📖 1. 주제 선정 이유
🔆 첫 주제는 ‘시장 동향’을 보는 대시보드
- 원론적이지만, 분석가, 특히 BA는 내부 지표만 보지 않는다.
- 분석가의 관심사는 넒어야 함
- 도메인 : 현업에서는 이미 알고 있다.
- 시장 / 트렌드 : 모두가 영향을 받는다.
- 경쟁사 : 우리도 대응해야 한다.
- 그래서 공식 데이터로 시작 : 통계청 공식 데이터로 알아보는 온라인 쇼핑 동향
- 진행 방식 : 전처리 → 태블로 / 루커 스튜디오 → 동향 파악
📖 2. 데이터셋 소개
🔆 통계청 공식 데이터로 알아보는 온라인 쇼핑 동향
- 5월 자료를 6월동안 조사하여 7월에 발표

- 온라인 쇼핑에서는 어떤 카테고리의 거래액이 가장 높은가? 전년 대비 어떤 카테고리가 가장 크게 성장했는가? 등의 질문 가능
🔆 데이터 셋 자세히 소개
- 총 3가지 데이터 셋 제공
- 판매매체 : 모바일 쇼핑 + 인터넷 쇼핑
- 취급범위 : 종합몰 + 전문몰
- 운영형태 : 온라인매장(ex. 쿠팡) + 온오프라인 복합(ex. 올리브영)
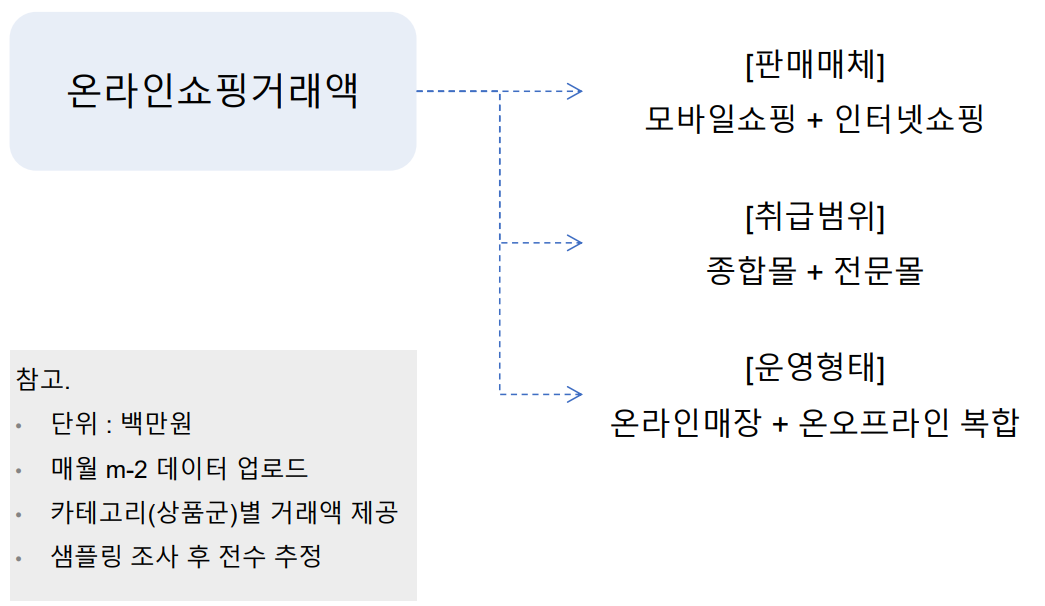
🔆 컬럼단위로 보는 온라인 쇼핑 거래액

🔆 공통적인 문제점 : 이 데이터는 쓸 수 없다.
- 이미 집계가 완료된 형태
- 총합, 중간 집계값 존재
- 거래액이 중복되어 2배로 부풀려질 수 있는 상황
- 가전, 전자, 통신기기 카테고리 세분화
- 거래액이 중복되어 2배로 부풀려질 수 있는 상황
- 날짜 컬럼 양식 불일치
- 추청치 컬럼 때문에 양식이 일부 다르다.
📖 데이터 재구조화
🔆 1번 문제 : 집계가 완료된 형태
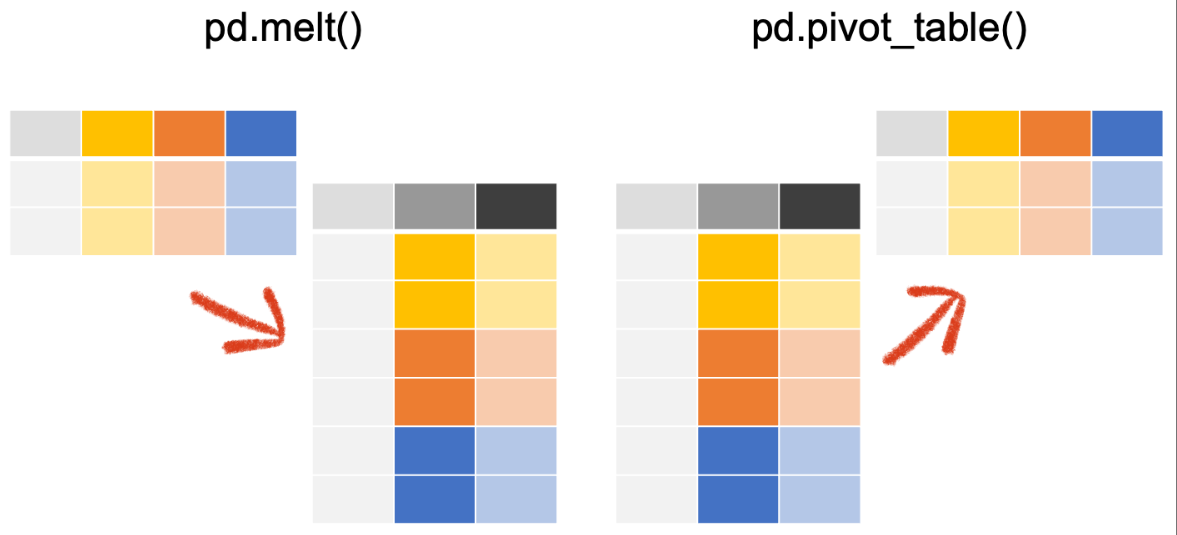
- 재구조화를 위한 메서드 적용
pd.melt(): 집계된 형태를 다시 세로로 길게 만들어주는 함수pd.pivot_table(): 엑셀의 pivot 테이블과 통일, 세로 형태를 가로 형태로 전환
🔆 pd.pivot_table()
- 엑셀의 pivot 테이블과 통일, 세로 형태를 가로 형태로 전환
df.pivot_table(values = None, # 집계값
index = None, # 집계기준(행)
columns = None, # 집계기준(열)
aggfunc = 'mean') # 집계방식 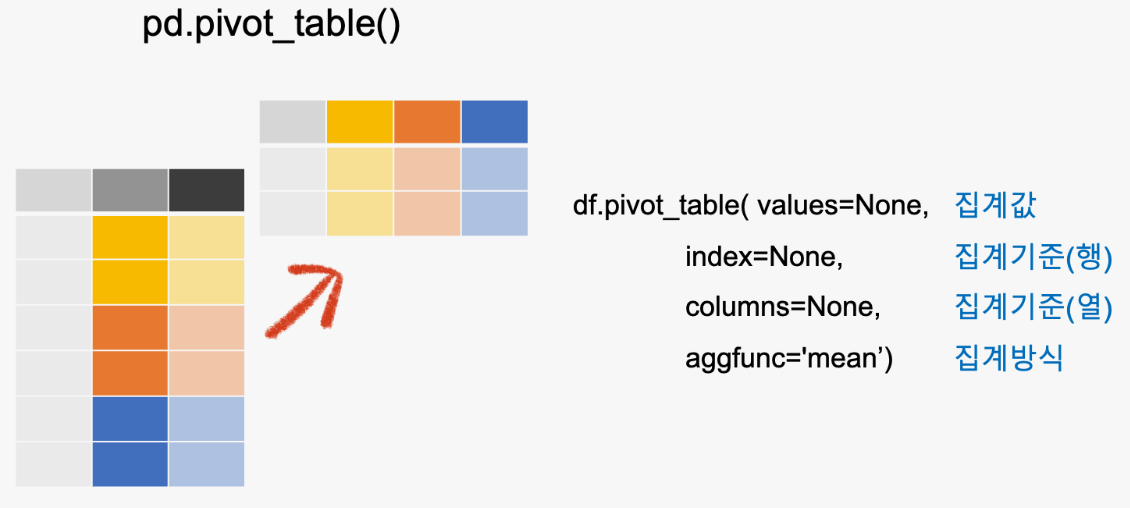
🔆 pd.melt()
- 집계된 데이터를 세로로 길게 늘여트리는 메서드
df.melt(id_vars = None, # 유지할 컬럼
value_vars = None, # 변환할 컬럼
var_name = None, # 변환 후 생성되는 컬럼 이름
value_name = 'value') # 변환 후 생성되는 값 컬럼의 이름 
📖 데이터 탐색
☁️ Pandas 설치
!pip install pandas: 판다스 설치!pip list: 설치완료 확인
☁️ 파일 불러오기
import pandas as pd: 판다스 불러오기route1 = r'csv파일 위치': csv 파일 불러오기\U가 주소에 들어가 유니코드로 인식하는 에러 발생r은 Raw 문자열을 의미, 가공되지 않고 문자 그대로 사용하라는 뜻\가 이스케이프 문자이기에 이부분을 무력화 하는 동작
df = pd.read_csv(route1, encoding = 'cp949'):utf-8,cp949: 한글 encoding이 필요한 데이터셋
☁️ 데이터 탐색
df.info(): 데이터 타입 확인- 2017.01 ~ 2019.12 : object -> int 수정 해줘야함
df.columns: 컬럼 확인df.columns[0]: 0번 컬럼 확인
df[df.columns[0]].unique(): 0번 컬럼의 데이터 유일 값 확인df['column_name'].unique(): 컬럼명 지정하여 유일값 확인df[df['column_name'] == 'data']: 값이 data인 테이블 추출
📖 데이터 구조화
☁️ pd.melt()

df.melt(): 집계된 데이터를 세로로 길게 늘여트리는 메서드pd.melt(df):melt()다른 표현 방식df.tail():head()와 반대로 하위 값 추출df.melt('column_name'): 유지할 값 입력pd.melt(df, id_vars = list(df.columns[:3]))- 유지할 컬럼 외 컬럼은 세로로 길게 펴버림
- 먼저 재구조화할 데이터프레임(df)을 써주고 id_vars는 인덱스(기준)
pd.melt(df, id_vars = cate_cols, var_name = 'var_name', value_name = 'value_name')- 다른 표현 :
df.melt(id_vars = cate_cols, var_name = 'var_name', value_name = 'value_name') var_name과value_name으로 column명을 바로 지정 가능var_name은melt를 통해 새로 생기는 집계 기준value_name은 값을 의미하는 column
- 다른 표현 :
☁️ pd.pivot_table()

pivot은 값을 집계하고, 모양도 바꿀 수 있다. (행, 열 지정)result = df2.copy(): 데이터 프레임 copyresult.pivot_table(index = ['column1', 'column2', ...]):- int형이 아닌 object형으로 선언되어 있음
- 데이터 오류, 집계할 수 있는 값이 없다
TypeError: agg function failed [how->mean,dtype->object] Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
set(): 집합 자료형- 중복을 허용하지 않고, 순서가 없다.
- 인덱싱 지원 X
- 중복을 허용하지 않고, 순서가 없다.
if type(i) != int: 데이터 타입이 int형이 아닌 값 추출replace(바뀔_문자열, 바꿀_문자열): 문자열 안의 특정한 값을 다른 값으로 치환
☁️ Indexing
df = df[조건식]: df에 조건식으로 구한 값 대입drop(): 데이터프레임에서 열을 삭제하는 메서드df.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')labels: 삭제할 레이블명 /axis를 지정해야 함axis: {0 : index / 1 : columns} /labels인수를 사용할경우 지정할 축index: 인덱스명을 입력해서 바로 삭제 가능columns: 컬럼명을 입력해서 바로 삭제 가능level: 멀티인덱스의 경우 레벨을 지정해서 진행 가능inplace: 원본을 변경할지 여부 /True일경우 원본이 변경, 기본값Falseerrors: 삭제할 레이블을 찾지 못할경우 오류를 띄울지 여부 /ignore할 경우 존재하는 레이블만 삭제- ※
axis=0+labels는index인수와 역할이 같고axis=1+labels는columns와 역할이 같다.
apply(): DataFrame에 함수를 적용하여 반환하는 메서드df.apply(func, axis=0, raw=False, result_type=None, args=(), kwargs)function: 각 행이나 열에 적용할 함수axis: {0 : Index / 1 : columns} 함수를 적용할 축row: {True : ndarray / False : Series} 함수에 전달할 축의 형식True면ndarray형태로 전달하고False면Series형태로 전달 / 기본적으로Series
result_type: {expand / reduce / broadcast} 반환값의 형태를 결정expand이면 배열 형태를 기준으로 열을 확장(기본 인덱스로)reduce인 경우는 그대로 Serise형태로 반환broadcase인 경우 기존 열 형식대로 확장하여 반환(열의 수가 같아야 함)
☁️ Lambda
def: 함수를 만들 때 사용하는 예약어 / 함수 이름은 함수를 만드는 사람이 임의로 만들 수 있다-
매개변수(parameter): 함수에 입력으로 전달되는 값을 받는 변수 -
인수(arguments): 함수를 호출할 때 전달하는 입력값 -
※ 매개변수와 인수 혼용 주의!
def 함수_이름(매개변수): 수행할_문장 ... return 리턴값
-
lambda: 함수를 생성할 때 사용하는 예약어 / 보통 함수를 한 줄로 간결하게 만들 때 사용함수_이름 = lambda 매개변수1, 매개변수2, ... : 매개변수를_이용한_표현식to_csv(): 데이터프레임 객체를 csv 형식으로 변환하는 메서드df.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', quoting=None, quotechar='"', line_terminator=None, chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.', errors='strict', storage_options=None)path_or_buf: csv파일이 생성되는 경로와 파일명sep: csv 파일의 구분자 / 기본값은 ' , 'na_rep: 결측값을 어떻게 출력할지 지정 가능 / 기본값은 공백float_format: 부동소수점의 경우 어떤 형식으로 출력할지 지정 가능columns: 출력할 열을 지정하는 인수header: 열 이름을 설정 /False일 경우 열 이름을 출력Xindex: 인덱스의 출력 여부 /False일 경우 인덱스를 출력Xindex_label: 인덱스의 레이블(인덱스명)을 설정mode: {'w' / 'a'} 쓰기 모드를 지정 /a로 지정할 경우 기존 파일 아래에 값을 추가하여 입력 가능encoding: 인코딩 설정 / 기본값은utf-8compression: {‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’,None} 압축 설정을 지정 / 기본값은 'infer'로 적절한 압축형식을 추론quoting: 값에 대해서 인용구 설정 가능 / 어떤 값에 대해서 인용구를 설정할지는 아래와 같다- {
0: MINIMAL 문자와 특수문자 /1: ALL 모든필드 /2: NONNUMERIC 숫자가 아닌것 /3: NONE 안함}
- {
quotechar:quoting에서 지정한 인용구에 대해서 인용구에 사용할 문자를 지정 / 기본값은 쌍따옴표chunksize: 한번에 불러올 행의 수를 지정 / 예를들어 100을 입력할 경우 한번에 100행씩 변환 / 속도 향상에 기여date_format: 값이 시계열(datetime) 데이터인 경우 그 값의 포맷을 지정(예 : '%Y-%m')doublequoto: 값중에quotechar과 같은 값이 있을때, 그 값을 인용구 처리할지의 여부escapechar:doublequoto=False인 경우 인용구와 중복되는 그 값을 어떤 값으로 변경할지 여부decimal: 자리수로 쓰이는 문자를 지정 / 즉,100,000의 경우decimal="."으로 할 경우100.000으로 표시errors: 인코딩 오류에 대해서 오류 처리 설정 / 가능한 값은 아래와 같다- {
strict: 인코딩 오류에 ValueError 발생 /ignore: 무시 /replace잘못된 데이터를 대체마커 '?' 지정 / ...}
- {
storage_options: 특정 스토리지 연결에 적합한 추가 옵션 / 예: 호스트, 포트, 사용자 이름, 비밀번호 등을 지정
📖 List Comprehension
☁️ List Comprehension
- 리스트를 간결하게 나타내는 문법
[표현식 for 항목 in 반복_가능_객체 if 조건문] ☁️ range([start,] stop [,step])
- 입력받은 숫자에 해당하는 범위 값을 반복 가능한 객체로 만들어 리턴
range([start,] stop [,step])- 인수가 하나일 경우
시작 숫자를 지정해 주지 않으면 range 함수는 0부터 시작한다.
list(ange(5))
[0, 1, 2, 3, 4]- 인수가 2개일 경우
입력으로 주어지는 2개의 인수는 시작 숫자와 끝 숫자를 나타낸다. 단, 끝 숫자는 해당 범위에 포함되지 않는다는 것에 주의하자.
list(range(5, 10))
[5, 6, 7, 8, 9]- 인수가 3개일 경우
세 번째 인수는 숫자 사이의 거리를 말한다.
list(range(1, 10, 2))
[1, 3, 5, 7, 9]
list(range(0, -10, -1))
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]📖 OS 라이브러리
☁️ OS
os.getcwd(): 현재 위치os.listdir(path): path 하위의 파일(디렉터리 포함)을 리스트로 반환os.path.join(path, *paths): path와 paths에 해당하는 모든 경로를 더하여 전체 경로를 반환os.mkdir(path): 새로운 폴더 생성os.rename(filename1, filename2): 폴더 파일 이름 변경 / 앞의 폴더를 뒤의 폴더명으로 변경os.path.exists(path): path가 기존 경로나 열린 파일 기술자를 참조하면True를 반환os.rmdir(path): 폴더 삭제os.path.splitext(path):(root, ext)/root와ext(파일 확장자)를 분리
