Health-LLM: Large Language Models for Health Prediction via Wearable Sensor Data
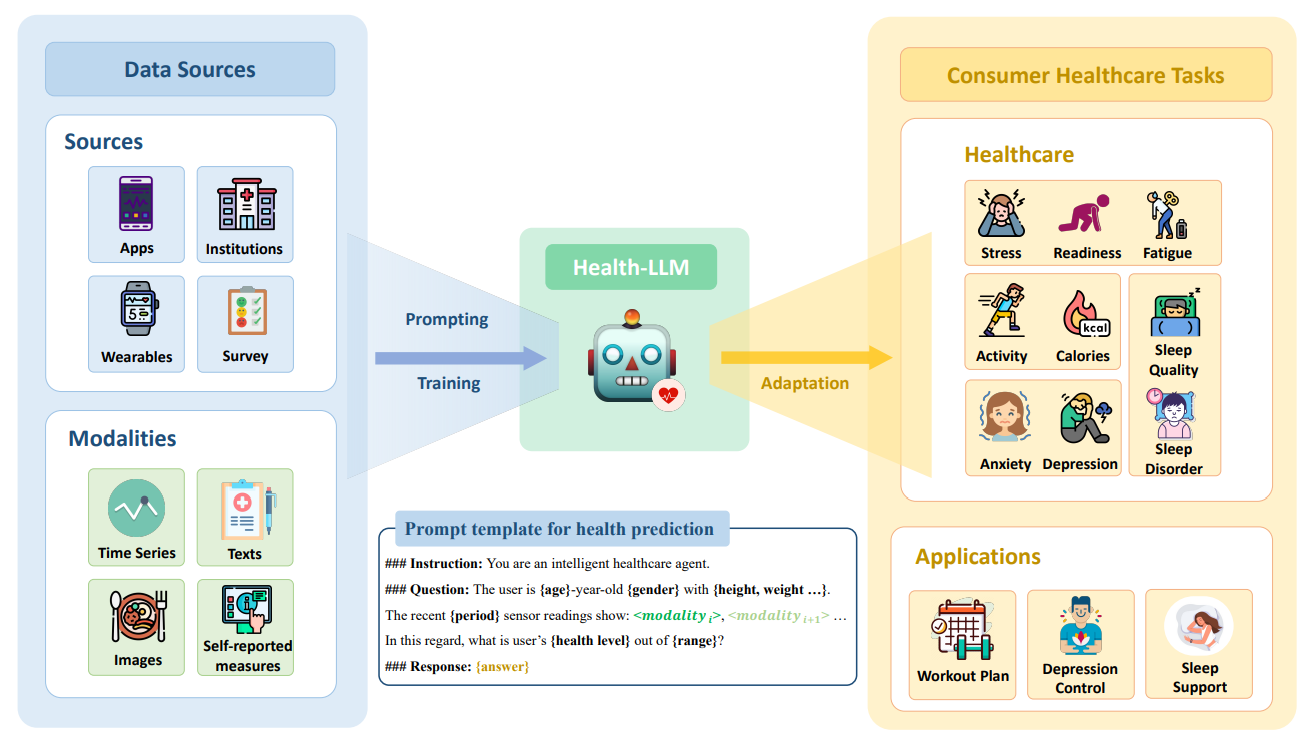
Health-LLM: Large Language Models for Health Prediction via Wearable Sensor Data
어플, 웨어러블, 서베이, 기관 등으로부터 멀티모달 데이터를 받아온다고 가정하는 컨셉 기반 연구로 소스들로 어떻게 데이터를 받아오고, 다양한 형태의 데이터를 어떻게 처리해 llm에 입력할 것인지에 대해 다루고 있지는 않습니다
고민해볼 것:
- 어떤 소스로부터 데이터를 가져올지
- 어떻게 실시간으로 데이터를 수집할 것인지
- 오디오, 이미지, 비디오, 텍스트 등 다양한 형식의 데이터를 어떻게 처리할 것인지
- 텍스트 형식의 데이터 중에서도 time series data 등 특정 형태의 데이터는 어떻게 처리할 것인지
결과볼 때 왜 결과가 이렇게 나왔는지 생각해보기. 공개 데이터셋의 경우 baseline 모델이 이미 학습한 데이터일 수도 있다
이 연구는 LLM을 활용하여 웨어러블 센서 데이터를 통해 건강 예측을 수행하는 프레임워크, Health-LLM을 제안합니다. 연구진은 12개의 최신 LLM을 사용하여 정신 건강, 활동 추적, 대사 및 수면 평가와 관련된 10개의 건강 예측 작업을 실험했습니다. 주요 모델로서 "HealthAlpaca"를 개발했으며, 이는 더 큰 모델(GPT-3.5, GPT-4 등)과 비슷한 성능을 보였고, 특히 10개 작업 중 8개에서 가장 뛰어난 성과를 보였습니다.
연구의 주요 성과는 다음과 같습니다:
- Contextual Prompting의 중요성: 사용자 정보, 건강 지식, 시간적 정보를 포함한 문맥적 강화가 성능을 크게 향상시키며, 최대 23.8%까지 개선이 가능함을 확인했습니다.
- 제로샷 및 퓨샷 학습: 제로샷 학습에서도 높은 성과를 보였으나, 퓨샷 및 Chain-of-Thought, 자가 일관성(SC) 전략을 통해 모델의 성능을 더 높일 수 있었습니다.
- 미세 조정의 효과: HealthAlpaca는 GPT-4보다 작은 모델임에도 우수한 성능을 보여, LLM이 웨어러블 데이터 예측에 효과적으로 적응할 수 있음을 시사합니다.
Abstract
LLM은 자연어 작업에서 높은 성과를 보이나, 의료 분야에서 특화된 비언어적 데이터를 이해하고 해석하는 데는 한계가 있습니다. 본 연구는 사용자 정보와 생리 데이터를 포함한 맥락 정보를 기반으로 LLM이 건강 관련 예측을 수행할 수 있는 능력을 평가합니다. 연구진은 최신 LLM 12개를 대상으로 프롬프트 설정과 파인튜닝 기법을 적용해, 정신 건강, 활동, 대사 및 수면 평가에 관한 10가지 건강 예측 작업을 수행했습니다. 그 결과, HealthAlpaca라는 모델이 더 큰 모델(GPT-3.5, GPT-4 등)과 유사한 성능을 보이며, 10가지 작업 중 8개에서 가장 우수한 성과를 보였습니다. 연구는 또한 컨텍스트 강화 전략이 최대 23.8%의 성능 개선을 가져오는 등 건강 예측에 유용함을 강조하고 있습니다.
- 스마트폰 및 웨어러블 센서에서 생성되는 다차원적인 시계열 데이터의 다양성을 활용하는 데 있어 LLM의 역량은 제한적으로만 연구되었습니다.
- 정적인 텍스트와 달리, 이러한 데이터는 높은 차원성, 비선형 관계, 그리고 연속적 특성 때문에 LLM이 시간 경과에 따른 동적 패턴을 이해해야 하는 어려움이 있습니다.
- 컨텍스트 강화란 LLM이 헬스케어 도메인에서 이해력을 높이기 위해 프롬프트에 추가 정보를 전략적으로 포함시키는 기법으로, 주요 요소는 다음과 같습니다:
- 사용자 프로필 (예: 나이, 성별, 키 등)
- 건강 지식 (특정 건강 목표를 정의하는 정보와 방정식)
- 시간적 맥락 (시간 시계열 데이터의 중요성 테스트)
- 이러한 정보를 조합한 종합적인 맥락
1. Introduction
- LLM은 다양한 텍스트 생성 및 지식 검색 작업에 있어서 뛰어난 성능을 보여주고 있지만, 헬스케어 분야에서 LLM의 실제 활용 가능성과 한계는 여전히 충분히 탐구되지 않았습니다.
- 웨어러블 센서 데이터의 도전: 웨어러블 센서에서 생성되는 멀티모달 및 시계열 데이터는 고차원적이고 비선형적인 특성을 지녀 LLM이 이를 이해하기 어렵습니다. LLM이 개별 데이터 포인트 뿐만 아니라 시간에 따른 동적 패턴을 이해해야 하기 때문입니다.
- 현재 LLM 중 일부는 의학 분야 지식을 다루는 데 가능성을 보이고 있지만, 소비자 건강 예측 작업, 특히 생리적 데이터(예: 심박수)와 행동 시계열 데이터(예: 일일 걸음 수)에 의존하는 작업에서는 그 활용이 제한적입니다.
2. Related Works
2.1. Wearable Sensor Data with LLMs
웨어러블 센서 기술은 개인 건강 모니터링에 혁신을 가져왔으며, 심박 변이와 같은 생리 데이터를 연속적으로 추적할 수 있게 되었습니다. 이러한 시계열 데이터는 평균, 표준편차와 같은 통계 요약, 푸리에 변환 등을 통해 다양한 형태로 모델에 입력됩니다. 이 데이터는 텍스트로 사용하거나 특정 모듈과 타임스탬프 인코더를 통해 인코딩된 형태로도 입력이 가능합니다. 이러한 웨어러블 센서 데이터와 머신러닝의 결합은 스트레스 수준 모니터링, 영양 관리와 같은 다양한 건강 결과를 예측하는 데 유망한 가능성을 보입니다.
2.2. Health LLMs
LLM을 의료에 적용하는 연구는 빠르게 성장하고 있습니다. 예를 들어, Singhal et al. (2022)은 PaLM 2와 같은 LLM을 개선하여 다양한 데이터셋에서 우수한 성능을 보였습니다. 또한, Xu et al. (2023)은 LLM을 정신 건강 작업에 적용하고, 원격 데이터와 시계열 데이터를 활용해 성과를 증진시켰습니다. 최근 GPT-4는 의료 시험에서 높은 점수를 기록하며, 의료 논리를 설명하는 데 뛰어난 능력을 보여줍니다.
Here’s a structured summary for the Methods section with bullet points for clarity:
3. Methods

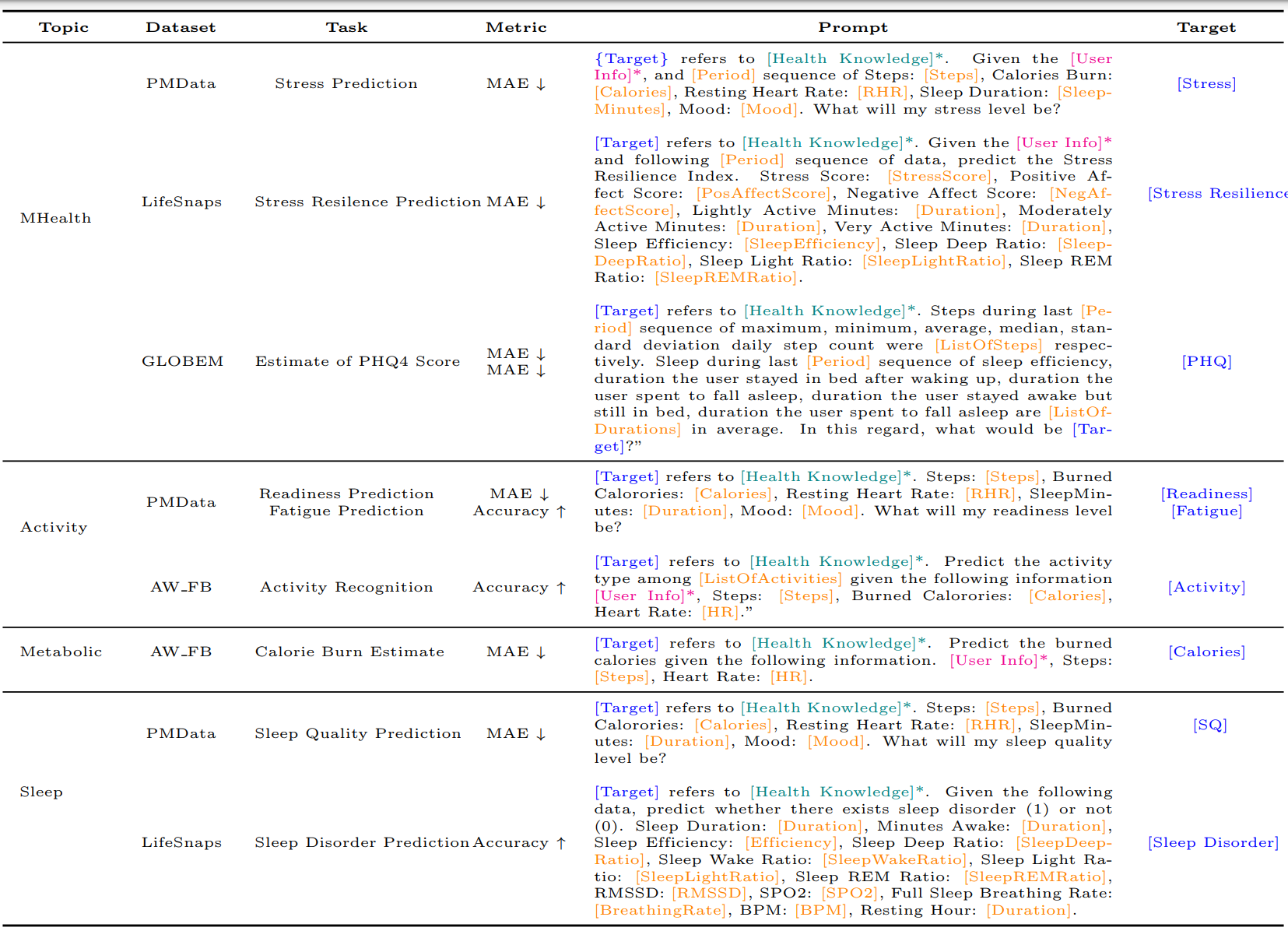

3.1. Zero-shot Prompting
- 목적: 사전 학습된 LLM이 별도의 추가 학습 없이 의료 예측 작업을 수행할 수 있는지 평가.
- 방법: 기본 프롬프트 설정(bs)을 통해 웨어러블 센서 데이터를 요약.
- 프롬프트에 추가되는 정보:
- 사용자 프로필 정보(예: 연령, 성별) User Context
- 건강 관련 지식 및 정의 Health Context
- 시간적 맥락을 포함한 시계열 데이터 Temporal Context
3.2. Few-shot Prompting
- 목적: 3-shot으로 모델이 문맥 학습을 통해 예측 작업을 수행하도록 유도.
- 추가 기법:
- Chain-of-Thought(CoT): 모델이 논리적으로 이어지는 생각을 연결하여 이해도를 높임.
- Self-Consistency(SC): 모델의 응답을 일관되고 논리적으로 만들기 위한 기법.
- 효과: CoT와 SC 기법이 결합된 프롬프팅으로 모델의 의료 지식 이해도를 극대화함.
3.3. Instruction Tuning
- 목적: 사전 학습된 모델의 파라미터를 특정 작업에 맞게 조정하여 성능 향상.
- 방법: Parameter Efficient Fine-tuning(PEFT) 기법을 통해 적은 파라미터만 조정하여 모델을 헬스케어 작업에 맞춤.
- 효과: 모델이 건강 예측에 필요한 용어와 메커니즘을 깊이 이해하게 되어, 보다 정확한 예측이 가능함
3.4. Temporal Encoding Methods
- 목적: 시계열 데이터를 텍스트 형식으로 변환하여 LLM이 시간적 패턴을 이해하도록 지원.
- 주요 인코딩 방식:
- 자연어 문자열 변환: 데이터의 간결성과 해석 용이성을 위해 자연어로 표현.
- 모달리티별 인코딩: 데이터의 특정 모달리티에 맞춘 인코딩 방식을 적용.
- 통계적 요약 방식: 데이터의 주요 특징을 요약하여 표현.
- 장점:
- 자연어 문자열 변환:
- 간결하고 해석이 쉬워, 사용자가 결과를 쉽게 이해할 수 있음.
- 결측값이 있을 경우, "NaN" 등의 특수 기호로 처리하여 데이터 손실 없이 표현할 수 있음.
- 매일, 매주, 매월과 같은 특정 time window를 직관적으로 나타내어 시계열 데이터의 변동성을 효과적으로 반영함.
- 모달리티별 인코딩:
- 데이터의 특성에 맞춘 맞춤형 인코딩 방식을 사용하여, 각 모달리티(예: 심박수, 걸음 수 등)의 고유한 패턴을 더 정확하게 반영할 수 있음.
- 타임스탬프 인코더 등을 활용하여 시간의 흐름에 따른 데이터의 변화를 보다 명확히 캡처할 수 있음.
- 통계적 요약 방식:
- 평균, 표준편차와 같은 통계적 요약을 통해 시계열 데이터의 전반적인 경향과 변동성을 파악하는 데 유용함.
- 요약된 데이터를 통해 모델이 시간에 따른 일반적인 패턴을 이해하도록 돕고, 연산 자원을 절약하면서도 중요한 정보는 유지할 수 있음.
- 자연어 문자열 변환:
4. Experiment
4.1. Datasets and Tasks
- 사용된 4가지 데이터셋:
- PMData: 16명의 참가자 대상, Fitbit과 PMSys 스포츠 로그를 사용하여 스트레스, 준비 상태, 피로도, 수면의 질 등 다양한 데이터를 수집.
- LifeSnaps: 71명의 참가자로부터 Fitbit Sense와 설문 데이터로 수면 장애 및 스트레스 회복력 등을 평가.
- GLOBEM: 497명의 장기 데이터를 포함하여 우울증과 불안 수준을 파악하기 위해 수집된 다년간의 데이터.
- AW FB: 신체 활동을 구분하고 칼로리 소모량을 예측하기 위해 Apple Watch와 Fitbit 데이터를 포함한 49명의 활동 로그.
- 작업 유형:
- 각 데이터셋에서 스트레스 예측, 수면 장애 탐지, 준비 상태 평가, 피로도 모니터링, 칼로리 소모량 추정 등의 작업을 정의하여, 총 10개의 건강 관련 예측 작업 수행
4.2. Models
- 사용된 모델들:
- MedAlpaca, PMC-Llama, GPT-3.5, GPT-4 등 pre trained 모델 사용
- 베이스라인 비교: 단순한 다수결 클래스 예측, 전통적 머신러닝 모델(MLP, SVM, RandomForest), 전통적 언어 모델(BERT, BioMed-RoBERTa 등)과의 성능 비교.
- 모델들은 각기 다른 소비자 건강 예측 작업에서의 성능을 평가하기 위해 사전 학습 데이터 및 크기 차이를 통해 비교됨
5. Results and Discussion
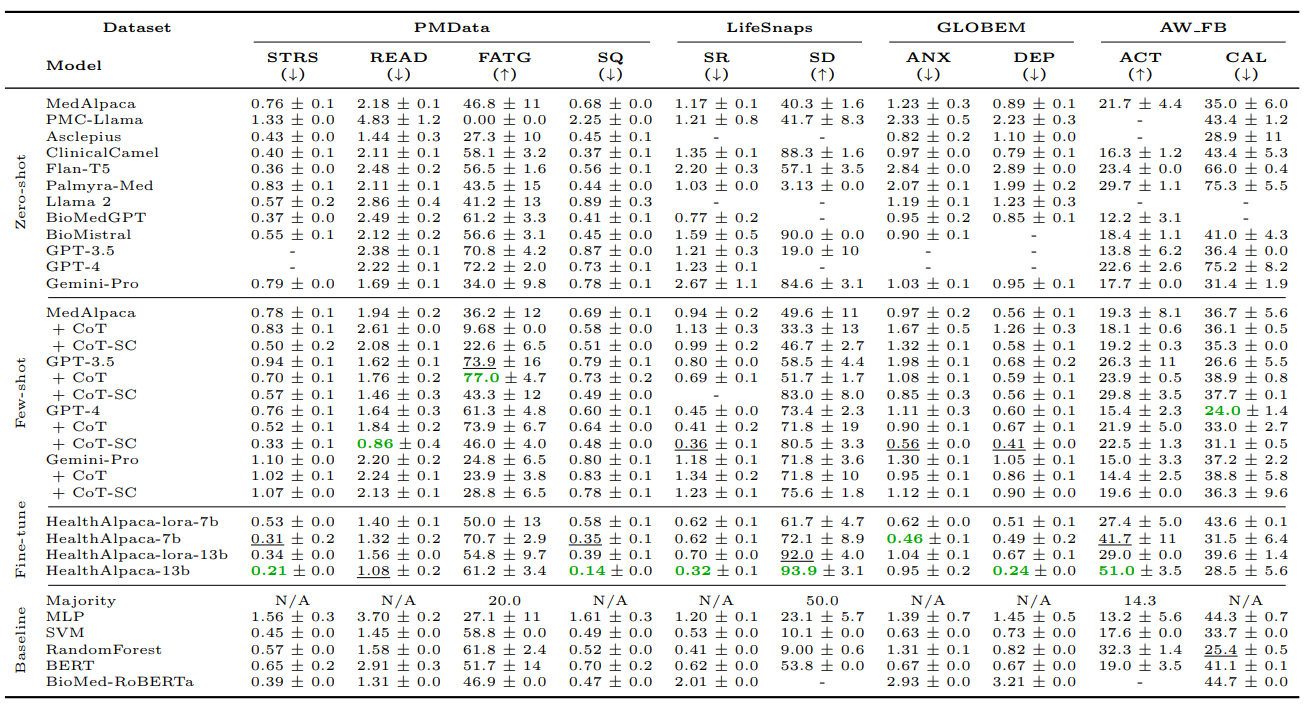
5.1. Zero-shot and Few-shot Performance
- Zero-shot:
- 모델 크기와 성능 간의 명확한 우위는 발견되지 않았음.
- 작은 모델(100B 미만의 파라미터)이 일부 작업에서 큰 모델보다 더 좋은 성능을 보여줌.
- 예: Asclepius는 고품질 임상 데이터로 사전 훈련되어 GPT-3.5-turbo와 비슷한 성능을 나타냄, 이는 모델 크기보다 도메인 특화 지식이 더 중요할 수 있음을 시사함.
- Few-shot:
- GPT-3.5와 GPT-4는 few-shot 프롬프팅에서 성능 향상을 보여줌.
- 특히 CoT와 SC 기법을 적용했을 때 10개의 작업 중 9개에서 최고의 성과를 기록하여 구조화된 프롬프팅이 중요한 역할을 함【10:0†source】【10:3†source】.
5.2. Finetuning Performance
- HealthAlpaca 모델:
- 모든 소비자 건강 작업 중 10개 중 8개에서 최고 성능을 기록, 이는 두 배 이상의 파라미터를 가진 GPT 시리즈 및 Gemini-Pro와 비슷하거나 더 나은 성과를 보임.
- HealthAlpaca-lora: LoRA 기법을 사용한 효율적인 파라미터 튜닝을 통해 모델 성능을 높임.
- 파라미터 증가 효과: HealthAlpaca-13b는 더 큰 파라미터 수로 인해 HealthAlpaca-7b보다 대부분의 작업에서 더 높은 성능을 보임
5.3. Generalization of Fine-tuned Models across Datasets
- 데이터셋 간 일반화 성능 평가:
- 데이터셋별로 특화된 파인튜닝을 수행하여 작업별 성능을 비교.
- 다중 데이터셋 파인튜닝 모델인 HealthAlpaca는 단일 데이터셋 파인튜닝 모델보다 다양한 작업에서 더 나은 일반화 성능을 보임.
- 일부 경우(예: AW FB에서 STRS 예측)에서는 단일 데이터셋 파인튜닝이 zero-shot 및 데이터셋 특화 모델보다 성능이 우수했음, 이는 데이터셋 간 시너지 효과가 일부 작업에서 유리할 수 있음을 시사함
5.4. Importance of different contexts in Prompt Designing for Healthcare LLMs
- 여러 컨텍스트 정보(사용자 정보, 건강 지식, 시간적 맥락 등)를 추가하면 모델 성능이 크게 향상되었습니다. 특히, 건강 컨텍스트를 추가할 때 성능 향상이 가장 크게 나타났습니다.
- 모델 별로 컨텍스트의 효과가 다르게 나타났습니다. 예를 들어, Palmyra-Med 모델은 시간적 맥락을 추가했을 때 최대 44.58% 성능 개선을 보였으며, 이는 의학 데이터셋(PubMedQA와 MedQA)으로 미세 조정된 덕분입니다. 시간적 패턴을 잘 이해하여 건강 상태의 변화 추세를 효과적으로 해석할 수 있게 된 것입니다.
- 반면에 GPT-3.5나 GPT-4와 같은 대형 모델에서는 이미 시간 시리즈 데이터의 통계적 특성을 이해할 수 있어, 시간적 컨텍스트 추가가 큰 도움이 되지 않았습니다.
- 데이터셋 측면에서도 성능 향상이 관찰되었으며, LifeSnaps 데이터셋은 최대 34.46%까지 개선되었습니다. 특히, GLOBEM과 AW FB 데이터셋은 시간적 요소가 두드러져 모든 컨텍스트 강화 전략에서 성능 개선이 크게 나타났습니다.
5.5. Importance of Training Size in Fine-tuning Performance
- 모델 HealthAlpaca의 성능을 다양한 훈련 데이터 크기로 실험하여, 데이터의 양이 미세 조정 성능에 미치는 영향을 평가했습니다. 원본 데이터셋의 5%, 15%, 25%, 50%, 100%로 줄인 데이터를 사용했으며, 15% 데이터셋만으로도 모든 작업에서 제로샷 성능을 초과하는 성과를 달성했습니다. 이는 제한된 컴퓨팅 자원으로도 효과적인 미세 조정이 가능하다는 것을 시사하며, 더 많은 훈련 데이터가 추가될수록 성능이 점진적으로 향상됨을 보여줍니다
5.6. Case Study of LLM’s Capability on Health Reasoning
- 시간 시리즈 데이터 해석: HealthAlpaca와 GPT-4 등 모델이 건강 데이터에 대해 다른 해석 방식을 보였습니다. 예를 들어, HealthAlpaca는 보수적인 접근을 통해 일관된 활동을 유지하는 것을 강조했지만, GPT-4는 활동량이 높은 날을 중심으로 활발한 활동을 제안했습니다. 수면 장애 평가에서 HealthAlpaca는 전반적인 수면 메트릭스를 바탕으로 장애가 없음을 제안했지만, GPT-4는 수면의 불일치와 낮은 효율성을 감지하여 수면 문제 가능성을 제시했습니다.
- 잘못된 추론 및 환각: 데이터 해석 오류가 발생하는 경우도 있으며, LLM은 데이터나 일반적인 기준을 잘못 적용해 부정확한 건강 평가를 할 수 있습니다. 예를 들어, HealthAlpaca는 높은 활동성을 충분히 반영하지 못하거나, GPT-4는 일관된 활동 필요성을 과소평가하는 등의 오류를 보였습니다. 이러한 사례는 LLM이 세부 데이터 분석과 전체적인 건강 평가 간의 균형을 유지해야 할 필요성을 강조합니다
6. Conclusion
- 컨텍스트 강화의 효과: 건강 지식을 포함한 프롬프트 설계가 모든 데이터셋과 LLM에서 성능을 향상시키는 데 크게 기여함을 확인했습니다.
- HealthAlpaca 모델의 우수성: 미세 조정된 HealthAlpaca 모델은 10개 과제 중 8개에서 GPT-4와 Gemini-Pro 같은 대형 모델을 능가하는 성능을 보였습니다.
- LLM의 건강 추론 능력: 사례 연구를 통해 LLM이 건강 예측을 수행하는 과정에서 잘못된 해석이나 환각된 추론이 발생할 수 있음을 확인하고, 모델이 보다 신뢰성 있는 건강 평가를 제공할 수 있도록 세밀한 데이터 분석이 필요하다고 강조했습니다.
정리
-
이 논문에서 LLM을 웨어러블 센서 데이터에 적용할 때 주요 도전 과제는 무엇인가?
LLM은 텍스트 기반 작업에서 우수한 성능을 보이지만, 웨어러블 센서 데이터는 다중모달 시계열 데이터로, 높은 차원성과 비선형적 특성을 지녀 LLM이 효과적으로 처리하기 어렵다. 시간적 흐름과 연속성, 데이터의 비정형성 등은 LLM이 패턴을 인식하고 예측하는 데 도전 과제로 작용한다. -
Health-LLM 프레임워크의 주요 구성 요소는 무엇인가?
Health-LLM 프레임워크는 웨어러블 센서 데이터를 처리하기 위해 사용자 프로필, 건강 지식, 시간적 맥락과 같은 컨텍스트를 강화한 프롬프트 설계, 제로샷 및 퓨샷 프롬팅, 파인튜닝 기법을 포함한다. 특히, PEFT 기법을 사용하여 모델을 효율적으로 미세 조정함으로써, LLM이 건강 예측에 특화된 지식을 학습하도록 설계되었다. -
HealthAlpaca 모델은 기존 LLM들과 비교해 어떤 점에서 우수한가?
HealthAlpaca는 파인튜닝을 통해 헬스케어 작업에 최적화된 모델로, 10가지 건강 예측 과제 중 8개에서 GPT-4와 같은 대형 모델보다 우수한 성능을 기록했다. 특히, 다중모달 데이터를 해석하고, 다양한 건강 지식과 시간적 패턴을 반영하여 높은 예측 성능을 보여주었다. -
이 논문의 연구 결과를 다른 헬스케어 도메인에 어떻게 적용할 수 있는가?
이 논문의 연구 결과는 웨어러블 센서 데이터 외에도 EMR(전자 의료 기록) 데이터와 같은 비정형 데이터에 LLM을 적용하여 환자의 상태 모니터링이나 예후 예측에 활용할 수 있다. 사용자 컨텍스트 강화 전략과 파인튜닝 기법은 다양한 건강 관련 데이터에 확장 적용되어 맞춤형 의료 서비스를 지원할 수 있다. -
LLM을 통한 개인 맞춤형 건강 예측의 실용적인 이점은 무엇인가?
LLM을 활용한 개인 맞춤형 건강 예측은 사용자 특성에 맞춘 세부적인 건강 관리와 실시간 모니터링을 가능하게 한다. 이를 통해 조기 진단과 예방적 관리가 가능하며, 사용자 경험을 높여 자가 건강 관리와 의료 전문가의 의사 결정을 지원할 수 있다. -
본 연구에서 제안된 프레임워크를 개선하기 위해 어떤 추가 연구가 필요한가?
본 연구의 프레임워크를 개선하기 위해 다양한 인구 통계 및 건강 상태에 대한 데이터 확장을 통한 일반화 연구가 필요하다. 또한, 사용자 피드백을 반영해 실시간으로 성능을 조정하는 적응형 학습 시스템을 개발함으로써, 보다 개인화된 예측과 사용 편의성을 높일 수 있다.
