
4.1 분류
: 학습 데이터로 주어진 데이터의 피처와 레이블값을 머신러닝 알고리즘으로 학습해 모델 생성, 이 모델로 새로운 데이터 값이 주어졌을 때 미지의 레이블 값 예측하는 방법 (지도학습)
<종류>
- 나이브 베이즈
- 로지스틱 회귀
- 결정 트리
- 서포트 벡터 머신
- 최소 근접 알고리즘
- 신경망
- 앙상블
앙상블
: 서로 다른/또는 같은 알고리즘을 단순히 결합한 형태 또는 배깅, 부스팅
4.2 결정 트리
: 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리(Tree) 기반의 분류 규칙을 만드는 것. 따라서 데이터의 어떤 기준을 바탕으로 규칙을 만들어야 가장 효율적인 분류가 될 것인가가 알고리즘 성능을 좌우.
트리의 구조
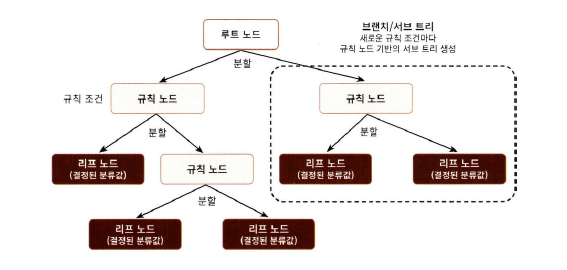
-
트리의 구조
- 규칙 노드: 규칙 조건
- 루트 노드: 첫 규칙 조건
- 리프 노드: 결정된 클래스(더이상 자식 노드가 없는 노드)
- 브랜치 노드: 자식 노드가 있는 노드
- 서브 트리: 새로운 규칙 조건마다 생성되는 트리
-
규칙이 너무 많으면(=트리의 깊이가 깊어지면) 예측 성능이 저하될 수 있음. (분류 방식이 복잡해져 과적합이 될 가능성이 큼)
--> 결정 노드는 정보 균일도가 높은 데이터 세트를 먼저 선택할 수 있도록 규칙 조건을 만듦 (균일도가 높아야 예측이 잘 됨)
ex. 10개의 공이 모두 검은색인 세트-> 쉽게 검은색이라고 예측,
검은공 5개, 흰 공 5개인 세트->데이터를 판단하는데 있어 많은 정보 필요
정보 이득(Information gain)
: 엔트로피라는 개념을 기반으로 균일도를 측정하는 방법
- 엔트로피: 데이터 집합의 혼잡도 (다른 값이 섞여 있으면 엔트로피가 높음)
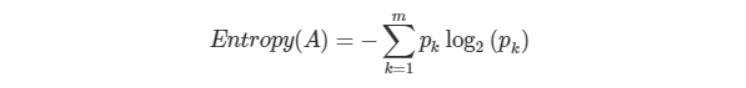
- 정보 이득 지수: 1-엔트로피 지수
- 정보 이득이 높은 속성(=균일하게 나눌 수 있는 것) 기준으로 분할
DecisionTreeClassifier()은 지니 계수를 이용해 데이터 세트를 분할함.
- 지니 계수: 데이터 집합의 불순도(impurity)
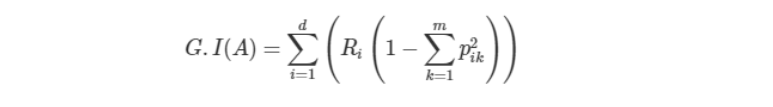
결정트리 알고리즘은 정보 이득이 높거나 지니 계수가 낮은 조건을 찾아서 반복적으로 분할함.
결정 트리 모델의 특징
- 알고리즘이 쉽고 직관적
- 각 피처의 스케일링과 정규화 같은 전처리 작업이 필요 없음
- 과적합으로 정확도가 떨어짐 (모델의 정확도를 높이기 위해 조건을 추가하면 트리 깊이가 깊어져 결과적으로 복잡한 학습 모델이 생성됨. 과적합이 된 모델은 예측 성능이 떨어지기 때문에 트리의 크기를 제한하는 것이 필요)
결정 트리 파라미터
분류: DecisionTreeClassifier()/ 회귀: DecisionTreeRegressor()
- min_samples_split: 노드 분할을 위한 최소한의 샘플 데이터 수(default=2, 작을수록 과적합 가능성 증가)
- min_sampels_leaf: 말단 노드(leaf)가 되기 위한 최소한의 샘플 데이터 수
- max_features: 최적의 분할을 위해 고려할 최대 피처 개수(default=None)
- max_depth: 트리의 최대 깊이(default=None)
- max_leaf_nodes: 말단 노드(leaf)의 최대 개수
결정 트리 모델의 시각화
: Graphviz 패키지 이용
from sklearn.tree import export_graphviz
# export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성함.
export_graphviz(dt_clf, out_file="tree.dot", class_names=iris_data.target_names , \
feature_names = iris_data.feature_names, impurity=True, filled=True)
import graphviz
# tree.dot 파일을 Graphviz 읽어서 Jupyter Notebook상에서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)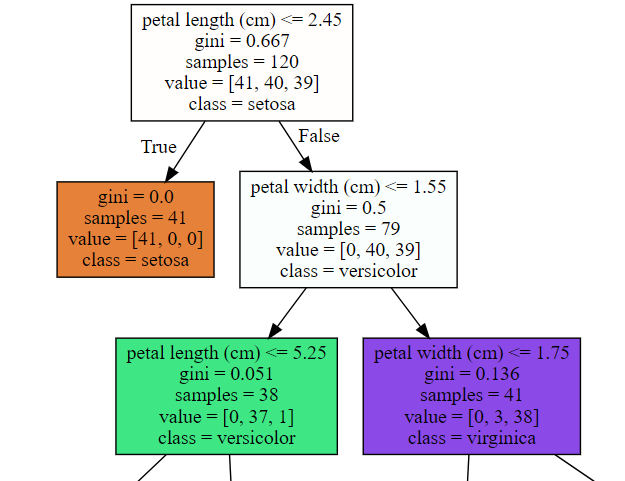
- 루트 노드: setosa, versicolor, virginica 각각 41, 40, 39개의 데이터, 총 120개의 데이터를 가짐. setosa의 개수가 가장 많으므로 class는 setosa.
- 주황색 노드: 모든 41개의 데이터가 setosa. 더이상의 규칙이 필요없는 리프 노드
- 하얀색 브랜치 노드: 지니 계수가 0.5로 높으므로 추가적인 규칙 필요한 브랜치 노드
- 초록색 노드: 대부분이 versicolor인 데이터로 지니 계수가 매우 낮지만, 데이터가 혼재되어 있어 새로운 규칙으로 자식 노드 생성 필요
- 보라색 노드: 대부분이 virginica인 데이터로 지니 계수가 낮지만, 이 역시 데이터가 혼재되어 있어 새로운 규칙으로 자식 노드 생성 필요
하이퍼파라미터 조정
-
max_depth
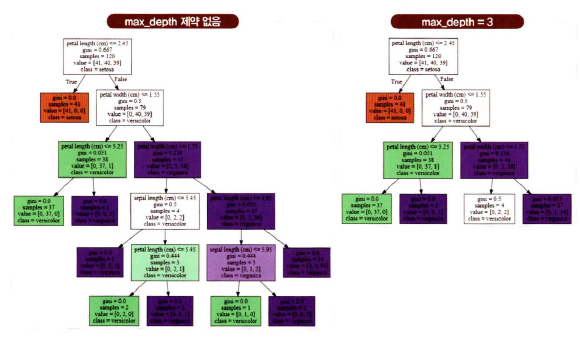
깊이를 줄이면 보다 간단한 트리 생성 -
mean_samples_split
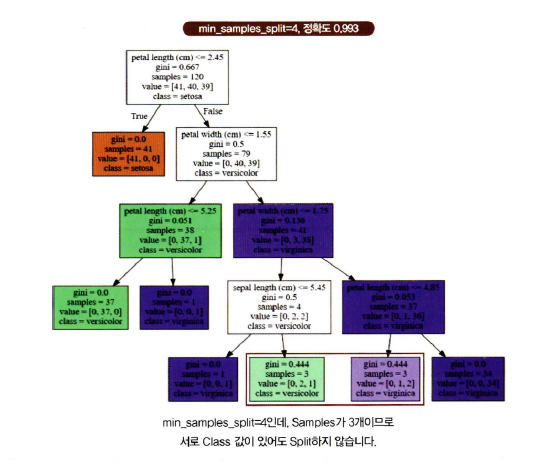
mean_samples_split=4이면, 샘플 수가 3인 노드들은 분할 불가 -
mean_samples_leaf
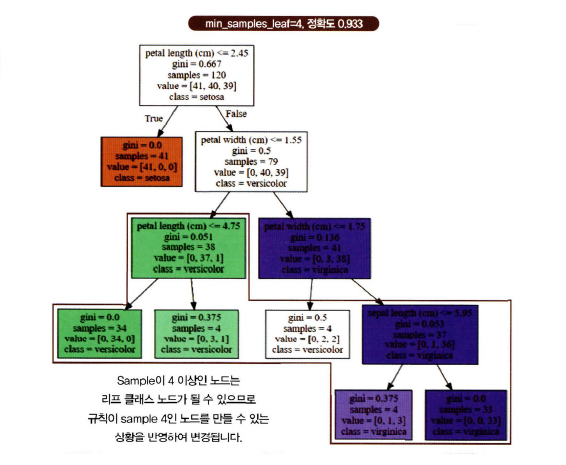
mean_samples_leaf=4이면, 샘플 수가 4 이하이면 리프 노드가 됨
피처 별 중요도
: 결정 트리는 균일도에 기반해 어떤 속성을 규칙 조건으로 선택하는지가 중요. 중요한 몇 개의 피처가 명확한 규칙 트리를 만드는 데 기여하며, 간결하고 이상치에 강한 모델을 만들 수 있음. (featureimportances)
sns.barplot(x=dt_clf.feature_importances_, y=iris_data.feature_names)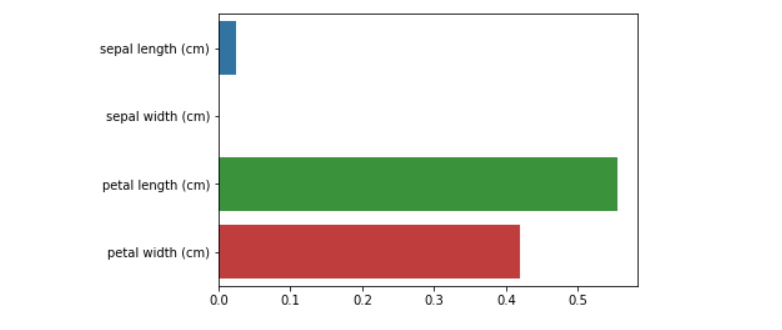
petal length의 중요도가 가장 높음. 따라서 결정 트리의 루트 노드의 조건이 petal length에 대해서 생성됨.
결정 트리 과적합(Overfitting)
X_features, y_labels = make_classification(n_features=2,
n_redundant=0, n_informative=2,n_classes=3,
n_clusters_per_class=1,random_state=0)
# n_features: 독립 변수의 수(여기서는 2차원 시각화를 위해 2로 설정)
# n_redundant: 독립 변수 중 다른 독립 변수의 선형 조합으로 나타나는 성분의 수
# n_informative: 독립 변수 중 종속 변수와 상관관계가 있는 변수의 수
# n_classes: 종속 변수의 클래스 수
# n_clusters_per_classes: 클래스 당 클러스터 수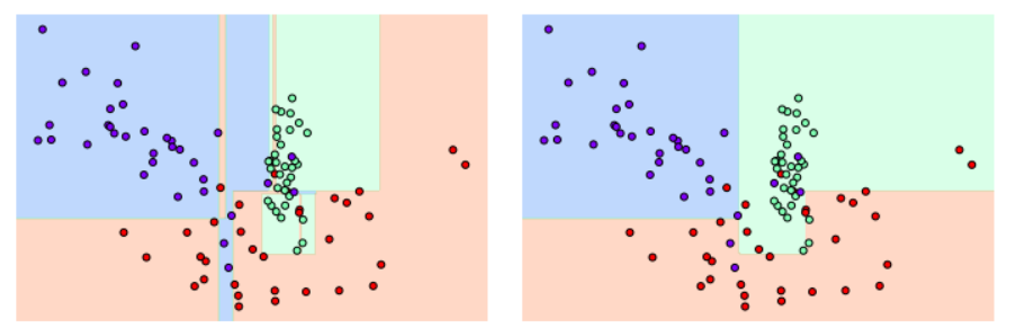
좌측 그래프는 일부 이상치 데이터까지 분류하여 결정 기준 경계가 많아지고 매우 복잡해짐(과적합 가능성 매우 높음). 이를 min_samples_leaf=6을 설정하여 다시 시각화한 결과 이상치에 크게 반응하지 않으면서 좀 더 일반화된 분류 규칙에 따라 분류되었음.
사용자 행동 인식 데이터 세트의 예측 분류
@
4.3 앙상블 학습
: 여러 개의 분류기를 생성하고, 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법
- 대부분의 정형 데이터 분류 시에는 뛰어난 성능
- 랜덤 포레스트, 그래디언트 부스팅, XGBoost, LightGBM 등
- 학습 유형: 보팅, 배깅, 부스팅 등
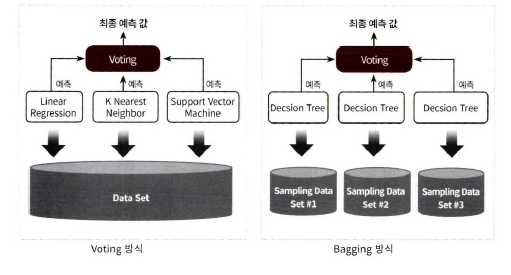
ex. (좌) 선형 회귀, K 최근접 이웃, 서포트 벡터 머신 예측 결과를 가지고 보팅을 통해 최종 예측 결과 선정 / (우) 결정 트리로 여러 분류기가 개별 예측
1. 보팅(Voting)
: 서로 다른 알고리즘을 가진 분류기를 결합하여 최종 예측 결과를 결정하는 방식
-
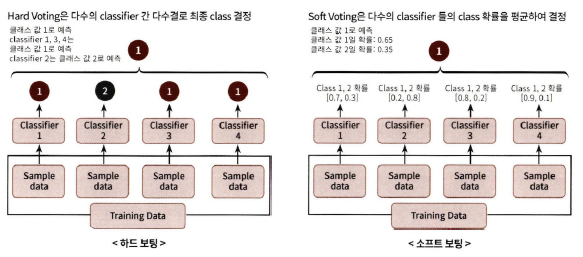
하드 보팅: 예측한 결괏값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결괏값으로 선정
-
소프트 보팅: 분류기들의 레이블 값 결정 확률을 평균해서 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결괏값으로 선정(일반적 방법/예측 성능이 더 좋음)
-
보팅 분류기(VotingClassifier)
# 로지스틱 회귀와 KNN 사용
lr_clf = LogisticRegression()
knn_clf = KNeighborsClassifier(n_neighbors=8)
# 개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현한 분류기
vo_clf = VotingClassifier( estimators=[('LR',lr_clf),('KNN',knn_clf)] , voting='soft' )
# estimator: 보팅에 사용될 여러 개의 Classifier 객체들을 튜플 형식으로 입력
# voting: hard/soft (default=hard)보팅으로 분류기를 결합한다고 해서 무조건 예측 성능이 향상되는 것은 아님. 하지만 보통은 단일 알고리즘보다는 좋은 경우가 많음.
2. 배깅(Bagging)
: 각각의 분류기가 모두 같은 유형의 알고리즘을 기반으로 하지만, 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행 ex. 랜덤 포레스트
- 부트스트래핑 분할 방식: 개별 Classifier에게 데이터를 샘플링해서 추출하는 방식
- 개별 분류기가 부트스트래핑 방식으로 샘플링된 데이터 세트에 대해서 학습을 통해 개별적인 예측을 수행한 결과를 보팅을 통해서 최종 예측 결과를 선정
- 데이터 세트 간의 중첩 허용
3. 부스팅(Boosting)
: 여러 개의 분류기가 순차적 학습, 앞선 분류기의 예측이 틀린 데이터에 대해서 다음 준류기에게 가중치를 부여하면서 학습과 예측 진행 ex. 그래디언트 부스트, XGBoost, LightGBM
4. 스태킹
: 여러 가지 다른 모델의 예측 결괏값을 다시 학습 데이터로 만들어서 다른 모델로 재학습시켜 결과를 예측하는 방법
4.4 랜덤 포레스트
: 여러 개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링하여 개별적으로 학습 수행, 최종적으로 모든 분류기가 보팅을 통해 예츠 결정
- 앙상블 알고리즘 중 비교적 빠른 수행 속도
- 결정 트리를 기반 알고리즘으로 해 쉽고 직관적임
- 배깅의 대표적인 알고리즘
- RandomForestClassifier
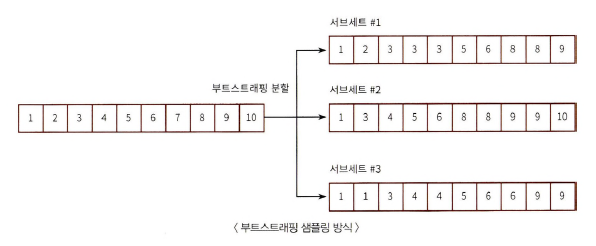
부트스트래핑(Bootstrapping)
: 서브세트의 데이터 건수는 전체 데이터 건수와 동일하지만 개별 데이터가 중첩되어 있음.
하이퍼 파라미터 및 튜닝
하이퍼 파라미터
- n_estimators: 결정 트리의 개수(default=10)
- max_features: sqrt(전체 피처 개수) 만큼 참조
- max_depth
- min_samples_leaf
튜닝
params = {
'n_estimators':[100],
'max_depth' : [6, 8, 10, 12],
'min_samples_leaf' : [8, 12, 18 ],
'min_samples_split' : [8, 16, 20]
}
# RandomForestClassifier 객체 생성 후 GridSearchCV 수행
rf_clf = RandomForestClassifier(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf , param_grid=params , cv=2, n_jobs=-1 )
grid_cv.fit(X_train , y_train)