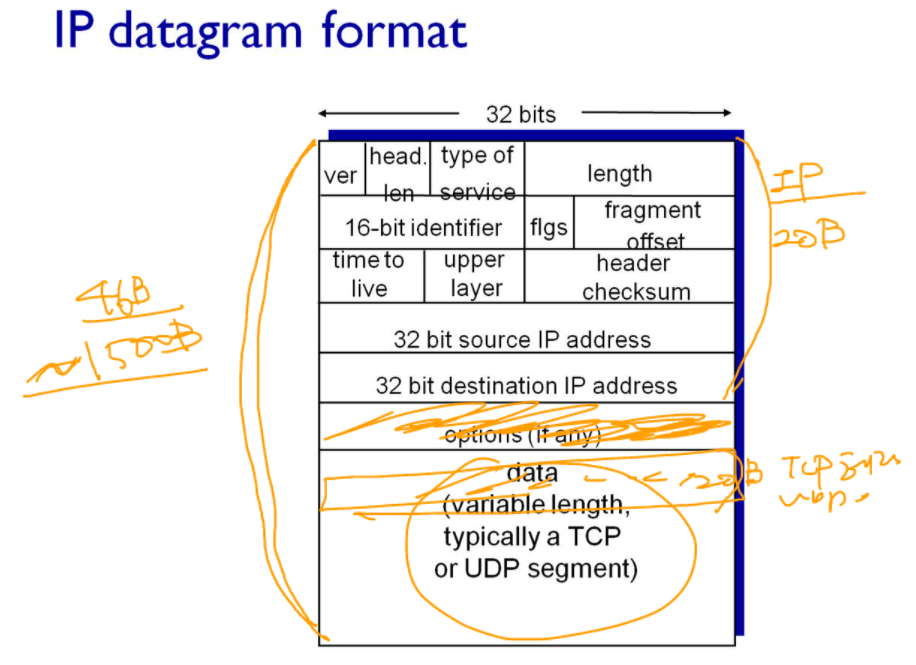
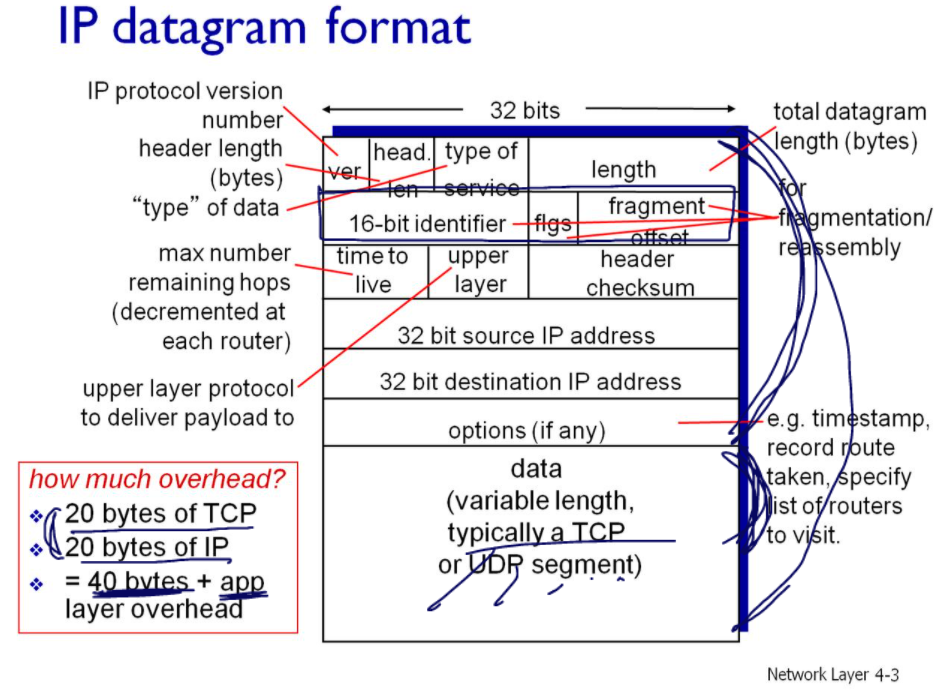
3계층, IP 데이터그램의 포맷
먼저, ip버전이 나온다. ip버전4는 지금까지도 사용되고 있는 포맷이다. 버전6가 90년대 후반부터 연구되었고, 현재는 8프로 정도의 단말이 ip ver6를 사용하고 있다.
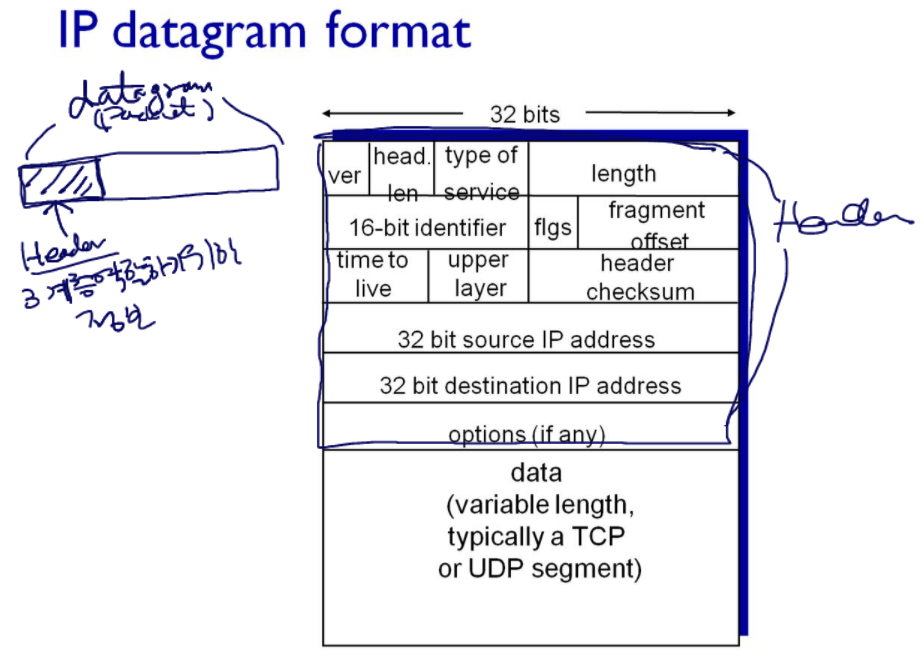
데이터그램은 위와 같이 구성되는데, 그 중 Header에는 3계층의 역할을 수행하기 위한 정보가 들어있다. 오른쪽 남색 네모 부분이 헤더이다. 나머지는 4계층에서 내려온 세그먼트(위 그림에서는 data로 표현)가 들어가게 된다.
4계층에서 데이터를 얼마만큼 보냈느냐에 따라, 3계층 데이터그램의 크기가 달라진다. 즉 3계층에서 데이터그램의 크기는 세그먼트에 따라 달라진다.헤더는 20 바이트로 고정이 되어있다고 생각해도 된다.
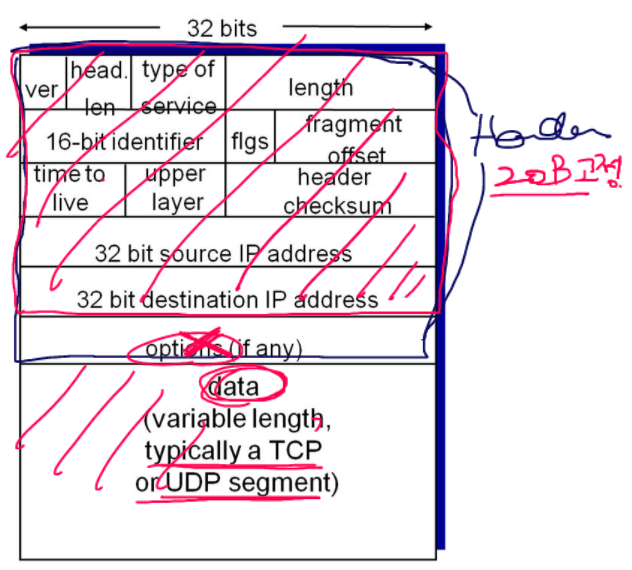
옵션은 거의 쓰지 않는다.
데이터그램의 크기는 20바이트 + 세그먼트의 크기
4계층에서 내려온 세그먼트 또한 까보면 세그먼트 헤더가 앞에 붙는다. 이 세그먼트 헤더에는 어떤 정보가 붙는가? 바로 4계층에서 수행되어야 할 TCP나 UDP에서 수행되어야 할 여러 역할들...
(TCP에서는 특별히 세그먼트의 순서를 맞추고, 제대로 세그먼트가 오지 않았을 때는 다시 요청도 하고. 그리고 각 포트와 맵핑이 되고. 3계층의 IP가 호스트 PC와 맵핑된다면 4계층에서는 헤더에 있는 포트 번호를 보고 적당한 소켓을 찾아간다. 한 개의 소켓은 한 개의 포트에 맵핑이 되어있으니까 세그먼트 번호, 포트번호, 체크섬 등이 세그먼트 헤더 안에 들어가있다)
...을 위한 정보들이 들어가있다. 세그먼트의 헤더 또한 20바이트이다.
세그먼트의 크기는 20바이트 + app data

3계층에서 패킷(데이터그램)의 크기는 20B + (20B + 애플리케이션에서 내려온 데이터) 이다.
애플리케이션에서 데이터를 많이 보낼 수도, 적게 보낼수도 있다.이러한 유동성에는 문제가 따른다.
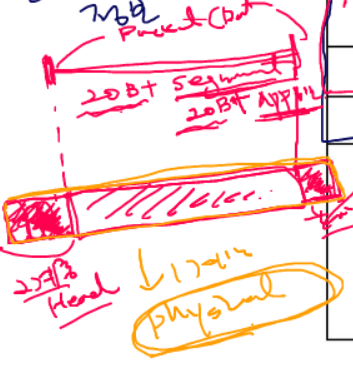
패킷은 2계층에서 2계층 헤더와 트레일러가 패킷 앞 뒤에 장착되게 된다. 이 데이터는 1계층(Physical Layer)으로 내려가게 되는데, 이 Physical이 무엇이냐에 따라서 2계층에서 보낼 수 있는 프레임의 크기에 제약이 있게 된다.
따라서 패킷의 크기를 제한해두었다. 만약 이더넷을 사용하고 있다면 Physical Layer로 랜선(UTP)를 사용하는데, 이더넷에서는 프레임에 들어갈 수 있는 패킷의 크기를 제한하고 있는데 46바이트에서 1500바이트까지의 패킷만 임베드할 수 있도록 제한하고 있다.
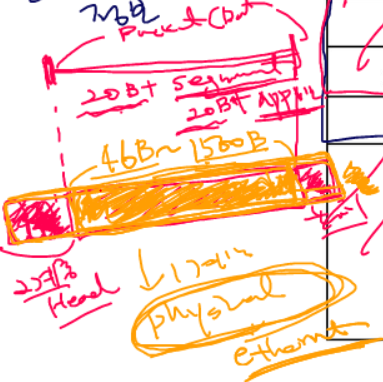
최대 1500 바이트, 최소 46바이트까지 프레임에 임베드할 수 있다.
이건 물리적인 특성 때문에 그렇다. 한번에 물리적으로 보낼 수 있는 데이터의 크기가 제한되어있기때문이다.
고로, 애플리케이션의 데이터는 한번에 최대 1460 만큼의 데이터를 보낼 수 있다.
1460보다 크면 잘라서 보내게 된다.
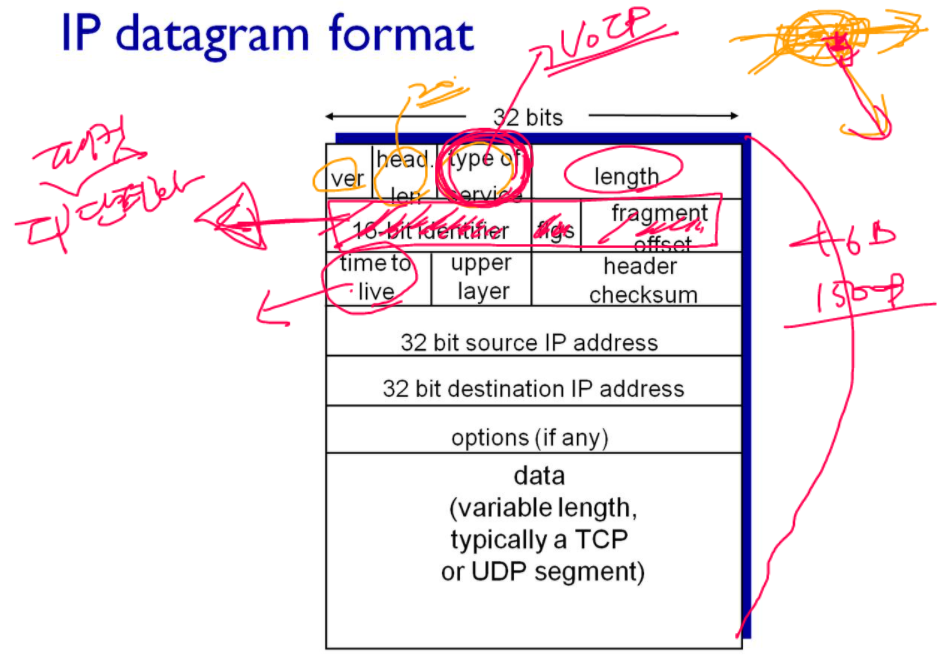
패킷(데이터그램)의 구성 요소
version
가장 먼저 버전이 들어간다.
header length
헤더의 길이(20)이 들어가고,
type of service
typeofsevice가 들어간다. 이는 급한 패킷을 먼저 보내는 것인데 에로 VoIP가 있다. 음성데이터 같은 실시간 데이터를 비실시간 데이터보다 먼저 보내는 것이다.
length
length에는 패킷의 전체크기를 적는다(최소 46바이트, 최대 1500 바이트).
16-bit identifier, flags, fragment offset
16-bit identifier(패킷의 고유번호), flags, fragment offset은 IP 패킷의 단편화와 관련된다.
time to live
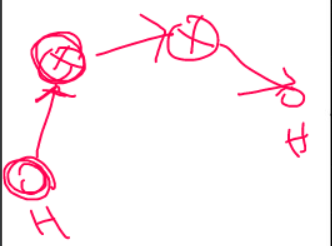
time to live 호스트(송신)에서 호스트(수신)까지 몇홉이나 걸릴지 예상해서 적어놓는 곳이다.
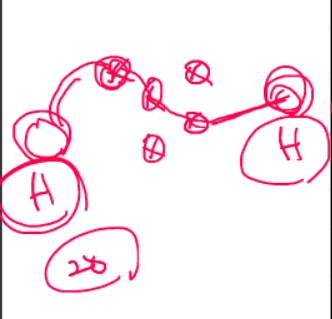
위 그림은 최단 경로가 4홉이며, time to live에는 20이 들어갈 수 있다. 즉 적어도 20홉 안에는 패킷이 도착한다는 말이다. 20홉 같이 넉넉히 쓴다.
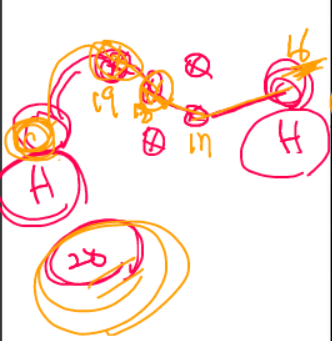
한 홉씩 갈 때마다 time to server의 값이 1씩 줄어든다. 위 예시의 경우, 20홉을 예상했고, 결국 도착했을 때의 time to server 는 16으로, 꽤 괜찮은 경로로 패킷을 보냈다.
time to server 항목이 있는 이유는, 잘못된 라우팅을 했을 때,
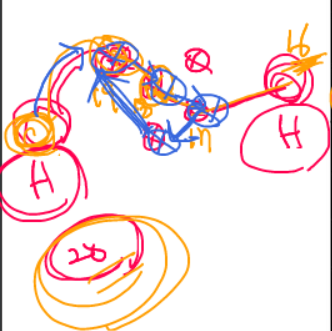
위에서 패킷은 루프를 만들며 홉 수가 계속 증가하게 된다. 만약 time to live가 없다면 계속해서 무한 반복하며 패킷이 돈다. 헛짓을 하고 있는 코어 네트워크의 라우터들...
그렇기에 time to live 옵션을 주어서 패킷이 이동함에 따라 홉 수가 하나씩 줄어들다, 20 -> 19 -> 18 -> .... 1 -> 0 0이 되면 이 패킷을 드랍해 버린다. 더이상 라우팅하지 않고 버려버린다.
time to live 항목이 존재하는 이유는, 라우팅 홉수를 넉넉하게 예상하여 주는데, 홉이 0이 되면 패킷을 버려버려! 라고 하기 위해 존재한다. 충분히 넉넉하게 주었는데도 0이 되었다는 것은 뭔가 라우팅에 루프가 생겼거나 잘못되었다는 뜻이기 때문이다. time to live가 0이 된 패킷을 받은 라우터는 그 패킷을 버려버린다. 그래야 네트워크에 있는 잘못 라우팅 되고 있는 패킷들이 없어지기 때문이다.
upper layer
upper layer는 현재 패킷에 들어있는 데이터부분(TCP면 세그먼트, UDP면 데이터그램)이 TCP인지, UDP인지 표현한다. 말 그대로 upper layer가 뭔지 설명하고 있다.
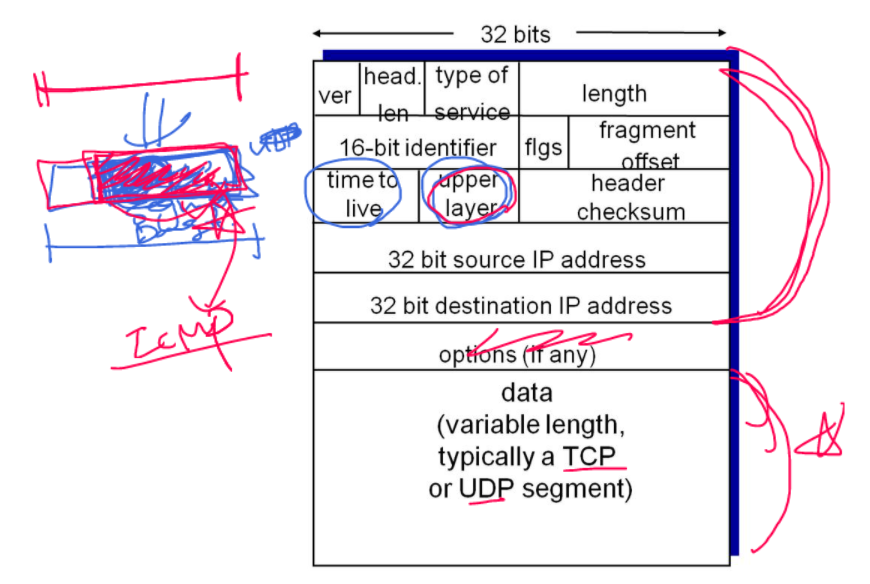
별표 친 두 부분이 서로 대응되는 4계층에서 내려온 데이터 부분이다. 이 데이터 안에는 data 뿐만 아니라 ICMP 프로토콜의 내용도 이곳에 들어가 있을 수 있다. 즉 네트워크 계층의 제어를 위한 정보가 ICMP인데, iCMP 정보가 upper layer에 기록이 되어있다.
header checksum
헤더의 체크섬이 들어간다. 체크섬이란, 20바이트인 헤더를 2바이트(16비트)씩 자르면 2바이트가 10개가 나온다. 이걸 다 더해서 1의 보수를 header checksum에 기재한다.

주의할 것은, 아래 데이터의 체크섬이 아니라, 헤더의 체크섬이다. 헤더가 깨졌는지 안깨졌는지를 파악하는 것이지 데이터가 깨졌는지 안깨졌는지를 확인하는 것이 아니다.
상황을 만들어보자.
호스트가 라우터로 데이터를 보낼 때, 헤더를 2바이트씩 자른 것을 다 더한 것의 1의 보수를 checksum 에 기재한다. 데이터를 받은 라우터는 자신의 받은 헤더를 또 2바이트씩 잘라 더한 것의 1의 보수를 계산한 다음, header checksum과 같다면 데이터를 잘 받았다고 생각한다. 제대로 왔군! 안깨졌어!
근데, 현재 라우터에서 그 다음 라우터로 보낼 때, header checksum이 그대로 가지 않는다. 그 이유는 time to live 정보가 바뀌기 때문이다. 업데이트 된 헤더체크섬이 라우터로 전송된다.
REMEMBER : Header checksum 은 매번 업데이트 되어 다음 라우터로 전송
32 bit source IP address
ip 버전 4에서는 32bit, 버전 6는 128비트
3계층에서 가장 중요한 것은 뭐니뭐니 해도 IP이다. 라우터들은 ip주소에 기반하여 라우팅을 한다. source ip에는 자기 자신의 ip가 적혀있다.
32 bit destination IP address
ip 패킷 단편화 (ip fragmentation)
ip 데이터그램의 헤더에서, 16bit ID, flags, offset이 있다고 했다. 헤더부분에서 이 세가지가 32bit를 차지하고 있는데 이 부분이 ip패킷의 단편화를 담다앟고 있다.
16bit ID : 패킷의 번호
flags :
offset :
1계층에서 전송 매체에 따라 보낼 수 있는 데이터의 크기가 달라진다. 그러므로, 매체에 따라 2계층에서의 프레임의 크기가 달라진다. 이더넷에서의 프레임의 크기는?
2계층 프레임에서, 헤더와 트레일러 제외한 데이터를 페이로드라 하는데, 페이로드에는 3계층에서 내려온 패킷(데이터그램)이 들어가게 된다.
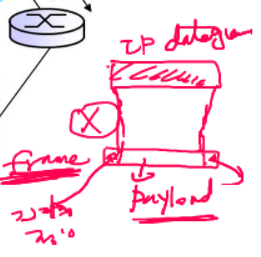
페이로드의 크기는 제한이 되어있는데, 46바이트~1500바이트까지의 크기만 들어갈 수있다. 이더넷(랜선)을 사용하고 있을 때에 해당한다.
근데 문제는, 모든 라우터가 전부 이더넷을 사용하고 있는 것은 아니다. 예를들어 광역네트워크 같은 링크의 경우 데이터의 크기가 1500바이트보다 더 작아야 한다...
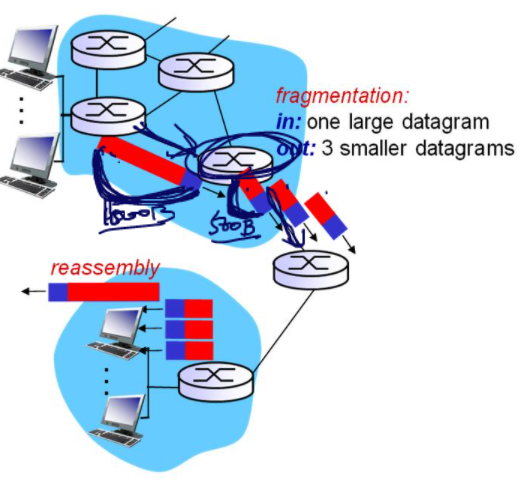
매체마다 한번에 전송가능한 프레임의 크기가 제한되어있고, 매체마다 다르기 때문에 프레임에 들어가는 페이로드의 크기가 달라진다.
위 그림에서는 첫번째 라우터는 1500바이트의 데이터를 한번에 전송가능한 매체여서 한번에 1500바이트를 보냈다. 그러나 받은 라우터에서는 한번에 500바이트밖에 보내재 못해서, 받은 패킷(데이터 그램)을 쪼개어 3개로 만든 뒤 500 바이트씩 보낸다.
즉 3개의 프레임이 되었다.
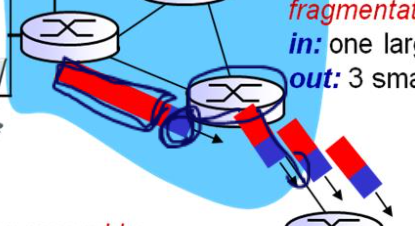
빨간 부분이 패킷(데이터그램)이고, 파란 부분이 데이터그램 헤더이다.
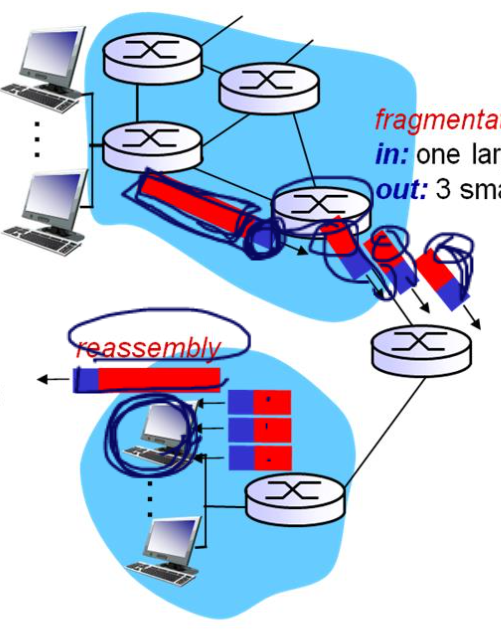
3개를 받은 Host는 다시 reassemble한다.
중간의 라우터들은?
절대 쪼개진 데이터들을 합치지 않는다. 그냥 쪼개진 데이터들을 보낸 뒤 마지막 호스트에서 합친다.
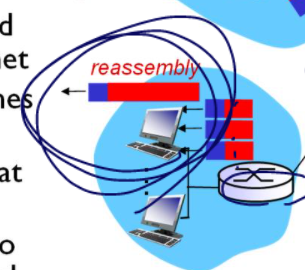
중간중간 라우터들이 설령 합쳐 보낼 수 있는 매체를 사용한다고 해서 쪼개진 패킷을 절대 합치지 않는다. 라우터들은 단순함을 추구하기 때문에 합치지 않는다. 마지막에 있는 호스트에서 합친다.

MTU : Maximum Tranfer Unit
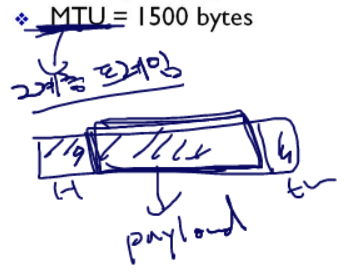
2계층 프레임의 페이로드를 MTU라고 한다. 페이로드는 IP데이터그램이다.
IP 데이터 그램의 크기가 MTU 인 것이다.
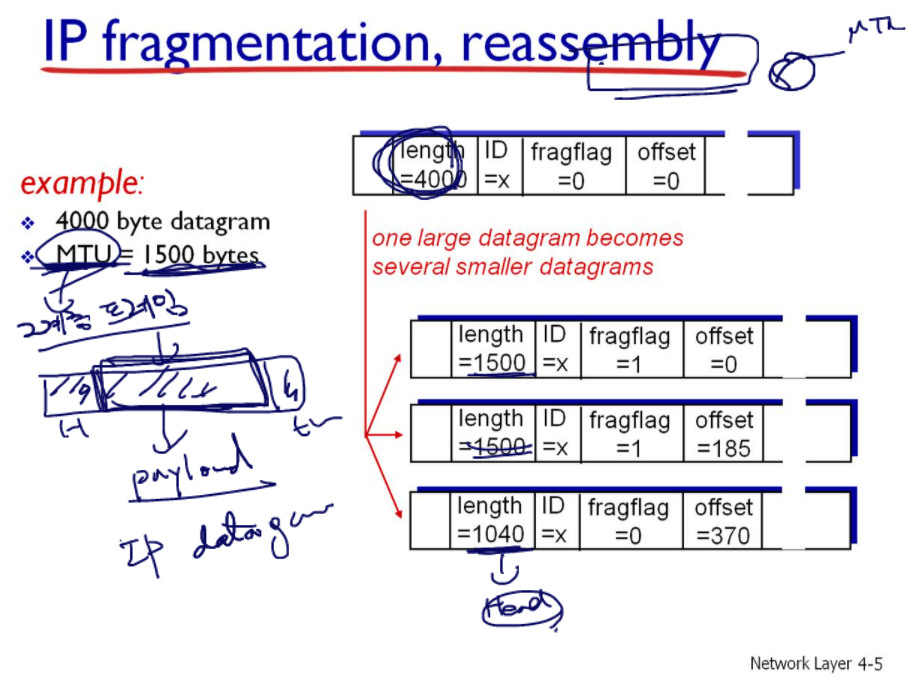
어떤 라우터가 데이터를 받았는데, 4000 바이트였다. 근데 이 라우터는 MTU가 1500바이트라면, 데이터를 쪼개 보내야 한다. 마지막 데이터가 1000이 아니라 1040인 이유는 헤더때문이다.
패킷을 쪼개더라도, ID는 동일하다. flagflag가 1이라는 뜻은, 자신 말고도 뒤에 또 다른 데이터가 올 것이라는 것을 알려주는 표시이다. 즉 자신이 마지막 조각이 아니라는 뜻이다. 만약 마지막 조각이면 0이라고 기재한다.
이렇게 다음 데이터가 올것이다/마지막이다 를 기재해주는 이유는, 마지막 호스트에서 조각들을 reassemble 을 위해 순서를 알게 하기 위함이다.
조각들을 보낼 때 순서대로 보낸다고해서 목적지에 순서대로 도착하지 않는다. 순서가 바뀔수도 있다. 데이터의 순서를 알게 하기 위해 offset을 쓴다. 위 그림에서는 0번, 185번, 370번 이다. 숫자가 작을수록 앞의 데이터라는 뜻이다.

offset은 단위가 8바이트로 나눈 데이터를 쓴다. 즉 쪼개진 첫번쨰 패킷의 헤더 제외한 데이터의 크기는 1480인데, 이를 8바이트로 나눈 값을 적어준다.
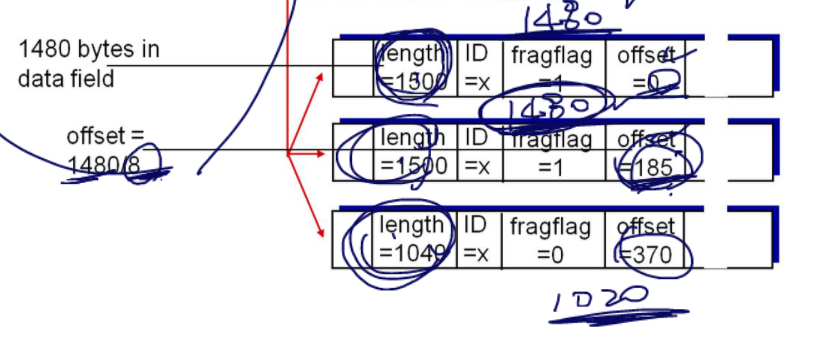
offset을 통해 순서를 알고, flag를 통해 마지막데이터인지 아닌지 확인한 후, 마지막이라면 재조립(reassemble)을 시작한다.
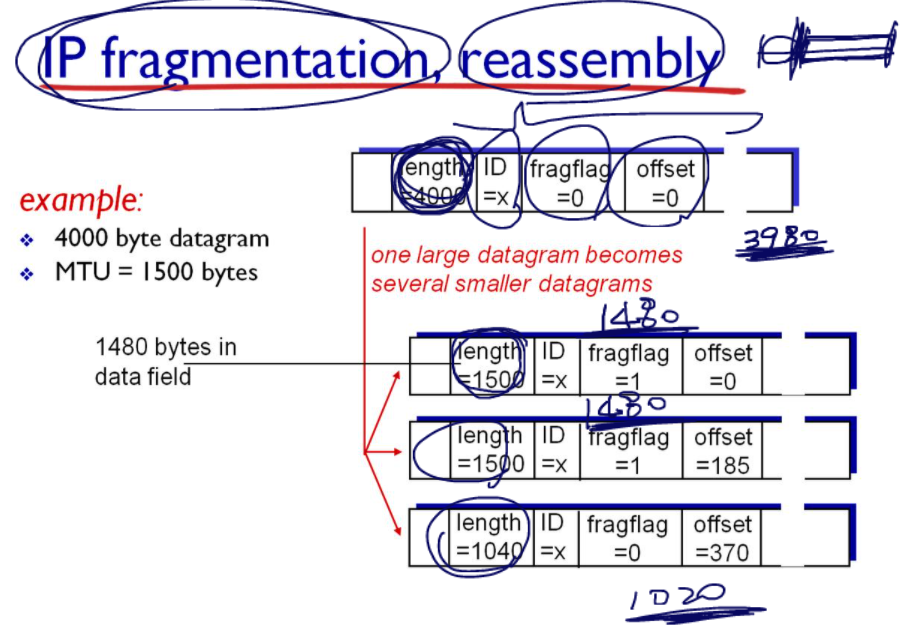
처음, 받은 ip데이터그램의 크기는 4000바이트이다. 이 중 20바이트는 헤더로, 나머지 크기는 3980바이트이다.
쪼갠 패킷들을 보면, 첫번째 패킷(데이터그램)의 경우 헤더가 20바이트, 데이터 크기는 1480이다. 두번째 패킷 또한 마찬가지로 1480이다.
마지막 패킷의 경우, 1020이 되어야 총 데이터 3980이 된다.
3980 = 1480 + 1480 + 1020
