
텍스트 분석
- 텍스트 분류: 문서가 특정 분류 또는 카테고리에 속하는 것을 예측하는 기법. 지도학습.
- 감성 분석: 텍스트에서 나타나는 주관적인 요소를 분석하는 기법. 지도학습+비지도학습
- 텍스트 요약: 텍스트 내에서 중요한 주제나 중심 사상을 추출하는 기법. ex. 토픽 모델링
- 텍스트 군집화와 유사도 측정: 비슷한 유형의 문서에 대해 군집화 수행하는 기법/문서들 간의 유사도를 측정해 비슷한 문서끼리 모을 수 있는 방법
8.1 텍스트 분석의 이해
: 비정형 데이터인 텍스트를 분석하는 것
- 피처 벡터화(피처 추출): 텍스트를 단어 기반의 다수의 피처로 추출하고 이 피처에 단어 빈도수와 같은 숫자 값을 부여하여 텍스트를 단어의 조합인 벡터값으로 변환하는 것
- BoW, Word2Vec 방법
수행 과정
Step 1: 텍스트 전처리: 클렌징, 대/소문자 변경, 특수문자 삭제 등, 단어의 토큰화 작업, 불용어(의미 없는 단어) 제거 작업, 어근 추출 등 정규화 작업
Step 2: 피처 벡터화 및 추출: 전처리가 된 텍스트에서 피처를 추출하고 벡터 값 할당. BoW(Count 기반, TF-IDF 기반), Word2Vec 방법 존재
Step 3: 머신러닝 모델 수립 및 학습/예측/평가
패키지
- NLTK
- Gensim
- SpaCy
8.2 텍스트 전처리 - 텍스트 정규화
텍스트 정규화
: 클렌징, 정제, 토큰화, 어근화 등의 다양한 텍스트 전처리를 수행하는 것
클렌징(Cleansing)
: 불필요한 문자, 기호 등을 사전에 제거하는 작업. ex. HTML, XML 태그나 특정 기호
토큰화(Tokenization)
: 문장 토큰화(문장을 분리), 단어 토큰화(단어를 토큰으로 분리)
-
문장 토큰화
: 문장의 마침표, 개행문자 등 문장의 마지막을 뜻하는 기호 또는 정규 표현식에 따라 분리- sent_tokenize()
-
단어 토큰화
: 공백, 콤마, 마침표, 개행문자 또는 정규 표현식 등으로 단어 분리- BoW 같이 단어의 순서가 중요하지 않은 경우 문장 토큰화를 사용하지 않고 단어 토큰화만 사용해도 충분
- word_tokenize()
from nltk import word_tokenize, sent_tokenize
# 문서의 문장 별로 단어 토큰화 만드는 함수 생성
def tokenize_text(text):
# 문장 토큰화
sentences = sent_tokenize(text)
# 분리된 문장 별 단어 토큰화
word_tokens = [word_tokenize(sentence) for sentence in sentences]
return word_tokens
#여러 문장들에 대해 문장별 단어 토큰화 수행
word_tokens = tokenize_text(text_sample)
print(type(word_tokens),len(word_tokens))
print(word_tokens)- 문장을 단어 별로 하나씩 토큰화할 경우 문맥적인 의미 무시 => n-gram을 통해서 해결
: 연속된 n개의 단어를 하나의 토큰화 단위로 분리
ex. 2-gram: I like dogs and cats -> (I, like), (like, dogs), (dogs, and), (and, cats)
불용어(=stop word) 제거
: 문장을 구성하는 필수 문법 요소지만 문맥적으로 큰 의미가 없는 단어
- 문법적인 특성으로 인해 빈번하게 등장하여 중요 단어로 인식될 수 있음 -> 제거 필요
import nltk
# 영어 불용어 사전
stopwords = nltk.corpus.stopwords.words('english')
all_tokens = []
# word_tokens list 에 대해 stop word 제거
for sentence in word_tokens:
filtered_words=[]
# 개별 문장별로 tokenize된 sentence list에 대해 stop word 제거
for word in sentence:
#소문자 변환
word = word.lower()
if word not in stopwords:
filtered_words.append(word)
all_tokens.append(filtered_words)
print(all_tokens)Stemming과 Lemmatization
: 문법적 또는 의미적으로 변화하는 단어의 원형을 찾는 것(시제, 3인칭 단수 여부 등)
- Lemmatization: 문법적인 요소(품사)와 의미론적 기반에서 단어의 원형 추출(더 정교)
- NLTK.WordNetLemmatizer: 단어와 품사 입력해줘야 함
- Stemming: 일반적인 방법, 단순화된 방법을 적용해 일부 철자가 훼손된 어근 단어를 추출
- NLTK.LancasterStemmer, Porter, snowball
8.3 Bow(Bag of Words)
: 문서가 가지는 모든 단어를 문맥이나 순서를 무시하고 일괄적으로 단어에 대해 빈도 값을 부여해 피처 값을 추출하는 모델
장단점
장점
- 쉽고 빠른 구축
- 단어의 발생 횟수에 기반하고 있지만 예상보다 문서의 특징을 잘 나타낼 수 있는 모델
단점
- 문맥 의미 반영 부족: 순서를 고려하지 않기 때문. 보완하기 위해 n-gram 기법 활용할 수 있지만 제한적.
- 희소 행렬 문제: 매우 많은 단어가 칼럼으로 만들어져 대부분의 데이터가 0으로 채워짐 -> 성능 감소
- 희소 행렬: 행렬에서 대부분의 값이 0으로 채워지는 행렬
- 밀집 행렬: 대부분의 값이 0이 아닌 의미 있는 값으로 채워지는 행렬
피처 벡터화
: 텍스트를 특정 의미를 가지는 숫자형 값인 벡터 값으로 변환하는 것
- 모든 문서에서 모든 단어를 칼럼 형태로 나열
- 각 문서에서 해당 단어의 횟수나 정규화된 빈도 값으로 부여하는 데이터 세트 모델로 변경

카운트 기반의 벡터화
: 각 문서에서 해당 단어가 나타나는 횟수(count)를 부여하는 경우
- 카운트 값이 높을수록 중요한 단어
- 자주 사용되는 단어까지 높은 값 부여(is, the 등)
TF-IDF
: 개별 문서에서 자주 나타나는 단어에 높은 가중치를 주되, 모든 문서에서 전반적으로 자주 나타나는 단어에 대해서는 페털티 적용하여 값을 부여
- ex. '분쟁', '종교 대립' 자주 사용됨 -> 지역 분쟁과 관련된 문서 -> 가중치 부여
- ex. '많은', '당연히', '업무' -> 보편적으로 많이 사용되어 문서의 특징과 관련있다고 보기 어려움 -> 패털티 부여
- 카운트 기반의 벡터화 보완
CountVectorizer, TfidfVectorizer
피처 벡터화 과정
Step 1: 영어의 경우 모든 무자를 소문자로 변경
Step 2: n-gram-range를 반영하여 각 단어 토큰화
Step 3: 텍스트 정규화(불용어 필터링만 수행)
Step 4: 토큰화된 단어를 피처로 추출, 단어 빈도수 벡터 값 적용
CountVectorizer() 파라미터
- max_df: 높은 빈도수를 가지는 단어 제외(0.95 이면 상위 5% 제외)
- min_df: 낮은 빈도수를 가지는 단어 제외(0.02이면 하위 2% 제외)
- max_features: 추출하는 피처의 개수(높은 빈도순)
- stop_words: 불용어 제외
- n_gram_range: (범위 최솟값, 범위 최댓값)
- analyzer: 피처 추출을 수행한 단위(dafault='word')
- token_pattern: 토큰화를 수행하는 정규 표현식 패턴 지정(default='\b\w\w+\b')
- tokenizer: 토큰화를 별도의 커스텀 함수로 이용시 적용
BoW 벡터화를 위한 희소 행렬
희소 행렬
: 대규모 행렬의 대부분의 값을 0이 차지하는 행렬
- BoW 형태를 가진 언어 모델의 피처 벡터화는 대부분 희소 행렬
- 불필요한 0 값이 메모리 공간에 할당되어 많은 메모리 공간 필요
- 행렬이 커서 데이터 엑세스를 위한 시간 증가
- 작은 공간을 차지하도록 변환: COO, CSR 형식
COO 형식
: 0이 아닌 데이터만 별도의 데이터 배열에 저장하고, 그 데이터가 가리키는 행과 열의 위치를 별도의 배열로 저장하는 방식
ex. [[3,0,1],[0,2,0]] => (0,0), (0,2), (1,1)
import numpy as np
dense = np.array( [ [ 3, 0, 1 ], [0, 2, 0 ] ] )
from scipy import sparse
# 0 이 아닌 데이터 추출
data = np.array([3,1,2])
# 행 위치와 열 위치를 각각 array로 생성
row_pos = np.array([0,0,1])
col_pos = np.array([0,2,1])
# sparse 패키지의 coo_matrix를 이용하여 COO 형식으로 희소 행렬 생성
sparse_coo = sparse.coo_matrix((data, (row_pos,col_pos)))CSR 형식
: COO 형식이 행과 열의 위치를 나타내기 위해서 반복적인 위치 데이터를 사용해야 하는 문제점을 해결한 방식

- 행 위치 배열 [0,0,1,1,1,1,1,2,2,3,4,4,5] -> [0,2,7,9,10,12,13] (index만 표현)
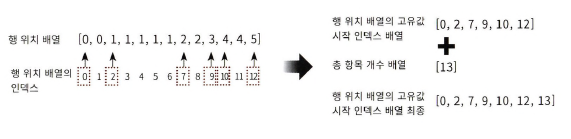
- 메모리가 적게 들고 빠른 연산 가능
# 행 위치 배열의 고유한 값들의 시작 위치 인덱스를 배열로 생성
row_pos_ind = np.array([0, 2, 7, 9, 10, 12, 13])
# CSR 형식으로 변환
sparse_csr = sparse.csr_matrix((data2, col_pos, row_pos_ind))8.4 20 뉴스그룹 분류
- 희소 행렬의 분류를 효과적으로 잘 처리할 수 있는 알고리즘: 로지스틱 회귀, 선형 서포트 벡터 머신, 나이브 베이즈 등
@
8.5 감성 분석
: 문서의 주관적인 감성/의견/감정/기분 등을 파악하기 위한 방법
- 문서 내 텍스트가 나타내는 여러가지 주관적인 단어와 문맥을 기반으로 감성 수치를 계산하는 방법 이용
- 긍정/부정 지수로 구성 -> 합산하여 긍/부정 결정
- 지도학습: 학습 데이터와 타깃 레이블 값을 기반으로 학습 수행, 다른 데이터의 감성 분석을 예측하는 방법
- 비지도 학습: 'Lexicon'이라는 감성 어휘 사전 이용. 감성 분석을 위한 용어와 문맥에 대한 정보를 갖고 긍/부정적 감성 여부 판단
지도학습 - IMDB 영화평
비지도학습
- Lexicon 감성 사전: 긍정/부정 감성의 정도를 의미하는 수치(감성 지수)를 가짐
- 감성 지수는 단어의 위치, 주변 단어, 문맥, POS(Part of Speech) 등을 참고해 결정
- NLTK.WordNet: 어휘의 시맨틱(문맥상 의미) 정보 제공, 품사로 구성된 개별 단어를 Synset(Sets of cognitive synonyms)이라는 개념을 이용해 표현
- NLTK 감성 사전의 예측 성능이 좋지 않아 일반적으로 다른 감성 사전 적용
- SentiWordNet: 긍정 감성 지수, 부정 감성 지수, 객관성 지수를 할당하여 최종 감성 지수를 계산
- VADER: 주로 소셜 미디어의 텍스트에 대한 감성 분석을 제공하며 비교적 빠른 시간에 뛰어난 분석 결과를 제공하여 대용량 데이터에 사용됨
- Pattern: 예측 성능이 뛰어남
SentiWordNet
8.6 토픽 모델링
: 문서 집합에 숨어 있는 주제를 찾아내는 것
- 머신러닝 기반의 토픽 모델은 숨겨진 주제를 효과적으로 표현할 수 잇는 중심 단어를 함축적으로 추출
- LSA, LDA(LatentDirichletAllocation()) 기법
20 뉴스그룹 실습
@
8.7 문서 군집화
: 비슷한 텍스트 구성의 문서를 군집화(비지도 학습)
@
8.8 문서 유사도
코사인 유사도
: 벡터와 벡터 가느이 유사도를 비교할 때 벡터의 크기보다는 벡터의 상호 방향성이 얼마나 유사한지에 기반
두 벡터 사잇각
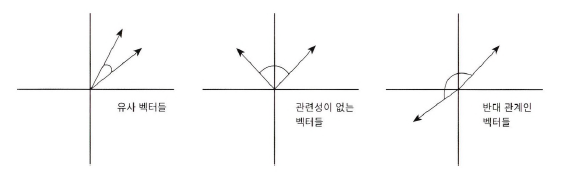
코사인 유사도
: 두 벡터의 내적을 총 벡터 크기의 합으로 나눈 것(내적 결과를 총 벡터 크기로 정규화한 것)
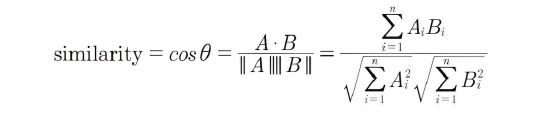
- 희소 행렬 기반에서 문서와 문서 벡터 간의 크기에 기반한 유사도 지표(유클리드 거리 기반 지표)는 정확도가 떨어지기 쉬움
- 문서가 긴 경우 단어의 빈도수가 많을 것이기 때문에 빈도수에만 기반해서는 공정한 비교를 할 수 없음
def cos_similarity(v1, v2):
dot_product = np.dot(v1, v2)
l2_norm = (np.sqrt(sum(np.square(v1))) * np.sqrt(sum(np.square(v2))))
similarity = dot_product / l2_norm
return similarity- sklearn.metrics.pairwise.cosine_similarity API
- 파라미터: 비교 기준이 되는 문서의 피처 행렬, 비교되는 문서의 피처 행렬
from sklearn.metrics.pairwise import cosine_similarity
similarity_simple_pair = cosine_similarity(feature_vect_simple[0] , feature_vect_simple)
print(similarity_simple_pair)8.9 한글 텍스트 처리
한글 NLP 처리의 어려움
- 띄어쓰기: '아버지가 방에 들어가신다'가 '아버지 가방에 들어가신다'가 될 수도 있음
- 조사: '집은'에서 은이 조사인지 은(銀)인지 구분하기 어려움
KoNLPy
: 한글 형태소 패키지
- 형태소: 단어로서 의미를 가지는 최소 단위
- 형태소 분석: 말뭉치를 형태소 어근 단위로 쪼개고 각 형태소에 품사 태깅을 하는 방법
네이버 영화 평점 감성 분석
@
8.10 캐글 Mercari Price Suggestion Challenge
@
