Leveraging LLMs to Predict Affective States via Smartphone Sensor Features
Leveraging LLMs to Predict Affective States via Smartphone Sensor Features
Digital Phenotyping (=Personal sensing) 이란 스마트폰, 웨어러블 등 개인 디지털 기기로부터 데이터를 수집하고 분석해 행동, 신체 및 정신 건강을 추론 하는 활발한 연구분야입니다. 전통적인 분석방법은 통계 및 기계학습이지만, LLM의 등장으로 새로운 접근이 가능해졌습니다.
해당 논문의 연구 목표는 스마트폰 센서 데이터를 활용하여 대학생들의 감정 상태를 예측하기 위해 LLM의 가능성을 탐구하는 것입니다. 데이터가 적은 환경에서 기존의 통계 및 머신러닝 모델이 성능이 제한적이라는 문제를 해결하고자, 제로샷 및 퓨샷 학습 방식의 LLM을 적용하여 스마트폰 행동 데이터와 감정 상태 간의 연관성을 파악하고, 이를 통해 digital phenotyping 기술을 개선하는 데 목적이 있습니다.
이 연구는 스마트폰의 다양한 센서를 통해 수집된 데이터(배터리 사용, 화면 잠금 해제, 위치, 앱 사용 기록, 키보드 사용, 통신 기록 등)를 분석하여 사용자의 행동과 감정 상태의 연관성을 파악하려고 했습니다. 또한, LLM의 제로샷 및 퓨샷 기법을 활용하여 감정 상태(예: 활동적, 주의 집중, 긴장, 두려움 등)를 예측하는 방식을 검토했습니다. 그 결과, 퓨샷 방식이 감정 상태 예측에 더 유효하였으며, 특히 LLM이 특정 행동 패턴을 인지할 수 있음을 보여주었습니다.
ABSTRACT
젊은 성인의 정신 건강 문제가 증가함에 따라, 스마트폰과 같은 개인 디지털 장치에서 수집된 데이터를 분석해 감정 상태를 예측하는 디지털 페노타이핑(digital phenotyping)이 중요한 연구 주제로 떠오르고 있다고 설명합니다.
기존의 통계 및 머신러닝 접근법 대신 LLM을 활용하여 대학생의 스마트폰 센서 데이터 기반으로 감정 상태를 예측하는 연구를 진행했으며, 제로샷 및 퓨샷 방식의 LLM을 사용해 감정 상태를 예측하는데 성공적인 결과를 보였습니다.
1. INTRODUCTION
Digital phenotyping은 스마트폰과 같은 디지털 장치에서 행동 데이터를 수집해 정신 건강 상태를 예측하는 방식으로, 정신 건강 연구에서 주목받고 있습니다. 하지만 기존 머신러닝 모델은 소규모 데이터에서 overfitting 문제를 겪기 쉬워 디지털 페노타이핑에 한계가 있었습니다. 이에 따라, 저자들은 대형 언어 모델(LLM)의 높은 추론 능력과 넓은 사전 지식을 활용하여 스마트폰 센서 데이터를 분석하고 감정 상태를 예측하는 가능성을 탐구하고자 했습니다.
overfitting: overfitting은 머신러닝 모델이 학습 데이터에 너무 집중하여, 학습 데이터에 포함된 패턴이나 노이즈까지 지나치게 학습하는 현상입니다. 그 결과 모델이 새로운 데이터에 대해 일반화하는 능력이 떨어져, 테스트 데이터나 실제 상황에서는 예측 성능이 낮아지게 됩니다.
2. METHOD AND EXPERIMENTS
논문의 방법 및 실험 부분에서는 연구 설계, 데이터 수집, 데이터 처리, LLM의 예측 작업에 대한 세부사항을 설명합니다.
2.1 Participants and Data Collection
-
참가자: 2023년 호주 대학생 약 150명을 대상으로 한 digital phenotyping 연구의 일환으로, 그 중 10명의 데이터를 분석 대상으로 선정했습니다. 연구 기간은 한 학기(17주) 동안 진행되었습니다.
-
데이터 수집: 스마트폰 센서를 통해 데이터를 수집했으며, AWARE-Light 앱을 사용하여 배터리 잔량, 화면 잠금 해제 횟수, 위치 정보, 앱 사용 기록, 키보드 사용, 통화 및 메시지 등 다양한 행동 데이터를 지속적으로 기록했습니다.
-
자기 보고 평가: 참가자들은 매주 이메일을 통해 제공된 링크로 I-PANAS-SF(Positive and Negative Affect Schedule, 긍정 및 부정 감정 상태를 측정하는 설문지)를 작성했습니다. 이 설문지는 긍정 감정(활기참, 결단력, 주의 집중, 영감, 경각심)과 부정 감정(화남, 적대감, 부끄러움, 초조함, 두려움)을 각각 리커트 척도(1~5)로 평가합니다 .
-
데이터 처리: 수집된 데이터는 중복 및 오류 항목을 제거하고 77개의 행동 특성으로 변환되었습니다. 각 특성은 하루 일과의 데이터로 표현되었으며, 설문지 항목별로 예측하도록 데이터를 구성했습니다.
-
LLM 예측 작업:
- 제로샷 예측: LLM이 학습 데이터 없이 주간 활동 설명을 기반으로 감정 상태를 예측하게 했습니다.
- 퓨샷 예측: 퓨샷 학습을 통해 데이터의 일부를 제공하여 점진적으로 예측 정확도를 높였습니다.
- chain-of-thought 기법: LLM이 예측 결과에 대한 논리를 설명할 수 있도록 유도하여 예측의 이해 가능성을 높였습니다.
2.2 Data processing
-
데이터 정제: 자가 보고 설문 데이터와 스마트폰에서 수집된 raw data를 정제하여 중복 및 손상된 항목을 제거하였습니다.
-
행동 특성 생성: RAPIDS 도구를 사용하여 일일 수준의 행동 특성을 생성하고 선택하였습니다. 예시로 집에서 보낸 시간, 받은 메시지 수, 화면 잠금 해제 지속 시간 등이 포함되며, 누락된 데이터에 대해서는 대체하지 않고 그대로 처리하였습니다.
-
특정 항목 예측: 기존의 연구들은 설문지 전체 점수에 집중하지만, I-PANAS-SF 설문지는 전체 점수를 제공하지 않기 때문에 각 항목(기쁨, 분노 등)에 대해 개별 예측을 수행하였습니다.
-
시간 정보 유지: LLM이 시간 정보를 기반으로, 시간에 따른 변화나 순서를 이해하고 예측에 반영할 수 있는지를 평가하기 위해 데이터에 시간 정보를 포함한 상태로 유지하여 훈련을 진행하였습니다.
예를 들어, 스마트폰 사용 패턴이나 감정 상태는 시간에 따라 변화할 수 있습니다. 아침과 저녁의 활동이 다를 수 있고, 시간 흐름에 따라 감정 상태가 달라질 수 있습니다.
따라서, 시간 정보를 포함한 데이터로 훈련시키면 LLM이 “언제”라는 맥락을 이해하며 예측을 수행할 수 있는지를 확인할 수 있게 됩니다. 이를 통해 LLM이 시간 흐름에 따라 달라지는 행동 패턴과 감정 변화를 잘 파악하는지 평가하려는 것입니다.
2.3 Task Description
연구는 LLM이 스마트폰에서 유추된 행동과 감정 상태 간의 연결을 파악할 수 있는지를 확인하기 위해 제로샷과 퓨샷 작업을 수행했습니다.
-
데이터 구성: 주간 활동 데이터는 약 5,000개의 토큰으로 구성되며, 실험은 리소스 제한으로 인해 Gemini 1.5 Pro에서 수행되었습니다. LLM은 텍스트 설명 대신 각 감정 상태에 대해 리커트 점수(1~5)를 예측하도록 설정했습니다. 일관된 응답을 위해 temperature 값을 0으로 설정하여 예측이 변동 없이 나오도록 조정했습니다.
-
작업 설정: 10명의 참가자의 17주 데이터를 무작위로 나누어 10주는 훈련용, 7주는 테스트용으로 사용했으며, 각 참가자에 대해 여러 번의 무작위 훈련-테스트 분할을 반복했습니다.
-
샷 수 증가: 퓨샷 프롬프트 방법에서는 1샷부터 시작해 최대 10샷까지 훈련 예제를 단계적으로 추가했습니다. 제로샷 작업은 기본 비교용으로 수행되었으며, 각 감정 상태에 대한 주간 활동 설명을 바탕으로 감정 점수를 예측하게 했습니다.
(리커트 점수: "기쁨 점수: 4" / 텍스트 설명: "학생은 대부분 즐거운 기분이었으며, 활기차고 긍정적인 모습을 보였습니다.")
3. RESULTS & DISCUSSION
-
평가 지표: 예측의 정확성을 평가하기 위해 각 참가자에 대한 평균 절대 오차(MAE)와 상대 오차를 개별적으로 계산하고, 이들을 전체 평균으로 산출했습니다.
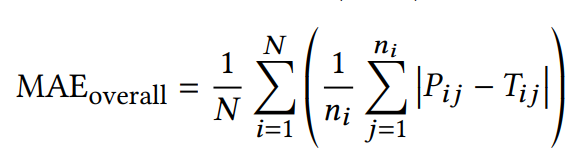
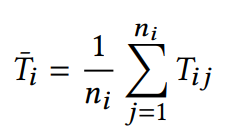
-
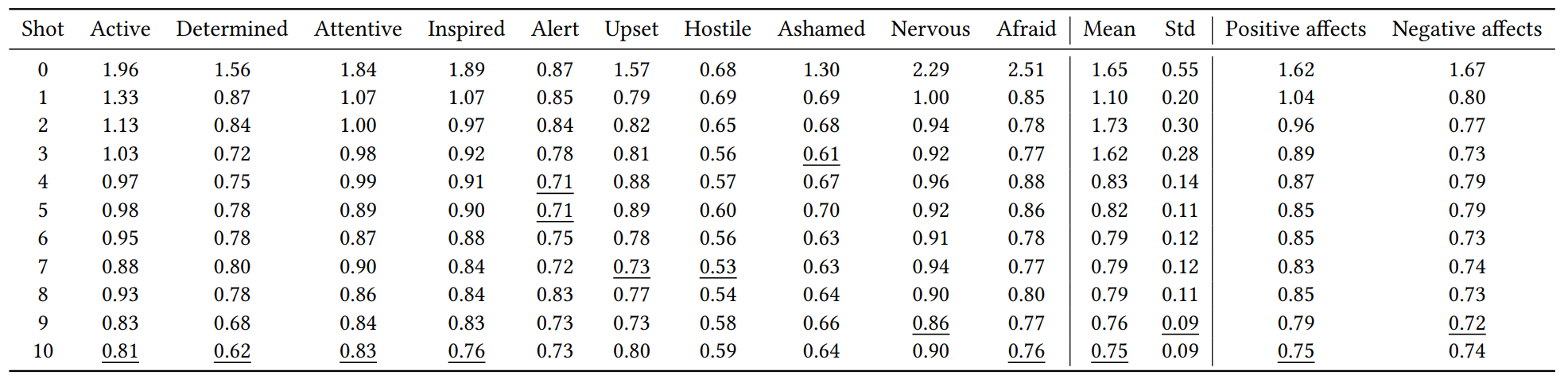
제로샷 성능: 제로샷 학습에서는 MAE가 1.65로 높아 예측 정확도가 낮았으나, 각 참가자별 예측 일관성은 유지되었습니다. 특히, 긍정 감정과 부정 감정 예측의 성능이 거의 비슷하게 나타났으며, '경각심' 항목에서 성능이 가장 좋았고, '두려움'과 '초조함' 항목에서는 성능이 가장 낮았습니다.
-
퓨샷 성능: 퓨샷 학습에서는 샷 수가 증가할수록 MAE가 감소하여, 1샷에서 성능 향상이 두드러졌습니다. 특히 1샷에서는 긍정 감정보다 부정 감정에서 예측 성능이 더 우수했으나, 10샷에서는 긍정과 부정 감정 예측 성능이 거의 비슷해졌습니다.
예시를 제공하기 시작한 후 성능이 눈에 띄게 향상, 많은 예시를 제공할 수록 긍정 및 부정 감정 사이의 예측 성능이 비슷해짐. -
감정 항목별 차이: 일부 항목에서는 예측 성능이 우수했으며, 특히 '적대감' 항목에서 가장 낮은 MAE를 보였습니다. 샷 수가 증가할수록 각 항목 간 성능 차이가 줄어드는 경향이 나타났으며, 이는 LLM이 추가된 데이터로 인해 더 안정적인 예측 성능을 발휘하게 됨을 시사합니다.
-
참가자별 성능: 참가자별로 MAE가 감소하는 경향이 나타났으며, 각 참가자에 대해 긍정 감정과 부정 감정 예측 곡선이 비슷한 추세를 보였습니다. 이는 스마트폰 행동 데이터가 감정 상태를 예측하는 데 유사한 수준의 정보를 제공하고 있음(LLM이 긍정적인 감정과 부정적인 감정을 예측하는 데 있어 스마트폰 행동 데이터로부터 균형 잡힌 정보를 얻고 있다)을 나타냅니다.
 1샷에서 뚜렷한 성능 향상, 샷 수가 증가할수록 감정 예측 성능(MAE)이 전반적으로 향상됨
1샷에서 뚜렷한 성능 향상, 샷 수가 증가할수록 감정 예측 성능(MAE)이 전반적으로 향상됨
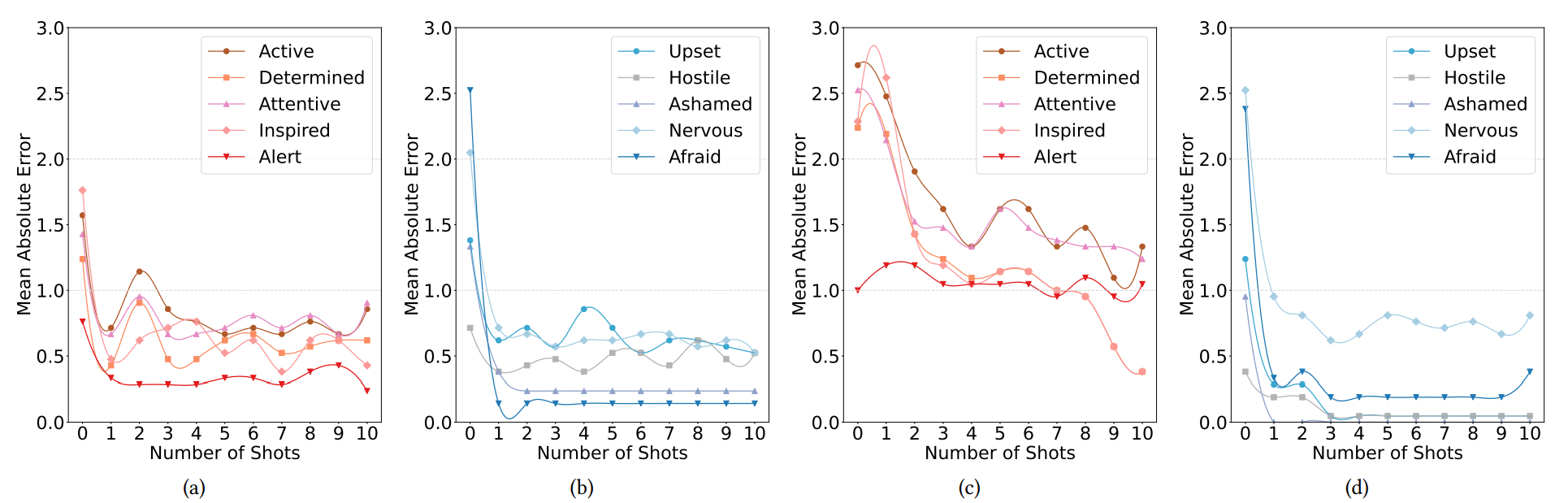 Figure 3: 두 명의 참가자에 대해 샷 수가 증가할수록 긍정 및 부정 감정 예측의 평균 절대 오차(MAE)가 감소하여 예측 성능이 향상됨
Figure 3: 두 명의 참가자에 대해 샷 수가 증가할수록 긍정 및 부정 감정 예측의 평균 절대 오차(MAE)가 감소하여 예측 성능이 향상됨
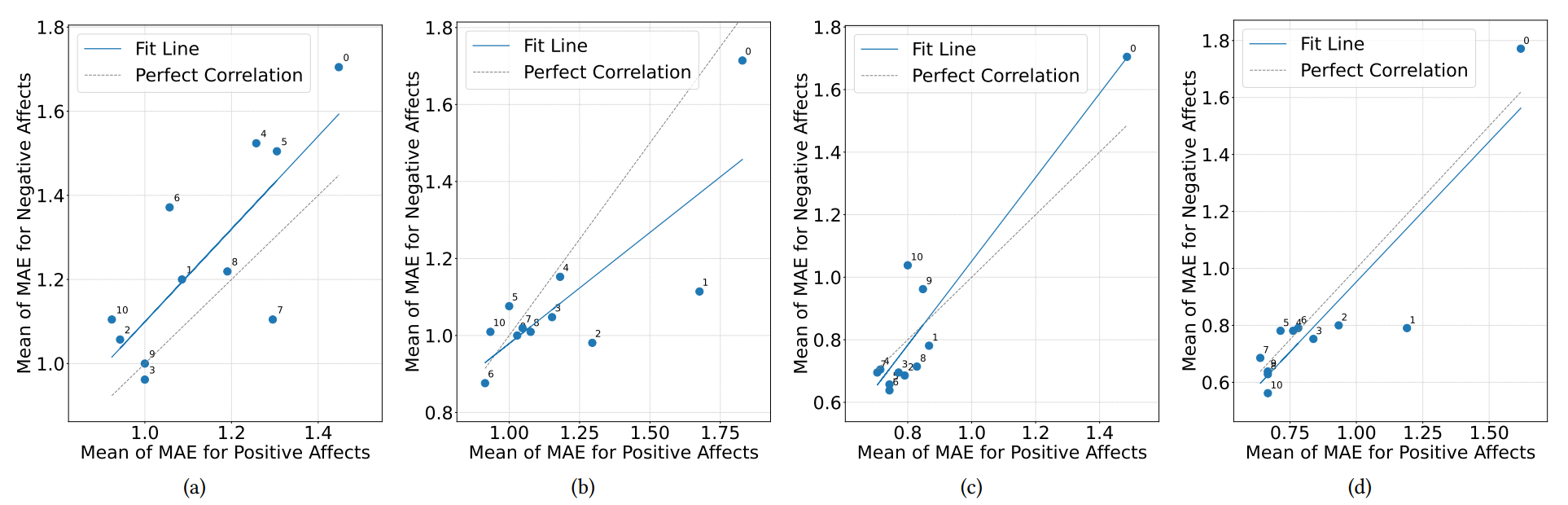 Figure 4: 네 명의 참가자에 대한 긍정 감정과 부정 감정 예측 간의 MAE가 선형적으로 비슷한 속도로 줄어들어, 두 감정 예측 간의 성능 향상이 일관된 관계를 나타냄
Figure 4: 네 명의 참가자에 대한 긍정 감정과 부정 감정 예측 간의 MAE가 선형적으로 비슷한 속도로 줄어들어, 두 감정 예측 간의 성능 향상이 일관된 관계를 나타냄
4. FUTURE WORK AND CONCLUSIONS
제로샷과 퓨샷 학습을 통해, LLM이 최소한의 데이터로도 주간 감정 상태 예측에 성공적으로 적응할 수 있음을 확인했지만, 제로샷에서는 오차율이 높았습니다. 반면, 라벨이 있는 데이터(원샷/퓨샷)를 제공할 경우 예측 성능이 크게 향상되어, LLM이 정신 건강 및 감정 상태 예측에서 중요한 도구가 될 수 있음을 시사합니다.
향후 연구 방향:
- 모델 개선: 일일 활동 기반의 파인튜닝을 통해 더 방대한 데이터를 활용하여 참가자별 예측 모델과 일반 예측 모델 간의 비교가 가능하도록 합니다.
- 데이터 불균형 처리: 자가 보고 데이터의 주관적 특성 때문에 일부 감정 항목이 과소표현될 가능성이 있어 데이터셋의 크기를 늘리거나 리샘플링 기법을 적용하여 더욱 견고한 모델을 구축합니다.
- 추론 능력 향상: chain-of-thought 방식을 사용하여 심리적 웰빙 예측을 개선하는 가능성도 제안합니다.
