
12.4 Clustering Methods
Clustering(군집화)
- 데이터셋을 n개의 다른 cluster(subgroup)으로 군집화하는 방법
- 비지도 학습: 데이터셋에 기반하여 cluster를 구별
- 데이터셋 내부에서 동질적인 subgroup을 찾는 것이 목표
(PCA: 분산을 일정 부분을 잘 설명할 수 있는 데이터셋의 저차원 표현을 찾는 것이 목표) - ex. 암의 subtype 군집, market segmentation 등
- dendrogram: 클러스터의 개수에 따라 클러스터 결과를 시각화한 것
K-Means Clustering
- K개의 개별 클러스터로 나누는 것
- K를 지정하면, 알고리즘이 데이터를 각 클러스터로 할당
알고리즘
: 클러스터 내의 분산은 최소화하는 방향으로 군집화
- squared Euclidean distance

- K 군집 내의 모든 데이터끼리의 유클리디안 거리의 합을 최소화
- But, 계산이 너무 많음
- simpler algorithm: centroid
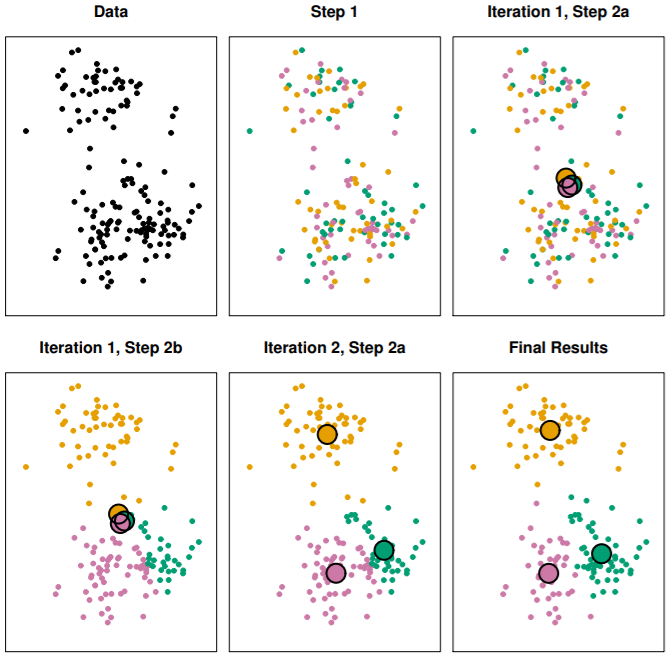
- K 값 임의로 지정
- K개의 클러스터에 클러스터 중심점을 계산함(중심점=p feature 평균 벡터)
- 중심점이 sum of squared deviations를 최소화하는 상수값 역할
- 각 데이터를 가장 가까운 중심점이 있는 클러스터로 할당(유클리디안 거리 이용)
- 더이상 클러스터가 바뀌지 않으면 local optimum
- K-means 알고리즘이 local optimum을 찾는데에 목적이 있기 때문에 초기에 K값을 어떻게 지정하는지에 따라 결과가 달라짐
- 따라서 여러 K에 대해 결과를 도출해볼 필요가 있음
Hierarchical Clustering
- K-means의 단점
- K를 사전에 지정해주어야 함
- 이를 해결한 것이 hierarchical clustering
dendrogram
- bottom-up or agglomerative(응집하는) 알고리즘
- leaf에서 시작하여 위로 올라가면서 cluster되는 형태
- 해석
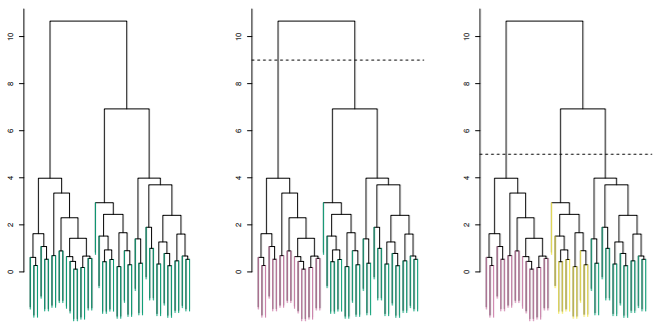
- 각각의 leaf는 45개의 observation을 뜻함
- 위로 올라가면서 비슷한 observation끼리 줄기로 결합됨
- 빠르게 결합된(아래쪽에서 결합된) observation끼리 더 비슷하다는 의미
- 높이는 얼마나 두 observation이 다른지 의미함
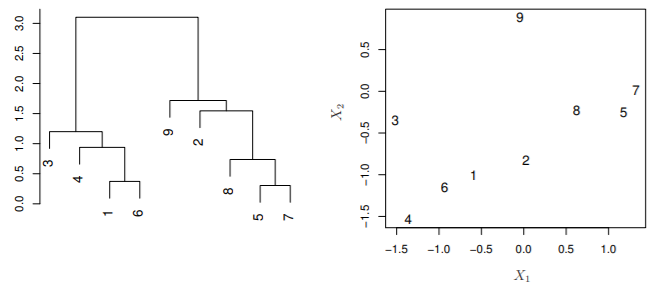
- 여기서 9와 2가 9와 (8,5,7)보다 더 similar하지는 않음
- horizontal로 가깝다고해서 비슷한 것은 아님(좌우는 언제든지 바뀔 수 있음)
- 줄기가 처음 결합되는 부분에서의 높이 차이(vertically)를 비교해야함
- horizontal 컷 밑으로 나뉜 부분이 cluster가 되는 것
- 위 그림에서 9에서 자르면 클러스터는 2개가 됨(2번째 그림)
- 위 그림에서 5에서 자르면 클러스터는 3개가 됨(3번째 그림)
- 결국, cut의 높이를 정하는 것이 K-means에서 K를 정하는 것과 같음
알고리즘
- dendrogram의 밑에서부터 시작, 각 observation은 각 cluster로 생각됨
- 비슷한 두 클러스터끼리 결합됨 -> 전체 하나로 통합될 때가지 반복
- 어떻게 비슷하다고 판단하는지? inter-cluster dissimilarity
- linkage: 두 그룹 간의 dissimilarity를 지정
- complete: largest dissimilarity(가장 일반적, balanced dendrogram)
- average: average dissimilarity(가장 일반적, balanced dendrogram)
- single: smallest dissimilarity
- centroid: dissimilarity beyween the centroid
- inversion문제: 결합 높이가 개별 클러스터 밑에서 형성될 수 있음 -> 해석, 시각화 문제
- linkage: 두 그룹 간의 dissimilarity를 지정
- 어떻게 비슷하다고 판단하는지? inter-cluster dissimilarity
Choice of Dissimilarity Measure
- correlation-based distance
: 각 observation의 feature들의 상관관계가 얼마나 높은지에 따라 similarity 결정
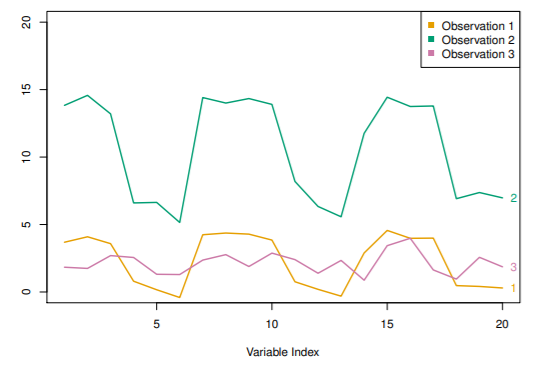
- 1, 3번은 매우 가까움 -> 유클리디안 거리가 작음
- 1, 2번은 비슷한 형태 -> correlation based 거리가 작음
- 데이터 타입이나 분석 목적에 따라 어떤 방법을 사용할지 정해야 함
- ex. identify subgroups of similar shoppers
- 행: shoppers / 열: items / 그 상품을 샀으면 1, 사지 않았으면 0으로 채워진 matrix
- 유클리디안: 상품을 적게 산 사람들끼리 묶임
- correlation: 비슷한 선호도를 가진 사람들끼리 묶임
- 목적을 고려했을 때 이 경우엔 후자 선택
- ex. identify subgroups of similar shoppers
- 변수가 scaled 되어야하는지 고려
- 같은 예제
- 평소에 자주 사는 상품의 경우 inter-shopper dissimilarities에 더 큰 영향을 줄 것임
- 이는 클러스터링에도 영향을 줌(맨 왼쪽)
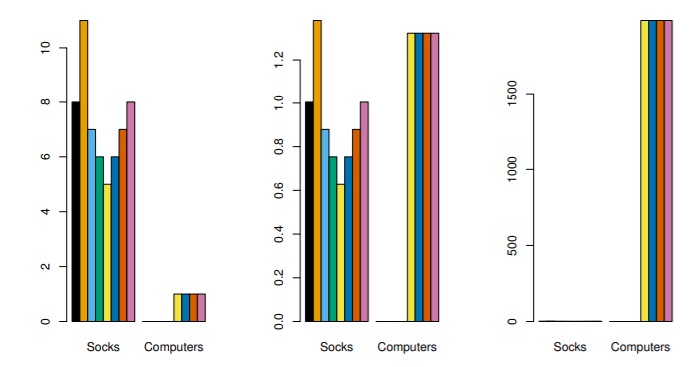
- 변수가 scaled 되면, 각 변수가 hierarchical clustering에 미치는 영향이 동일해짐(중앙)
- 또한, 각 변수의 단위가 다른 경우에는 scaling 필요
- 같은 예제
Practical Issues in Clustering
Small Decisions with Big Consequences
- 스케일링 여부
- hierarchical clustering의 경우: dissimilarity measure, linkage type, dendrogram cut
- K-means clustering의 경우: K 지정
=> 보통 여러 경우를 하고 가장 좋은(유용하고 해석하기 쉬운) 결과를 선택
Validating the Clusters Obtained
- cluster가 실제 그룹을 대표할 수 있는지, 아니면 noise에 의해 생성된 것인지 확인 필요
Other Considerations in Clustering
- 모든 observation이 clustering에 포함되기 때문에 outlier에 의해서 왜곡된 군집이 형성될 수 있음
- mixture model을 대안으로 사용
- 데이터의 작은 변화에도 민감함
- 하나의 데이터를 제외하기만 해도 군집화를 하면 결과가 달라질 수 있음
A Tempered Approach to Interpreting the Results of Clustering
- 하이퍼파라미터를 다양하게 선택하는 등 하나의 결과를 절대적인 것으로 받아들이지 않아야 함
- 또다른 연구와 가설의 starting point로서 사용

Data Analyst | Statistics