
1. 카프카의 주요 특징
- 높은 처리량
- 보낼 때와 받을 때 모두 배치로 묶어서 네트워크 전송이 가능하다.
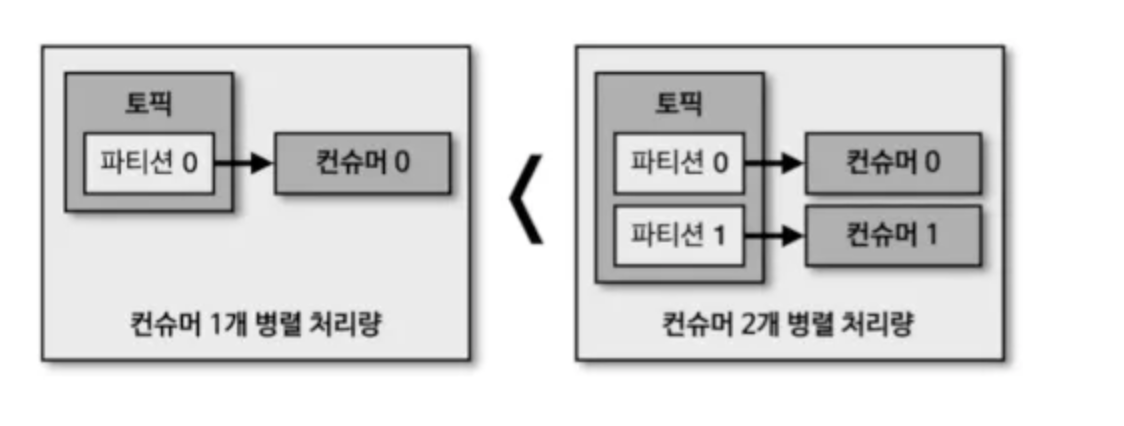
- 파티션 개수만큼 컨슈머 개수를 늘려서 동일 시간당 데이터 처리량을 늘릴 수 있다.
- 확장성
- 데이터의 상황에 맞게 브로커의 갯수를 늘리거나(scale-out) 줄여 (scale-in)할 수 있다.
- 스케일 아웃과 스케일 인은 클러스터의 무중단 운영을 지원하므로 안정적인 운영이 가능하다.
- 영속성
- 카프카는 데이터를 메모리에 저장하지 않고 파일 시스템에 저장한다. (재시작하여도 복구가능)
- 여기서 I/O 성능향상을 위해 페이지 캐시 영역을 메모리에 따로 생성하여 사용
- 고가용성
- 3개 이상의 브로커로 구성된 클러스터는 일부 서버에 장애가 발생하더라도 무중단으로 안전하고 지속적으로 데이터를 처리할 수 있다. (리플리케이션)
2. 주요 구성 요소
Topic
- 클러스터 내 메시지가 저장되는 장소
- 논리적인 저장소
- 각 토픽의 이름은 카프카 내에서 고유하다.
Producer
- 메시지를 생성(Produce)해서 Kafka의 Topic으로 메시지를 보내는 애플리케이션
Consumer
- Topic의 메시지를 가져와서 소비(Comsume)하는 애플리케이션
Comsumer Group
- Topic의 메시지를 사용하기 위해 협력하는 Consumer들의 집합
- 하나의 Consumer는 하나의 Consumer Group에 포함되며, Consumer Group 내의 Consumer들은 협력하여 topic의 메시지를 분산 병렬 처리한다.
💡 Producer와 Consumer의 Decoupling
- Producer와 Consumer는 서로 알지 못하며, Producer와 Consumer는 각각 고유의 속도로 Commit Log에 Write 및 Read를 수행한다.
- 다른 Consumer Group에 속한 Consumer들은 서로 관련이 없으며, Commit Log에 있는 Event(message)를 동시에 다른 위치에서 Read할 수 있다.
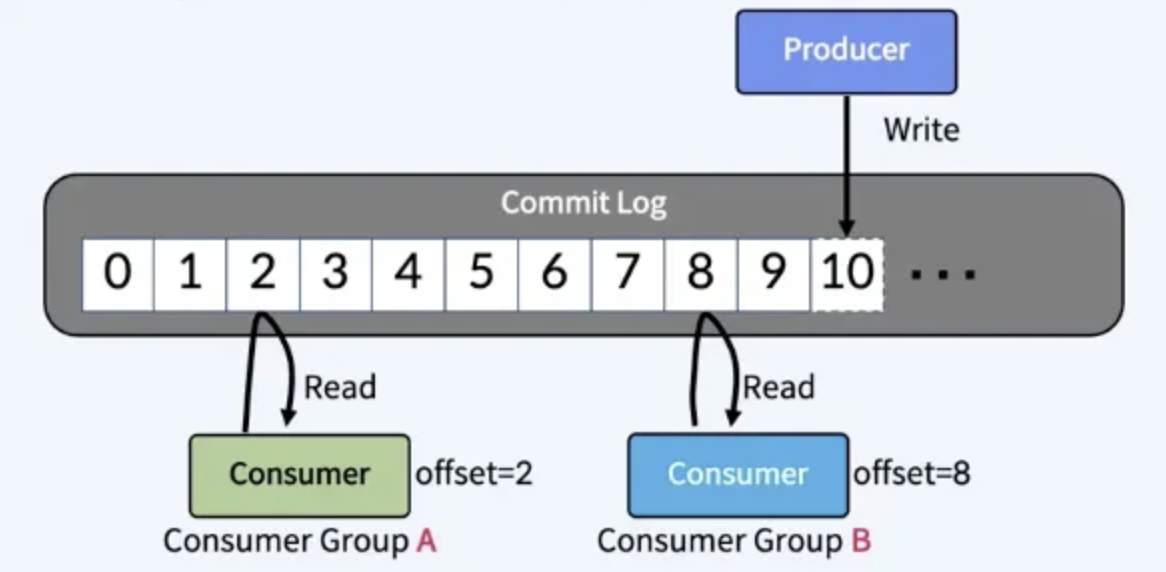
Commit Log
- 추가만 가능하고 변경은 불가능한 데이터 스트럭처
- 데이터는 항상 로그 끝에 추가되고 변경되지 않음
- offset : Commit Log에서의 Event위치
- consumer lag : 컨슈머가 읽은 current offset과 write log의 차이
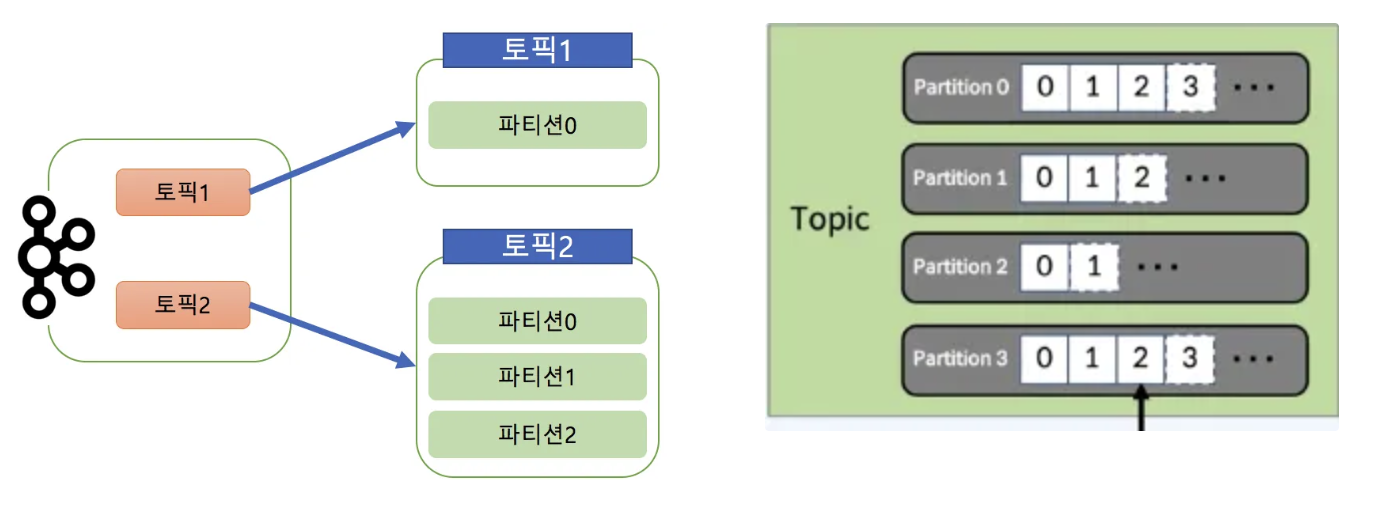
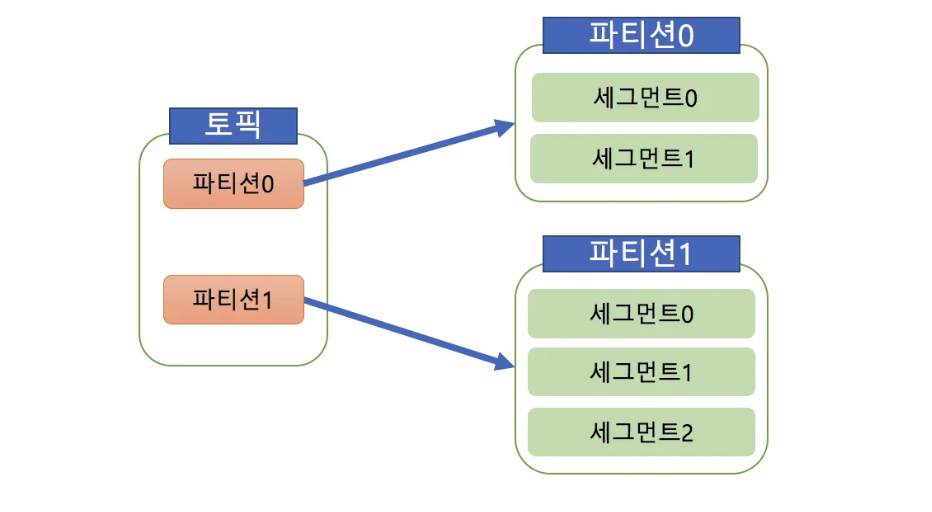
Partition
- 토픽을 구성하는 데이터 저장소로서 수평확장이 가능한 형태
- Commit Log, 하나의 Topic은 하나 이상의 Partition으로 구성
- 병렬 처리를 위해서 다수의 Partition을 사용
- Topic 생성시 Partition의 개수를 지정하고, 각 partition은 Broker들에 분산된다.
- Partition 번호는 0부터 시작하고 오름차순이다.
- Topic 내 partition들은 서로 독립적이다.
- Event의 위치를 나타내는 offset이 존재한다.
- offset은 하나의 partition에서만 의미를 가진다.
- offset 값은 계속 증가하고 0으로 돌아가지 않는다.
- event의 순서는 하나의 Partition에서만 보장한다.
- Partition에 저장된 데이터는 변경이 불가능하다 (Immutable)
- Partition은 Segment File들로 구성된다.
💡 파티션 개수와 컨슈머 개수의 처리량
- 파티션 개수 ≥ 컨슈머 개수
- 파티션 개수를 운영 중에 줄이는 것은 불가능하다.
Segment
- 메시지가 저장되는 실제 물리 File
- Segment File이 지정된 크기보다 크거나 오래된 경우 새로운 파일을 만든다. (Rolling Strategy)
- Partition당 오직 하나의 Segment가 활성화 되어있다. (데이터가 계속 쓰여지는 중)
- 압축 시 non-active segment 중에서 가장 최근 데이터만 남고 삭제된다.
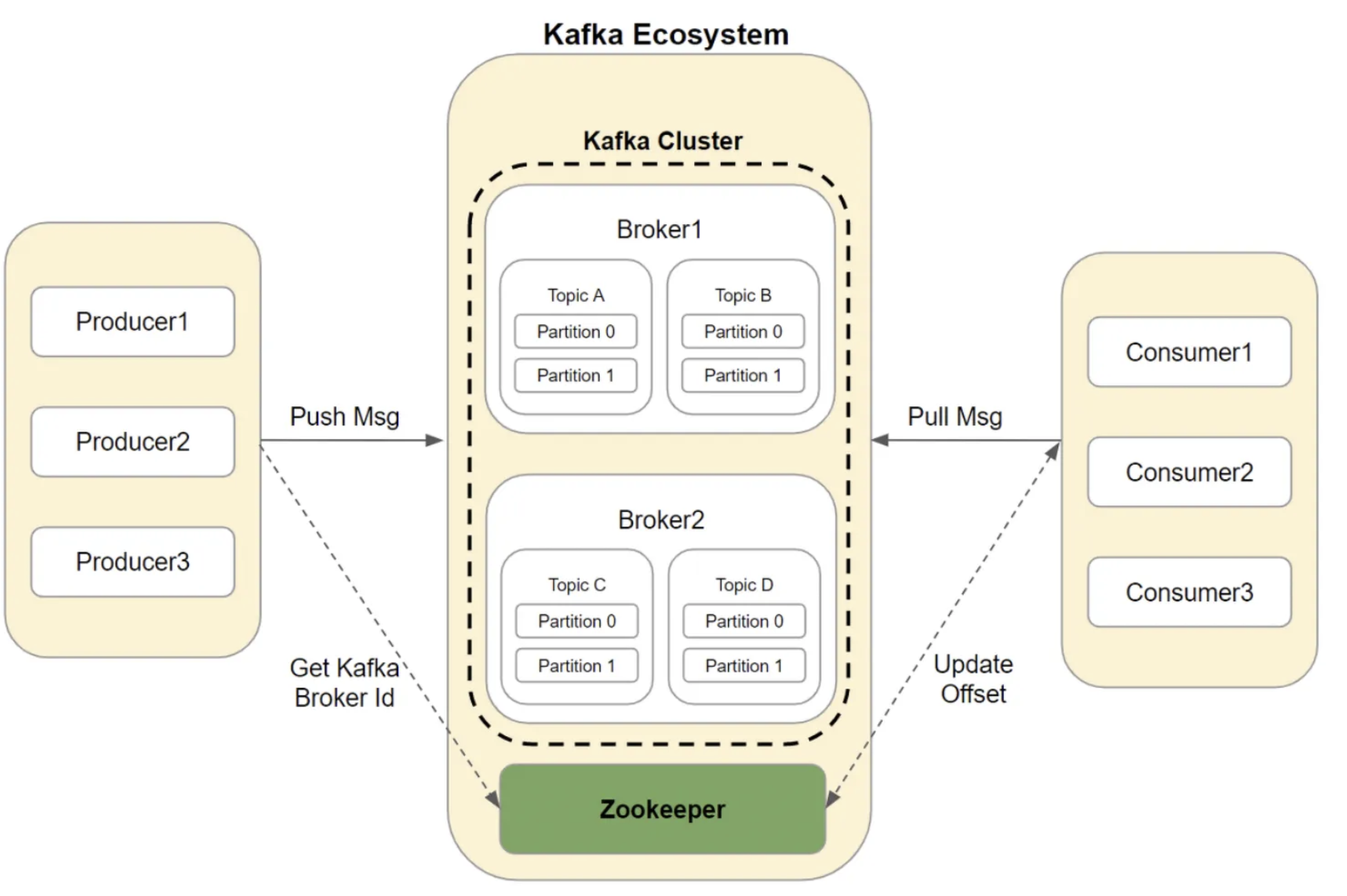
Broker
- Kafka Server라고 부르기도 함
- Topic내의 Partition들을 분산, 유지 및 관리
- Partition에 대한 Read 및 Write를 관리하는 소프트웨어
- 각각의 Broker들은 ID로 식별됨 (숫자)
- Broker ID와 Partition ID는 아무런 관계가 없음 → 어느 순서에나 있을 수 있음
- Topic의 일부 Partition들을 포함
- Topic 데이터의 일부분(Partition)을 갖을 뿐, 데이터 전체를 갖고 있지 않음
- Kafka Cluster : 여러 개의 Broker들로 구성됨 (최소 3개이상, 4개 이상을 권장)
- Client는 특정 Broker에 연결하면 전체 클러스터에 연결된다.
- 모든 Kafka Broker는 부트스트랩 서버라고 부른다.
- 특정 Broker 장애를 대비하여 전제 Broker List를 파라미터로 입력이 권장된다.
- Topic을 구성하는 Partition들은 여러 Broker 상에 분산된다.
- Topic 생성시 Kafka가 자동으로 Topic을 구성하는 전체 Partition들을 모든 Broker에게 할당해주고 분배해준다.
- 브로커의 역할
- 컨트롤러 : 다수 브로커 중 한 대가 컨트롤러 역할을 한다. 다른 브로커들의 상태를 체크하고 리더 파티션을 재분배하는 역할을 한다.
- 데이터 삭제 : 브로커만이 로그 세그먼트 단위로 데이터를 삭제할 수 있다. (시간 또는 용량에 따라..)
- 컨슈머 오프셋 저장 : 파티션의 어느 레코드까지 가져갔는지 오프셋을 커밋한다.
__consumer_offsets토픽에 저장한다. - 그룹 코디네이터 : 컨슈머 그룹의 상태를 체크하고, 파티션을 컨슈머와 매칭되도록 분배하는 역할을 한다.
Rebalance - 데이터의 저장 : config/server.properties의 log.dir 옵션에 정의한 장소에 데이터를 저장한다. 토픽이름과 파티션 번호의 조합으로 하위 디렉토리를 생성
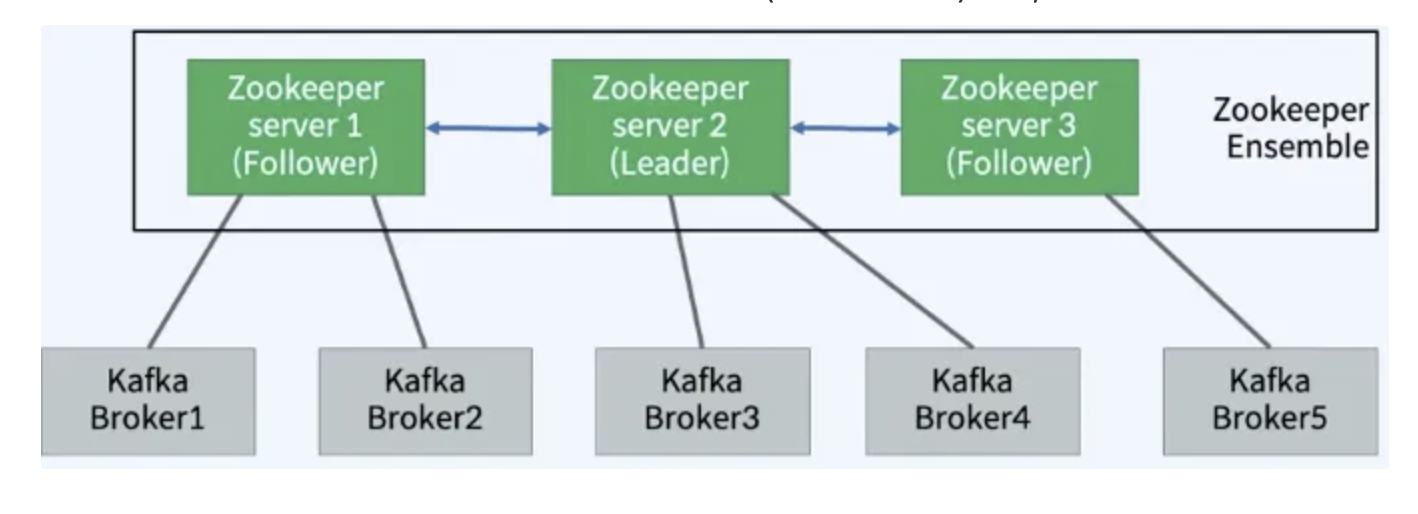
Zookeeper
- 카프라 Broker들을 관리한다. (목록, 설정 등)
- 변경사항에 대해 Kafka에 알린다.
- Topic 생성/제거
- Broker 추가/제거
- 분산형 Configuration 정보를 유지, 분산 동기화 서비스를 제공하고, 대용량 분산 시스템을 위한 네이밍 레지스트리를 제공하는 소프트웨어
- root znode에 각 클러스터별 znode를 생성하고 클러스터 실행시 root가 아닌 하위 znode로 설정
- 분산작업을 제어하기 위한 Tree 형태의 데이터 저장소
- 주키퍼를 사용하여 멀티 Kafka Broker들 간의 정보(변경 사항 포함) 공유, 동기화 등을 수행한다.
Record(Message)
- Message = Record = Event = Data
- Header, Key, Value로 구성된다.
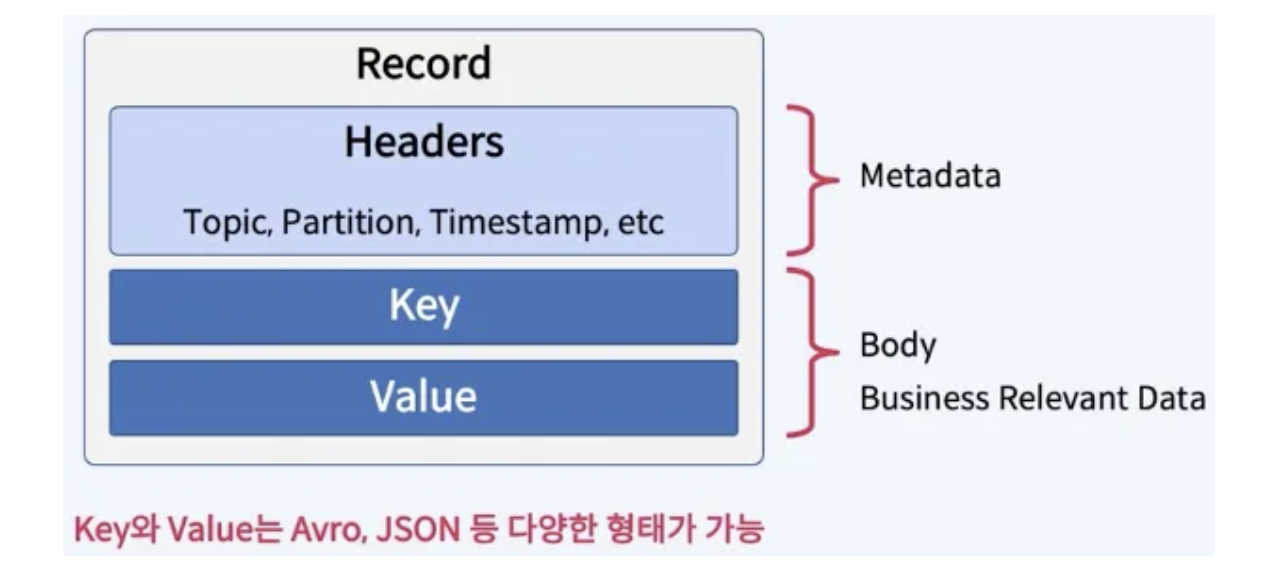
- Serializer를 통해 ByteArray로 바꿔서 카프카에 저장한다.
- key와 value는 각각 다른 Serializer를 사용해서 변환을 한다.
