
7.1 K-평균 알고리즘 이해
: 군집 중심점(centroid)이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법
군집 생성 과정
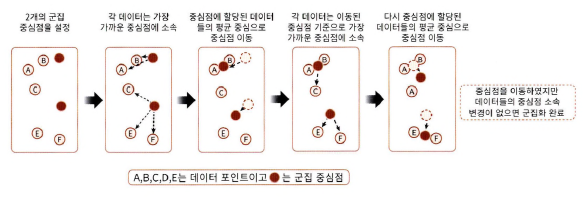
Step 1: 군집화의 기준이 되는 중심을 구성하려는 군집 개수만큼 정함
Step 2: 각 데이터는 가장 가까운 곳에 위치한 중심점에 속함
Step 3: 소속이 결정되면 군집 중심점을 소속된 데이터의 평균 중심으로 이동함
Step 4: 기존에 속한 중심점보다 더 가까운 중심점이 있다면 해당 중심점으로 다시 소속 변경
Step 5: 다시 중심을 소속된 데이터의 평균 중심으로 이동
Step 6: 위 프로세스를 반복, 데이터의 중심점 변경이 없으면 반복 중단 및 군집화 종료
장점
- 일반적인 군집화에서 가장 많이 활용
- 알고리즘이 쉽고 간결
단점
- 거리 기반 알고리즘이기 때문에 속성의 개수가 매우 많을 경우 군집화 정확도가 감소(PCA 차원 축소가 필요할 수 있음)
- 반복 수행 횟수가 많아지면 수행 시간이 증가
- 몇 개의 군집을 선택해야할지 가이드가 어려움
KMeans()
파라미터
- n_clusters: 군집 개수=군집 중심점의 개수
- init: 초기에 군집 중심점의 좌표를 설정할 방식. 일반적으로는 k-means++ 방식으로 최초 설정함
- max_iter: 최대 반복 횟수
속성
- labels_: 각 데이터 포인트가 속한 군집 중심점 레이블
- cluster_centers: 각 군집 중심점 좌표([군집 개수, 피처 개수]), 군집 중심점 시각화 가능
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=300,random_state=0)
kmeans.fit(irisDF)
print(kmeans.labels_) # 0, 1, 2로 표현됨
# 타겟값과 군집화된 레이블 분포
irisDF['target'] = iris.target
irisDF['cluster']=kmeans.labels_
iris_result = irisDF.groupby(['target','cluster'])['sepal_length'].count()
print(iris_result) # target 0 데이터는 잘 그루핑되었으나, target 1, 2에서는 두 가지 레이블로 분산되어 그루핑됨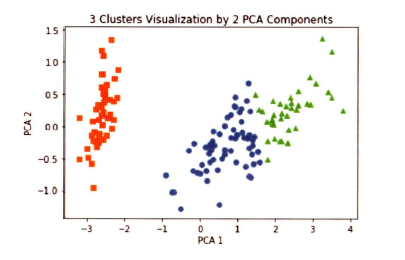
동그라미와 세모는 명확하게 구분되어 있지 않음
군집화 알고리즘 테스트를 위한 데이터 생성
make_blobs()
: 개별 군집의 중심점과 표준 편차 제어 기능이 추가되어 있음
파라미터
- n_samples: 생성할 총 데이터 개수(default=100)
- n_features: 데이터의 피처 개수(시각화가 목표면 2개로 설정)
- centers: int로 설정하면 군집의 개수, ndarray로 설정하면 개별 군집 중심점의 좌표
- cluster_std: 생성될 군집 데이터의 표준 편차(0.8이면 데이터의 표준편차가 0.8, [0.8, 0.6]이면 첫 번째 군집과 두 번째 군집의 표준편차가 각각 0.8, 0.6). 이 파라미터로 데이터의 분포도 조절.
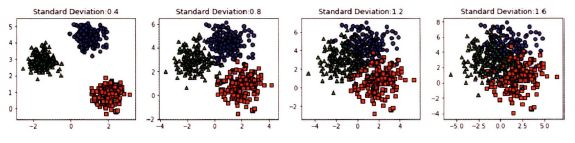
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=200, n_features=2, centers=3, cluster_std=0.8, random_state=0)
# KMeans 객체를 이용하여 X 데이터를 K-Means 클러스터링 수행
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=200, random_state=0)
cluster_labels = kmeans.fit_predict(X)make_classification()
: noise를 포함한 데이터를 만드는 데 유용
make_circle(), make_moon()
: 중심 기반 군집화로 해결하기 어려운 데이터 세트를 만드는 데 사용
7.2군집 평가
군집화
- 데이터 내에 숨어 있는 별도의 그룹을 찾아서 의미 부여
- 동일한 분류 값에 속하더라도 그 안에서 더 세분화된 군집화 추구
- 서로 다른 분류 값의 데이터도 더 넓은 군집화 레벨화
실루엣 분석
: 각 군집 간의 거리가 얼마나 효율적으로 분리되어 있는지 나타내는 군집화 평가 방법(효율적=다른 군집과는 떨어져 있고, 동일 군집끼리는 가깝게 뭉쳐 있다)
- 직관적으로 이해 쉬움
- 데이터 별로 다른 데이터와의 거리를 반복적으로 계산해야 하기 때문에 데이터 양이 늘어나면 수행 시간 크게 증가 + 메모리 부족 에러 -> 군집별로 임의의 데이터를 샘플링해 계수 평가
실루엣 계수(silhouette coefficient)
: 개별 데이터가 가지는 군집화 지표. 해당 데이터가 같은 군집 내의 데이터와 얼마나 가깝게 군집화되어 있고, 다른 군집에 있는 데이터와는 얼마나 멀리 분리되어있는지를 나타내는 지표
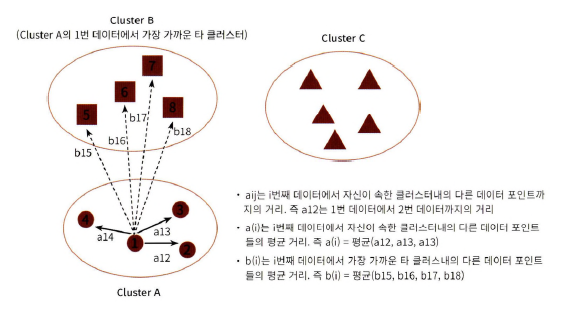
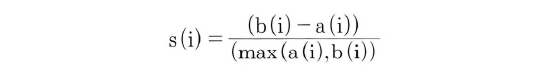
- a(i): 해당 데이터 포인트와 같은 군집 내에 있는 다른 데이터 포인트와의 거리의 평균
- b(i): 해당 데이터 포인트가 속하지 않은 군집 중 가장 가까운 군집과의 평균 거리
- 실루엣 계수 s(i): 두 군집 간의 거리가 얼마나 떨어져 있는지를 Max(a(i), b(i))로 나누어 정규화한 값.
-> -1~1 사이 값. 1에 가까울수록 근처의 군집과 멀다는 것, 0에 가까울수록 가깝다는 것, -는 다른 군집에 데이터 포인트가 할당되었다는 것
- sklearn.metrics.silhouette_samples(X, labels, metric='euclidean', **kwds): 각 데이터 포인트의 실루엣 계수 계산
- sklearn.metrics.silhouette_score(X, labels, metric='euclidean', sample_size=None, **kwds): 전체 데이터의 실루엣 계수 값의 평균 계산
좋은 군집화의 조건
- 전체 실루엣 계수의 평균값(silhouette_score())이 0~1 사이 값을 가지며, 1에 가까움
- 개별 군집의 평균값의 편차가 크지 않음(개별 군집의 실수엣 계수 평균값이 전체 실루엣 계수의 평균값에서 크게 벗어나지 않음)
from sklearn.metrics import silhouette_samples, silhouette_score
# iris 의 모든 개별 데이터에 실루엣 계수값을 구함.
score_samples = silhouette_samples(iris.data, irisDF['cluster'])
# irisDF에 실루엣 계수 컬럼 추가
irisDF['silhouette_coeff'] = score_samples
# 모든 데이터의 평균 실루엣 계수값을 구함.
average_score = silhouette_score(iris.data, irisDF['cluster'])
# 군집별 실루엣 계수 평균
irisDF.groupby('cluster')['silhouette_coeff'].mean()군집별 평균 실루엣 계수의 시각화를 통한 군집 개수 최적화
평균 실루엣 계수 값이 높다고 해서 반드시 최적의 군집 개수로 군집화가 잘 되었다고 볼 수는 없음(특정 군집 내의 실루엣 계수만 높을 수 있기 때문)
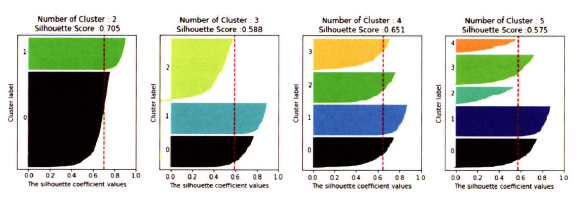
- X축: 실루엣 계수 값
Y축: 개별 군집과 이에 속하는 데이터(높이로 추측) - 점선: 전체 실루엣 계수 평균
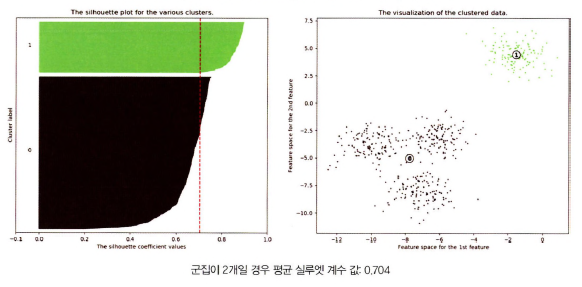
- 군집 계수 = 2 (평균 실루엣 계수: 0.704)
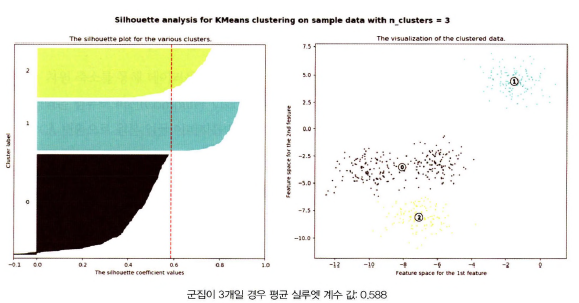
- 1번 군집은 모두 평균 실루엣 계수 값 이상, 내부 데이터끼리 잘 밀집되어있고 0번과 멀리 떨어져있음
- 0번 군집은 내부 데이터끼리 많이 떨어져있음
- 군집 계수 = 3 (평균 실루엣 계수: 0.588)
- 1번, 2번 군집은 평균보다 높은 실루엣 계수를 가짐
- 0번은 내부 데이터 간의 거리가 여전히 멀고 2번 군집과 가깝게 위치하여 평균보다 낮은 실루엣 계수를 가짐
- 군집 계수= 4 (평균 실루엣 계수: 0.65)
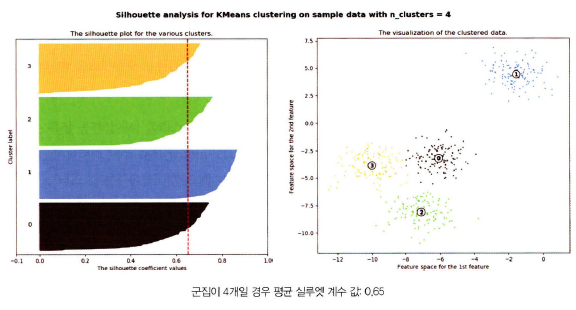
- 개별 군집의 평균 실루엣 계수 값이 비교적 균일
- 1번 군집은 모든 데이터가 평균보다 높은 실루엣 계수를 가짐
- 0번, 2번 군집은 절반 이상이 평균보다 높은 실루엣 계수를 가짐
- 3번 군집은 1/3 정도가 평균보다 높은 실루엣 계수를 가짐
=> 가장 이상적

Data Analyst | Statistics