OCR : 이미지나 영상에 존재하는 글자들을 찾아내고 해당 문자들을 출력하는 것. OCR은 이미지를 Input으로 사용하고 텍스트를 Output으로 하기 때문에 딥러닝에서 CNN과 RNN이 합쳐진 복합 구조의 모델이 주로 사용됨

OCR = Text Localization + Text Recognition
Object detection = Object Localization + Object Recognitio
OCR 이 더 어렵다고 함. 왜냐,
- 종횡비가 들쭉날쭉 (직사각형의 ratio가 다양함)
- Large distortion
- few pretrained models(Object Detection은 문제가 워낙 오래되었기에 미리 학습된 모델(이미지넷 등)을 사용하여 여기서부터 시작할 수 있음. 그러나 텍스트의 경우 이러한 모델들을 사용할 수 없기에 어려움)
- various languages
위와 같은 이유들로 인해 OCR is more challlenging...
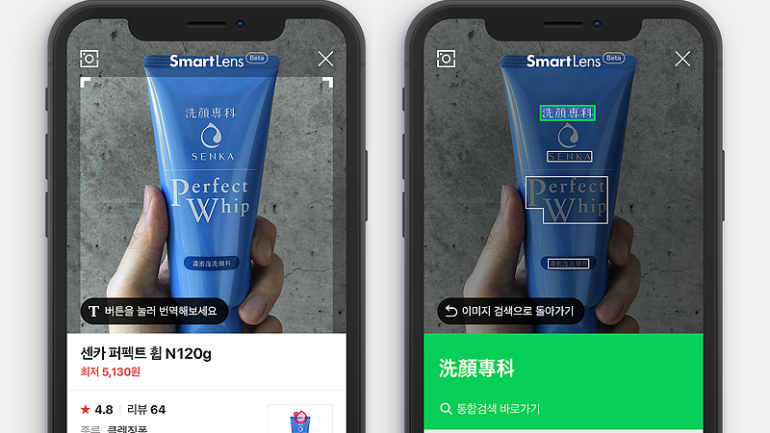
Text Localization
텍스트의 위치를 찾는 것이다. 텍스트가 있을 때 그것의 바운딩 박스를 찾는 것!
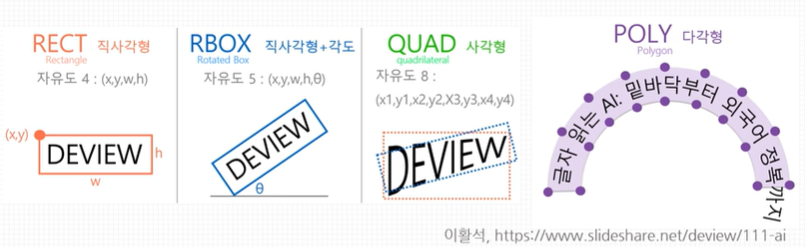
Localization을 위한 3가지 방법으로,

Text Recognition
보통 recognition은 image classification인데, text recognition의 경우는 시퀀스를 classification해야 한다. 즉 글자 하나하나를 분류해야된다.
시퀀스 classification하면 음성인식이 사실 먼저 떠오름.
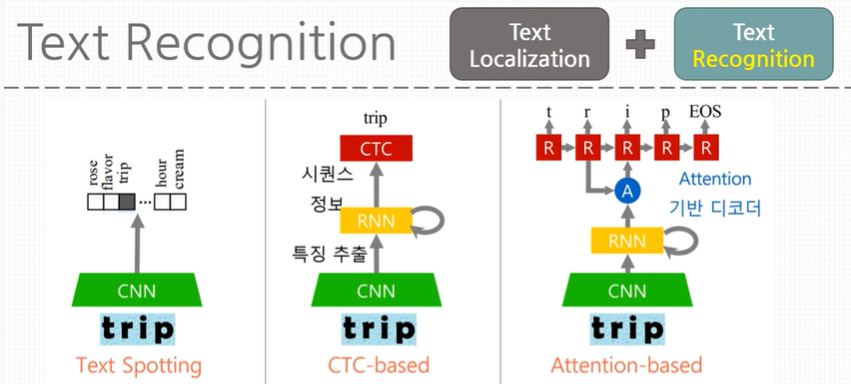
정리
OCR은 딱 두가지다. Localization과 Recognition을 하는 것! 그래서 Object Detection과 굉장히 비슷한데 BUT 텍스트라는 특성에 맞게 modification을 해주어야 한다.
OCR을 공부하려면, 우선 Object Detection을 먼저 공부해야하는데, Oject Detection을 하려면 Image Recognition이 수반되어야 하니 이에 대한 공부가 선행되어야 한다.
제일 먼저! Image Recognition에 대해 공부해보자!
