
2.1 What is Statistical Learning
Goal of statistical learning: 설명변수와 반응변수 사이에 관계가 있다고 가정했을 때 설명변수로 종속변수를 설명하는 정확한 모델을 개발하는 것
ex. 설명 변수: tv, 라디오, 신문 -> 종속 변수: 판매 수
Y = f(X) + e
- f: systematic information that X provides about Y
- e: error term, mean zero
1. Why estimate f?
Prediction
Yhat = fhat(X), fhat은 블랙박스의 역할
- 목적: 설명변수 X를 이용하여 반응변수 Y를 예측
- 정확도는 reducible error와 irreducible error에 의존
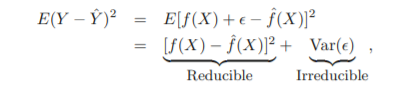
- reducible error: 가장 적절한 통계적 방법을 사용하여 모델의 정확도를 높임으로써 감소 가능
- irreducible error: e에 대한 부분인데, 이는 설명변수 X를 사용하여 감소시킬 수 없는 부분임
- why irreducible error > 0 ?
- e는 Y를 예측하는데 유용하지만, 관측되지 않은 변수들(unmeasured variable)에 대한 정보를 가지고 있을 수 있음
- e는 관측되지 않은 변동성(variation)에 대한 정보를 가지고 있을 수 있음
- 따라서 우리의 목표는 reducible error을 최소화하는 것
Inference
Yhat = fhat(X), fhat의 정확한 형태를 알아야 함
- 목적: 설명변수 X와 반응변수 Y의 관계에 대한 이해
- 많은 X들 중 중요한 소수의 설명변수 찾기
- Y와 각 X들 간의 관계 유무
- Y와 X들의 관계가 선형 방정식으로 설명될 수 있는지:
Ex. of Prediction and Inference
- Prediction: wants an accurate model to predict the response using the predictors
- Inference: Which media contribute to sales/Which media generate the biggest boost in sales/How much increase in sales is associated with a given increase in TV advertising
- Prediction + Inference: 이 집의 가치가 얼마나 과소/과대 평가 되었는가?/ 한강뷰의 집은 얼마나 더 많은 가치가 있을까?
- 선형 모델: 간단하고 해석하기 쉬움+ 정확한 예측 불가
- 복잡한 비선형 모델: 정확한 예측 + 해석하기 어려움
2. How do we estimate f?
Parametric Methods(모수 방법)
- 모델-based approach. f 추정 = 모델의 모수 추정(베타0~베타p 추정)
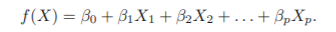
- 과정
- f의 형태를 가정 ex. 선형 모델
- 모델이 선택되면 학습 데이터를 가지고 모델에 학습시킴
- ols 방법 등
- 장점: 모수를 추정하는 것으로 문제를 단순화
- 단점: 추정한 모델이 unknown form of f와 같이 않을 것
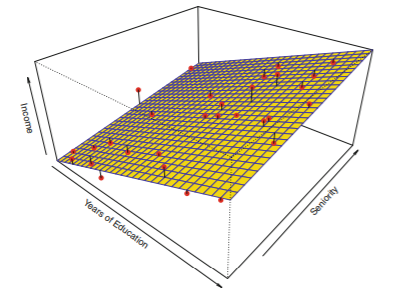
Non-parametric Methods(비모수 방법)
- f의 형태에 대한 가정을 하지 않음
- f의 추정치를 찾음
- 장점: 가능한 다양한 형태의 f에 대해 비교적으로 정확한 fit을 보여줌
- 단점: 모델에 대한 추정이 모수에 대한 추정이 되지 않으므로, f에 대한 정확한 추정을 위해서는 관측치의 수가 많아야함
- ex. thin-plot spline: attempts to produce an estimate for f that is as close as possible to the observed data
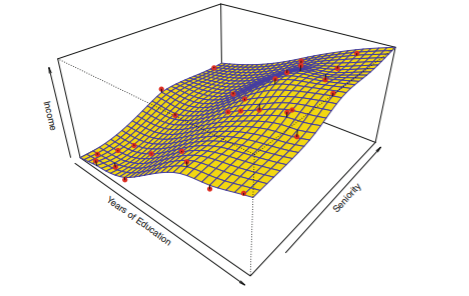
3. The Trade-off between prediction accuracy and model interpretability
- restrictive models: 해석하기 쉬움, 설명변수와 반응변수의 관게를 이해하기 쉬움
ex. 선형 회귀 < lasso (set a number of coefficient to exavtly zero: more restrictive) - flexible models: 관계를 이해하기 어렵지만 정확한 예측 가능
- 목적이 prediction인지 inference인지에 따라 예측 정확도가 높은 모델을 택할 것인지, 해석이 쉬운 모델을 택할 것인지가 달라짐
4. Supervised vs. Unsupervised learning
Supervised learning: 지도 학습
- X와 Y가 모두 주어져 있어 모두를 가지고 학습
- linear regression, logistic regression 등
Unsupervised learning: 비지도 학습
- X는 주어져 있지만 이에 해당하는 Y가 없어 X만을 가지고 학습
- clustering
semi-supervised learning
: n개의 관측치 중, m(m<n)개의 관측치는 X, Y값이 모두 주어져 있지만, 나머지 n-m개의 관측치는 X값만 주어진 경우
5. Regression vs. Classification
- quantitative variables: 숫자형
- qualitative variables: 카테고리형
- ex. male, female
회귀
: quantitative response
예외) logistic regression: 이진분류에 사용되지만 numerical value를 사용하기 때문에 회귀로 봐도 괜찮음
분류
: qualitative response
2.2 Assessing Model Accuracy
1. Measuring the quality of fit
MSE

- training data로 MSE를 줄이는 방향으로 모델링. 하지만, 우리의 관심은 test data에 대한 예측 정확도임.
- training MSE가 작다고 해서 test MSE도 작다는 보장이 없음
- 따라서, 단순히 training MSE가 가장 작은 모델을 선택하는 것보다 test MSE에 대한 비교도 필요함
- ex.
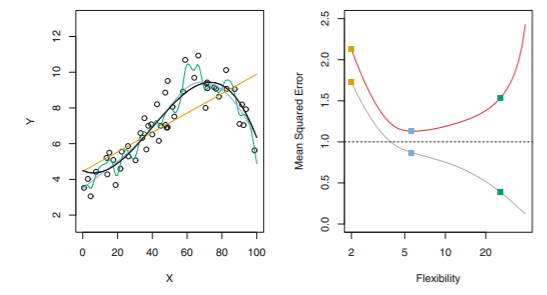
- df = 5 정도가 적절해 보임
- df = 20을 넘어간 초록색 모델은 과적합
2. The bias-variance trade-off
- variance: training set이 변화하면 fhat이 변화하는 양
- 함수가 training set에 더 flexible할수록 하나의 데이터가 변화하면 f의 추정치도 크게 변화함
- bias: error. accuracy와 관련.
- 함수가 training set에 더 flexible할수록 오류는 감소함
- ex.
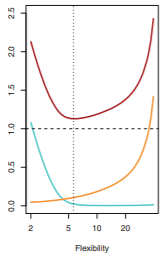
이러한 mse, bias, variance의 관계를 트레이드 오프 관계라고 함
3. The classification setting
train error
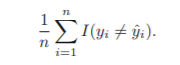
test error
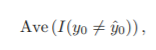
=> a good classifier is one for which the test error is smallest
Bayes classifier
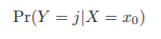
- test set x0에 대해 class j에 해당할 확률
=> ex. 0.5 이상이면 class 1, 미만이면 class 2 에 할당 - bayes decision boundary: 확률이 0.5가 되는 점들의 집합
- bayes error rate
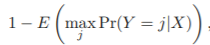
KNN
- test data x0과 가까운 training set의 점들을 찾아 더 많이 속한 class에 class 할당
- probability
N0: class j인 점들의 집합
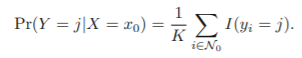
- ex. j=1일 때의 확률이 0.66, j=2일 때의 확률이 0.33이면 x0는 class 1에 속함
- 몇 개의 이웃을 고려할지, 즉 K의 값에 따라 성능이 결정됨
-
K=1인 경우, 과적합 발생 가능성이 매우 높음(바운더리 매우 복잡)
-
K=100인 경우, 과소적합 발생 가능성 있음(바운더리 매우 단순)
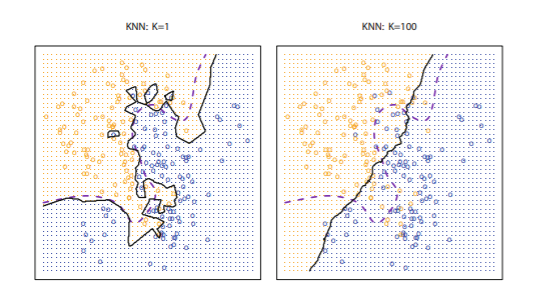
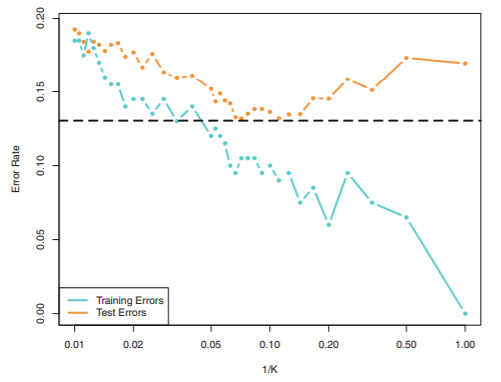
-
K가 작아질수록 traing error는 감소하지만 test error는 증가할 수 있어 적절한 K를 찾는 것이 필요
-

Data Analyst | Statistics