스크래핑(Scraping)
말 그대로 스크랩하는 것 입니다.
어떤 특정한 웹 사이트에 가서 그 사이트의 html을 긁어오는 것을 말합니다.
긁어온 정보를 잘 정리해서 DB에 저장할 수 있습니다.
유저가 게시글을 작성해서 등록할 때, 백엔드 API로 글의 내용을 보내주게 됩니다.
이때, 글의 내용에 http가 포함된 URL이 있다면, 그 사이트에 접속해서 open graph 가 있는 내용을 긁어와서 저장합니다.
나중에 글의 상세보기를 할 때, 사이트 소개를 같이 보여주게 됩니다.
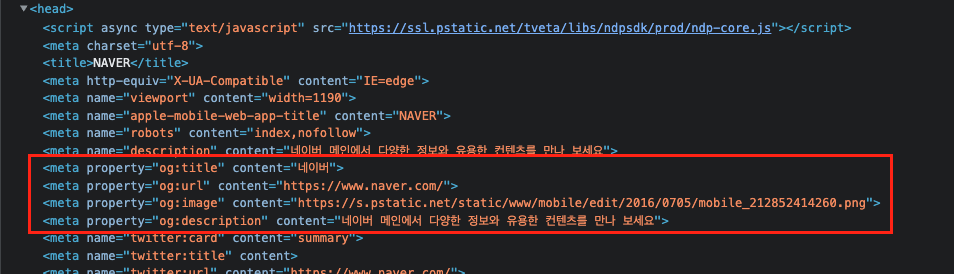
네이버에 들어가서 개발자 도구를 열어보면,
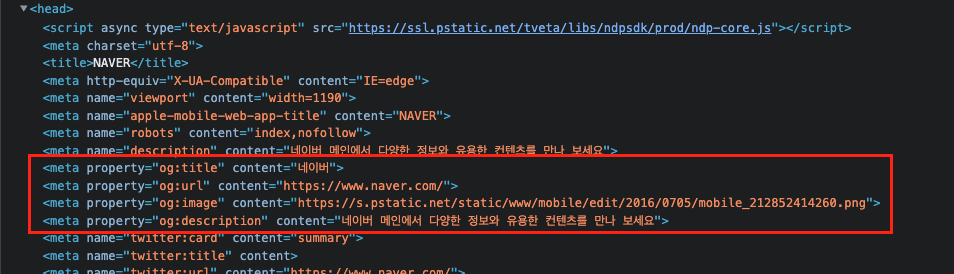
<head> 태그 안에 meta 태그들이 있고, 그 중에서 property 가 og 로 시작하는 태그들이 보입니다.
💡 The Open Graph protocol
페이스북에서 시작해서 유명해진 것으로, 아래의 정보들을 html에 head안에 meta 태그로 넣어줍니다.
og:title: The title of your object as it should appear within the graph, e.g., "The Rock".
og:type: The type of your object, e.g., "video.movie". Depending on the type you specify, other properties may also be required.
og:image: An image URL which should represent your object within the graph.
og:url: The canonical URL of your object that will be used as its permanent ID in the graph, e.g., "https://www.imdb.com/title/tt0117500/".
출처 : https://ogp.me/
크롤링
크롤링은 스크래핑을 정기적으로 혹은 주기적으로 여러번하는 것을 마합니다.
🚨 다른 사이트를 크롤링하는 것은 주의하셔야 합니다
'여기어때'의 '야놀자' 크롤링 법적 이슈
오픈 그래프 스크래핑
이제부터 앞서 소개한 오픈 그래프를 직접 스크래핑해보겠습니다.
이를 도와줄 도구로 cheerio를 사용하겠습니다.
💡 cheerio 라이브러리
cheerio 공식 홈페이지
[npm] cheerio
실습
09-01-cheerio-scraping 폴더를 만들어주세요.
yarn init 으로 package.json 파일을 생성해주고 파일 안에 "type": "module" 코드를 추가해줍니다.
{
"name": "09-01-cheerio-scraping",
"version": "1.0.0",
"main": "index.js",
"license": "MIT",
"type": "module"
}터미널에서 해당 폴더로 이동해 라이브러리 설치 명령어를 입력합니다.
npm install cheerio
or
yarn add cheerio설치가 잘 되었다면, index.js 파일을 만들고 import 해주세요.
http 주소가 들어있는 contents 라는 변수를 가지고, 이를 매개 변수로 받아오는 오픈 그래프를 스크래핑하는 함수 getOpenGraph 를 작성해보겠습니다.
import cheerio from 'cheerio';
function getOpenGraph(contents) {
}
const contents = "여기가 대형 포털사이트에요!! https://naver.com"
getOpenGraph(contents)먼저 여기가 대형 포털사이트에요!! https://naver.com 이 문자열에서 https://naver.com 이 부분만 분리해야 합니다.
// 문자열에 'http'가 들어있는지 확인
if(contents.includes("http")) {
let myHttpOg = '';
// 빈칸을 기준으로 나눈 후,
// 나눈 부분을 돌면서 http로 시작하는 부분이 있다면 myHttpOg에 담아줍니다
contents.split(' ').forEach(el => {
if(el.startsWith('http')) {
myHttpOg = el;
}
})
}이제 변수 myHttpOg 에는 https://naver.com 가 담겨져 있습니다.
얻은 URL 주소에 들어가 html을 가져와야합니다.
html은 우리가 서버로 API 요청을 보낼 때 사용했던 axios를 이용하면 됩니다.
axios 라이브러리를 먼저 설치한 후, import 해주세요.
// axios 라이브러리 설치
npm install axios
or
yarn add axiosimport axios from 'axios'if(contents.includes('http')) 문 안에 계속 작성을 해줘야합니다.
비동기 작업을 수행하니 getOpenGrahp 함수에 async 를 적용시켜줍니다.
const html = await axios.get(myHttpOg);
console.log(html);그리고 node index.js 명령어를 입력해 결과를 확인해봅시다.
이제 이 많은 태그들 중에서 오픈 그래프가 들어가있는 부분을 찾아야합니다.
이를 쉽게 찾아주는게 바로 cheerio입니다.
우리가 받아온 html 데이터를 cheerio에 넘겨줍니다.
const $ = cheerio.load(html.data);결과를 저장하는 변수의 이름은 $ 가 아니라 다른것도 상관없지만, 공식 문서에서 쓰는대로 따라하겠습니다.
다시 네이버의 소스 코드를 보면 meta 태그에는 property 와 content 속성이 있습니다.
이를 걸러내기 위한 코드를 작성합니다.
$('meta').each((_, el) => {
if(!$(el).attr('property')) {
// property가 없으면 return
return;
}
// og:title을 ':'로 분리하면 0번째가 'og', 1번째가 'title'
console.log($(el).attr('property').split(':')[1]);
console.log($(el).attr('content'));
console.log('================================')
})node index.js 명령어로 콘솔을 확인해보겠습니다.
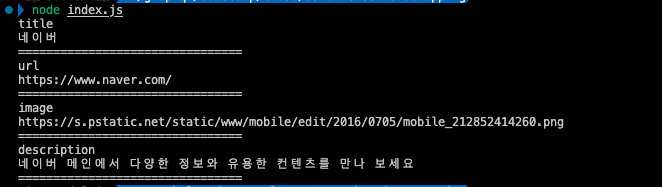
우리가 원하는 오픈 그래프의 정보가 잘 출력되는 것을 확인할 수 있습니다.
그리고 저장해주기 위해 객체를 만들어 주겠습니다.
async function getOpenGraph(contents) {
const openGraph = {
title: '',
description: '',
image: '',
url: ''
}
// ... 기존 코드
}출력해서 값을 확인해봤던 부분을 각각 변수에 담아 방금 만든 openGraph 객체에 넣어줍니다.
$('meta').each((_, el) => {
if(!$(el).attr('property')) {
// property가 없으면 return
return;
}
// og:title을 ':'로 분리하면 0번째가 'og', 1번째가 'title'
console.log($(el).attr('property').split(':')[1]);
console.log($(el).attr('content'));
console.log('================================')
// openGraph 객체에 넣기
const key = $(el).attr('property').split(':')[1];
const content = $(el).attr('content');
openGraph[key] = content;
})마지막으로 객체에 잘 들어갔는지 확인해보겠습니다.
console.log('결과', openGraph);
index.js 의 최종코드는 다음과 같습니다.
import cheerio from 'cheerio';
import axios from 'axios';
async function getOpenGraph(contents) {
const openGraph = {
title: '',
description: '',
image: '',
url: ''
}
// 문자열에 'http'가 들어있는지 확인
if(contents.includes("http")) {
let myHttpOg = '';
// 빈칸을 기준으로 나눈 후,
// 나눈 부분을 돌면서 http로 시작하는 부분이 있다면 myHttpOg에 담아줍니다
contents.split(' ').forEach(el => {
if(el.startsWith('http')) {
myHttpOg = el;
}
})
const html = await axios.get(myHttpOg);
console.log(html.data);
const $ = cheerio.load(html.data);
$('meta').each((_, el) => {
if(!$(el).attr('property')) {
// property가 없으면 return
return;
}
// og:title을 ':'로 분리하면 0번째가 'og', 1번째가 'title'
console.log($(el).attr('property').split(':')[1]);
console.log($(el).attr('content'));
console.log('================================')
// openGraph 객체에 넣기
const key = $(el).attr('property').split(':')[1];
const content = $(el).attr('content');
openGraph[key] = content;
})
}
console.log('결과', openGraph);
}
const contents = "여기가 대형 포털사이트에요!! https://naver.com"
getOpenGraph(contents)스크래핑과 Rest-API
문자열에서 http가 포함된 주소를 찾아, 그 사이트의 html을 가져와 오픈 그래프를 가져오는 함수를 만들어봤습니다.
그런데 지금은 1회성으로, 함수가 종료되면 데이터가 사라집니다.
이번에는 게시글을 create하는 Rest-API를 수정해, 글 내용에 주소가 있다면 그 사이트의 오픈 그래프를 긁어와 같이 DB에 저장해보겠습니다.
08-03-rest-api-with-mongoose-1 폴더를 복사해 사본을 만들고 폴더명을 09-02-cheerio-scraping-with-rest-api 으로 변경해줍니다.
opengraph.js
여기에 opengraph.js 파일을 만들어서 09-01-cheerio-scraping 폴더의 index.js 파일의 코드를 복사해 붙여넣습니다.
getOpenGraph 함수를 api에서 사용하기 위해서 몇가지 수정해주겠습니다.
마지막 두 줄을 주석처리해 주세요.
// const contents = "여기가 대형 포털사이트에요!! https://naver.com"
// getOpenGraph(contents)결과를 출력했던 곳에 openGraph 객체를 리턴해주는 코드를 추가해줍니다.
console.log('결과', openGraph);
return openGraph;index.js
폴더를 잘 복사붙여넣기 했다면 cheerio, axios 라이브러리가 잘 설치되어 있을 것 입니다.
아니라면 패키지 설치를 통해 다시 설치해 주세요.
이제 수정한 getOpenGraph 함수를 API 안에서 불러서 사용할 수 있도록, opengraph.js 에는 import 를 추가해주세요.
// opengraph.js
export async function getOpenGraph(contents) {
// ... 기존 코드
}// index.js
import { getOpenGraph } from './opengraph.js'
// ... 기존 코드이제 게시글을 작성하는 API에 아래 로직을 넣어줍니다.
app.post('/board', async (req, res) => {
// 오픈그래프 스크래핑하기
const openGraph = await getOpenGraph(req.body.contents);
// 데이터를 등록하는 로직 (DB에 저장하기)
const board = new Board({
writer: req.body.writer,
title: req.body.title,
contents: req.body.contents,
og: openGraph
});
await board.save();
res.send('등록에 성공하였습니다.');
});기존에 writer, title, contents 만 있던 board 모델에 og 를 추가해주세요.
const boardSchema = new mongoose.Schema({
writer: String,
title: String,
contents: String,
og: {
title: String,
description: String,
image: String,
url: String
}
})이제 제대로 API가 동작하는지 확인해보겠습니다.
터미널에서 docker compose build 후 docker compose up 을 해주세요.
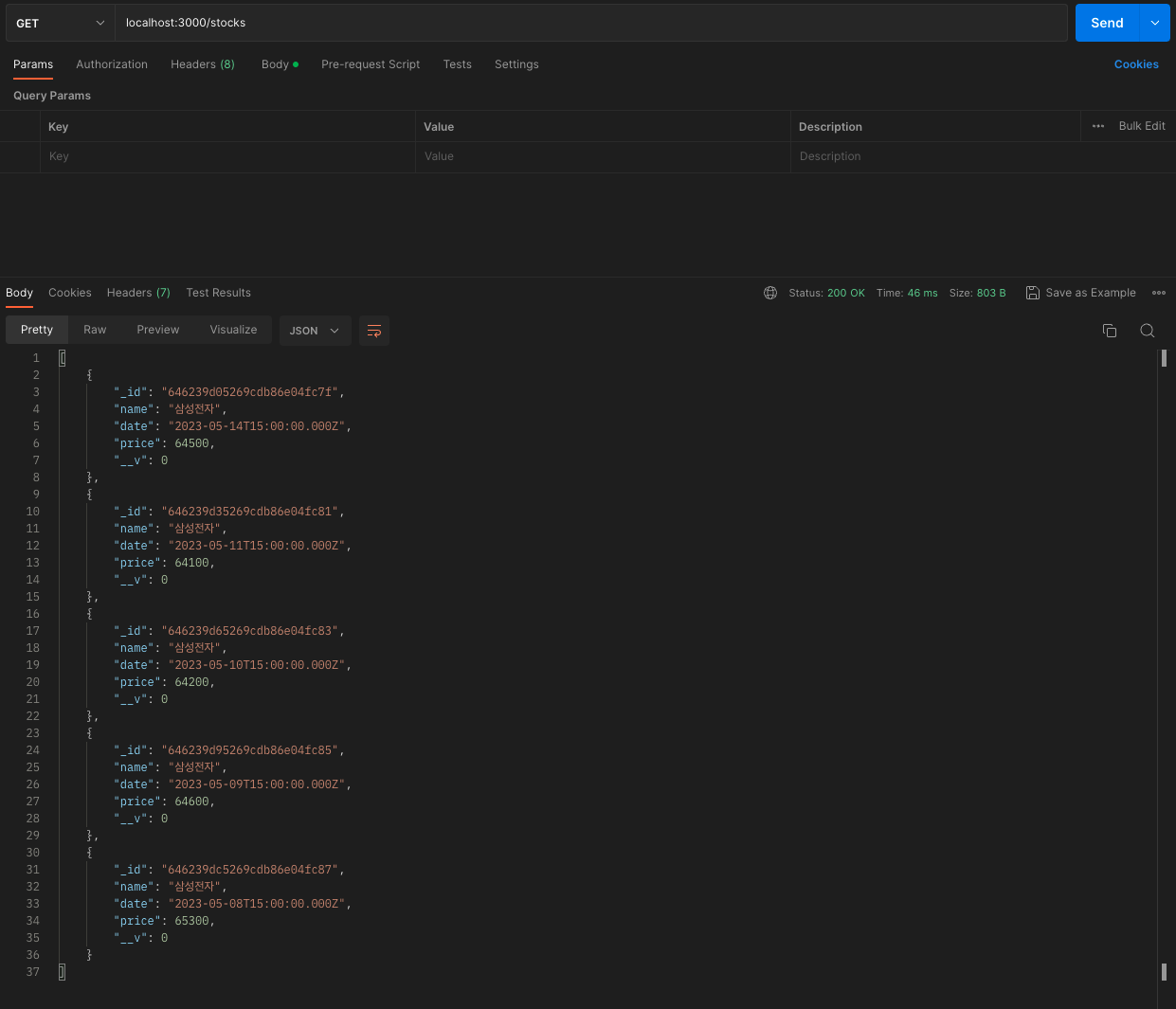
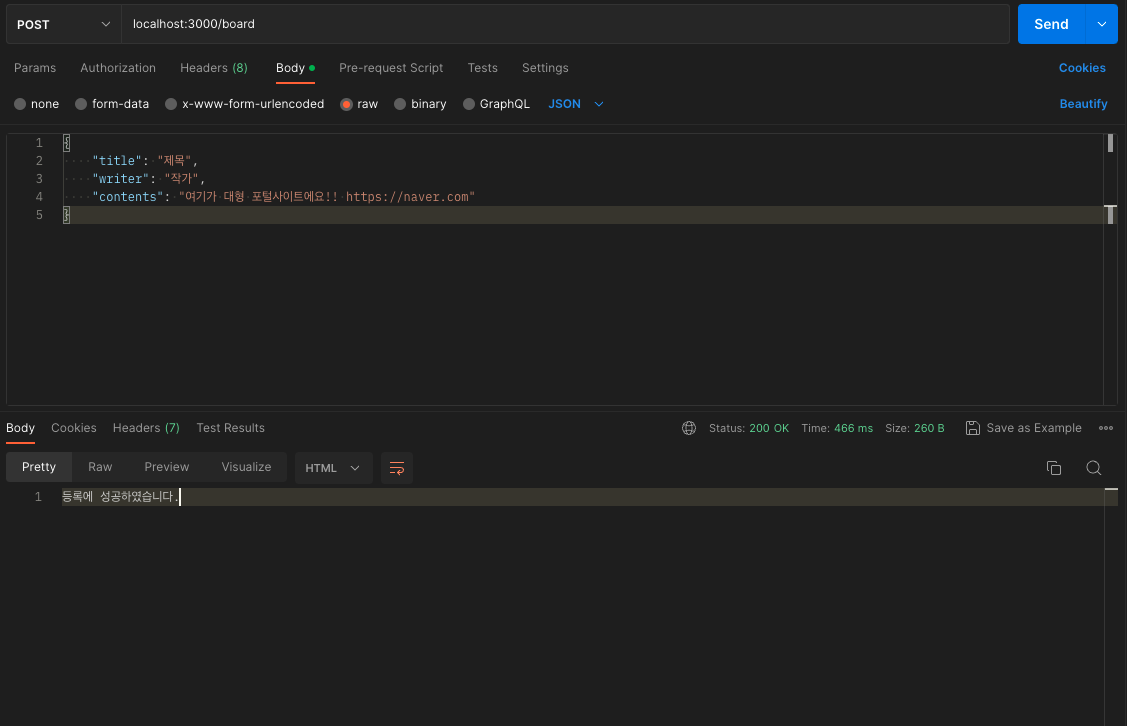
postman으로 전송해서 writer, title, contents 를 보내줍니다.
이때, contents 안에 네이버 주소를 포함시켜보겠습니다.
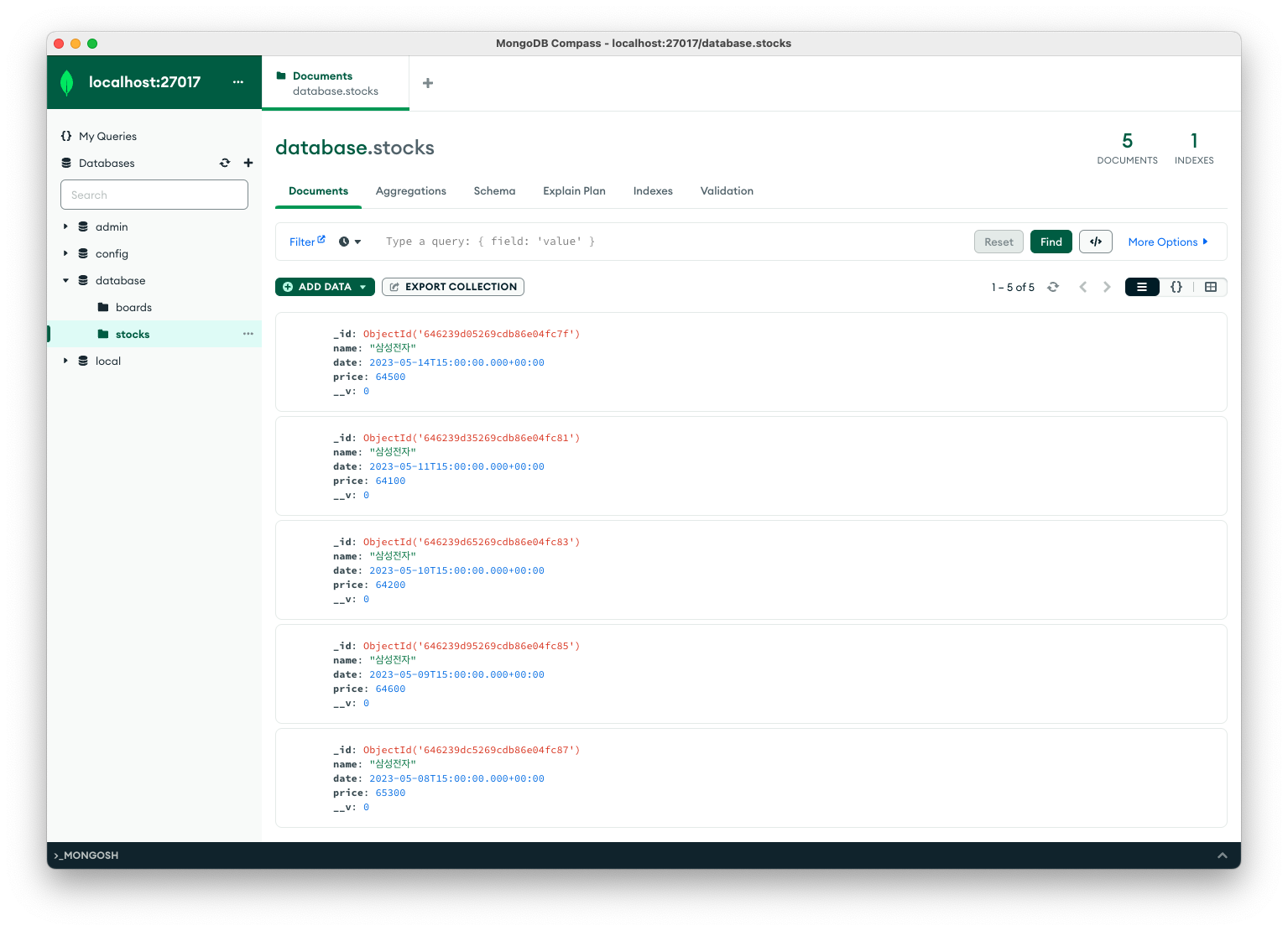
MongoDB Compass로 네이버에 들어가 스크래핑한 결과가 DB에 잘 저장되었는지 확인해보겠습니다.
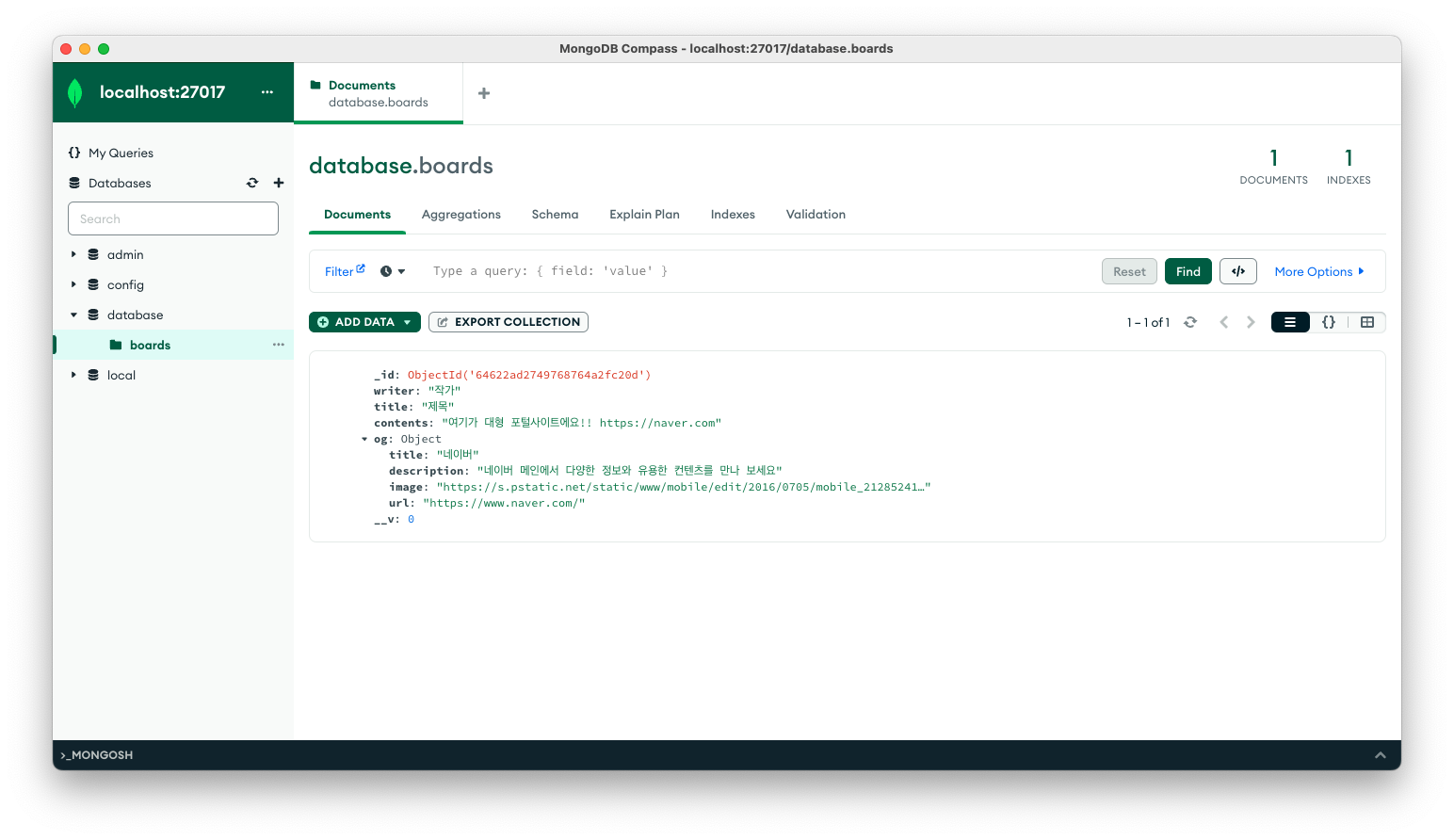
정상적으로 저장이 되어있습니다.
크롤링 puppeteer
09-03-puppeteer-crawling 폴더를 새로 만들어 줍니다.
index.js 파일을 만들고, 초기화를 통해 package.json 을 생성해줍니다.
package.json 안에 "type": "module" 을 추가해줍니다.
{
"name": "09-03-puppeteer-crawling",
"version": "1.0.0",
"main": "index.js",
"license": "MIT",
"type": "module"
}크롤링을 하기 위한 도구로 puppeteer을 쓰겠습니다.
해당 라이브러리를 설치해줍니다.
npm install puppeteer
or
yarn add puppeteer
위의 코드를 참고해서 크롤링하는 코드를 작성해보겠습니다.
index.js 에서 먼저 import 해주겠습니다.
import puppeteer from "puppeteer";startCrawling 이라는 함수를 만들고 실행해주겠습니다.
function startCrawling() {
}
startCrawling();startCrawling 함수 안에 puppeteer를 실행해 가상의 브라우저를 변수에 저장해줍니다.
function startCrawling() {
const browser = puppeteer.launch({headless: false});
}크롬 브라우저를 띄운 다음에 원하는 사이트/페이지로 이동해, 거기에 있는 버튼을 클릭해 넘어가는 식으로 유저처럼 동작합니다.
터미널에서 node index.js 로 파일을 실행하고 조금 기다리면 크롬과 비슷한 크로미엄이라는 브라우저가 나타나게 됩니다.
여기서 headless 를 true 로 하면 브라우저가 띄워지는게 보이지는 않지만 똑같이 동작하게 됩니다.
여기에 launch 라는걸 await 를 사용해서 기다려줘야 합니다.
async function startCrawling() {
const browser = await puppeteer.launch({headless: false});
}이후에는 새로운 페이지를 만들고, 여기어때 사이트에 들어가보겠습니다.
async function startCrawling() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setViewport({width: 1280, height: 720});
await page.goto('');
await new Promise(r => setTimeout(r, 1000));
}페이지의 내용이 다 로딩됐다고 한다면, 이제 숙소 이름과 가격 등을 가져와보겠습니다.
개발자 도구를 열어서 어느 태그를 긁어야할지 확인합니다.
원하는 태그를 우클릭후 copy > copy selector를 하면 태그의 css 선택자를 복사할 수 있습니다.
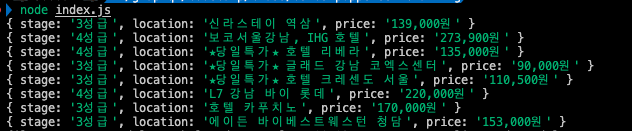
반복문을 돌면서 여러개의 숙소 정보를 가져오겠습니다.
for(let i=2; i<=10; i++) {
const data = {};
data.stage = await page.$eval(`#poduct_list_area > li:nth-child(${i}) > a > div > div.name > div > span`, el => el.textContent);
data.location = await page.$eval(`#poduct_list_area > li:nth-child(${i}) > a > div > div.name > strong`, el => el.textContent);
data.price = await page.$eval(`#poduct_list_area > li:nth-child(${i}) > a > div > div.price > p > b`, el => el.textContent);
console.log(data);
}
// 작업이 끝났다면 브라우저를 닫아준다
await browser.close();터미널을 통해 파일을 실행시켜봅니다.
주식 크롤링
여기어때 사이트 크롤링은 마치 네이버 스크래핑처럼 사이트에 들어가서 바로 태그를 긁어왔습니다.
그런데, 정보를 가져오고 싶은 페이지가 로그인을 해야 볼 수 있다던지, 다음 페이지 넘어가기가 필요하거나, 클릭해야 나오는 팝업 등에서 긁어오고 싶을 때 처럼 다른 동작이 필요할 때 puppeteer이 유용합니다.
이번에는 네이버 금융에서 삼성전자의 시세 가격을 가져와 보겠습니다.
네이버 금융 : https://finance.naver.com/item/sise.naver?code=005930
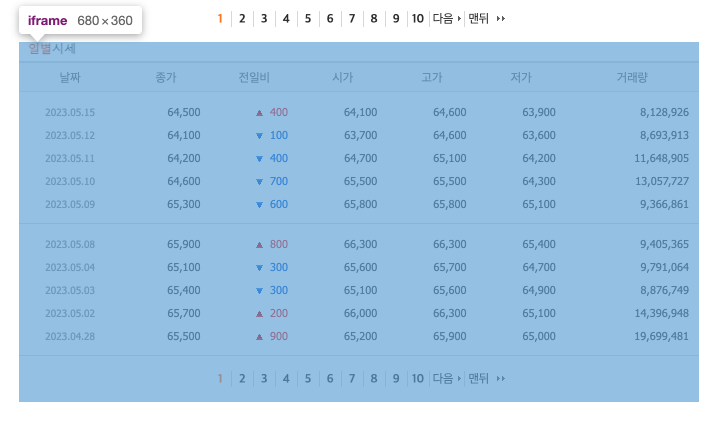
위 사진을 보듯이, 시세 가격은 iframe 태그 안에 있습니다.
iframe 태그 안에서는 다른 html이 끼워져 있는 경우로, 따로 찾아서 들어가야지만 긁어올 수 있습니다.
09-03-puppeteer-crawling 폴더를 복사해 사본을 만들고 폴더명을 09-04-puppeteer-crawliing-iframe 으로 변경합니다.
주식 사이트를 크롤링하기 위해, 몇가지 수정해보겠습니다.
기존에 있는 for 문은 삭제하고, 주소 부분을 해당 사이트로 고쳐주세요.
await page.goto('https://finance.naver.com/item/sise.naver?code=005930');앞서 했던 것과 같이, 개발자 도구를 열어 가격 정보가 담겨 있는 태그를 우클릭해서 copy selector 를 해줍니다.
const myPrice = await page.$eval('body > table.type2 > tbody > tr:nth-child(3) > td:nth-child(2) > span', el => el.textContent);위처럼 코드를 작성해도 이번엔 제대로 가져오지 못합니다.
왜냐하면 iframe 안에 들어가야하기 때문입니다.
원하는 페이지로 이동한 후에 그페이지 안에 있는 iframe 중에서 내가 원하는 태그는 src에 /item/sise_day.naver?code=005930 를 포함하고 있는 태그입니다.
이 iframe 을 가져오는 코드를 작성합니다.
// iframes을 중에서 찾아주는데, 저 주소를 가지고 있는 iframe을 가져온다
const iframePage = page.frames().find(iframe => iframe.url().includes('/item/sise_day.naver?code=005930'));그 다음에는 copy selector 한 것을 사용할 수 있습니다.
import puppeteer from "puppeteer";
async function startCrawling() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setViewport({width: 1280, height: 720});
await page.goto('https://finance.naver.com/item/sise.naver?code=005930'); // 해당 주소로 이동
await new Promise(r => setTimeout(r, 1000));
// iframes을 중에서 찾아주는데, 저 주소를 가지고 있는 iframe을 가져온다
const iframePage = page.frames().find(iframe => iframe.url().includes('/item/sise_day.naver?code=005930'))
for(let i=3; i<=7; i++) {
await new Promise(r => setTimeout(r, 3000));
const myDate = await iframePage.$eval(`body > table.type2 > tbody > tr:nth-child(${i}) > td:nth-child(1) > span`, el => el.textContent);
const myPrice = await iframePage.$eval(`body > table.type2 > tbody > tr:nth-child(${i}) > td:nth-child(2) > span`, el => el.textContent);
console.log(`날짜: ${myDate}, 가격: ${myPrice}`)
}
// 작업이 끝났다면 브라우저를 닫아준다
await browser.close();
}
startCrawling();크롤링 후 DB 저장 & Rest-API
이번에는 방금 크롤링 한 주식 정보를 DB에 저장해보겠습니다.
저장한 후에는 API로 요청했을 때 다시 꺼내올 수 있도록 만들어보겠습니다.
09-05-puppeteer-crawling-iframe-with-rest-api 라는 이름의 새 폴더를 만들어주세요.
08-03-rest-api-with-mongoose-1 폴더를 복사해 09-05 폴더 안에 붙여넣기 하고, backend 라고 폴더명을 변경합니다.
09-04-puppeteer-crawliing-iframe 폴더를 복사해 09-05 폴더안에 붙여넣기 하고, crawler 라고 폴더명을 변경합니다.
모델 만들기
DB 모델을 만들겠습니다.
backend 폴더와 crawler 폴더 안에 각각 models 폴더를 새로 만들어 주세요.
그리고 backend 폴더 안에 있는 models 폴더에 stock.model.js 파일을 만들겠습니다.
여기있는 stock 모델은 주식 데이터를 꺼내올 때 사용하게 됩니다.
import mongoose from 'mongoose';
const stockSchema = new mongoose.Schema({
name: String,
date: Date,
price: Number
});
export const Stock = mongoose.model('stock', stockSchema);crawler 폴더 안에 있는 models 폴더 안에도 stock.model.js 파일을 복사해 붙여넣기 합니다.
crawler 폴더 안에 있는 모델은 데이터를 저장할 때 사용하게 됩니다.
여기에도 mongoose 를 설치해줘야 합니다.
그리고 crawler 폴더의 index.js 파일에서 stock 모델을 import 하고 DB를 연결해줍니다.
import puppeteer from "puppeteer";
// Stock 모델
import { Stock } from './models/stock.model.js'
// DB연결
import mongoose from "mongoose";
mongoose.connect('mongodb://localhost:27017/database');
async function startCrawling() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setViewport({width: 1280, height: 720});
await page.goto('https://finance.naver.com/item/sise.naver?code=005930'); // 해당 주소로 이동
await new Promise(r => setTimeout(r, 1000));
// iframes을 중에서 찾아주는데, 저 주소를 가지고 있는 iframe을 가져온다
const iframePage = page.frames().find(iframe => iframe.url().includes('/item/sise_day.naver?code=005930'))
for(let i=3; i<=7; i++) {
await new Promise(r => setTimeout(r, 3000));
const myDate = await iframePage.$eval(`body > table.type2 > tbody > tr:nth-child(${i}) > td:nth-child(1) > span`, el => el.textContent);
const myPrice = await iframePage.$eval(`body > table.type2 > tbody > tr:nth-child(${i}) > td:nth-child(2) > span`, el => el.textContent);
// DB에 저장
const stock = new Stock({
name: '삼성전자',
date: myDate,
price: Number(myPrice.replace(',', '')) // 가격의 콤마 제거 후, 숫자로 변환
})
await stock.save();
console.log(`날짜: ${myDate}, 가격: ${myPrice}`)
}
// 작업이 끝났다면 브라우저를 닫아준다
await browser.close();
}
startCrawling();백엔드 쪽에서 API를 만들어주겠습니다.
backend 폴더 안에 index.js 파일에 아래의 API를 추가해줍니다.
import { Stock } from './models/stock.model.js'
// ... 기존 코드
app.get('/stocks', async (_, res) => {
const stocks = await Stock.find();
console.log(stocks);
res.send(stocks);
})
// ... 기존 코드서버 실행
터미널에서 백엔드 폴더로 이동해 docker compose build 후 docker compose up 을 통해 도커를 실행합니다.
터미널에서 크롤러 폴더로 이동해, node index.js 를 이용해 크롤링 하고 DB에 저장합니다.
잘 들어갔는지 MongoDB Compass 로 확인해보고, postman으로 GET 요청을 해 제대로 응답하는지 확인합니다.