
9.1 추천 시스템의 개요와 배경
- 추천 시스템의 묘미: 사용자 자신도 좋아하는지 몰랐던 취향을 시스템이 발견하고 그에 맞는 콘텐츠를 추천해주는 것
- 유형
- 콘텐츠 기반 필터링
- 협업 필터링
- 최근접 이웃
- 잠재 요인
9.2 콘텐츠 기반 필터링 추천 시스템
: 사용자가 특정한 아이템을 매우 선호하는 경우, 그 아이템과 비슷한 콘텐츠를 가진 다른 아이템을 추천하는 방식
ex. 영화의 장르, 감독, 출연 배우, 키워드 등의 콘텐츠 고려하여 유사한 영화 추천
9.3 최근접 이웃 협업 필터링
: 사용자가 아이템에 매긴 평점 정보나 상품 구매 이력과 같은 사용자 행동 양식만을 기반으로 추천 수행
사용자-아이템 평점 행렬
- 행: 개별 사용자
- 열: 개별 아이템
- 값: 평점
- 희소 행렬의 특성을 가짐
사용자 기반
: '당신과 비슷한' 고객들이 다음 상품도 구매했습니다.
- 특정 사용자와 유사한 다른 사용자를 Top-n으로 선정해 이 사용자들이 좋아하는 아이템 추천
- ex.
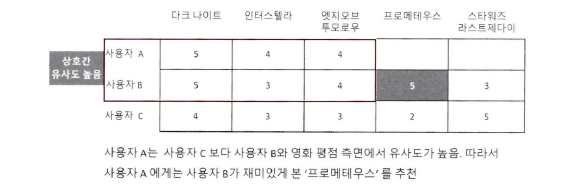
사용자 A는 B와 평점 정보가 비슷하므로 상호 간 유사도가 높다고 할 수 있음.
=> 따라서 B 사용자가 더 재미있게 관람한 프로메테우스 추천
아이템 기반
: '이 상품을 선택한' 다른 고객들은 다음 상품도 구매했습니다.
- 아이템이 가지는 속성과는 상관없이 사용자들의 평가 척도가 유사한 아이템을 추천하는 기준이 되는 알고리즘
- ex.
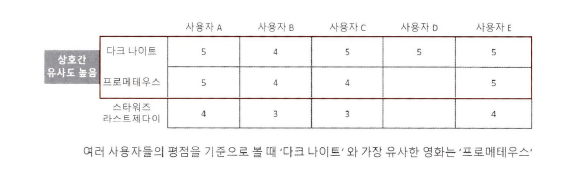
다크 나이트와 프로메테우스의 상호 간 유사도가 높음
=> 따라서 사용자 D에게 스타워즈보다는 프로메테우스 추천 - 아이템 기반 협업 필터링이 정확도가 더 높음
- 비슷한 영화를 구입/좋아한다고해서 사람들의 취향이 비슷하다고 판단하기 어렵기 때문
- 취향과 관계없이 유명한 영화는 대부분의 사람이 관람
- 사용자들이 평점을 매긴 영화의 개수가 많지 않음
- 비슷한 영화를 구입/좋아한다고해서 사람들의 취향이 비슷하다고 판단하기 어렵기 때문
유사도 측정
: 코사인 유사도 이용
9.4 잠재 요인 협업 필터링
: 사용자-아이템 평점 매트릭스 속에 숨어있는 잠재 요인을 추출해 추천 예측을 할 수 있게 하는 기법
- 잠재요인이 어떤 것인지는 명확히 정의 불가능
행렬 분해
: 대규모 다차원 행렬을 SVD와 같은 차원 감소 기법으로 분해하는 과정에서 잠재 요인 추출
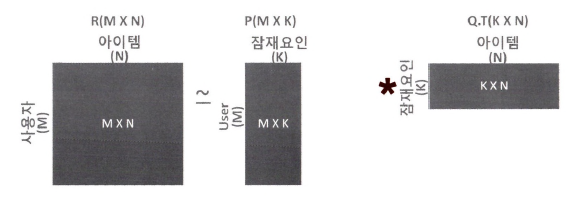
- M: 총 사용자 수
- N: 총 아이템 수
- K: 잠재 요인의 차원 수
- R: M x N 차원의 사용자-아이템 평점 행렬
- P: M x K 차원의 사용자-잠재 요인 행렬
- Q: N x K 차원의 아이템-잠재 요인 행렬
확률적 경사 하강법을 이용한 행렬 분해
: P와 Q 행렬로 계산된 예측 R 행렬 ㄱ밧이 실제 R 행렬 값과 가장 최소의 오류를 가질 수 있도록 반복적인 비용 함수 최적화를 통해 P와 Q를 유추하는 것
- Null 값이 있는 행렬도 행렬 분해 가능
- 과정
- Step 1: P, Q를 임의의 값을 가진 행렬로 설정
- Step 2: 예측 행렬 계산, 예측 행렬과 실제 행렬에 해당하는 오류 값 계산
- Step 3: 오류 값을 최소화할 수 있도록 P, Q 행렬을 적절한 값으로 업데이트
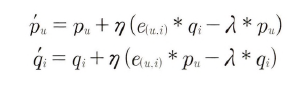
- Step 4: 반복, 근사화
- 비용 함수식
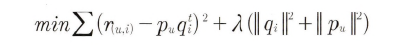
R = ##행렬
num_users, num_items = R.shape
K=3
# P와 Q 크기를 지정, 정규분포를 가진 random한 값
np.random.seed(1)
P = np.random.normal(scale=1./K, size=(num_users, K))
Q = np.random.normal(scale=1./K, size=(num_items, K))
# R > 0 인 행 위치, 열 위치, 값을 non_zeros 리스트에 저장
non_zeros = [ (i, j, R[i,j]) for i in range(num_users) for j in range(num_items) if R[i,j] > 0 ]
steps=1000 # SGD 업데이트 횟수
learning_rate=0.01 # 학습률
r_lambda=0.01 # L2 regularization 계수
# SGD 기법으로 P와 Q 행렬 업데이트
for step in range(steps):
for i, j, r in non_zeros:
# 실제 값과 예측 값의 차이인 오류 값
eij = r - np.dot(P[i, :], Q[j, :].T)
# Regularization을 반영한 SGD 업데이트 공식 적용
P[i,:] = P[i,:] + learning_rate*(eij * Q[j, :] - r_lambda*P[i,:])
Q[j,:] = Q[j,:] + learning_rate*(eij * P[i, :] - r_lambda*Q[j,:])
rmse = get_rmse(R, P, Q, non_zeros)
if (step % 50) == 0 :
print("### iteration step : ", step," rmse : ", rmse)
# 예측 행렬
pred_matrix = np.dot(P, Q.T)
print('예측 행렬:\n', np.round(pred_matrix, 3))ex. 영화 데이터
사용자-아이템 행렬 데이터 = (사용자-잠재 요인 행렬) * (잠재 요인-아이템 행렬)
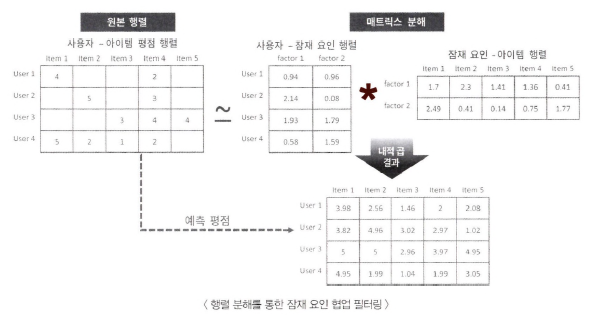
- 잠재 요인: 영화가 가지는 장르별 특성 선호도
- 사용자-잠재 요인 행렬: 사용자의 영화 장르에 대한 선호도
- 아이템-잠재 요인 행렬: 영화의 장르별 특성값
- 행렬 분해로 평점 예측 가능

9.5 TMDB 5000 영화 데이터(콘텐츠 기반 필터링)
: 영화 장르 속성을 기반으로 추천 시스템 생성(장르 칼럼 값의 유사도를 비교한 뒤, 그 중 높은 평점을 가지는 영화 추천)
장르 콘텐츠 유사도 측정
Step 1: 문자열로 변환된 장르 칼럼을 count 기반 피처 벡터화 변환
Step 2: 피처 벡터화한 데이터 세트를 코사인 유사도를 통해 비교
Step 3: 장르 유사도가 높은 영화 중에 평점이 높은 순으로 영화 추천
@
9.6 MovieLens 데이터(아이템 기반 최근접 이웃 협업 필터링)
@
9.7 MovieLens 데이터(행렬 분해를 이용한 잠재 요인 협업 필터링)
@
9.8 Surprise 패키지
- 다양한 추천 알고리즘 기반의 추천 시스템 구축 가능
- 핵심 API가 사이킷런의 핵심 API와 유사한 API 명으로 작성됨
# 모듈 임포트
from surprise import SVD
from surprise import Dataset
from surprise import accuracy
from surprise.model_selection import train_test_split
# 데이터 로드
data = Dataset.load_builtin('ml-100k')
# train/test 데이터 분리
trainset, testset = train_test_split(data, test_size=.25, random_state=0)
algo = SVD()
algo.fit(trainset)
# 개별 사용자와 영화에 대한 추천 예측 평점 반환
predictions = algo.test(testset)
print('prediction type :',type(predictions), ' size:',len(predictions))
print('prediction 결과의 최초 5개 추출')
predictions[:5]
# prediction 객체에서 uid, iid, est 속성 추출
[(pred.uid, pred.iid, pred.est) for pred in predictions[:3]]
accuracy.rmse(predictions)@

Data Analyst | Statistics