
Classification: 반응변수 Y가 qualitive(or categorical) variable
4.1 An Overview of Classification
Ex 1. 응급실에 온 환자가 세 가지 증상 중 어떤 증상을 가지고 있을까
Ex 2. 온라인 뱅킹 서비스는 IP 주소, 과거 거래 내역 등을 고려하여 해당 사이트의 거래가 사기인지 아닌지 판단해야 함
Ex 3. 어떤 DNA 돌연변이가 유해한지 판단
4.2 Why Not Linear Regression?
Multiple Classification
: qualitive variable의 인코딩
case 1)

case 2)

=> case 1과 case 2의 경우의 회귀 모델이 달라 결국 예측값도 달라질 것
=> 만약 natural ordering, 즉 순서형 변수였다면 1, 2, 3 이렇게 인코딩하는 것이 reasonable할 것
Binary Classification
: 더미 변수 활용

=> stroke와 drug overdose 중에 무엇이 0 또는 1이든 간에 선형 회귀 모형은 같은 예측을 할 것
In General
일반적으로 2가지 이상의 qualitative response를 가진 경우까지 dummy variable approach를 확장시키는 것이 쉽지 않음
=> 회귀보다는 분류의 문제로 접근하는 것이 더 좋음
4.3 Logistic Regression
: binary 문제에서 category에 속할 확률을 예측 -> 후에 특정 기준(ex. 0.5)에 따라 분류
Logistic Model
linear function
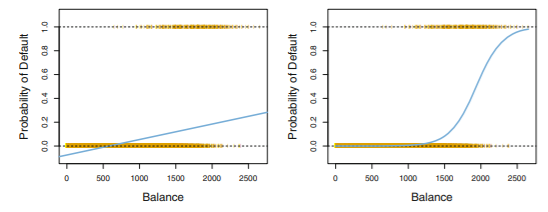
left case)
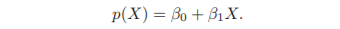
확률이 선형모형이면, 0과 1 사이에 머물지 않고 벗어남. 따라서 확률을 0~1 사이로 만들어주는 다른 함수 필요
logistic function
right case)
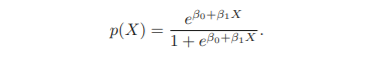
- maximum likelihood이라는 방법으로 모델 fit
- 확률이 0에 가까워지기는 하지만, 절대 0 밑으로 떨어지지 않음. 1에 가까워지기는 하지만, 절대 1 위로 올라가지는 않음.
- S-shaped curve
Odds, Log-odds(logit)
Odds
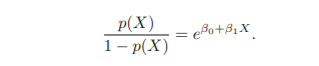
- 0~무한대 값을 가짐
Log-Odds
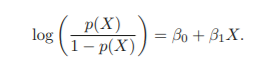
- X에 대해 선형
P(X)와 X는 선형 관계가 아니므로 X의 1 unit increase가 p(X)의 변화와 일치하지 않는다. 하지만, X가 증가하면 P(X)가 증가하고, X가 감소하면 P(X)는 감소한다.
Estimating the Regression Coefficients
Maximum likelihood
: maximize the likelihood function
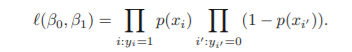
- 최소제곱법도 maximum likelihood의 특별한 경우
- 이를 통해 실제 값과 최대한 비슷한 예측값을 만들도록 beta1, beta0 추정
- ex.

- beta1 = 0.0055: 1 unit increase in balance = 0.0055 unit increase in the log odds of default
- balacne와 default의 확률과 상관관계가 있음
Making Predictions
ex.

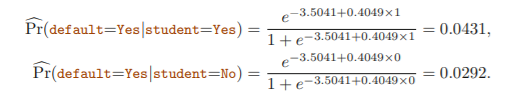
students tend to have higher default probabilities than non-students.
Multiple Logistic Regression
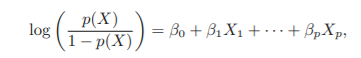
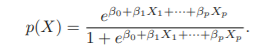
ex.
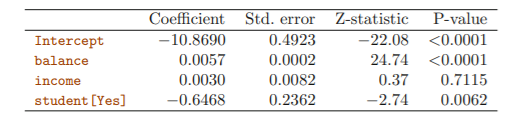
- default~student에서는 student[Yes] 더미 변수의 계수가 양수였는데 여기서는 음수가 나옴
- 즉, balance와 income을 fixed 시켰을 때 student가 default할 확률이 non-student보다 적음
- 이유는?
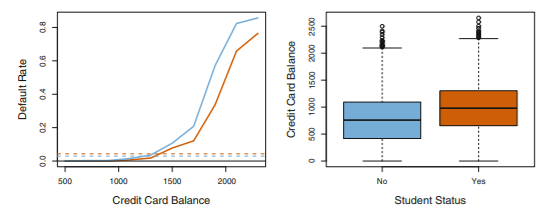
student 변수와 balance 변수가 서로 상관관계를 가지기 때문에(student가 non-student보다 평균 balance가 높음)
4.4 Linear Discriminant Analysis
- 로지스틱 회귀: 두 개의 반응변수 클래스에 대해 k에 속할 확률 Pr(Y=k|X=x)를 직접 모델링(Y의 조건부 확률 모델링)
- alternative: 반응변수 Y의 각 클래스에서 설명변수 X의 분포를 모델링(Pr(X=x|Y=k))하고, 베이즈 정리를 사용하여 Pr(Y=k|X=x)에 대해 추정
- 만약 이 분포가 정규분포라면 로지스틱 회귀와 매우 비슷
logistic regression이 아닌 LDA를 사용하는 이유
- 범주가 명확하게 구분되어 있는 경우, 로지스틱 회귀는 불안정한 결과를 보임
- 자료의 개수가 적을 때에도 각 클래스에 대한 X의 분포가 정규분포와 유사하다면, 로지스틱 회귀보다 안정적임
- 3개 이상의 범주가 있을 시 성능이 더 뛰어남
Using Bayes' Theorem for classification
Bayes Theorem
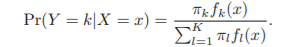
- fk(x)=Pr(X=x|Y=k): 클래스 k의 X의 밀도함수
- Pr(Y=k|X=x): 사후 확률
- πk: 클래스 k의 사전 확률
Bayes Classifier
: Pk(X)가 가장 큰 클래스에 할당
LDA for p=1
fk(X)의 정규분포 가정
- fk(X) 가 정규분포(가우시안 분포)를 따른다고 가정
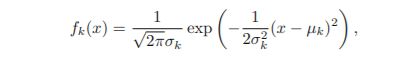
- k개의 클래스의 분산이 모두 동일하다고 가정
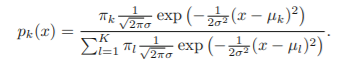
이를 log를 취하고 변환을 하면,
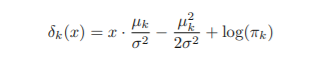
bayes classifier은 위 값이 가장 큰 클래스로 할당 - 만약 클래스 개수가 2개(k=2)이고, 사전분포가 같다면(π1=π2), bayes decision boundary는 다음과 같음
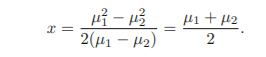
πk, μk, σ^2 추정
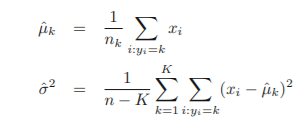
(n: 전체 훈련 데이터셋 개수, nk: k번째 클래스의 훈련 데이터셋의 개수)
-
사전분포에 대한 정보가 없으면 보통 아래와 같이 정의
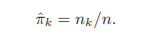
-
이를 아래 식에 대입하여 값을 구하고, 이 값이 가장 큰 클래스로 할당함(LDA가 Bayes classifier에 근사함)
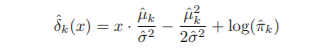
위 식(discriminant function)은 x에 대한 선형 함수 형태
ex.
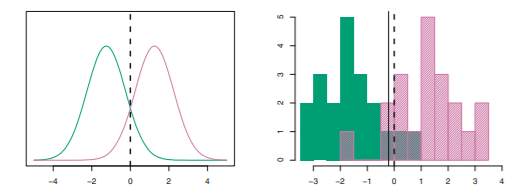
n1 = n2, πhat1 = πhat2
-> Bayesian boundary = (μhat1 + μhat2)/2 (점선)
LDA boundary(실선)
bayes error rate: 10.6%, LDA test error rate: 11.1%
=> 이 데이터셋에서 LDA의 성능이 좋은 편
LDA for p>1
fk(X)의 multivariate normal 분포 가정
X = (X1, X2, ..., Xp)
-
fk(X) 가 다변량 정규분포(다변량 가우시안 분포)를 따른다고 가정
X~N(μ,Σ)
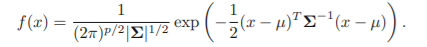
-
각 predictor는 일변량 정규분포를 따름
Xk~N(μk,Σ) -
k개의 클래스의 분산이 모두 동일하다고 가정
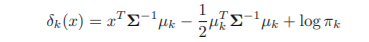
bayes classifier은 위 값이 가장 큰 클래스로 할당
πk, μk, Σ 추정
일변량 정규분포 가정했을 때와 동일하게, μhatk와 Σ를 추정하고 이를 아래의 식에 대입하여 추정치를 구한 후, 이 추정치가 가장 큰 클래스에 데이터 할당
위 식 역시 linear function of x (=LDA decision rule depends on x only through a 'linear' combination of its elements)
ex.
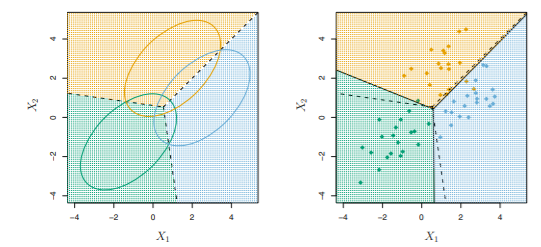
- 왼쪽 eliptical line: 95% 확률
- Bayesian boundary(점선), LDA boundary(실선)
- 두 boundary가 비슷
- Bayes error rate: 0.0746, LDA error rate: 0.0770 => 이 데이터셋에서 LDA의 성능이 좋은 편
Training error rate
- train error rate이 test error rate보다 낮음(train set에 맞춰서 모델이 생성되었기 때문)
- defualt(연체자)가 전체의 3.33% 밖에 되지 않는 경우, 전체 이용자를 모두 연체자가 아니라고 예측을 할 경우의 error rate이 3.33% 밖에 되지 않을 것
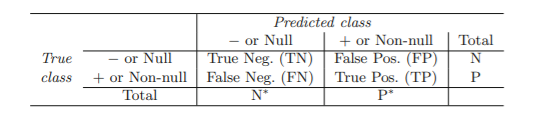
1. Confusion matrix
: 실제와 예측 분류 상황을 시각화하여 확인 가능
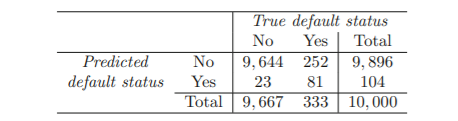
전체 error rate은 낮음
But, 연체자들의 252/333=75.7%가 잘못 분류됨
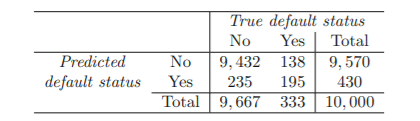
2. Sensitivity and Specificity
Sensitivity(민감도): TP/(FN+TP)
실제 값이 Positive인 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율
ex. 81/333 = 24.3%
Specificity(특이성): TN/(TN+FP)
실제값 Negetive가 정확히 예측되어야 하는 수준
ex. 9644/9667 = 99.8%
Why LDA have such sensitivity in Default data?
: LDA는 classifier 중 전체 오류가 가장 작은 Bayes classifier에 근사하려고 하는데, 이는 어느 class에서 오류가 생기는지에 상관 없이 전체 오류의 크기만 줄이려고 함
=> threshold를 변경함으로써 카드사의 필요에 보다 적합한 분류기를 개발 가능
임계값을 0.5에서 0.2로 변경한 결과, 전체 error rate은 3.73%으로 증가했지만, 민감도도 195/333 = 58.6%로 증가(연체자를 더 잘 분류함)
Trade-off
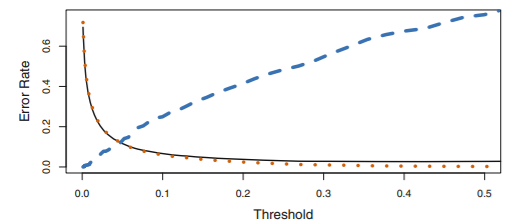
임계값이 증가할수록 전체 error rate은 감소하지만, Positive 중에서 Negative로 잘못 예측할 확률, 즉, 연체자 중에서 연체자가 아니라고 예측될 확률은 증가
-> domain knowledge에 따라 결정(default와 연관된 비용에 대한 정보 등)
ROC curve
: two types of error를 동시에 시각적으로 보여줌

- X축: 1 - specificity
Y축: Sensitivity - ROC curve 아래 부분: AUC
AUC가 클수록 좋은 분류기 - 모든 임계치를 비교하기 때문에 서로 다른 분류기들을 비교하는데 용이
QDA(Quadratic Discriminant Analysis)
- 각 class의 데이터들은 모두 정규분포를 따름
- 예측을 위해서 파라미터의 추정치를 Bayes' theorem에 대입
- But! 각 class들이 각각의 공분산행렬을 가짐. X~N(μk, Σk)
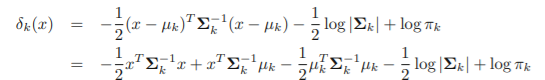
위 값이 최대가 되는 class에 할당.
X에 대한 quadratic fucntion(not linear)
Why prefer LDA to QDA, or vice-versa?
-
prefer LDA: train set가 상대적으로 적어 분산을 줄이는 것이 중요한 경우
-
prefer QDA: train set이 매우 커서 분산을 줄이는 것이 중요하게 고려되지 않거나, K 클래스에 대한 공통 공분산 행렬의 가정이 명백히 사용 불가능할 경우
-
ex.
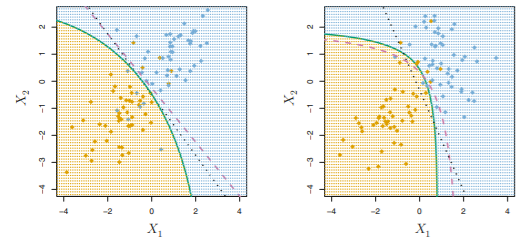
(좌) common correlation of 0.7
(우) different correlation of 0.7 and -0.7
4.5 A Comparison of Classification Methods
Logistic Regression vs. LDA
logistic regression
LDA
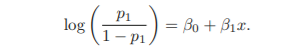
- 공통점
- have linear functions of x
- have linear decision boundaries
- 차이점
- logistic regression: maximum likelihood으로 추정됨
- LDA: 정규분포로부터의 평균과 분산의 추정치를 갖고 계산됨
Two approach, similar?
: fitting 과정 말고는 다른 것이 없어 비슷한 결과를 줄 수도 있다?
- LDA 선호: 데이터가 공통 공분산 행렬을 가진 가우시안 분포를 가진다는 가정이 성립하는 경우
- logistic regression 선호: 정규분포 가정이 성립되지 않을 경우
KNN vs. logistic regression and LDA
- KNN: 비지도학습, decision boundary의 모양에 대한 가정 없음
- logistic regression and LDA: 지도학습
- decision boundary가 매우 비선형인 경우 KNN이 선호됨
QDA vs. KNN, logistic regression, LDA
- KNN과 logistic regression, LDA 사이의 절충안 역할
- logistic regression, LDA보다 더 넓은 범위의 문제를 다룰 수 있음
- KNN처럼 flexible하지는 않지만, 학습 데이터가 제한적일 경우에 성능이 더 좋음(decision boundary(δ1=δ2)에 대한 가정이 있기 때문)
