
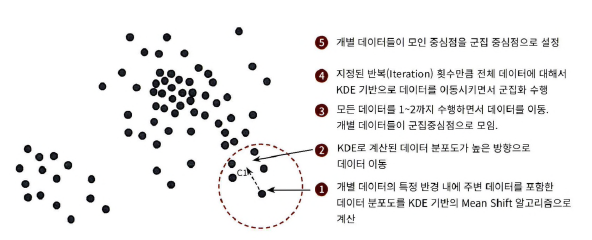
7.3 평균 이동
: 중심을 군집의 중심(데이터가 모여 있는 밀도가 가장 높은 곳)으로 지속적으로 움직이면서 군집화 수행.
- 군집 중심점이 데이터 포인트가 모여있는 곳이라는 생각에서 착안
- 확률 밀도 함수 이용(KDE 이용)
과정
주변 데이터와의 거리 값을 KDE 함수 값으로 입력한 뒤 그 반환 값을 현재 위치에서 업데이트하면서 이동
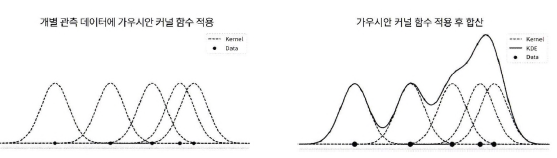
KDE(Kernel Density Estimation)
: 함수를 통해 어떤 변수의 확률 밀도 함수를 추정하는 대표적인 방법
- 관측된 데이터 각각에 커널 함수를 적용한 값을 모두 더한 뒤 데이터 건수로 나누어 확률 밀도 함수 추정
- 확률 밀도 함수(PDF): 확률 변수의 분포를 나타내는 함수 ex. 감마, 정규, t분포 등
- 대표적인 커널 함수로 가우시안 분포 함수 사용
KDE 함수식
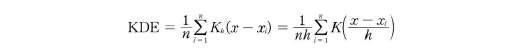
- K: 커널 함수, x: 확률 변숫값, xi: 관측값, h: 대역폭(bandwidth)
- 대역폭: KDE 형태를 부드러운(또는 뾰족한) 형태로 평활화하는 데 적용. 이를 어떻게 설정하느냐에 따라 확률 밀도 추정 성능 크게 좌우
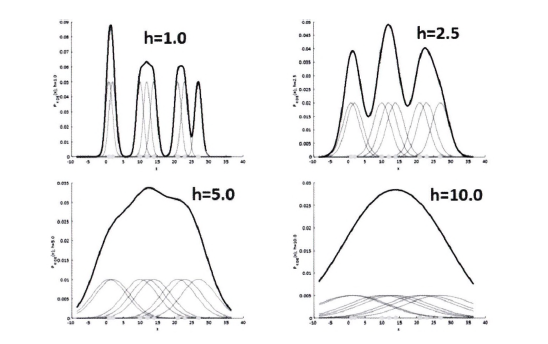
- h = 작은 값: 좁고 뾰족한 KDE. 변동성이 큰 방식으로 확률 밀도 함수 추정. 과적합 쉬움
- h = 큰 값: 과도하게 평활화된 KDE로 인해 지나치게 단순화된 방식으로 확률 밀도 함수 추정. 과소적합 쉬움
- h가 클수록 적은 수의 군집 중심점을 가짐
- 오직 대역폭의 크기에 따라 군집화 수행(군집의 개수를 지정x)
estimate_bandwidth()
from sklearn.datasets import make_blobs
from sklearn.cluster import MeanShift
# 데이터 생성
X, y = make_blobs(n_samples=200, n_features=2, centers=3,
cluster_std=0.7, random_state=0)
# bandwidth 최적화 값 찾기
from sklearn.cluster import estimate_bandwidth
best_bandwidth = estimate_bandwidth(X)
print('bandwidth 값:', round(bandwidth,3))
# 평균 이동을 통한 군집화
meanshift = MeanShift(bandwidth=best_bandwidth)
cluster_labels = meanshift.fit_predict(X)
print('cluster labels 유형:', np.unique(cluster_labels))
# 레이블 값 비교
print(clusterDF.groupby('target')['meanshift_label'].value_counts())장점과 단점
장점
- 데이터 세트의 형태 가정, 특정 분포도 기반의 모델 가정 필요 없음
- 유연한 군집화 가능
- 이상치의 영향력이 크지 않음
- 미리 군집의 개수를 정하지 않음
단점
- 수행 시간이 오래 걸림
- bandwidth의 크기에 따른 군집화 영향이 매우 큼
=> 분석 업무 기반의 데이터 세트보다는 컴퓨터 비전 영역에서 많이 사용. 이미지나 영상 데이터에서 특정 개체를 구분하거나 움직임을 추적하는 데 뛰어난 역할.
7.4 GMM(Gaussian Mixture Model)
GMM 소개
GMM 군집화: 군집화를 적용하고자 하는 데이터가 여러 개의 가우시안 분포(정규분포)를 가진 데이터 집합들이 섞여서 생성된 것이라는 가정 하에 군집화를 수행하는 방식
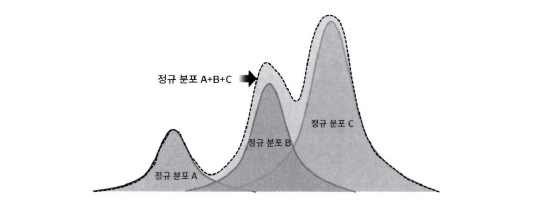
데이터 세트를 구성하는 여러 개의 정규 분포 곡선을 추출하고 개별 데이터가 이 중 어느 정규 분포에 속하는지 결정함 => 모수 추정
모수 추정
- 개별 정규 분포의 평균과 분산 추정
- 각 데이터가 어떤 정규 분포에 해당되는지의 확률 추정
- EM(Expectation and Maximization) 방법 적용
GaussianMixture()
- n_components: gaussian mixture 모델의 총 개수 => 군집의 개수를 정하는 데 중요한 역할
from sklearn.mixture import GaussianMixture
# gmm으로 군집화
gmm = GaussianMixture(n_components=3, random_state=0).fit(iris.data)
gmm_cluster_labels = gmm.predict(iris.data)
# 클러스터링 결과 저장
irisDF['gmm_cluster'] = gmm_cluster_labels
irisDF['target'] = iris.target
# target 값에 따라서 gmm_cluster 값이 어떻게 매핑되었는지 확인
iris_result = irisDF.groupby(['target'])['gmm_cluster'].value_counts()
print(iris_result)GMM과 K-평균의 비교
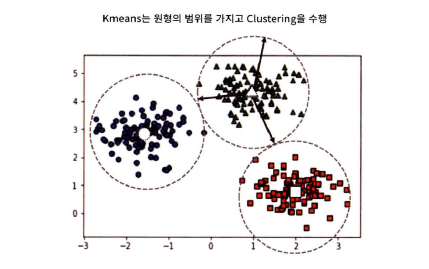
K-means
- 평균 거리 기반으로 군집화
- 원형의 범위에서 군집화 수행(데이터 세트가 원형의 범위를 가질수록 군집화 효율 증가)
GMM
- 보다 유연하게 다양한 데이터 세트에 적용
군집화 시각화 참고 코드
# 클러스터 결과를 담은 DataFrame과 사이킷런의 Cluster 객체등을 인자로 받아 클러스터링 결과를 시각화하는 함수
def visualize_cluster_plot(clusterobj, dataframe, label_name, iscenter=True):
if iscenter :
centers = clusterobj.cluster_centers_
# 레이블 값 및 군집 표시 기호 설정
unique_labels = np.unique(dataframe[label_name].values)
markers=['o', 's', '^', 'x', '*']
isNoise=False
for label in unique_labels:
label_cluster = dataframe[dataframe[label_name]==label]
if label == -1:
cluster_legend = 'Noise'
isNoise=True
else :
cluster_legend = 'Cluster '+str(label)
plt.scatter(x=label_cluster['ftr1'], y=label_cluster['ftr2'], s=70,\
edgecolor='k', marker=markers[label], label=cluster_legend)
if iscenter:
center_x_y = centers[label]
plt.scatter(x=center_x_y[0], y=center_x_y[1], s=250, color='white',
alpha=0.9, edgecolor='k', marker=markers[label])
plt.scatter(x=center_x_y[0], y=center_x_y[1], s=70, color='k',\
edgecolor='k', marker='$%d$' % label)
if isNoise:
legend_loc='upper center'
else: legend_loc='upper right'
plt.legend(loc=legend_loc)
plt.show()7.5 DBSCAN
: 특정 공간 내에 데이터 밀도 차이에 기반한 알고리즘으로 군집화 수행
- 복잡한 기하학적 분포도를 가진 데이터 세트에 대해서 군집화를 잘 수행
파라미터
- 입실론 주변 영역(epsilon): 개별 데이터를 중심으로 입실론 반경을 가지는 원형의 영역
- 최소 데이터 개수(min points): 개별 데이터의 입실론 주변 영역에 포함되는 타 데이터의 개수
데이터 포인트
- 핵심 포인트(Core Point): 주변 영역 내에 최소 데이터 개수 이사으이 타 데이터를 가지고 있을 경우
- 이웃 포인트(Neighbor Point): 주변 영역 내에 위치한 타 데이터
- 경계 포인트(Border Point): 주변 영역 내에 최소 데이터 개수 이상의 이웃 포인트를 가지고 있지 않지만, 핵심 포인트를 이웃 포인트로 가지고 있는 데이터(P3, P4, P6, P7, P8, P11, P9, P10)
- 잡음 포인트(Noise Point): 최소 데이터 개수 이상의 이웃 포인트를 가지고 있지 않으며, 핵심 포인트도 이웃 포인트로 가지고 있지 않는 데이터 (P5)
과정
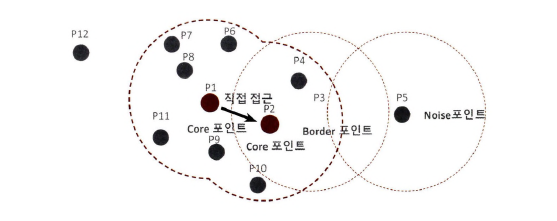
최소 데이터 세트를 5개로 가정
Step 1: P1을 기준으로 이웃 포인트가 6개 이므로 P1은 핵심 포인트
Step 2: P2를 기준으로 이웃 포인트 5개이므로 P2는 핵심 포인트
Step 3: P1의 이웃 포인트 P2가 핵심 포인트이므로 직접 접근 가능
Step 4: P1에서 직접 접근이 가능한 P2를 서로 연결하여 군집화 구성
Step 5: 위 과정을 반복하여 점차적으로 군집 영역 확장
DBSCAN()
- 일반적으로 eps <= 1, eps가 증가하면 noise 줄어듦
- 특정 군집 개수로 군집을 강제하지 말고, 파라미터를 통해 최적의 군집을 찾는 것이 중요
from sklearn.cluster import DBSCAN
# 주변 영역 반경 = 0.6, 최소 데이터 개수 = 8
dbscan = DBSCAN(eps=0.6, min_samples=8, metric='euclidean')
dbscan_labels = dbscan.fit_predict(iris.data)
# 군집화된 레이블 값 저장
irisDF['dbscan_cluster'] = dbscan_labels
irisDF['target'] = iris.target
# 예측 비교
iris_result = irisDF.groupby(['target'])['dbscan_cluster'].value_counts()
print(iris_result)
- -1에 속하는 군집은 noise
- 0, 1 두 개의 군집으로 군집화됨
make_circles() 데이터 세트
from sklearn.datasets import make_circles
X, y = make_circles(n_samples=1000, shuffle=True, noise=0.05, random_state=0, factor=0.5)
clusterDF = pd.DataFrame(data=X, columns=['ftr1', 'ftr2'])
clusterDF['target'] = y
visualize_cluster_plot(None, clusterDF, 'target', iscenter=False)-
데이터 형태
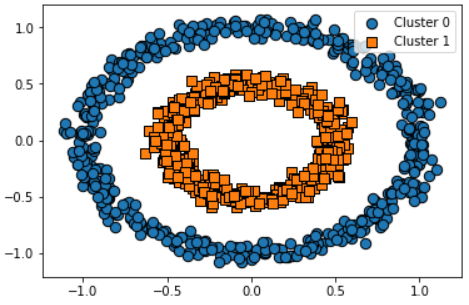
-
(좌) KMeans / (우) GaussianMixture
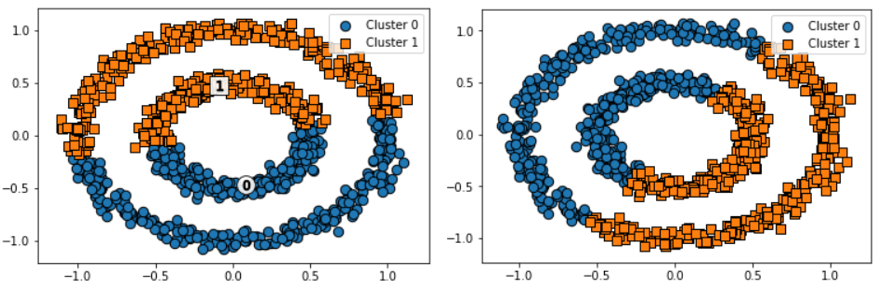
-
DBSCAN
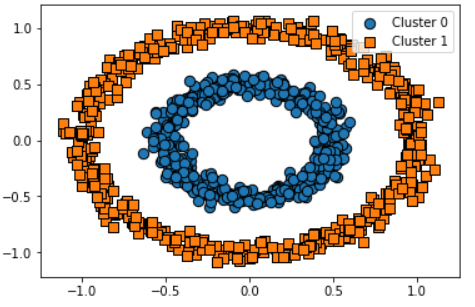
DBSCAN은 정확히 군집화 됨
7.6 고객 세그먼테이션
고객 세그먼테이션의 정의와 기법
정의
: 다양한 기준으로 고객을 분류하는 기법
- 어떤 상품을 얼마나 많은 비용을 써서 얼마나 자주 사용하는가에 기반한 정보로 분류하는 것이 중요
- 주요 목표: 타깃 마케팅
- 타깃 마케팅: 고객을 여러 특성에 맞게 세분화해서 그 유형에 따라 맞춤형 마케팅이나 서비스 세공
RFM 기법
- RECENCY: 가장 최근 상품 구입 일에서 오늘까지의 기간
- FREQUENCY: 상품 구매 횟수
- MONETARY VALUE: 총 구매 금액
고객 세그먼테이션 실습
@
