
3.1 정확도(Accuracy)
정확도 = (예측 결과가 동일한 데이터 건수)/(전체 예측 데이터 건수)
BUT! 불균형한 레이블 값 분포에서 머신러닝 모델의 성능을 판단할 경우에는 적합한 평가 지표가 될 수 없다.
ex. 10개의 데이터 중 9개가 레이블이 0, 1개가 레이블이 1이고, 무조건 0으로 예측 결과를 반환하는 모델의 경우도 정확도가 0.9가 된다.
3.2 오차행렬(Confusion Matrix)
오차행렬: 이진 분류의 예측 오류가 얼마인지+어떤 유형의 예측 오류가 발생하고 있는지를 함께 나타내는 지표 (confusion_matrix())
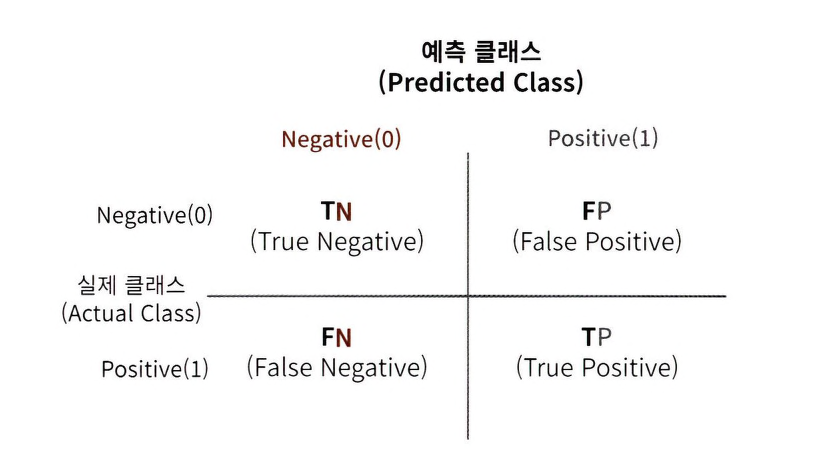
ex. 10개의 데이터 중 9개가 레이블이 0, 1개가 레이블이 1이고, 무조건 0으로 예측 결과를 반환한 모델의 경우,
TN=9, FN=1, FP=0, TP=0이다.
정확도 = (TN+TP)/(TN+FP+FN+TP) = 0.9
불균형한 데이터 세트에서는 정확도만으로는 신뢰도가 떨어질 수 있다. 이런 경우, 다른 평가 지표인 정밀도와 재현율이 선호된다.
3.3 정밀도(Precision)와 재현율(Recall)
정밀도
= TP/(FP+TP)
: 예측을 Positive 로 한 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율 (precision_score())
ex. 스팸메일: 실제 일반메일을 스팸메일로 분류하면 업무에 차질이 생김(FP)
재현율
= TP/(FN+TP)
: 실제 값이 Positive인 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율 (recall_score()) (=민감도(Sensitivity))
ex. 암 환자: 실제 암 환자를 양성이 아닌 음성으로 잘못 판단하면 생명을 앗아갈 정도의 심각한 문제(FN)
ex. 금융거래 사기: 실제 사기 건을 아니라고 잘못 판단하면 회사에 업무적으로 미치는 손해가 큼(FN)
정밀도/재현율 트레이드오프(Trade-off)
: 정밀도와 재현율은 상호 보완적인 평가 지표이기 때문에 어느 하나를 높이면 다른 하나의 수치는 떨어진다.
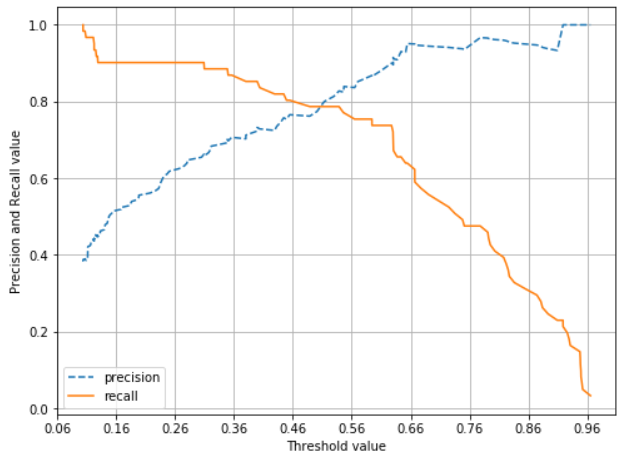
위 그래프의 경우에는 임계값(Threshold)이 0.45인 경우가 best.
일반적으로 이진 분류에서는 임계값을 0.5, 50%로 결정한다. 이를 조정하여 0.4로 내리면 Positive 예측값이 많아지면서, 실제 양성을 음성으로 예측하는 횟수(FN)가 상대적으로 줄어들기 때문에 재현율(=TP/(FN+TP)) 값이 높아진다.

정밀도와 재현율은 단순히 하나의 성능 지표를 높이기 위한 수단으로 사용해서는 안 된다. (극단적인 수치 조작 가능) 따라서, 정밀도와 재현율이 적절하게 조합된 평가 지표가 필요하다.
# 테스트를 수행할 모든 임곗값을 리스트로 저장
thresholds = [0.4, 0.45, 0.50, 0.55, 0.60]
def get_eval_by_threshold(y_test , pred_proba_c1, thresholds):
for custom_threshold in thresholds:
binarizer = Binarizer(threshold=custom_threshold).fit(pred_proba_c1)
custom_predict = binarizer.transform(pred_proba_c1)
print('임곗값:',custom_threshold)
get_clf_eval(y_test , custom_predict)
get_eval_by_threshold(y_test ,pred_proba[:,1].reshape(-1,1), thresholds )
3.4 F1 스코어(F1 Score)
F1 스코어: 정밀도와 재현율을 결합한 지표 (f1_score())
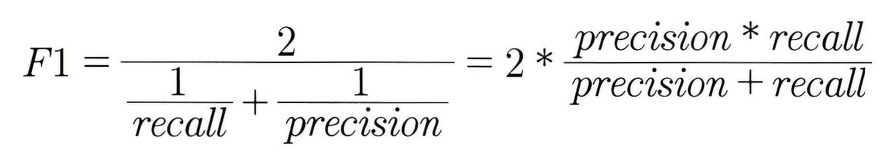
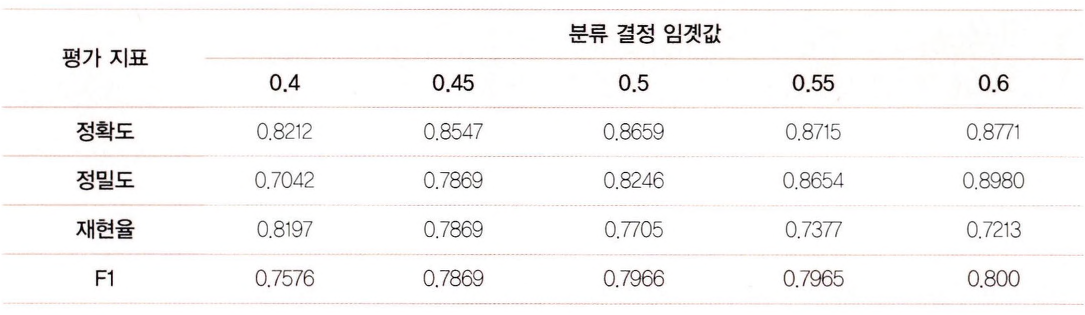
여기서 임계값이 0.6인 경우 F1 값이 가장 좋지만, 재현율이 크게 감소하고 있어 주지해야한다.
3.5 ROC 곡선과 AUC
ROC 곡선
: FPR(FP rate)에 따른 TPR(TP rate, 재현율/민감도)의 변화를 나타내는 곡선 (roc_curve())
- 민감도(Sensitivity, TPR): 실제값 Positive가 정확히 예측되어야하는 수준(=재현율)
- 특이성(Specificity, TNR): 실제값 Negetive가 정확히 예측되어야 하는 수준
FPR = FP/(FP+TN) = 1- 특이성
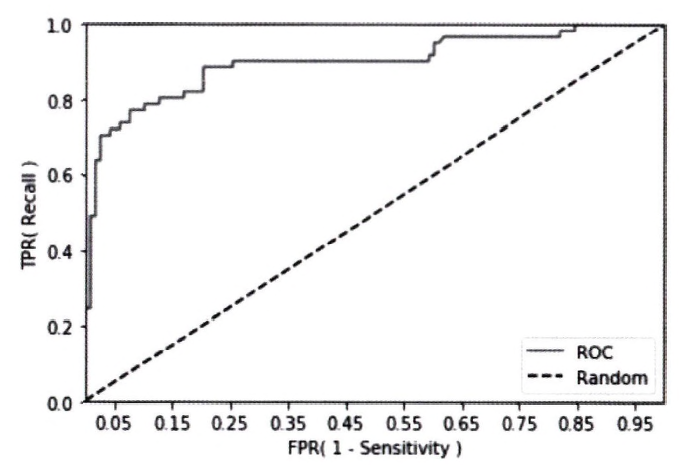
ROC 곡선이 가운데 직선과 멀어질수록 성능이 뛰어난 것이다.
임계값이 1일 경우, 아예 Positive로 예측하지 않아 FP=0이 되므로 FPR=0이 되고,
임계값이 0일 경우, 모두 Positive로 예측하여 TN=0이 되므로 FPR=1이 된다.
AUC 스코어
: ROC 곡선 밑의 면적 (roc_auc_score)
1에 가까울수록 좋은 수치이다. AUC 값이 커지려면 FPR이 작은 상태에서 얼마나 큰 TPR을 얻을 수 있는지가 관건이다.
def get_clf_eval(y_test, pred=None, pred_proba=None):
# 오차행렬
confusion = confusion_matrix( y_test, pred)
# 예측 정확도
accuracy = accuracy_score(y_test , pred)
# 정밀도 및 재현율
precision = precision_score(y_test , pred)
recall = recall_score(y_test , pred)
# f1 스코어
f1 = f1_score(y_test,pred)
# ROC-AUC
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f},\
F1: {3:.4f}, AUC:{4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))