
22.05.06
동적 메모리 할당
- 개요
- 할당기는 힙을 다양한 크기의 블록들의 집합으로 관리함.
- 할당기는 두 가지의 종류가 있다.
- 명시적 할당기
- 명시적인 할당기는 응용이 명시적으로 할당된 블록을 반환해 줄 것을 요구한다.
- 예를 들어, C 표준 라이브러리는 malloc 패키지라고 하는 명시적 할당기를 제공한다.
- malloc 함수를 호출해서 블록을 할당하고, free 함수를 호출해서 블록을 반환한다.
- 묵시적 할당기
- 언제 할당된 블록이 더 이상 프로그램에 의해 사용되지 않고 블록을 반환하는지를 할당기가 검출할 수 있을 것을 요구함.
- 가비지 컬렉터가 묵시적 할당기이다.
- 자동으로 사용하지 않은 할당된 블록을 반환시켜주는 작업을 가비지 컬렉션이라고 부름.
- 자바같은 상위수준 언어들은 할당된 블록을 반환시키기 위해 가비지 컬렉션을 사용함.
- 명시적 할당기
- malloc/free
- malloc
- malloc 함수는 블록 내에 포함될 수 있는 어떤 종류의 데이터 객체에 대해서 적절히 정렬된 최소 size 바이트를 갖는 메모리 블록의 포인터를 리턴한다.
- 64비트 모드에서 주소는 항상 16의 배수인 블록을 리턴한다.
- 프로그램이 가용한 가상메모리보다 더 큰 크기의 메모리 블록을 요청하는 경우 NULL을 리턴하고 errno를 설정한다.
- malloc 같은 동적 메모리 할당기는 mmap과 munmap 함수를 사용해서 명시적으로 힙 메모리를 할당하거나 반환하며, 또는 sbrk 함수를 사용할 수 있다.
- sbrk함수는 커널의 brk(힙의 꼭대기를 가리키는 변수) 포인터에 incr을 더해서 힙을 늘리거나 줄인다. 성공한다면 이전의 brk 값을 리턴하고, 아니면 -1을 리턴하고 errno를 ENOMEM으로 설정한다. 만일 incr이 0이면 sbrk는 현재의 brk값을 리턴함. → 힙 영역을 늘림
- free
- ptr 인자는 malloc, calloc, realloc에서 획득한 할당된 블록의 시작을 가리켜야 한다. 그렇지 않으면 free의 동작은 정의되지 않음.
- malloc
- 동적 메모리 할당기를 만드는 이유
- malloc이라는 것이 없다면, 배열을 정해진 최대 배열 크기를 갖는 정적 배열로 정의할 것이다. 일단 크게 만들어 놓으면 프로그램이 터질 일은 줄어들기 때문이다.
- 작은 프로그램에서는 크게 문제가 되지 않겠지만, 사용자가 많은 규모의 소프트웨어라면 정적배열 선언은 관리가 어려워진다.
- 그 어려움을 해결하려면 런타임시 메모리에 데이터를 동적으로 할당하는 것이다. 이렇게 되면 메모리의 최대크기는 사용가능한 가상메모리의 양에 의해서만 제한 됨.
- 단편화
- 내부 단편화
- 내부 단편화는 할당된 블록이 데이터 자체보다 더 클 때 일어남 → 예를들어 더블워드 정렬을 맞추기 위해서 20바이트를 요청했는데 패딩으로 24바이트를 잡는 경우가 내부 단편화다.
- 외부 단편화
- 할당 요청을 만족시킬 수 있는 메모리 공간이 전체적으로 공간을 모았을 때는 충분한 크기가 존재하지만, 이 요청을 처리할 수 있는 단일한 가용블록은 없는 경우에 발생 → 외부 단편화는 측정하기가 어려움 왜냐면 미래의 요청 패턴에도 의존하기 때문임.
- 내부 단편화
- 구현 이슈
- 힙을 배열처럼 생각 해보자.
- 힙을 하나의 커다란 바이트의 배열과, 이 배열의 첫 번째 바이트를 가리키는 포인터 p로 구성할 수 있다. malloc은 p의 값을 스택에 저장하고 p를 size 크기만큼 증가시키고 p의 이전 값을 호출자에게 리턴한다. free는 아무것도 하지 않고 단순히 호출자한테 리턴한다 → 처리량은 좋지만 블록을 하나도 재사용하지 않기 때문에 메모리 이용도가 나쁠 것.
- 그래서 고민해봐야할 것들은 → 1. 어떻게 가용블록을 지속적으로 추적할까? 2. 새롭게 할당하기 위해 적절한 가용블록을 선택할 수 있어야함. 3. 블록을 할당한 후 남는 부분들을 처리해야함. 4. 할당이 해제된 블록을 적절하게 합쳐야 함.
- 위의 기능을 구현하기 위해선 정보가 필요하다. 할당기는 정보를 블록 내에 저장함.
- 묵시적 가용리스트(implicit)
- 블록정보
- 헤더 : 블록 크기와 블록 할당 여부를 담는다
- 데이터 : 담아야 할 데이터를 담는 부분(payload)
- 패딩 : 외부 단편화를 극복하기 위한 전략의 일부분으로 사용할 수도 있고, 정렬 요구사항을 만족하기 위해 필요
- 블록정보
- 할당한 블록의 배치
- first fit
- 가용 free 리스트를 처음부터 검색해서 크기가 맞는 첫 번째 가용 블록을 선택
- next fit
- 검색을 이전 검색이 종료된 지점에서 검색을 시작한다.
- best fit
- 모든 가용 블록을 검사하며 크기가 가장 맞는 가장 작은 블록을 선택
- first fit
- 가용 블록의 분할
- 할당기가 크기가 맞는 가용 블록을 찾은 후에 가용 블록의 어느 정도 할당할지에 대해 결정을 내려야함
- 가용 블록 전체를 사용하는 것이 하나 있다 → 비록 간단하고 빠르지만, 큰 단점은 내부 단편화가 생긴다는 것
- 크기가 잘 안 맞는다면 할당기는 대게 가용블록을 두부분으로 나누게 된다. 첫 번째 부분은 할당한 블록이 되고, 나머지는 새로운 가용 블록이 된다.
- 추가적인 힙 메모리 획득하기
- 할당기가 요청한 블록을 찾을 수 없다면 메모리에서 물리적으로 인접한 가용 블록들을 연결해서 더 큰 가용 블록을 만들어 보는 것이다. 이렇게 해도 충분히 큰 블록이 만들어지지 않거나 가용 블록이 이미 최대로 연결 되어있다면 할당기는 sork 함수를 호출해서 추가적인 힙메모리를 요청한다.
- 가용 블록 연결하기
- 할당기가 할당한 블록을 반환할 때, 새롭게 반환하는 블록에 인접한 다른 가용 블록들이 있을 수 있다. 이러한 인접 가용 블록들은 오류 단편화라는 현상을 유발할 수 있으며, 이때는 작고 사용할 수 없는 가용 블록으로 쪼개진 많은 가용 메모리들이 존재한다.
- 오류 단편화를 극복하기 위해 실용적인 할당기라면 연결이라는 과정으로 인접 가용 블록들을 통합해야한다.
- 경계 태그로 연결하기
- 각 블록의 끝 부분에 풋터를 추가하는 것으로, 풋터는 헤더를 복사한 것이다.
22.05.07
알고리즘
- 유클리드 호제법
- 유클리드 호제법이란 숫자 a, b가 있을 때, a를 b로 나눈 나머지와 b의 최대공약수는 a와 b의 최대 공약수가 같다는 것을 의미한다.
- 코드로는 계속해서 a를 b로 나누어서 a에 b를 b에 a를 b로 나눈 나머지를 대입시켜서 b가 0이 될때까지 반복을 하면 a값이 최대 공약수가 된다.
- 유클리드 호제법으로 최대 공약수를 구할수있고 최소 공배수는 a, b의 곱을 최대 공약수로 나누면 구할 수 있다.
def gcd(a, b): # 최대 공약수 while b > 0: a, b = b, a % b return a def lcm(a, b): # 최소 공배수 return a * b / gcd(a, b)
22.05.08
Computer System(CSAPP)
- 6.3 메모리 계층구조
- Cache(캐시)란?
- 자주 사용하는 데이터나 값을 미리 복사해 놓은 임시 장소
- 캐시는 저장 공간이 작고 비용이 비싼 대신 빠른 성능을 제공
- 캐시사용 고려해보면 좋을 예시
- 반복적으로 동일한 결과를 돌려주는 경우
- 캐시에 데이터를 미리 복사해 놓으면 계산이나 접근 시간 없이 더 빠른 속도로 데이터에 접근할 수 있다.
- 6.3.1 메모리 계층구조에서의 캐시
- 메모리 계층구조의 중심 개념 각 k에 대해, 레벨 k에 있는 보다 빠르고 더 작은 저장 장치가 레벨 k + 1에 있는 더 크고 더 느린 저장장치를 위한 캐시 서비스를 제공한다.
- 예를 들어 로컬 디스크는 네트워크 너머 원격 디스크로부터 가져온 파일들(웹페이지 같은)에 대한 캐시로 서비스하며, 메인메모리는 로컬 디스크 상의 데이터에 대한 캐시로 서비스하는 식인데, 가장 작은 캐시인 CPU 레지스터 집합에 이를 때까지 지속됨.
- 캐시적중
- k + 1 레벨에서 데이터 객체 d가 필요한데 k 레벨에 있으면 캐시 적중이라고 함. 프로그램은 d를 레벨 k에서 직접 읽음. 메모리 계층구조의 본성에 의해 k + 1에서 읽는 것보다 더 빠르다.
- 캐시미스
- 반면 레벨 k에서 캐시되지 않는다면 캐시 미스가 발생한 것
- 레벨 k에서의 캐시는 레벨 k + 1에 있는 캐시로부터 d를 포함하는 블록을 가져오며, 만일 레벨 k 캐시가 이미 꽉 찬 상태라면 기존 블록에 덮어 쓰기도 한다.
- 덮어쓰는 과정은 블록을 교체하거나 축출하는 것으로 알려져 있는데, 축출되는 블록은 때로 희생블록이라고 불림.
- 어떤 블록을 교체할지에 관한 결정은 캐시의 교체 정책에 의해 정해짐 → 랜덤으로 교체되던가, 가장 과거에 접근한 블록이 교체되던가.
- 캐시관리
- 컴파일러는 캐시 계층구조의 최상위 레벨인 레지스터 파일을 관리한다
- 레벨 L1,L2,L3의 캐시들은 캐시에 구현된 하드웨어 로직으로 관리됨
- 가상메모리를 사용하는 시스템에서 DRAM 메인 메모리는 디스크에 저장된 데이터 블록에 대한 캐시 서비스를 제공하며, 운영체제 소프트웨어와 CPU 주소번역 하드웨어의 조합으로 관리된ㅍ다.
- Cache(캐시)란?
22.05.09
알고리즘
-
순열, 조합 구현
- itertools 모듈
from itertools import permutationslist(permutations(arr, 몇개로 순열조합 만들건지))
from itertools import combinationslist(combinations(arr, 몇개로 조합 할건지))
- 재귀 함수
- 한 가지 원소를 뽑고 그 원소를 제외한 리스트로 조합 혹은 순열을 구하는 것
- 조합
- combination([1,2,3,4], 2) = ([1] + combination([2,3,4], 1)) and ([2] + combination([3,4],1)) and ([3] + combination([4], 1))
- 순열
- permutation([1,2,3,4], 2) = ([1] + permutation([2,3,4], 1)) and ([2] + permutation([1,3,4], 1)) and ([3] + permutation([1,2,4], 1)) and ([4] + permutation([1,2,3], 1))
- 코드
def comb(lst,n): ret = [] if n > len(lst): return ret if n == 1: for i in lst: ret.append([i]) elif n>1: for i in range(len(lst)-n+1): for temp in comb(lst[i+1:],n-1): ret.append([lst[i]]+temp) return ret def perm(lst,n): ret = [] if n > len(lst): return ret if n==1: for i in lst: ret.append([i]) elif n>1: for i in range(len(lst)): temp = [i for i in lst] temp.remove(lst[i]) for p in perm(temp,n-1): ret.append([lst[i]]+p) return ret
- dfs - 순열
- 코드
import sys input = sys.stdin.readline n, m = map(int, input().split()) s = [] def dfs(): if len(s) == m: print(' '.join(map(str, s))) return for i in range(1, n + 1): if i not in s: s.append(i) dfs() s.pop() dfs()
- 코드
- dfs - 조합
- 코드
import sys input = sys.stdin.readline n, m = map(int, input().split()) s = [] def dfs(start): if len(s) == m: print(*s) return for i in range(start, n+1): s.append(i) dfs(i + 1) s.pop() dfs(1)
- 코드
- itertools 모듈
22.05.10
동적 메모리 할당
-
explicit malloc(명시적 할당)
-
가용 블록끼리 포인터로 연결해 다음 블록 위치를 명시적으로 알 수 있다.
-
가용 블록은 header와 footer 말고는 데이터를 필요로 하지 않음 → 가용 블록 안의 payload 자리에 다음 가용블록(successor block)과 이전 가용 블록(predecessor block)의 주소를 저장함.
-
하나의 이중 연결 리스트를 만들어서 가용 블록을 연결한다.
-
implicit 방식과 달리 메모리 내에서 물리적으로 연속적이지 않아도 된다. 주소 상으로 인접 블록이 아니더라도 포인터 주소를 이용해서 위치를 찾아감.
-
할당
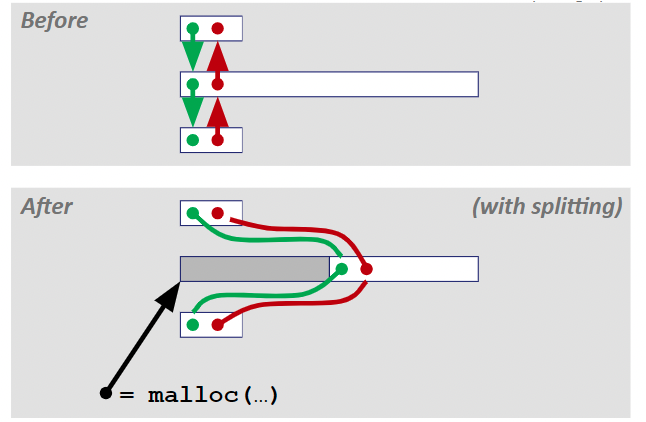
해당 가용 리스트를 분할한 다음 새 가용 블록을 기존 가용 블록과 링크되었던 이전(prev), 다음(next) 블록과 연결한다.
-
가용
- LIFO 방식으로
-
explicit의 초기 힙은 6word의 메모리를 가짐.
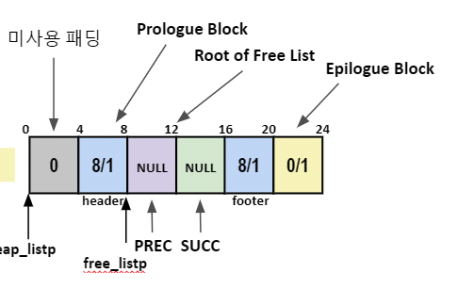
-
PutFreeBlock 함수
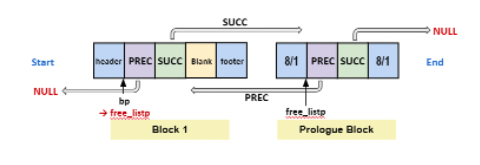
-
구현 코드 및 설명 → https://github.com/yeopto/malloc-lab
-
Computer System
WEEK06의 주차별 키워드는 “시스템 콜, 데이터 세그먼트, 메모리 단편화, sbrk/mmap” 이렇다. malloc을 implicit, explicit 방식으로 구현을 해보고 이해를 한 상태고, 마지막 수요일에 Seglist를 공부하면서 이번주차는 마무리 해야겠다라는 생각을 했다. 하지만 문득 주차별 키워드에 대해 공부해보고 싶은 생각이 들었다. 키워드를 하나씩 검색해보니 각 키워드끼리 연관성이 있고, 또, 키워드에 대해 알기위해선 커널, 운영체제 이론에 대해 알아야했다. 이참에 깊게는 아니더라도 전반적인 흐름은 잡고 가면 좋겠다는 생각에 정리를 해보려한다.
-
운영체제란?
- 개요
- 운영체제는 컴퓨터 시스템의 자원들을 효율적으로 관리하며, 사용자가 컴퓨터를 편리하고, 효과적으로 사용할 수 있도록 환경을 제공하는 여러 프로그램의 모임이다.
- 운영체제는 컴퓨터 사용자와(user) 컴퓨터 하드웨어 간의 인터페이스로서 동작하는 시스템 소프트웨어의 일종으로, 다른 응용프로그램이 유용한 작업을 할 수 있도록 환경을 제공해 줍니다.
- 운영체제의 목적
- 처리능력 향상, 사용 가능도 향상, 반환 시간 단축
- 처리능력, 반환시간, 사용 가능도, 신뢰도는 운영체제의 성능을 평가하는 기준
- 처리능력(Throughput) - 일정 시간 내에 시스템이 처리하는 일의 양
- 반환시간(Turn Around Time) - 시스템에 작업을 의뢰한 시간부터 처리가 완료될 때까지 걸린 시간
- 사용가능도(Availablility) - 시스템을 사용할 필요가 있을 때 즉시 사용 가능한 정도
- 신뢰도(Reliabilty) - 시스템이 주어진 문제를 정확하게 해결하는 정도
- 개요
-
커널이란?
- 컴퓨터와 전원을 켜면 운영체제는 이와 동시에 수행된다. 한편 소프트웨어가 컴퓨터 시스템에서 수행되기 위해서는 메모리에 그 프로그램이 올라가 있어야 한다.
- 마찬가지로 운영체제 자체도 소프트웨어로서 전원이 켜짐과 동시에 메모리에 올라가야 함.
- But 운영체제처럼 규모가 큰 프로그램이 모두 메모리에 올라간다면 한정된 메모리 공간의 낭비가 심할 것.
- 따라서 운영체제 중 항상 필요한 부분만을 전원이 켜짐과 동시에 메모리에 올려놓고 그렇지 않은 부분은 필요할 때 메모리에 올려서 사용하게 되는데 이 때 메모리에 상주하는 운영체제의 부분을 커널이라한다. → 즉 커널은 운영체제의 핵심적인 부분
-
시스템 호출(System call)
-
개요
- 쉽게 설명하면 유저가 응용프로그램을 이용해 명령을 운영체제에게 “이것 좀 처리해줘" 하는 것이다.
- 운영체제는 크게 커널모드, 사용자모드로 나뉘어 구동 됨.
- 커널 모드는 모든 시스템 메모리 접근이 가능하며, 모든 CPU명령 실행이 가능함.
- 사용자 모드는 사용자 어플리케이션 실행, 하드웨어 직접 접근 불가. System call 호출 시 일시적으로 커널모드로 전환. 커널영역의 기능을 사용자모드가 접근하게 도와줌.
- 운영체제에서 프로그램이 구동되는데 있어 파일을 읽어 오거나, 파일을 쓰거나, 혹은 화면에 메시지를 출력하는 등 많은 부분이 커널 모드를 사용함.
- 시스템 호출은 이러한 커널 영역의 기능을 사용자 모드가 사용 가능하게, 즉 프로세스(실행중인 프로그램)가 하드웨어에 직접 접근해서 필요한 기능을 사용할 수 있게 해준다.
-
사용목적
- User가 애플리케이션으로 운영체제의 치명적인 데이터를 수정/삭제하는 권한을 막기 위함.
- 직접적인 하드웨어 요청이나 기타 시스템요청은 OS가 제공하는 System call을 통해 호출하도록 제공한다.
- 유저 어플리케이션이 System call을 호출하여 사용하면 해당 어플리케이션은 커널모드로 잠시 전환되는 작업을 거치게 됨.
-
작동원리
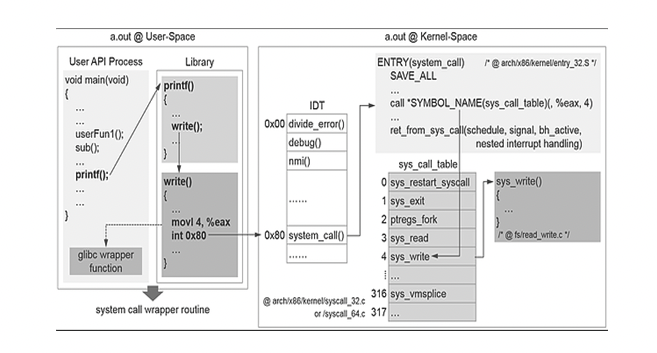
User API Process에서
printf()가 실행이 됨 → library 함수인printf()를 호출하게 됨 → 이는 내부에write()라는 system call 함수를 재차 호출함. 이렇게 호출된write()함수를 wrapper 함수라함 → 이 함수는 CPU내에 있는 범용 register 중의 하나인 eax register에write()함수에 할당되어 있는 고유한 번호인 4를 넣는다 → 다음으로 0x80을 인자로 트랩(trap)을 건다 → 커널은 트랩 번호인 0x80(intel CPU)을 IDT(Interrupt Descripto Table)에 검색하여 이에 해당하는 system_call()을 엔트리(ENTRY)에서 호출함 → 이 함수는 eax값을 index로 sys_call_table을 탐색 → eax resgister에 들어있는 4값으로 sys_write의 포인터 값을 받아 sys_write()를 호출
-
-
데이터 세그먼트
- 프로그램이 실행 될 때 프로그램은 RAM에 적재 됨.
- 다시 말해 프로그램의 모든 내용이 RAM 위로 올라옴. → 여기서 ‘프로그램의 모든 내용’ 이라 하면 프로그램의 코드와 프로그램의 데이터를 모두 의미
- 이렇게 RAM 위로 올라오는 프로그램의 내용을 크게 나누어서 코드 세그먼트(Code Segment)와 데이터 세그먼트(Data Segment)로 분류 가능하다.
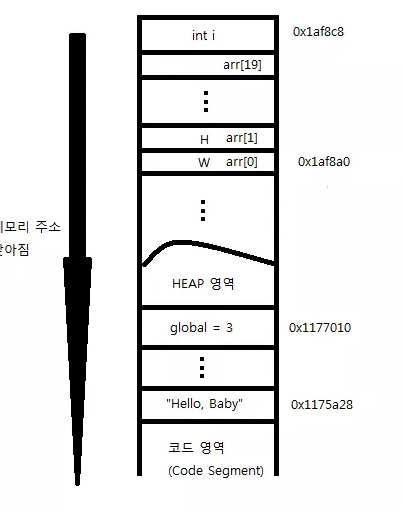
/* 메모리의 배치 모습 */ #include <stdio.h> int global = 3; int main() { int i; char *str = "Hello, Baby"; char arr[20] = "WHATTHEHECK"; printf("global : %p \n", &global); printf("i : %p \n", &i); printf("str : %p \n", str); printf("arr : %p \n", arr); }- 위 코드 메모리 위치를 그림으로 표현해보면
22.05.11
알고리즘
- dfs - 중복순열
- 코드
import sys input = sys.stdin.readline n, m = map(int, input().split()) s = [] def dfs(): if len(s) == m: print(*s) return for i in range(1, n + 1): s.append(i) dfs() s.pop() dfs()
- 코드
mmap(), malloc()
-
malloc → segregated free list로 힙 영역 내에서 메모리 할당해주는 함수
- 리눅스 경우 brk/sbrk 가 메모리 할당
- sbrk → 힙 크기를 늘이거나 줄이는 함수다. 커널의 brk 포인터(힙의 맨 끝을 가리키는 포인터)에 incr만큼 크기를 더해서 힙을 늘이거나 줄인다. 성공하면 이전의 brk 포인터 값을 리턴한다. 실패하면 -1을 리턴하고 errno = ENOMEM 이라고 설정해준다. incr = 0이면 늘어나지 않았으니 현재의 brk 값을 리턴한다.
- sbrk는 페이지 단위로 할당(4KB) → 사이즈가 큰 편이라 이걸 잘게 썰어주고 관리하는 게 heap management library.
-
mmap() → 커널에 새 가상 메모리 영역을 생성해줄 것을 요청하는 함수
- 매핑할 메모리의 위치와 크기를 인자로 받는다.
- 메모리에 매핑된 데이터는 파일 입출력 함수를 사용하지 않고 직접 읽고 쓸수 있다는 장점이 있다.
- mmap()에서는 할당 메모리의 크기가 최소 4KB(mmap()은 페이지 크기의 배수로 할당).
-
malloc()과 차이
- mmap은 “가상 메모리”에 매핑하는 함수. 할당해야 할 메모리 크기가 크면 mmap()으로 할당. mmap()에서는 페이지 단위(최소 4KB - 4096 Bytes)로 영역을 할당해주는 반면, 그 이하는 malloc()으로 heap에서 할당.
- mmap을 사용하면 시스템 콜을 호출할 필요가 없다.
- malloc()은 free()를 호출한다고 해서 해당 메모리 자원이 시스템에 바로 반환되지 X(초기화 안됨.) 반면 munmap()의 경우에는 즉시 시스템에 반환됨.
- malloc()은 큰 메모리 블록 요청이 들어오면 내부적으로 mmap()을 써서 메모리를 할당한다. 이때 큰 메모리 기준은 mallopt() 함수로 제어. 따라서 특별한 제어가 필요한 게 아니면 개발자가 직접 mmap()을 쓸 필요는 없음.
- mmap()이 malloc()을 포함하는 개념이라기보다 mmap()은 시스템에서 제공하는 저수준 시스템 콜이며 특별한 조건일 때 메모리를 할당하는 효과를 볼 수 있다. malloc()은 메모리를 할당하는 C library 함수이며 내부적으로 mmap(), brk() 등 시스템 콜을 써서 구현.
- mmap()은 단순히 메모리를 할당하는 시스템 콜이 아니므로 mmap()으로 쓴 코드를 모두 malloc()으로 바꿀 수는 없음.
출처 : https://woonys.tistory.com/entry/정글사관학교-51일차-TIL-mmap과-malloc-차이-정리
이번주는 malloc을 구현했다! 생각보다 이해도 잘 되었고 재미있었다. seglist까지 구현해보고 싶었지만 explicit까지 구현을 하고 컴퓨터 시스템 공부에 시간투자를 조금 더 한거같다. malloc에 대한 개념은 어느정도 이해를 했는데 캐시에 대해서는 아직 부족한거 같다. 시간날 때 틈틈이 공부해야겠다.
WEEK06 구현 소스코드 - https://github.com/yeopto/malloc-lab/blob/main/mm.c
