
4.5 GBM(Gradient Boosting Machine)
개요
부스팅: 여러 개의 약한 학습기를 순차적으로 학습, 예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식
1. AdaBoost(에이다 부스트)
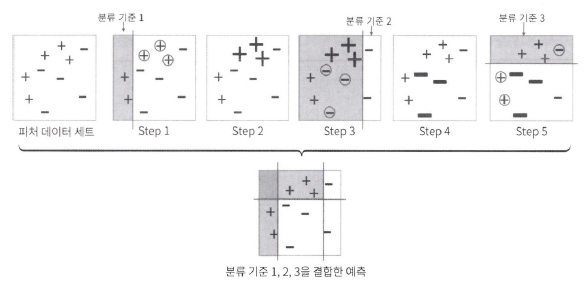
Step 1: 분류 기준 1로 +/- 구분. 동그라미는 잘못 분류된 데이터.
Step 2: 동그라미에 가중치 부여
Step 3: 분류 기준 2로 +/- 구분. 동그라미 잘못 분류된 데이터.
Step 4: 동그라미에 더 큰 가중치 부여
Step 5: 분류 기준 3으로 +/- 구분.
Final: 분류 기준 1, 2, 3을 결합한 예측 결과
2. Gradient Boost(그래디언트 부스트)
: 가중치 업데이트를 경사 하강법을 이용
- 경사 하강법: 오류식(h(x) = y - F(x), F(x): 예측함수, y: 실제 결과값)을 최소화하는 방향성을 가지고 반복적으로 가중치 값을 업데이트하는 것
- GradientBoostingClassifier
- 장점: 일반적으로 랜덤 포레스트보다는 에측 성능이 조금 뛰어남, 과적합에도 강한 뛰어난 예측 성능
- 단점: 수행 시간 오래 걸림, 하이퍼 파라미터 튜닝 노력 필요
GBM 하이퍼 파라미터 및 튜닝
하이퍼 파라미터
- loss: 비용함수 지정. 보통 기본값인 'deviance' 적용
- learning_rate: 학습 진행 시마다 적용하는 학습률. 0~1. (default=0.1) 작은 값은 업데이트 값이 작아져 최소 오류 값을 찾아 예측 성능이 높아질 수 있지만 시간이 오래 걸리고, 큰 값은 최소 오류 값을 찾지 못하여 예측 성능은 떨어지지만 빠른 수행이 가능.
- n_estimators: weak learner의 개수. (default=100). 개수가 많을수록 예측 성능이 좋아지지만 시간이 오래 걸림. learning_rate와 상호 보완적으로 조합해 사용함.
- subsample: weak learner가 학습에 사용하는 데이터의 샘플링 비율. (default=1: 전체 학습 데이터를 기반으로 학습)
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100, 500],
'learning_rate' : [ 0.05, 0.1]
}
grid_cv = GridSearchCV(gb_clf , param_grid=params , cv=2 ,verbose=1)
grid_cv.fit(X_train , y_train)4.6 XGBoost(eXtra Gradient Boost)
개요
- 분류와 회귀 영역에서 뛰어난 예측 성능
- GBM 대비 빠른 수행 시간: 병렬 수행 및 다양한 기능, but 다른 머신러닝 알고리즘에 비해서 빠르다는 것은 아님
- 과적합 규제
- Tree pruning: 더이상 긍정 이득이 없는 분할을 가지치기 해서 분할 수를 더 줄임
- 자체 내장된 교차 검증: 반복 수행 시마다 교차 검증을 수행해 최적화된 반복 수행 횟수를 가질 수 있음
- 조기 중단 기능: n_estimators에 지정한 부스팅 반복 횟수에 도달하지 않더라도 예측 오류가 더 이상 개선되지 않으면 반복을 중지해 수행 시간 개선
- 결손값 자체 처리
파이썬 래퍼 하이퍼 파라미터
-
일반 파라미터: 일반적으로 실행 시 스레드 개수, silent 모드 등의 선택을 위한 파라미터(거의 디폴트값 그대로 사용)
- booster: gbtree, gblinear
- silent: 출력 메세지 유무(default=0, 나타냄)
- nthread: CPU의 실행 스레드 개수(default=전체 스레드)
-
부스터 파라미터: 트리 최적화, 부스팅, regularization 등
- eta: GBM의 학습률. 0~1 사이의 값을 지정하며, 부스팅 스텝을 반복적으로 수행할 때 업데이트되는 학습률 값. 보통 0.01~0.2 값을 선호.
- num_boost_rounds: GBM의 n_estimators와 동일한 기능
- gamma: 트리의 리프 노드를 추가적으로 나눌지를 결정할 최소 손실 감소 값. 해당 값보다 큰 손실이 감소된 경우에 리프 노드를 분리. 값이 클수록 과적합 감소 효과가 있음.
- max_depth: 트리 기반 알고리즘의 max_depth와 동일한 기능
- sub_sample: 트리가 커져서 과적합되는 것을 제어하기 위해 데이터를 샘플링하는 비율(GBM의 subsample과 동일한 기능)
- colsample_bytree: 트리 생성에 필요한 피처를 임의로 샘플링하여 과적합을 조정하는 데 적용. GBM의 max_feautres와 유사
- lambda: L2 Regularization
- alpha: L1 Regularization
- scale_pos_weight: 비대칭한 클래스로 구성된 데이터 세트의 균형을 유지하기 위한 파라미터
-
학습 태스크 파라미터: 학습 수행 시의 객체 함수, 평가를 위한 지표 등을 설정하는 파라미터
- objective: 최솟값을 가져야할 손실 함수
- binary:logistic: 이진분류
- multi:softmax: 다중분류
- multi:softprob: 개별 레이블 클래스의 해당되는 예측 확률 반환
- eval_metric: 검증에 사용되는 함수 정의. 회귀: rmse/ 분류: error
과적합 문제를 해결하기 위한 파라미터 튜닝
- eta 값을 낮춤+num_round 높여줌
- max_depth 값을 낮춤
- min_child_weight 값을 높임
- gamma 값을 높임
- subsample과 colsample_bytree 조정(트리가 너무 복잡하게 생성되는 것을 방지)
위스콘신 유방암 예측 1
@
사이킷런 래퍼 하이퍼 파라미터
- eta -> learning_rate
- sub_sample -> subsample
- lambda -> reg_lambda
- alpha -> reg_alpha
- num_boost_round -> b_estimators
위스콘신 유방암 예측 2
4.7 LightGBM
특징
- XGBoost 보다 학습에 걸리는 시간/메모리 사용량 적음
- 카테고리형 피처의 자동 변환과 최적 분할
- XGBoost와 예측 성능은 별다른 차이가 없음, but 적은 데이터 세트(일반적으로 10,000건)에 적용할 경우 과적합이 발생하기 쉬움
- 최근에는 GPU도 지원
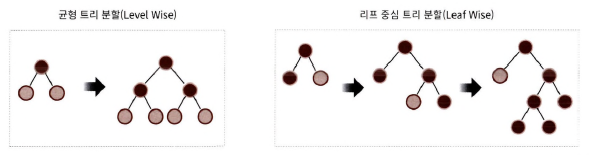
- 균형 트리 분할 방식: 오버피팅에 보다 강한 구조를 가질 수 있게 하기 위해 최대한 균형 잡힌 트리를 우지하면서 분할하기 때문에 트리의 깊이가 최소화되지만 균형을 위한 시간 필요
- 리프 중심 트리 분할 방식: 트리의 균형을 맞추지 ㅇ낳고, 최대 손실 값을 가지는 리프 노드를 지속적으로 분할하면서 트리의 깊이가 깊어지고 비대칭적인 규칙 트리 생성 (LightGBM)
하이퍼 파라미터
주요 파라미터
- num_iterations: 반복 수행하려는 트리의 개수(=n_estimators)
- learning_rate: 부스팅 스텝을 반복적으로 수행할 때 업데이트 되는 학습률 값
- max_depth: 트리 기반 알고리즘의 max_depth와 동일한 기능
- min_data_in_leaf: 최종 결정 클래스인 리프 노드가 되기 위해 최소한으로 필요한 레코드 수. 결정 트리의 min_samples_leaf(=min_child_samples)
- num_leaves: 하나의 트리가 가질 수 있는 최대 리프 개수
- boosting: 부스팅의 트리를 생성하는 알고리즘
- bagging_fraction: 트리가 커져서 과적합되는 것을 제어하기 위해서 데이터를 샘플링하는 비율
- feature_fraction: 개별 트리를 학습할 때마다 무작위로 선택하는 피처의 비율
- lambda_l2: L2 regulation 제어를 위한 값. 값이 클수록 과적합 감소 효과(=reg_lambda)
- lambda_l1: L1 regulation 제어를 위한 값(=reg_alpha)
Learning Task 파라미터
- objective: 최솟값을 가져야 할 손실함수. 회귀, 다중 클래스 분류, 이진 분류에 따라 손실함수 지정.
하이퍼 파라미터 튜닝 방향
: num_leaves의 개수를 중심으로 min_child_samples(min_data_in_leaf), max_depth를 함께 조정하면서 모델의 복잡도를 줄이는 것이 기본
- num_leaves: 개별 트리가 가질 수 있는 최대 리프의 개수로, 모델의 복잡도를 제어하는 주요 파라미터. 개수를 높이면 정확도가 높아지지만, 트리의 깊이가 깊어지고 모델이 복잡해져 과적합 가능성도 커짐
- min_data_in_leaf: 보통 큰 값으로 설정하면 트리가 깊어지는 것을 방지
- max_depth: 깊이의 크기를 제한하여 과적합을 개선하는 데 사용
파이썬 래퍼 LightGBM vs. 사이킷런 래퍼 XGBoost vs. 사이킷런 래퍼 LightGBM 비교

위스콘신 유방암 예측 3
@
4.8 캐글 산탄데르 고객 만족 예측
@
4.9 캐글 신용카드 사기 검출
@
극도로 불균형한 레이블 값 분포로 인한 문제점 해결
- 언더 샘플링: 많은 데이터 세트를 적은 데이터 세트 수준으로 감소
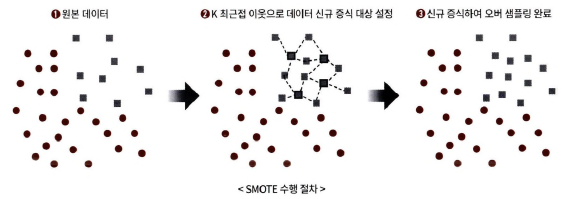
but, 너무 많은 정상 레이블 데이터를 감소시켜 제대로 된 학습을 수행할 수 없다는 단점 존재 - 오버 샘플링: 적은 데이터 세트를 증식하여 학습을 위한 충분한 데이터를 확보
동일 데이터의 증식은 과적합을 야기할 수 있어 약간 변경하여 증식
-> SMOTE: 적은 데이터 세트에 있는 개별 데이터들의 K 최근접 이웃을 찾아 이 데이터와 K개의 이웃들의 차이를 일정 값으로 만들어서 새로운 데이터를 생성하는 방식
4.10 스태킹 앙상블
: 개별 알고리즘의 예측 결과 데이터 세트를 최종적인 메타 데이터 세트로 만들어 별도의 머신러닝 알고리즘으로 최종 학습을 수행하고 테스트 데이터를 기반으로 다시 최종 예측을 수행하는 방식
** 메타모델: 개별 모델의 예측된 데이터 세트를 다시 기반으로 하여 학습, 예측하는 방식
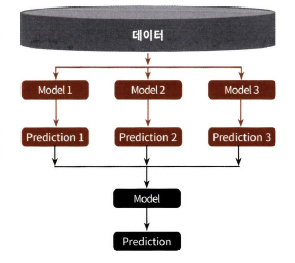
개별적인 기반 모델 + 개별 기반 모델의 예측 데이터를 학습 데이터로 만들어서 학습하는 최종 메타 모델
수행 스텝
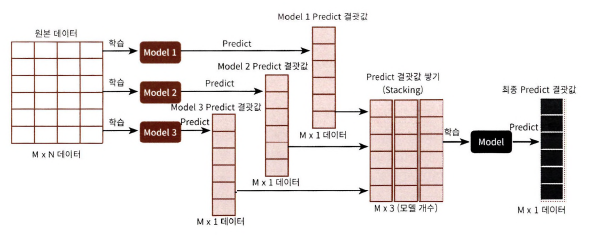
M개의 로우, N개의 피처, 3개의 ML 알고리즘 모델
: 각각 M개의 로우를 가진 1개의 레이블 값을 도출 -> 다시 합해서(스태킹) 새로운 데이터 세트 -> 최종 모델 적용 -> 최종 예측
기본 스태킹 모델
- 개별 모델: KNN, 랜덤 포레스트, 결정 트리, 에이다부스트
- 최종 모델: 로지스틱 회귀
# 개별 ML 모델을 위한 Classifier 생성
knn_clf = KNeighborsClassifier(n_neighbors=4)
rf_clf = RandomForestClassifier(n_estimators=100, random_state=0)
dt_clf = DecisionTreeClassifier()
ada_clf = AdaBoostClassifier(n_estimators=100)
# 최종 스태킹 모델을 위한 Classifier생성
lr_final = LogisticRegression(C=10)
# 개별 모델 학습
knn_clf.fit(X_train, y_train)
rf_clf.fit(X_train , y_train)
dt_clf.fit(X_train , y_train)
ada_clf.fit(X_train, y_train)
# 개별 데이터 예측
knn_pred = knn_clf.predict(X_test)
rf_pred = rf_clf.predict(X_test)
dt_pred = dt_clf.predict(X_test)
ada_pred = ada_clf.predict(X_test)
# 예측 데이터 병합
pred = np.array([knn_pred, rf_pred, dt_pred, ada_pred])
pred = np.transpose(pred)
# 최종 모델 학습 및 예측
lr_final.fit(pred, y_test)
final = lr_final.predict(pred)CV 세트 기반의 스태킹
스텝
- 각 모델 별로 원본 학습/테스트 데이터를 예측한 결과 값을 기반으로 메타 모델을 위한 학습용/테스트용 데이터 생성
- 개별 모델들이 생성한 학습용 데이터를 모두 스태킹 형태로 병합, 메타 모델이 학습할 최종 학습용 데이터 세트 생성.
Step 1
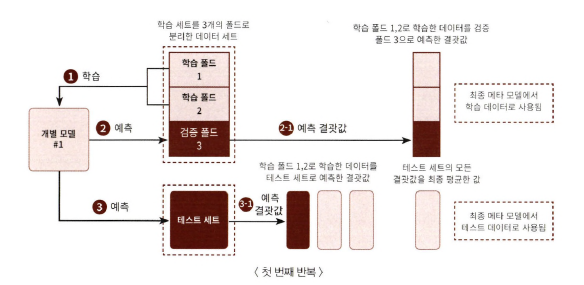
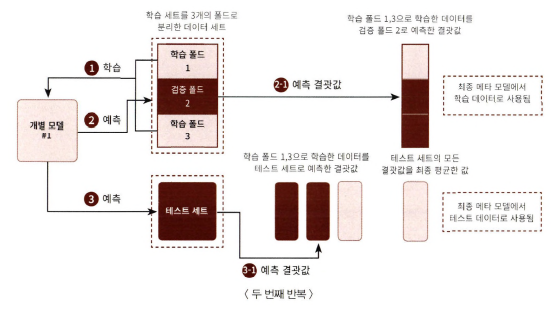
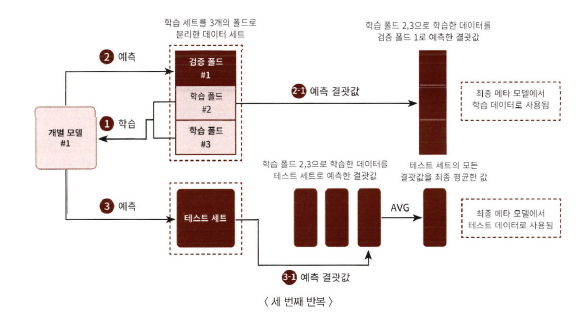
- 학습용 데이터를 N개의 폴드로 나눔. (N=3)
- 2개의 폴드는 학습을 위한 데이터 폴드 / 1개는 검증을 위한 데이터 폴드
- 2개의 폴드로 학습
- 학습된 개별 모델은 검증 폴드 1개 데이터로 예측하고 그 결과 저장
=> 3번 반복하면서 예측 결과를 별도로 저장하고 만들어진 예측 데이터를 메타 모델을 학습시키는 학습 데이터로 사용 - 학습된 개별 모델은 원본 테스트 데이터를 예측하여 예측값 생성
=> 3번 반복하면서 예측값의 평균으로 최종 결과값 생성하고, 메타 모델을 위한 테스트 데이터로 사용
=>3번째 반복에서 개별 모델의 예측값으로 학습 데이터와 테스트 데이터를 생성
Step 2
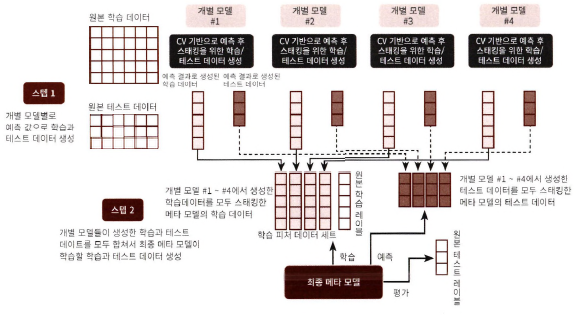
1. Step 1에서 생성한 학습/테스트 데이터를 모두 합쳐서 최종적으로 메타 모델이 사용할 학습/테스트 데이터 생성
2. 메타 모델 학습
3. 최종 테스트 데이터로 예측
4. 최종 예측 결과를 원본 테스트 데이터의 레이블과 비교, 평가
CV 세트 기반의 스태킹 실습
from sklearn.model_selection import KFold
from sklearn.metrics import mean_absolute_error
################### Step 1 ###################
# 개별 기반 모델에서 최종 메타 모델이 사용할 학습/테스트 데이터를 생성하는 함수
def get_stacking_base_datasets(model, X_train_n, y_train_n, X_test_n, n_folds):
# 지정된 n_folds값으로 KFold 생성.
kf = KFold(n_splits=n_folds, shuffle=False, random_state=0)
# 추후에 메타 모델이 사용할 학습 데이터 반환을 위한 넘파이 배열 초기화
train_fold_pred = np.zeros((X_train_n.shape[0], 1))
test_pred = np.zeros((X_test_n.shape[0],n_folds))
print(model.__class__.__name__ , 'model 시작')
for folder_counter , (train_index, valid_index) in enumerate(kf.split(X_train_n)):
# 입력된 학습 데이터에서 기반 모델이 학습/예측할 폴드 데이터 셋 추출
print('\t 폴드 세트: ',folder_counter,' 시작 ')
X_tr = X_train_n[train_index]
y_tr = y_train_n[train_index]
X_te = X_train_n[valid_index]
# 폴드 세트 내부에서 다시 만들어진 학습 데이터로 기반 모델의 학습 수행
model.fit(X_tr , y_tr)
# 폴드 세트 내부에서 다시 만들어진 검증 데이터로 기반 모델 예측 후 데이터 저장
train_fold_pred[valid_index, :] = model.predict(X_te).reshape(-1,1)
# 입력된 원본 테스트 데이터를 폴드 세트내 학습된 기반 모델에서 예측 후 데이터 저장.
test_pred[:, folder_counter] = model.predict(X_test_n)
# 폴드 세트 내에서 원본 테스트 데이터를 예측한 데이터를 평균하여 테스트 데이터로 생성
test_pred_mean = np.mean(test_pred, axis=1).reshape(-1,1)
# train_fold_pred는 최종 메타 모델이 사용하는 학습 데이터, test_pred_mean은 테스트 데이터
return train_fold_pred , test_pred_mean
# 각각 메타 모델이 추후에 사용할 학습/테스트용 데이터 세트 반환
knn_train, knn_test = get_stacking_base_datasets(knn_clf, X_train, y_train, X_test, 7)
rf_train, rf_test = get_stacking_base_datasets(rf_clf, X_train, y_train, X_test, 7)
dt_train, dt_test = get_stacking_base_datasets(dt_clf, X_train, y_train, X_test, 7)
ada_train, ada_test = get_stacking_base_datasets(ada_clf, X_train, y_train, X_test, 7)
################### Step 2 ###################
# 반환된 각 모델별 학습/테스트용 데이터 병합
# 메타 모델이 학습할 학습용 피처 데이터 세트
Stack_final_X_train = np.concatenate((knn_train, rf_train, dt_train, ada_train), axis=1)
# 메타 모델이 예측할 테스트용 피처 데이터 세트
Stack_final_X_test = np.concatenate((knn_test, rf_test, dt_test, ada_test), axis=1)
# 최종 메타 모델을 스태킹된 학습용 피처 데이터 세트와 원본 학습 레이블 데이터로 학습
lr_final.fit(Stack_final_X_train, y_train)
# 스태킹된 테스트 데이터 세트로 예측
stack_final = lr_final.predict(Stack_final_X_test)
print('최종 메타 모델의 예측 정확도: {0:.4f}'.format(accuracy_score(y_test, stack_final)))
# 정확도: 0.9737** 스태킹을 이루는 모델은 최적으로 파라미터를 튜닝한 상태에서 스태킹 모델을 만드는 것이 일반적
