내부구조
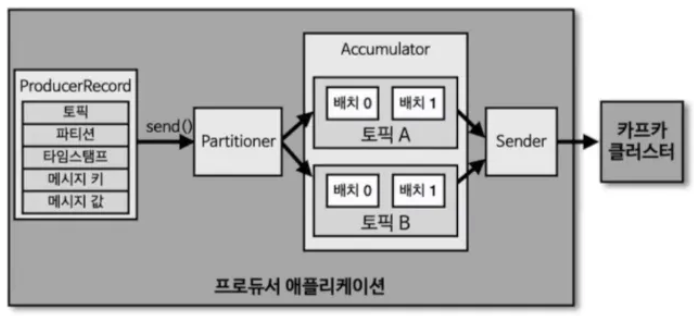
- ProducerRecord : 프로듀서에서 생성하는 레코드, 오프셋은 미포함
- send() : 레코드를 전송하는 요청 메서드
- Partitioner : 어느 파티션으로 전송할지 지정하는 파티셔너. 기본값으로 DefaultPartitioner로 설정
- Accumulator: 배치로 묶어 전송할 데이터를 모으는 버퍼
Partitioner
- 일단 메시지 키가 있을 때는 메시지 키의 해시값과 파티션을 매칭하여 레코드를 전송
- 만약 파티션 개수가 변경될 경우 (증가만 가능) 메시지 키와 파티션 번호의 매칭은 깨지게 됨
- 라운드 로빈 전략
- ProducerRecord가 들어오는 대로 파티션을 순회하면서 전송
- 어큐뮤레이터에서 묶이는 정도가 적기때문에 전송 성능이 낮음
- 스티키 파티셔닝 전략
- 레코드들이 배치로 묶일 때까지 기다렸다가 전송
- 배치로 묶일 뿐 결국 파티션을 순회하면서 보내기 때문에 모든 파티션에 분배되어 전송됨
- RoundRobinPartitioner에 비해 향상된 성능을 가짐
Producer Acks
- acks 설정은 요청이 성공할 때 정의하는 데 사용하는 Producer에 설정하는 Parameter
acks = 0: ack가 필요하지 않음. 메시지 손실이 다소 있더라도 빠르게 메시지를 보내야 하는 경우에 사용하지만 잘 사용하지 않는다.acks = 1 (default): Leader가 메시지를 수신하면 ack를 보낸다. Leader가 Producer에게 Ack를 보낸 후 Follwer가 복제하기 전에 Leader가 장애가 나면 메시지가 손실 된다.At most once(최대 한번)전송을 보장acks = -1: acks = all과 동일. 메시지가 Leader가 모든 Replica까지 Commit되면 ack를 보냄. Leader를 잃어도 데이터가 살아남을 수 있도록 보장한다. 그러나 대기 시간이 더 길고, 특정 실패 사례에서 반복되는 데이터 발생 가능성 있음At least once(최소 한번)전송을 보장
Producer Retry
- 재전송을 위한 Parameters
- 재시도(retry)는 네트워크 또는 시스템의 일시적인 오류를 보완하기 위해 모든 환경에서 중요하다.

Producer Batch
- 메시지를 모아서 한번에 전송한다.
- RPC(Remote Procedure Call) 수를 줄여서 Broker가 처리하는 작업이 줄어들기 때문에 더 나은 처리량을 제공한다.
linger.ms- default: 0, 즉시 보냄
- 메시지가 함께 Batch처리될 때까지 대기시간
- 일반적으로 100ms 를 사용
batch.size- default : 16 KB
- 보내기 전 Batch의 최대 크기
- 일반적으로 1000000 를 사용
Producer Delivery Timeout
- send() 후 성공 또는 실패를 보고하는 시간의 상한
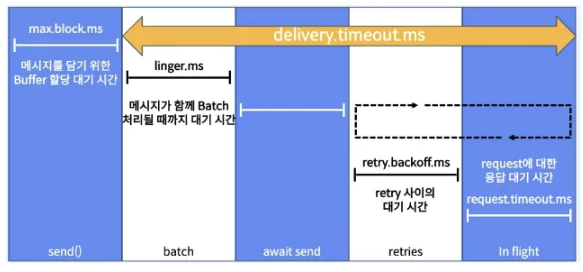
Message Send 순서 보장
max.in.flight.request.per.connection=5(default) : 하나의 네트워크에 여러 개를 동시에 날림- Batch가 중간에 1개가 실패하면 다른 배치가 먼저 Commit되면서 순서가 보장되지 않음
- enable.idempotence (true)
- 진행중(in-flight)인 여러 요청(request)을 재시도하면 순서가 변경될 수 있음
- 하나의 Batch가 실패하면, 같은 Partition으로 들어오는 후속 Batch들도 OutOfOrderSequenceException과 함께 실패한다.
Page Cache & Flush
- 메시지는 Partition에 기록됨
- Partition은 Log Segment File로 구성된다. (1G마다 새로운 Segment 생성)
- 성능을 위해 Log Segment는 OS Page Cache에 기록됨
- 로그 파일에 저장된 메시지의 데이터 형식은 Broker가 Producer로 부터 수신한 것 그리고 Consumer에게 보내는 것과 정확히 동일하므로 Zero-Copy가 가능함.
- Zero-Copy : 데이터가 User Space에 복사되지 않고 CPU 개입 없이 Page Cache와 Network Buffer사이에서 직접 전송되는 것을 의미 이를 통해 Broker Heap 메모리를 절약하고 엄청난 처리량을 제공한다.
- Page Cache는 다음과 같은 경우 디스크로 Flush 된다.
- Broker가 완전히 종료
- OS background “Flush Thread” 실행

프로듀서의 전송
적어도 한번 전송 (at least once)
- 브로커로부터 ack를 받을때까지 계속 재전송한다.
- ack만 못보낸 것인지, 저장까지 못한 것인지 알 수 없기 때문에 데이터가 중복으로 저장될 수 있다.
최대 한번 전송 (at most once)
- 메시지 중복 전송을 막기 위해 재전송을 하지 않는다.
- 브로커로부터 ack를 받든 말든 상관하지 않는다.
- 데이터 유실가능성이 있다.
중복 없는 전송
- 메시지를 저장할 때 PID(producer id)와 sequence 번호를 헤더에 포함해서 저장한다. (브로커 메모리에 저장)
- 프로듀서는 브로커로부터 ack를 받지 못하면 재전송을 한다. (ack를 받으면 메시지 번호를 1증가시켜 보낸다.)
- 저장전에 PID와 sequence 번호를 비교하여 같은 정보가 있으면 저장하지 않고, ack만 보낸다.
- Idempotent Producer
- Producer 파라미터 중 enable.idempotence를 true로 설정한다.
- Producer가 Retry를 하더라도 메시지 중복을 방지한다.
- 성능에 큰 영향이 없다.
정확히 한번 전송 (exactly once)
- Transaction 기능을 사용하여, 하나의 트랜잭션내의 모든 메시지가 모두 write되었는지 또는 전혀 write되지 않았는지 확인 (atomic message)
- 금융 거래 처리, 과금 정산을 위한 광고 조회수 추적, biling 서비스간 메시지 전송 등에 쓰인다.
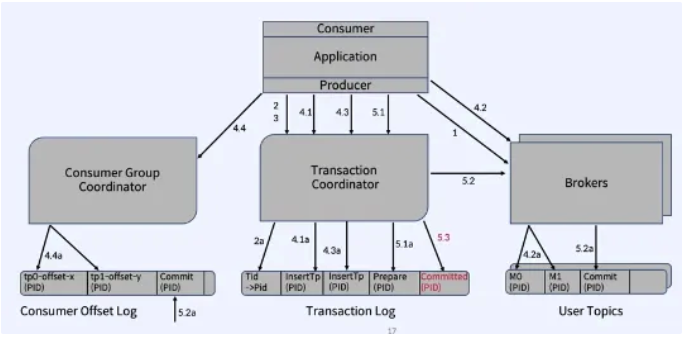
- Transaction Coordinator 사용
- 특별한 Transaction Log를 관리하는 Broker Thread
- 일련의 ID번호 (Producer Id, Sequence Number, Transaction ID)를 할당하고 클라이언트가 이 정보를 메시지 Header에 포함하여 메시지를 고유하게 식별
- Sequence Number는 Broker가 중복된 메시지를 Skip할 수 있게 함.
- 각 프로듀서에 고유한 Transaction id를 설정
- Producer를 Transaction API를 사용하여 개발
- Consumer에서 isolation.level을 read_committed로 설정 (default : read_uncommitted), auto_commit 을 false로 설정해야한다.
- 동작순서
- Transactions Coordinator 찾기
- Producer가 initTransactions()를 호출하여 Broker에게 FindCoordinatorRequest를 보내서 Transaction Coordinator의 위치를 찾음 Transaction Coordinator는 PID를 할당
- Transactions Coordinator 찾기
- Producer ID 얻기
- Producer가 Transaction Coordinator에게 InitPidRequest를 보내서(TransactionalID를 전달) Producer의 PID를 가져옴 PID의 Epoch를 높여 Producer의 이전 Zombie인스턴스가 차단되고 Transaction을 진행할 수 없도록 함
- 해당 PID에 대한 매핑이 TransactionLog에 기록
- Producer ID 얻기
- Transaction 시작
- Producer가 beginTransactions()를 호출하여 새 Transaction의 시작을 알림
- Producer는 Transaction이 시작되었음을 나타내는 로컬 상태를 기록
- 첫번째 Record가 전송될때까지 Transaction Coordinator의 관점에서는 Transaction이 시작되지 않음
- Transaction 시작
- AddPartitionsToTxnRequest
- ProduceRequest (send)
- AddOffsetCommitsToTxnRequest
- Transaction Coordinator로 보냄 partition offset 기록
- AddOffsetCommitsToTxnRequest
- TxnOffsetCommitRequest
- Producer는 __consumer_offsets Topic에서 Offset을 유지하기 위해 Consumer Coordinator에게 보낸다. Transaction이 커밋되기 전까지 해당 offset은 외부에서 볼수 없음
- TxnOffsetCommitRequest
- EndTxnRequest
- Transaction을 완료하기위해 commitTransaction()또는 abortTransaction()을 호출
- EndTxnRequest
- WriteTxnMarkerRequest
- UserTopic commit 먼저 완료
- Consumer Coordinator에 offset 커밋
- Transaction Coordinator에 커밋 로그 기록
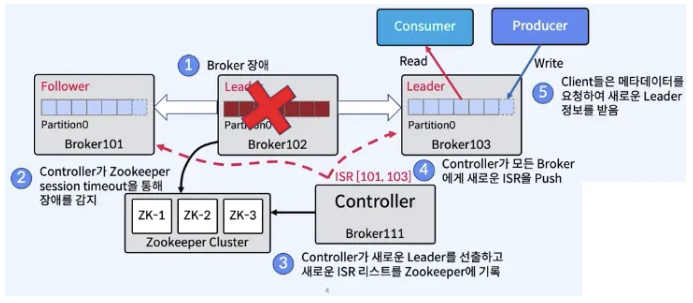
Replica Failure
In-Sync Replicas 리스트 관리
- Leader Partition이 있는 브로커가 관리
- 메시지가 ISR리스트의 모든 Replica에서 수신되면 Commit된 것으로 간주
- Kafka Cluster의 Controller가 모니터링하는 Zookeeper의 ISR 리스트에 대한 변경 사항은 Leader가 유지
- Follower가 실패하는 경우
- Leader에 의해 ISR 리스트에서 삭제됨 (replica.lag.time.max.ms : fetch request interval로 판단)
- Leader는 새로운 ISR을 사용하여 Commit함
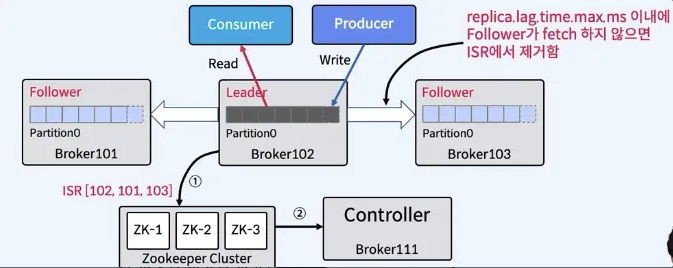
- Leader가 실패하는 경우
- Controller는 Follwer중에서 새로운 Leader를 선출한다. (broker 모니터링은 주키퍼가 한다.)
- Controller는 새 Leader와 ISR 정보를 먼저 zookeeper에 push한 다음 로컬 캐싱을 위해 Broker에 push함
Broker Failure 시나리오
- Broker 4대, Partition 4, Replication Factor가 3(리더 포함)인 경우 가정
- Broker 4에 장애가 발생하면?
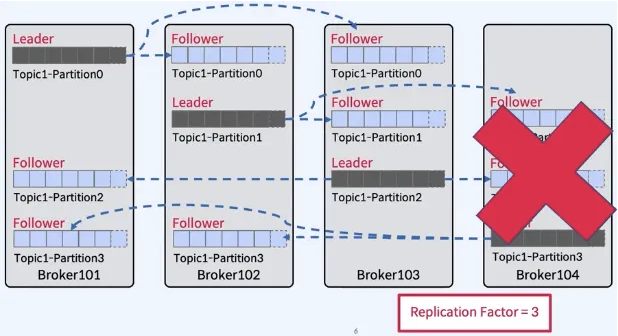
- Broker101, Broker102 중에 Partition3에 대한 리더를 재선출한다.
- 만약 Partition에 Leader가 없으면?
- Leader가 선출될 때까지 해당 Partition을 사용할 수 없게된다.
- Producer의 send()는 retries 파라미터가 설정되어 있으면 재시도함
- 만약 retries=0이면, NetworkException이 발생한다.
Replica Recovery
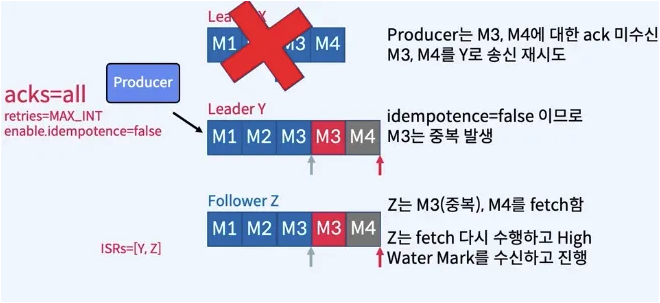
acks = all 의 중요성
- 3개의 Replica로 구성된 하나의 Parition
- Producer가 4개의 메시지 (m1, m2, m3, m4)를 보냈음
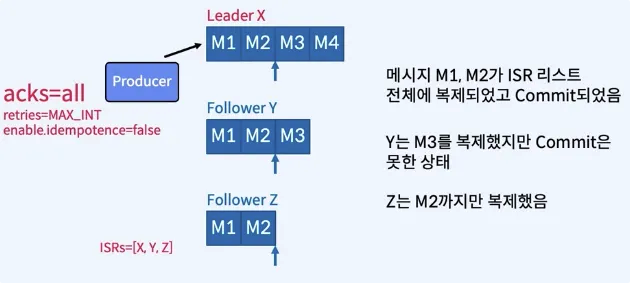
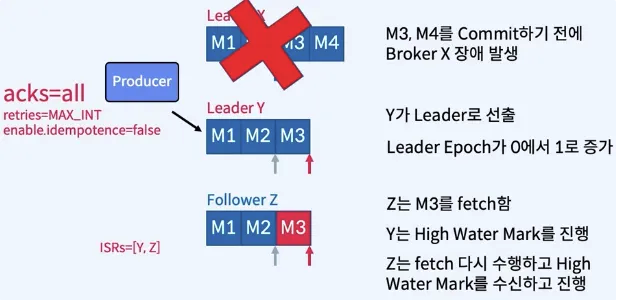
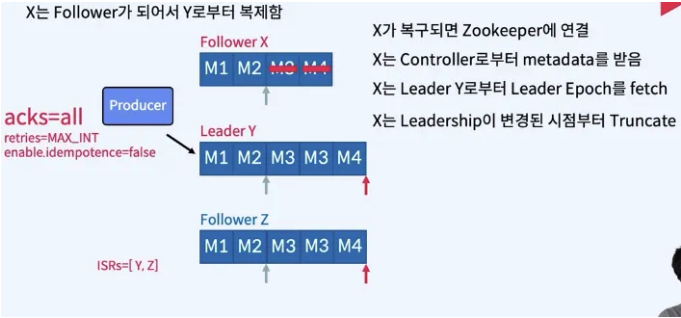
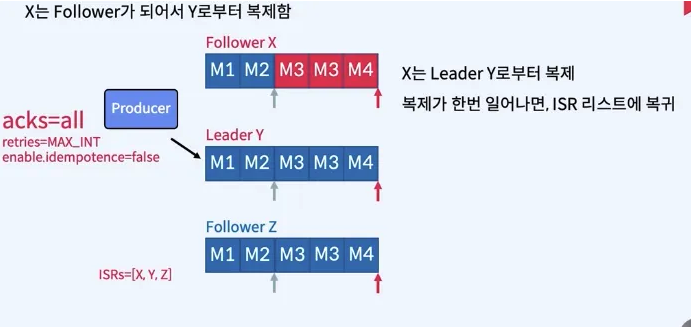
- 장애가 발생했던 X가 복구된다면?
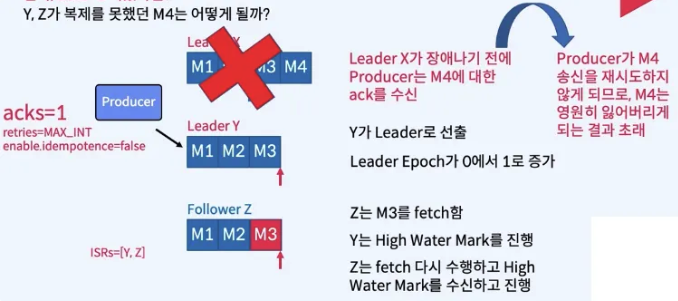
만약 acks = 1 이었다면?
Availability vs Durability
- 데이터 유실이 없게 하려면? (Durability - 내구성)
- Topic: replication.factor는 2보다 커야함 (최소 3 이상)
- Topic : min.insync.replicas는 1보다 커야함 (최소 2 이상)
- Producer: acks = all
- 데이터 유실이 있더라도 가용성을 높게하려면? (Availability - 가용성)
- Topic : unclean.leader.election.enable = true로 설정
- Topic 파라미터 - unclean.leader.election.enable
- ISR 에 없는 Replica를 Leader로 선출할 것인지에 대한 옵션 (default : false)
- ISR 리스트에 Replica가 하나도 없으면 Leader 선출을 안 함 - 서비스 중단
- ISR 리스트에 없는 Replica를 Leader로 선출함 - 데이터 유실
- Topic 파라미터 - min.insync.replicas
- 최소 요구되는 ISR의 개수에 대한 옵션 (default: 1)
- ISR 이 min.insync.replicas 보다 적은 경우, Producer는 NotEnoughReplicas 예외를 수신한다.
- Producer에서 acks=all과 함께 사용할 때 더 강력한 보장 + min.insync.replicas=2 (리더 포함)
- n개의 Replica가 있고, min.insync.replicas=2인 경우 n-2개의 장애를 허용할 수 있음
