1. Producing to Kafka
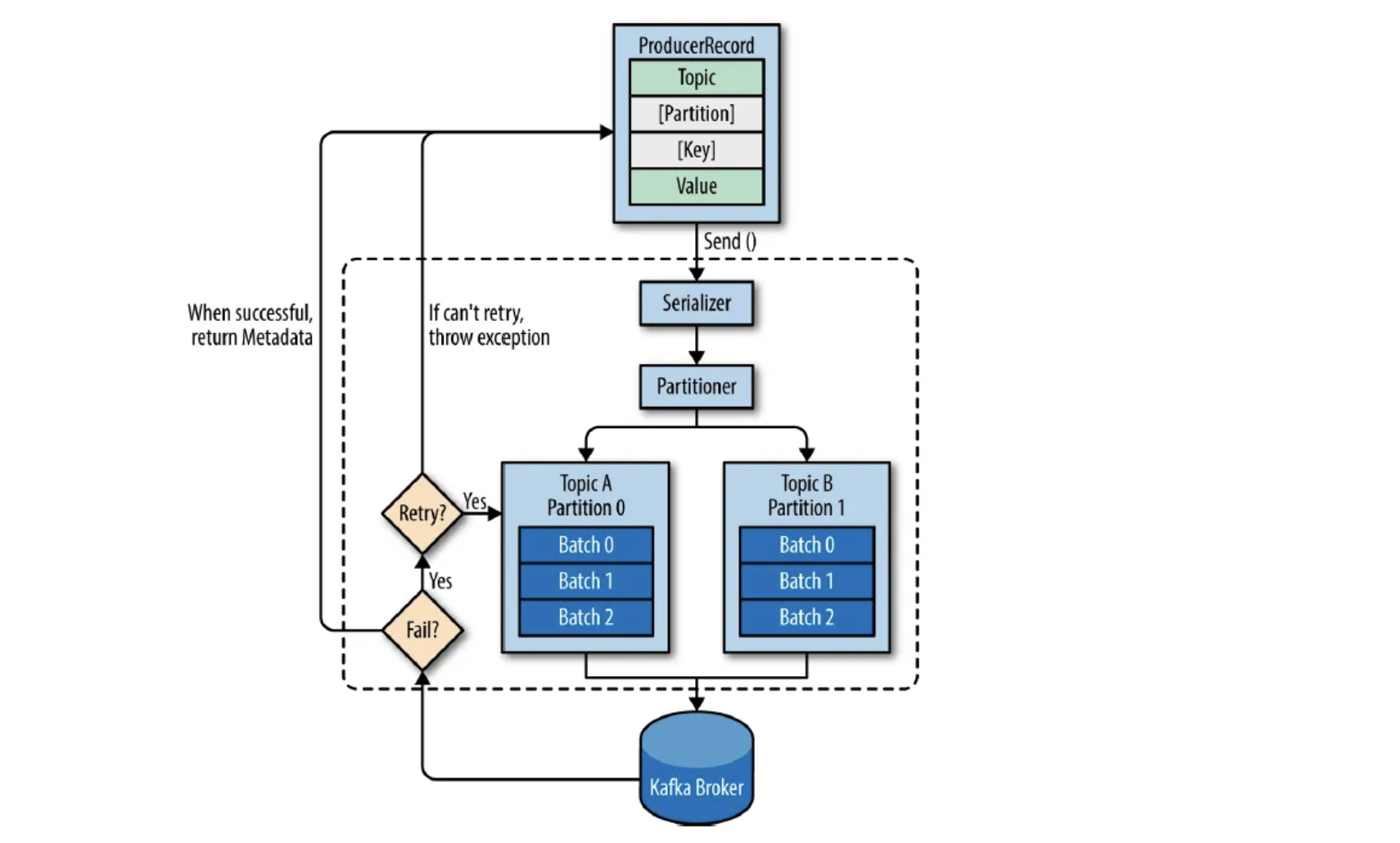
1. Producer Record
- Topic, Value (required)
- Send()
- Serializer
- Consumer는 Deserializer를 사용
- Partitioner
- 메시지를 Topic의 어떤 Partition으로 보낼지 결정
- Key가 null이 아닐 때 :
Partition = Hash(key) % Number of Partitions - Key가 null일 때 : Round Robbin 정책으로 동작(2.4 이전) → Sticky 정책으로 동작 (2.4 이후, Batch가 닫힐 때까지 하나의 partition으로 보내고 랜덤으로 Partition 선택)
- Compress (optional)
- RecordAccumulator
- to Kafka
2. Consuming from Kafka
- Consumer는 각각 고유의 속도로 Commit Log로 부터 순서대로 Read(Poll)를 수행
- 다른 Consumer Group 에 속한 Consumer들은 서로 관련이 없으며, Commit Log에 있는 Event(Message)를 동시에 다른 위치에서 Read 할 수 있음
Consumer Offset
- Consumer Group이 읽은 위치를 표시
- Consumer가 자동이나 수동으로 데이터를 읽은 위치를 commit하여 다시 읽음을 방지한다.
- Consumer가 가지고 있는게 아니라 카프카 내부에 기록한다. 때** : Round Robbin 정책으로 동작(2.4 이전) → Sticky 정책으로 동작 (2.4 이후, Batch가 닫힐 때까지 하나의 partition으로 보내고 랜덤으로 Partition 선택)
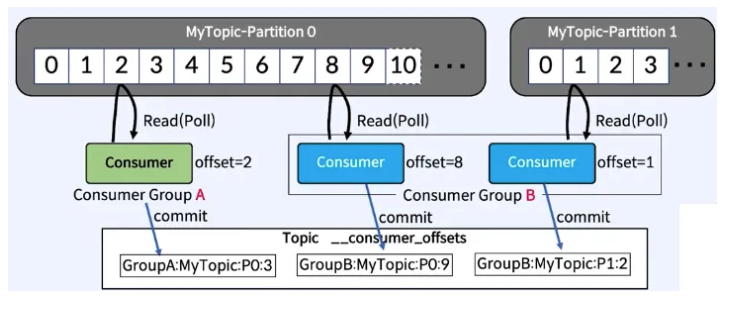
Multi-Parition with Single Consumer
- 모든 파티션에서 순차적으로 컨슘
- 하나의 consumer는 각 partition에서의 consumer offset을 별도로 유지(기록)한다.
Consuming as a Group
- 동일한 group.id로 구성된 모든 Consumer들은 하나의 Consumer Group을 형성
- 4개의 파티션이 있는 Topic을 consume하는 4개의 Consumer가 하나의 Group안에 있다면, 각 Consumer당 정확히 하나의 partition에서 record를 consume한다.
- Partition은 항상 Consumer Group 내의 하나의 Consumer에 의해서만 사용된다.
- Consumer는 주어진 Topic에서 0개 이상의 많은 Partition을 사용할 수 있다.
Multi Consumer Group
- Partition을 분배하여 Consume
- Consumer Group의 Consumer들은 작업량을 어느 정도 균등하게 분할한다.
- 동일한 Topic에서 consume하는 여러 Consumer Group이 있을 수 있다. (각자 독립적으로 동작)
3. Message Ordering (순서)
- Partition이 2개 이상인 경우 모든 메시지에 대한 전체 순서 보장 불가능
- Parition을 1개로 구성하면 모든 메시지에서 전체 순서 보장 가능 - 처리량 저하 (병렬 처리 불가)
- 전체 순서를 꼭 보장해야 하는 경우는 비즈니스 상황에서 많지 않다.
- 동일한 Key를 가진 메시지는 동일한 Parition에서만 전달되기 때문에 Key레벨에서 순서 보장이 가능하다.
- multi-partition 사용 가능 = 처리량 증가
- 따라서 운영중에 Partition 개수를 변경하면 순서보장이 불가하다.
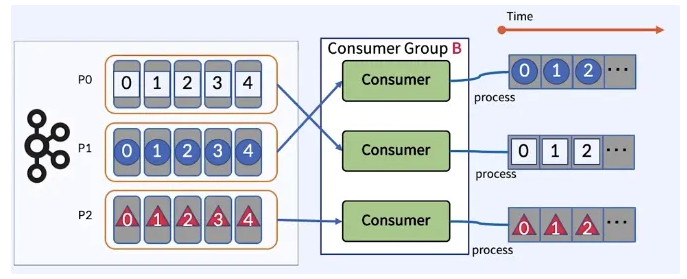
Key Cardinality
- Cardinality = 특정 데이터 집합에서 유니크(unique)한 값의 개수
- Key Cardinality는 Consumer Group의 개별 Consumer가 수행하는 작업의 양에 영향을 미친다.
- Key 선택이 잘못되면 작업 부하가 고르지 않을 수 있다.
- Key는 Value와 마찬가지로 Avro, Json등 여러 필드가 있는 복잡한 객체로 만들 수 있다.
- 핵심은 Partition 전체에 Record를 고르게 분포할 수 있는 key를 만드는 것이 중요
4. Consumer Failure
Consumer Rebalancing
- Consumer Group 내의 다른 Consumer가 실패한 Consumer를 대신하여 Partition에서 데이터를 가져와서 처리한다.
- Parition은 항상 Consumer Group내의 하나의 Consumer에 의해서만 사용된다.
- Consumer는 주어진 Topic에서 0개 이상의 많은 Partition을 사용할 수 있다.
5. Replication
- Broker에 장애가 발생하면? → 장애가 발생한 브로커의 Parition은 모두 사용할 수 없게 되는 상황
- 이때 해결책으로 다른 Broker에서 장애난 Partition을 가져가서 새로 만든다면?
- 기존 메시지와, offset 정보가 유실된다!
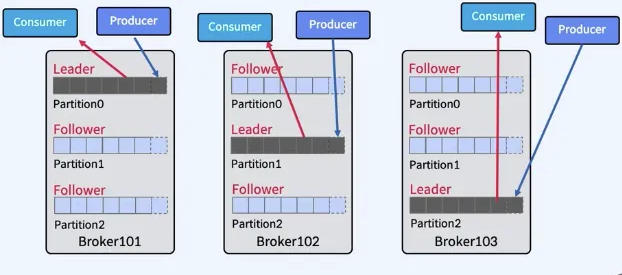
- Parition을 복제하여 다른 Broker상에서 복제물(Replicas)을 만들어서 장애를 미리 대비하는 것을 Replication이라고 한다.
- Replicas - Leader Parition, Follower Partition
- Producer는 Leader에만 Write하고 Consumer는 Leader로부터만 Read 한다.
- Follower는 Broker 장애시 안정성을 제공하기 위해서만 존재한다.
- Follower는 Leader의 Commit Log에서 데이터를 가져오기 요청(Fetch Request)으로 복제한다.
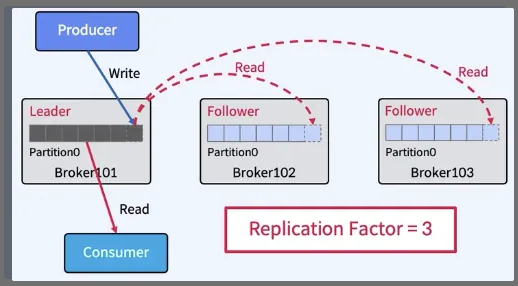
- Leader에 장애가 발생하면?
- Kafka 클러스터는 Follower 중에서 새로운 Leader를 선출한다.
- Clients(Producer/Consumer)는 자동으로 새 Leader로 전환한다.
- Partition Leader에 대한 자동 분산 (Hot Spot 방지)
- 리플리케이션 팩터 수가 커지면 안정성은 높아지지만, 그만큼 브로커 리소스를 많이 사용하게 된다.
- 운영환경에서 리플리케이션 팩터 3이면 충분
6. In-Sync Replicas(ISR)
- Leader 장애시 Leader를 선출하는데 사용
- In-Sync Replicas(ISR)는 High Water Mark라고 하는 지점까지 동일한 Replicas (Leader와 Follower모두)의 목록
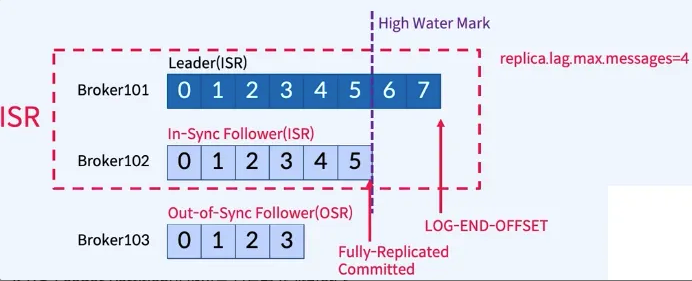
- replica.lag.max.messages 를 가지고 판단하면, 메시지 유입량이 갑자기 늘어났을때 , OSR로 판단이 될 수 있다.
- replica.lag.time.max.ms으로 판단해야한다. (follwer가 fetch하는 interval)
- ISR은 Leader Partition이 떠있는 브로커가 관리한다.
- Zookeeper에 ISR 업데이트, Controller가 Zookeeper로 부터 수신
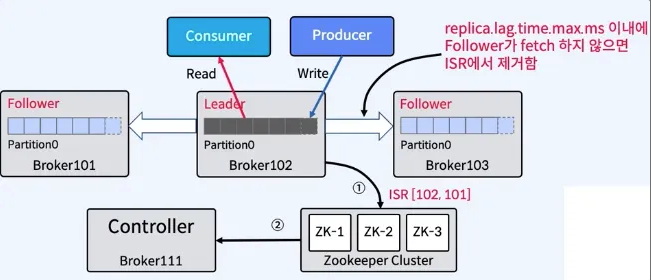
Controller
- Kafka Cluster 내의 Broker중 하나가 Controller가 된다.
- Controller는 Zookeeper를 통해 Broker Liveness를 모니터링한다.
- Controller는 Leader와 Replica 정보를 Cluster내의 다른 Broker들에게 전달한다.
- Controller는 Zookeeper에 Replicas정보의 복사본을 유지한 다음 더 빠른 액세스를 위해 클러스터의 모든 Broker 들에게 동일한 정보를 캐시한다.
- Controller가 Leader 장애시 Leader Election을 수행한다.
- Controller가 장애나면 다른 Active Broker들 중에서 재선출된다.
Consumer 관련 Position들
- Last Committed Offset(Current Offset) : Consumer가 최종 Commit한 Offset
- Current Position : Consumer가 읽어간 위치 (처리 중, Commit 전) 배치 때문에 차이날 수 있음
- High Water Mark(Commited) : ISR (Leader-Follower)간에 복제된 Offset
- Log End Offset : Producer가 메시지를 보내서 저장된 로그의 맨 끝 Offset
- Consumer Log : Log End Offset - Last Committed Offset
Committed
- ISR 목록의 모든 Replicas가 메시지를 받으면 “Committed” (fully-replicated)
- Consumer는 Committed 메시지만 읽을 수 있다. (High Water Mark)
- Leader는 메시지를 Commit할 시기를 결정한다.
- Committed 메시지는 모든 Follwer에서 동일한 Offset을 갖도록 보장한다.
- 즉, 어떤 Replica가 Leader인지 관계없이 모든 Consumer는 해당 Offset에서 같은 데이터를 볼 수 있다.
- Broker가 다시 시작할 때 Committed 메시지 목록을 유지하기 위해 Broker의 모든 Partition에 대한 마지막 Committed Offset은 replication-offset-checkpoint라는 파일에 기록된다.
High Water Mark
- 가장 최근에 Committed 메시지의 Offset 추적
- replication-offset-checkpoint 파일에 체크포인트를 기록한다.
Leader Epoch
- 새 Leader가 선출된 시점을 Offset으로 표시
- Broker 복구 중에 메시지를 체크포인트로 자른 다음 현재 Leader를 따르기 위해 사용됨
- Controller가 새 Leader를 선택하면 Leader Epoch를 업데이트하고 해당 정보를 ISR목록의 모든 구성원에게 보낸다.
- leader-epoch-checkpoint 파일에 체크포인트를 기록한다.
- 팔로워는 자신의 하이워터마크보다 높은 오프셋의 메시지를 무조건 삭제하지 않고, 먼저 리더에게 리더에포크 요청을 보내 응답을 받아서 최종 커밋된 오프셋 위치를 확인한다.
Message Commit 과정
Follwer에서 Leader로 Fetch만 수행
- Producer가 새로운 메시지를 발행한다.
- Follwer는 Fetcher Thread를 통해 계속 polling을 하며 새 데이터를 가져오고 (있으면) write한다.
- 다음 polling에 받은 데이터가 null이면 Leader는 High Water Mark를 증가시킨다.
- 그 다음 polling에 Leader는 high water mark를 주고, follower도 high water mark를 증가시킨다.
