
2.2 붓꽃 품종 예측하기
<수행 과정>
1. 데이터 세트 분리 (train/test)
2. 모델 학습 (decision tree)
3. 예측 수행
4. 평가 (정확도)
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
# 붓꽃 데이터 불러오기
iris = load_iris()
iris_data = iris.data
iris_label = iris.target
print('iris target값:', iris_label)
print('iris target명:', iris.target_names)
# DataFrame으로 변환
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
iris_df['label'] = iris.target
iris_df.head(3)
# train, test set을 분리
# test_size: test set에 할당되는 데이터의 size를 의미. 여기서는 전체 데이터의 20%를 test data로 사용.
# random_state: 코드를 수행할 때마다 동일한 결과를 나타내기 위해 지정. R에서의 set.seed()와 같은 역할.
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size=0.2, random_state=11)
# ML 알고리즘은 의사 결정 트리 사용
# DecisionTreeClassifier 객체 생성
dt_clf = DecisionTreeClassifier(random_state=11)
# 학습 수행
dt_clf.fit(X_train, y_train)
# 예측 수행
pred = dt_clf.predict(X_test)
# 예측 정확도 계산 (소수점 넷째자리까지)
# 예측 수행 결과 pred와 y_test 값 비교 (붓꽃 품종이 얼마나 일치하는지 확인)
print('예측 정확도: {0:.4f}'.format(accuracy_score(y_test,pred))) #예측 정확도: 0.93332.3 사이킷런의 기반 프레임워크
Estimator 이해 및 fit(), predict() 메서드
-
Estimator: 지도학습의 모든 알고리즘을 구현한 클래스
- 지도학습: 분류(Classification), 회귀(Regression)
- Classifier과 Regressor를 합친 것.
- fit(), predict()을 내부에서 구현하고 있음. 이를 이용해 간단하게 학습, 예측 결과 반환
- evaluation 함수, 하이퍼 파라미터 튜닝을 지원하는 클래스의 경우 estimator를 인자로 받음
ex. cross_val_score(), GridSearchCV.fit() 함수 내에서 estimator의 fit(), predict()를 호출하여 평가, 또는 튜닝.
-
비지도학습 알고리즘을 구현한 클래스
- 비지도 학습: 차원 축소, 클러스터링, 피처 추출 등
- fit(), transform() 적용
- fit(): 입력 데이터의 형태에 맞춰 데이터를 변환하기 위한 사전 구조 맞춤
- transform(): 입력 데이터의 차원 변환, 클러스터링, 피처 추출 등의 실제 작업
- fit() + transform() = fit_transform()
2.4 Model Selection 모듈
train_test_split()
: 학습/테스트 데이터 세트 분리
- test_size: 전체 데이터에서 차지하는 테스트 데이터 세트 크기. default=0.25
- train_size: 전체 데이터에서 차지하는 학습 데이터 세트 크기.
- shuffle: 데이터를 분리하기 전 데이터를 섞을 지 결정. default=True
- random_state: 수행할 때마다 동일한 데이터 세트로 분리하기 위해 지정. R에서의 set.seed()와 동일한 기능.
- 반환값 형태: 튜플
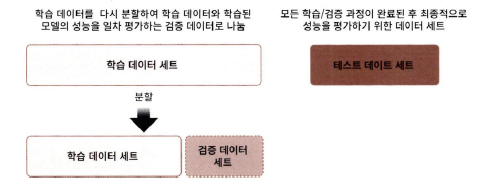
교차 검증
: 과적합이라는 문제점을 개선하기 위함
- 과적합: 모델이 학습 데이터에만 과도하게 최적화되어, 다른 데이터로 실제 예측을 수행할 대 예측 성능이 과도하게 떨어지는 것
- 교차 검증 수행 이유: 고정된 학습 데이터와 테스트 데이터로 평가를 하면 해당 테스트 데이터에만 최적의 성능을 발휘할 수 있도록 하여 편향된 모델이 유도됨. (다른 데이터를 사용하여 테스트를 하면 성능 저하)
-
K-fold 교차 검증
: K개의 데이터 폴드 세트를 만들어서 K번 만큼 각 폴드 세트에 학습과 검증 평가를 반복적으로 수행하는 방법ex. 5-fold 교차 검증
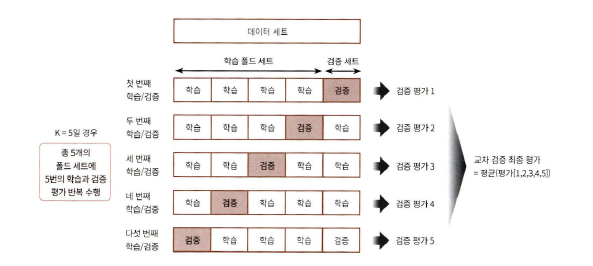
5개의 예측 평가를 구한 거의 평균을 5-fold 평가 결과로 반영
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
import numpy as np
iris = load_iris()
features = iris.data
label = iris.target
dt_clf = DecisionTreeClassifier(random_state=156)
# 5개의 폴드 세트로 분리하는 KFold 객체 생성
kfold = KFold(n_splits=5)
# 폴드 세트별 정확도를 담을 리스트 객체 생성
cv_accuracy = []
# 전체 붓꽃 데이터 크기
print('붓꽃 데이터 세트 크기:',features.shape[0])
n_iter = 0
# kfold.split(features): 폴드 별 학습용, 검증용 테스트의 로우 '인덱스'를 array로 반환
for train_index, test_index in kfold.split(features):
# 학습용, 검증용 테스트 데이터 추출
X_train, X_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
#학습 및 예측
dt_clf.fit(X_train , y_train)
pred = dt_clf.predict(X_test)
n_iter += 1
# 반복 시 마다 정확도 측정
accuracy = np.round(accuracy_score(y_test,pred), 4)
train_size = X_train.shape[0]
test_size = X_test.shape[0]
print('\n#{0} 교차 검증 정확도 :{1}, 학습 데이터 크기: {2}, 검증 데이터 크기: {3}'
.format(n_iter, accuracy, train_size, test_size))
print('#{0} 검증 세트 인덱스:{1}'.format(n_iter,test_index))
cv_accuracy.append(accuracy)
# 개별 iteration별 정확도를 합하여 평균 정확도 계산
print('\n## 평균 검증 정확도:', np.mean(cv_accuracy)) #평균 검증 정확도: 0.9교차 검증을 할 대마다 검증 세트의 인덱스가 달라짐.

-
Stratified K-fold
: 불균형한 분포도를 가진 레이블(결정 클래스) 데이터 집합을 위한 K-fold 방식- 불균형한 분포도를 가진 레이블 데이터: 특정 레이블 값이 특이하게 많거나 매우 적어서 값의 분포가 한 쪽으로 치우친 데이터
ex. 대출 사기 데이터 1억 건 중 대출 사기가 약 1000건 이면 전체의 0.0001%로 사기/정상 레이블 중에서 사기 레이블의 값이 매우 적음 - 원본 데이터와 유사한 레이블 값의 분포를 학습/테스트 세트에도 유지해야 함.
- Stratified K-fold는 원본 데이터의 레이블 분포를 먼저 고려한 후 학습/검증 데이터 분배
- 일반적으로 분류에서는 Stratified K-fold 사용, 회귀에서는 결정값이 연속된 숫자값이므로 Stratified K-fold 지원x.
- 불균형한 분포도를 가진 레이블 데이터: 특정 레이블 값이 특이하게 많거나 매우 적어서 값의 분포가 한 쪽으로 치우친 데이터
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=3)
n_iter=0
for train_index, test_index in skf.split(iris_df, iris_df['label']):
n_iter += 1
label_train= iris_df['label'].iloc[train_index]
label_test= iris_df['label'].iloc[test_index]
print('## 교차 검증: {0}'.format(n_iter))
print('학습 레이블 데이터 분포:\n', label_train.value_counts())
print('검증 레이블 데이터 분포:\n', label_test.value_counts())
학습 데이터와 검증 데이터 레이블이 동일하게 할당됨.
dt_clf = DecisionTreeClassifier(random_state=156)
skfold = StratifiedKFold(n_splits=3)
n_iter=0
cv_accuracy=[]
# StratifiedKFold의 split( ) 호출시 반드시 레이블 데이터 셋도 추가 입력 필요
for train_index, test_index in skfold.split(features, label):
# 학습용, 검증용 테스트 데이터 추출
X_train, X_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
#학습 및 예측
dt_clf.fit(X_train , y_train)
pred = dt_clf.predict(X_test)
# 반복 시 마다 정확도 측정
n_iter += 1
accuracy = np.round(accuracy_score(y_test,pred), 4)
train_size = X_train.shape[0]
test_size = X_test.shape[0]
print('\n#{0} 교차 검증 정확도 :{1}, 학습 데이터 크기: {2}, 검증 데이터 크기: {3}'
.format(n_iter, accuracy, train_size, test_size))
print('#{0} 검증 세트 인덱스:{1}'.format(n_iter,test_index))
cv_accuracy.append(accuracy)
# 교차 검증별 정확도 및 평균 정확도 계산
print('\n## 교차 검증별 정확도:', np.round(cv_accuracy, 4))
print('## 평균 검증 정확도:', np.mean(cv_accuracy))
## 평균 정확도: 0.9604
-
cross_val_score()
: 교차 검증을 편리하게. 위의 과정들을 한 번에 수행.- estimator: Classifier, Regressor
- Classifier: Stratified K-fold 방식
- Regressor: K-fold 방식
- X: 피처 데이터 세트
- y: 레이블 데이터 세트
- scoring: 예측 성능 평가 지표
- cv: 교차 검증 폴드 수
- estimator: Classifier, Regressor
GridSearchCV
: 하이퍼 파라미터를 순차적으로 입력하면서 최적의 파라미터를 도출할 수 있는 방안 제공하는 방식
- estimator: classifier, regressor, pipeline
- param_grid: {key+리스트 값} estimator의 튜닝을 위해 파라미터명과 사용될 여러 파라미터 값 지정
- scoring: 예측 성능을 측정할 평가 방법
- cv: 교차 검증을 위해 분할되는 학습/테스트 세트의 수
- refit: 최적의 하이퍼 파라미터를 찾은 뒤, 이로 재학습시킴. default=True
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
# 데이터를 로딩, 학습데이터와 테스트 데이터 분리
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=121)
dtree = DecisionTreeClassifier()
# 하이퍼 파라미터 지정
parameters = {'max_depth':[1,2,3], 'min_samples_split':[2,3]}
# 3-fold
grid_dtree = GridSearchCV(dtree, param_grid=parameters, cv=3, refit=True)
# 하이퍼 파라미터들을 순차적으로 학습 및 평가
grid_dtree.fit(X_train, y_train)
# 최적 하이퍼 파라미터 및 정확도
print('GridSearchCV 최적 파라미터:', grid_dtree.best_params_)
print('GridSearchCV 최고 정확도: {0:.4f}'.format(grid_dtree.best_score_))총 3x2=6가지의 결과가 도출됨.
# GridSearchCV의 refit으로 이미 학습이 된 estimator 반환
estimator = grid_dtree.best_estimator_
pred = estimator.predict(X_test)
print('테스트 데이터 세트 정확도: {0:.4f}'.format(accuracy_score(y_test,pred)))GridSearchCV 최적 파라미터: {'max_depth': 3, 'min_samples_split': 2}
GridSearchCV 최고 정확도: 0.9667
2.5 데이터 전처리
데이터 인코딩
-
레이블 인코딩(Label Encoding)
: 카테고리 피처를 코드형 숫자 값으로 변환 (LableEncoder 클래스)
ex. TV, 냉장고, 컴퓨터 (문자형) -> 1, 2, 3 (숫자형)--> 숫자형이므로 수의 크기가 알고리즘에 작용하여 성능 저하로 이어질 수 있음.
from sklearn.preprocessing import LabelEncoder
items=['TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서']
# LabelEncoder를 객체로 생성한 후 , fit( ) 과 transform( ) 으로 label 인코딩 수행.
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
print('인코딩 변환값:',labels)-
원-핫 인코딩 (One-Hot Encoding)
: 새로운 피처를 추가해 고유 값에 해당하는 칼럼에만 1, 나머지 칼럼에는 0을 표시(1) 문자열 값을 숫자형 값으로 변환 (LableEncoder 클래스)
(2) 입력 값은 2차원 데이터 (변환값.reshape(-1,1))
(3) 원-핫 인코딩 적용( OneHotEncoder 클래스)
# 먼저 숫자값으로 변환을 위해 LabelEncoder로 변환
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
# 2차원 데이터로 변환
labels = labels.reshape(-1,1)
# 원-핫 인코딩 적용
oh_encoder = OneHotEncoder()
oh_encoder.fit(labels)
oh_labels = oh_encoder.transform(labels)**get_dummies()를 이용하면 숫자형 변환 없이 바로 가능
df = pd.DataFrame({'item':['TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서'] })
pd.get_dummies(df)피처 스케일링과 정규화
피처 스케일링: 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업
-
표준화: 피처 각각을 N(0,1)인 가우시안 정규분포를 가진 값으로 변환
ex. StandardScaler()- 서포트 벡터 머신, 선형 회귀, 로지스틱 회귀 등 가우시안 분포를 가지고 있다고 가정했기 때문에 표준화가 예측 성능 향상에 중요할 수 있음
-
정규화: 서로 다른 피처의 크기를 통일하기 위해 0~1 사이 값으로 변환 (=같은 단위로 변환)
ex. MinMaxScaler(): 0~1, 음수가 있으면 -1~1
- fit(): 데이터 변환을 위한 기준 정보 설정
- transform(): fit된 정보를 이용해 데이터 변환
- fit_transform(): fit()과 transform()을 한 번에 적용
--> 주의할 점: 머신러닝 모델은 학습 데이터를 기반으로 학습되기 때문에 반드시 테스트 데이터는 학습 데이터의 스케일링 기준에 따라야함. 따라서, 테스트 데이터에 다시 fit()을 적용하지 않고, 이미 fit()이 적용된 scaler 객체를 이용해 transform()으로 변환해야함.
--> 따라서, fit_transform()은 테스트 데이터에서는 절대 사용하면 안 되는 메소드
--> 가능하다면, 학습/테스트 세트로 분리하기 전, 먼저 전체 데이터 세트에 스케일링 적용한 뒤 분리하는 것이 바람직
scaler = StandardScaler()
scaler.fit(train)
train_scaled = scaler.tansform(train)
#scaler.fit(test) 으로 다시 fit 시키면 test 데이터에 대해 변환이 새롭게 됨
#train으로 fit 시킨 scaler 바로 사용
test_scaled = scaler.transform(test)2.6 타이타닉 생존자 예측
