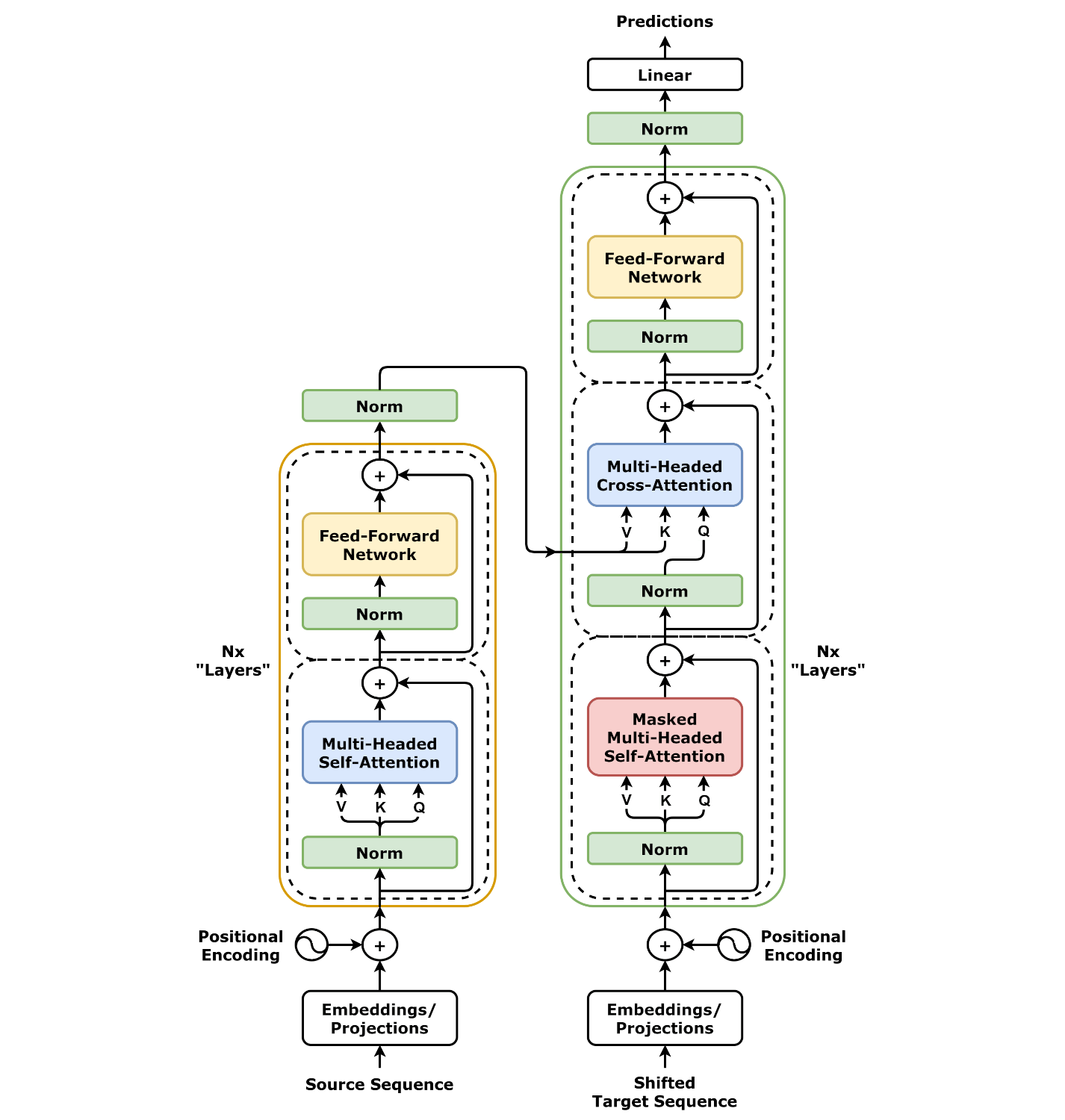
1. Attention
Attention 메커니즘은 문장에서 중요한 단어에 더 집중하는 방법입니다. 인간이 글을 읽을 때 모든 단어에 집중하지 않고, 문맥상 중요한 단어에 더 주의를 기울이는 것과 비슷한 원리입니다. 딥러닝 모델에서는 문장 내 각 단어의 중요도를 계산해 해당 단어들 사이의 관계를 평가하고, 이를 통해 모델이 더 나은 예측을 할 수 있도록 합니다.
2. Encoder와 Decoder
대부분의 자연어 처리(NLP) 모델은 Encoder와 Decoder로 구성되어 있습니다.
- Encoder: 입력 데이터를 받아 이를 압축된 표현(context vector)으로 변환합니다.
- Decoder: 이 압축된 표현을 기반으로 출력 데이터를 생성합니다.
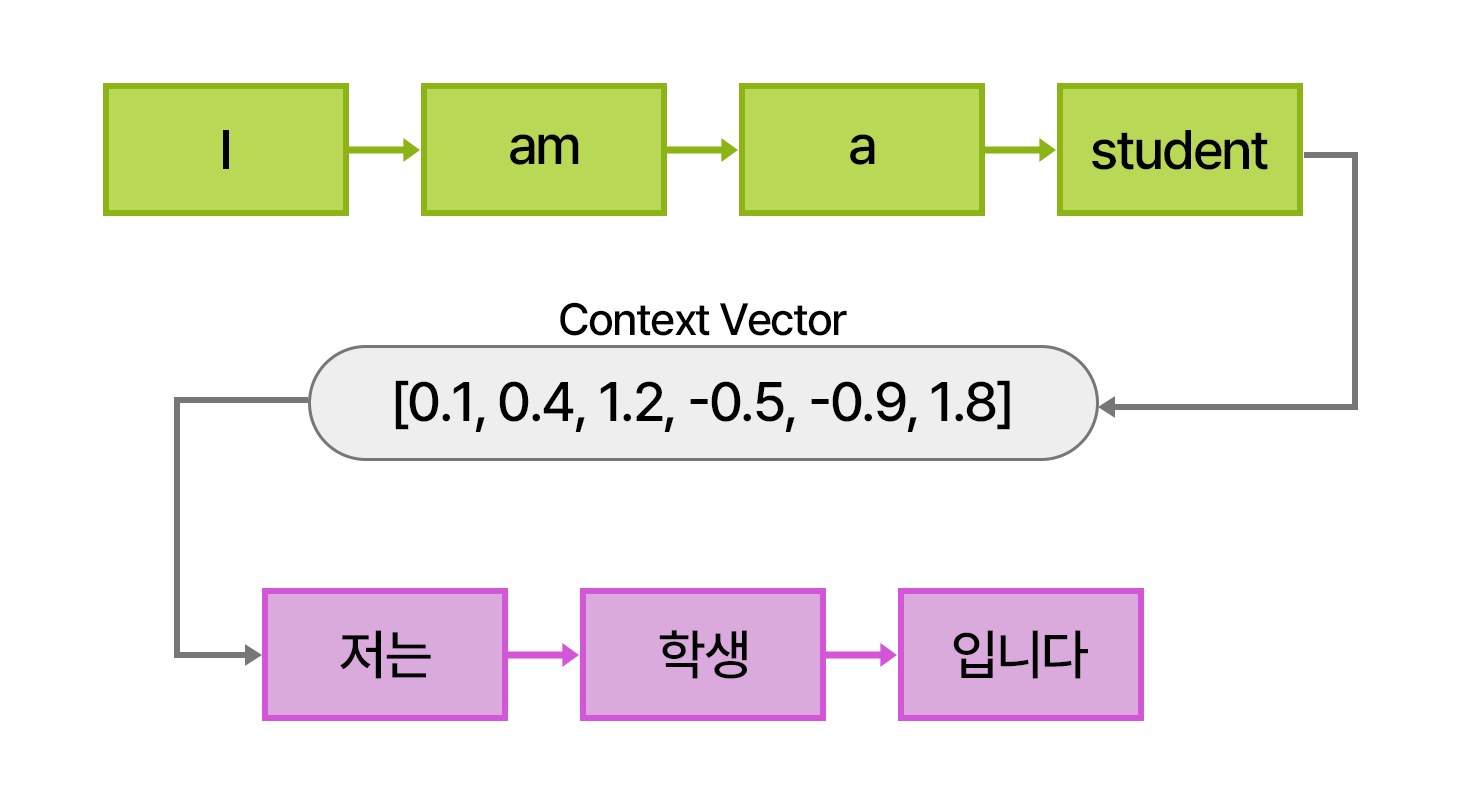
전통적인 RNN(순환 신경망) 기반 모델에서의 문제는, 입력된 단어들 중 일부 정보가 제대로 반영되지 않는다는 문제입니다. RNN 모델에서는 입력된 단어들이 순차적으로 처리되며, 각 단계에서 입력된 단어의 정보가 다음 단계로 전달됩니다. 이때 최종적으로 Encoder의 마지막 시점에서 나온 문맥 벡터(context vector)만을 사용하여 전체 문장을 요약합니다.
이 과정에서, 초기에 입력된 단어들의 정보가 뒤로 갈수록 희미해지는 문제가 발생합니다. 문장의 뒷부분 정보가 더 강하게 반영되고, 앞부분 단어의 정보는 희미해지는 경향이 있습니다. 특히 문장이 길어질수록 이런 문제가 더 심각해지며, 중요한 단어의 정보가 손실될 수 있습니다. 이는 정보 손실 문제로 이어집니다.
또한, 고정된 길이의 Context Vector는 긴 문장을 기억하기 어렵습니다.
이런 경우 전체 인풋을 처리하는 과정에서 문장의 초반부를 잊어버릴 수 있습니다.
이 문제를 해결하기 위해 등장한 것이 바로 Attention 메커니즘입니다. Attention은 입력된 모든 단어의 정보를 고르게 참조하면서도, 문맥상 중요한 단어에 더 집중할 수 있게 합니다. 이를 통해, 특정 단어가 문장에서 더 중요한 역할을 한다면, 그 단어에 대한 정보에 더 많은 가중치를 부여하여 정보 손실을 최소화하고, 중요한 정보를 더 잘 반영하게 됩니다.
따라서 Attention 메커니즘은 단순히 마지막 단어에 의존하는 대신, 문장 내의 모든 단어들 간의 관계를 고려하여, 각 단어가 문장에서 어떻게 쓰였는지를 전체적으로 분석하고 더 정확하게 학습할 수 있게 하는 중요한 방법입니다.
3. Embedding
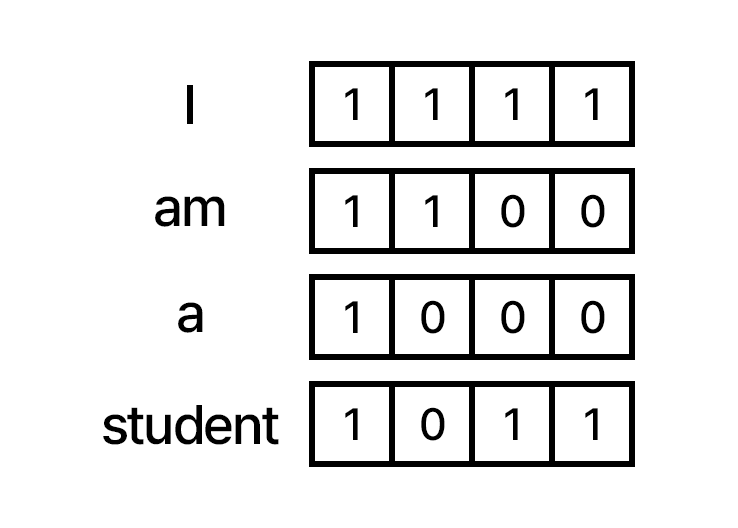
Embedding은 컴퓨터가 이해할 수 있도록 인풋의 자연어를 벡터로 변환하는 과정입니다. 예를 들어, 자연어(한국어, 영어 등)는 텐서(n차원 배열)로 변환됩니다.
예: "학생"이라는 단어를 [0.5, -0.3, 0.1, 0.7]과 같은 벡터로 변환.
임베딩 벡터는 각 단어의 의미를 담고 있으며, 모델 학습을 통해 문맥에 맞게 조정됩니다. 트랜스포머에서는 각 단어의 임베딩 벡터에 Positional Encoding을 더하여 단어의 의미와 위치 정보를 동시에 처리합니다.
Positional Encoding
트랜스포머 모델은 RNN처럼 순차적으로 데이터를 처리하지 않고, 병렬 처리를 합니다.
예)
RNN - "I", "am", "a", "student" 순서대로 인식
Transformer - "I am a student" 문장 하나를 한꺼번에 인식
그래서 단어의 순서 정보를 알지 못하기 때문에, 단어의 순서를 인식할 수 있도록 Positional Encoding을 사용합니다.
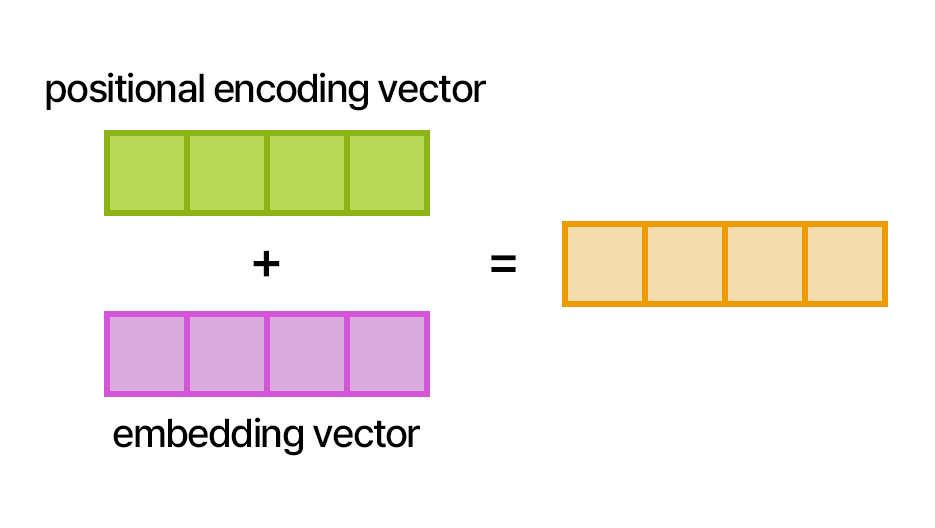
Positional Encoding은 각 단어의 위치에 대한 정보를 표현하는 벡터로, 이를 단어의 임베딩 벡터에 더해줌으로써 순서 정보를 반영합니다. 주기성을 가진 sin과 cos 함수가 사용되며, 긴 문장에서도 위치 정보가 왜곡되지 않고 안정적으로 표현됩니다.
삼각함수의 장점
- 범위가 -1 ~ 1로 안정적
- 주기함수기 때문에 글자수가 10억이 돼도 어차피 값이 -1 ~ 1 사이다. 즉 글자수의 영향을 받지 않는다.
- AI 모델은 예측 가능한 범위에서 왔다갔다 해야 하기 때문에 안정적인 걸 좋아한다. 그래서 정규화 라는걸 보통 해준다.
만약 삼각함수 대신 선형함수를 썼다고 해보자.
y=x-100 이라고 했을 때 글자수가 늘어나면 Positional Encoding 값도 어마어마하게 늘어날 것이다.
첫번째 두번째 글자가 1, 2 라고 했을 때, 물론 값이 차이가 있기는 하겠지만 값 자체가 너무 크기 때문에 상대적으로 차이가 거의 나지 않아 학습이 잘 안된다.
그래서 Positional Encoding은 sin, cos 함수를 사용한다.
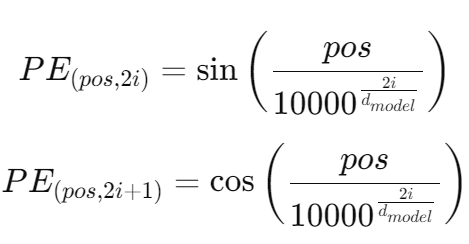
- pos: 문장에서 단어의 위치 (I - 0, am - 1, ...) Position of word
- i:: 임베딩 차원의 인덱스 (위 예시 이미지에서 임베딩 차원의 길이는 4, 즉 인덱스는 0, 1, 2, 3) Location of embedding vector
- d_model: 임베딩 벡터의 크기 Size of embedding vector
2i->짝수 2i+1->홀수
짝수의 경우 sin 함수, 홀수의 경우 cos 함수 사용
이렇게 하는 이유는 경우의 수를 늘리려고. 더 긴 문장도 겹치지 않게 하려고
위 식에서 d_model 로 나눠주는 이유 역시 정규화.
만약 나눠주지 않는다면, 인덱스 값이 크면 PE 값이 0에 가까워진다. 그럼 값별로 큰 차이가 없기 때문에 모델이 이해를 잘 하지 못한다.
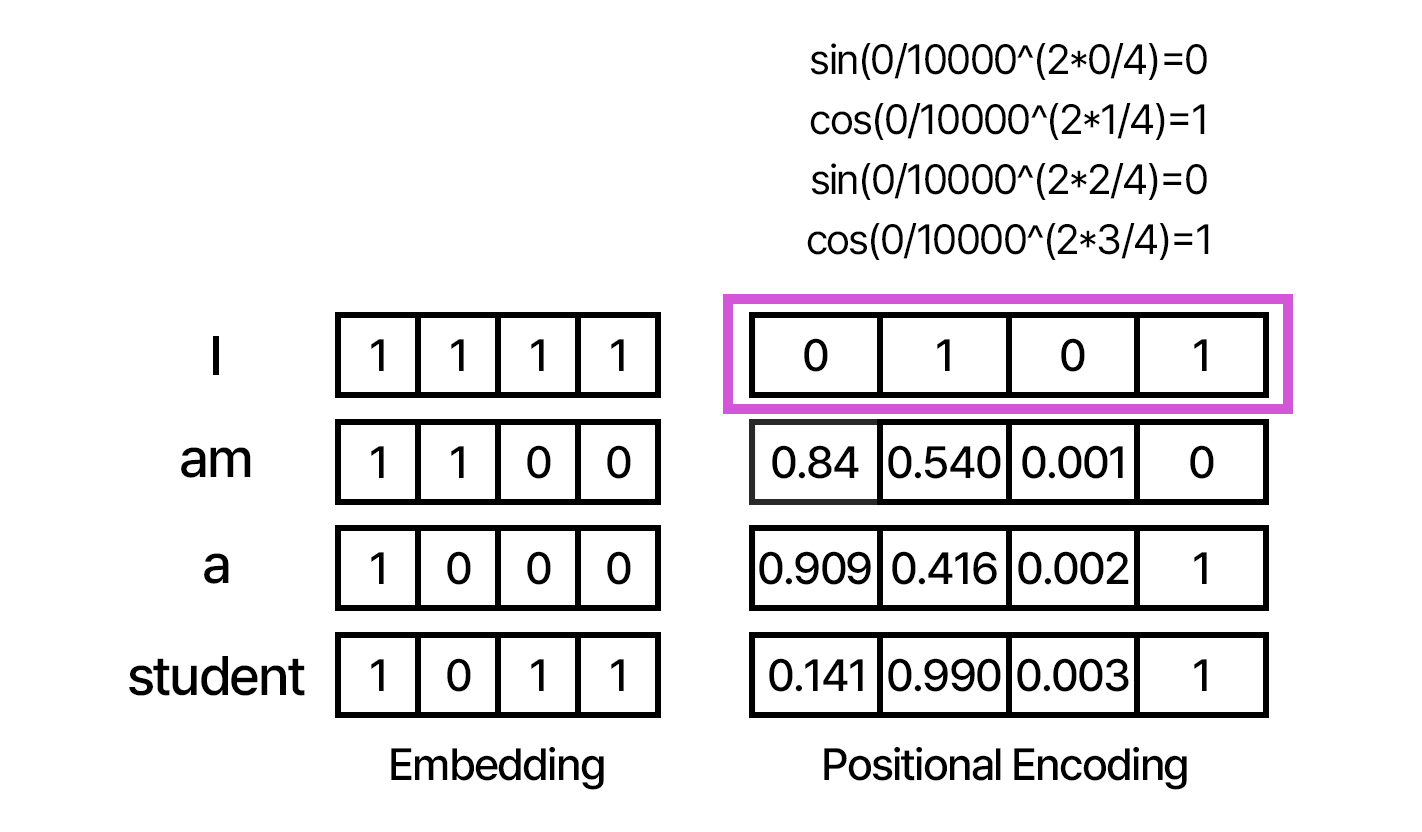
이렇게 계산된 Embedding Vector 와 Positional Encoding Vector 를 더해 만들어진 벡터를 Query, Key, Value Layer에 넣어준다.
4. 임베딩 차원 (Embedding Dimension)
임베딩 차원은 각 단어를 표현하는 벡터의 길이를 의미합니다. 예를 들어, 300차원 임베딩은 각 단어를 300개의 숫자로 표현합니다. 임베딩 차원이 클수록 단어의 의미를 더 정교하게 표현할 수 있지만, 계산 복잡도가 증가합니다. 임베딩 차원은 모델 설계 시 사람이 직접 설정하며, 모든 단어는 동일한 임베딩 차원을 가집니다.
임베딩 차원이 너무 낮으면 단어의 의미를 충분히 표현하지 못할 수 있고, 너무 높으면 학습에 시간이 오래 걸리고 비효율적일 수 있습니다.
임베딩 벡터의 값(예: [0.5, -0.2, 0.1])은 학습 과정에서 자동으로 결정되며, 처음에는 무작위 값으로 시작됩니다.
d_model = 임베딩 벡터의 총 차원 수 = size of embedding vector = 임베딩 차원
5. Self-Attention
The cat didn't eat the apple because it was not hungry.
라는 문장에서 우리는 문맥을 이해하기 때문에, it 이 가리키는 것이 무엇인지 안다.
하지만 기계는 문맥을 자동으로 이해할 수 없다. 이 문제를 해결하기 위해 Attention을 사용한다.
Self-Attention은 문장의 각 단어가 다른 단어들과 얼마나 관련이 있는지를 계산하는 메커니즘입니다. 문장 내에서 각 단어는 자기 자신을 포함한 다른 단어들과의 관계를 평가하고, 이를 바탕으로 중요한 단어를 선택합니다. 이때 Query, Key, Value라는 세 가지 벡터가 사용되며, 각 벡터는 다른 단어와의 상호작용을 통해 계산됩니다.
Self-Attention은 입력의 모든 단어 간 관계를 계산하여, 문장의 의미를 학습하는 데 중요한 역할을 합니다.
Transformer 의 원래 목적은 "번역" 이었다.
Attention)
나는 학생 입니다 -> I am a student
1. 여기서 "나는" 이 어떤 단어랑 제일 연관성있는지 일일히 계산.
2. 여기서 "학생" 이 어떤 단어랑 제일 연관성있는지 일일히 계산.
3. 여기서 "입니다" 이 어떤 단어랑 제일 연관성있는지 일일히 계산.
Self-Attention)
자기자신의 문장에 대한 Attention 을 self 로 취해준다.
I 와 am, I 와 student
am 과 I, am 와 student
...
이렇게 되면 각 단어들 사이의 상관관계를 알 수 있다.
잘 학습된 모델이라면 I 가 가리키는 것이 Student 이라는 것을 학습을 했을 것이다. 이게 Self-Attention이다.
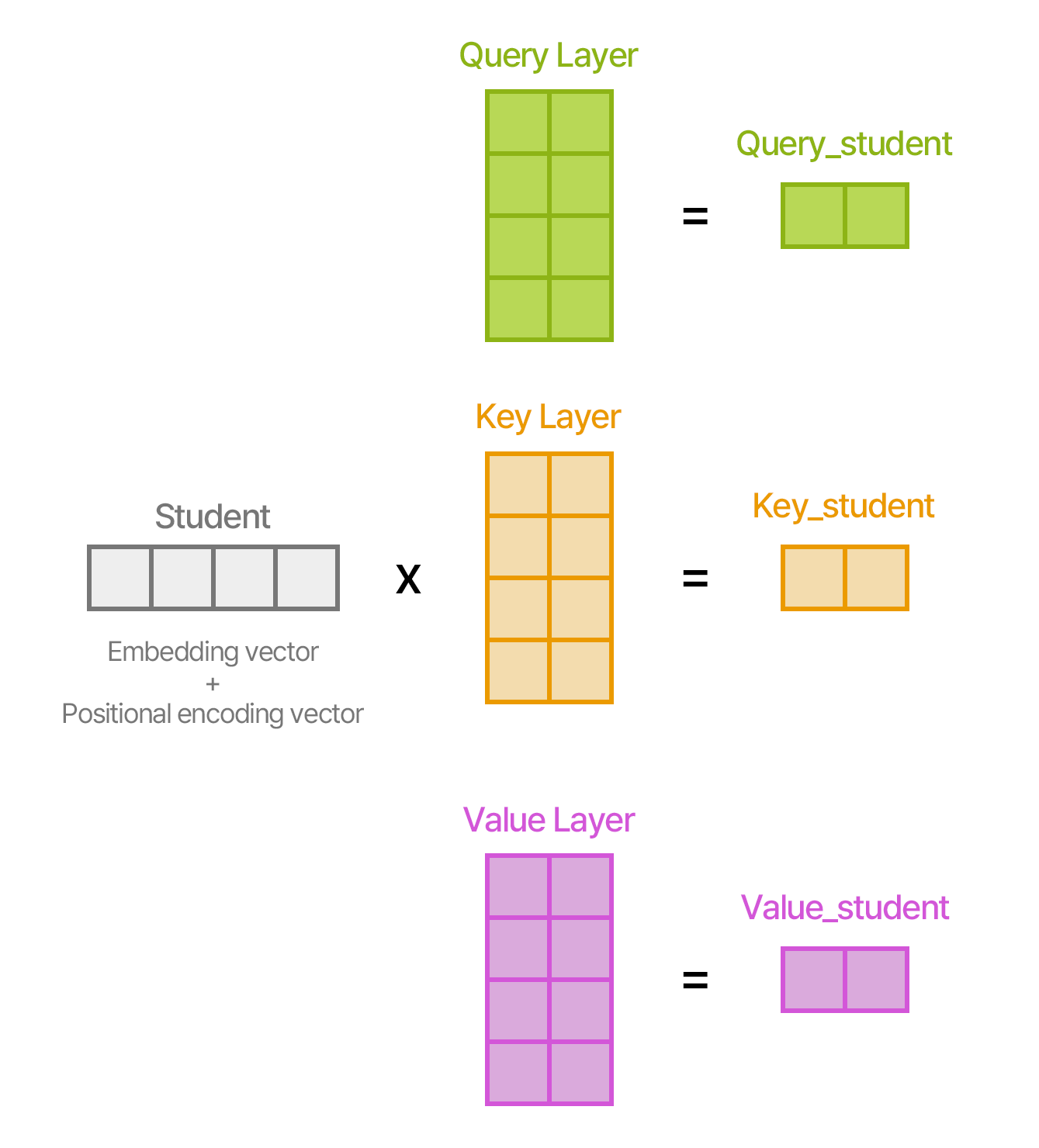
Student의 vector는 (1*4)
이 Embedding Vector를 Query, Key, Value Layer 에 집어넣어 준다.
Layer들은 (4*2).
여기서 행렬곱을 하면 (1*4) * (4*2) = (1*2) 크기의 Query_student 벡터, Key_student 벡터, Value_student 벡터를 출력하게 됩니다.
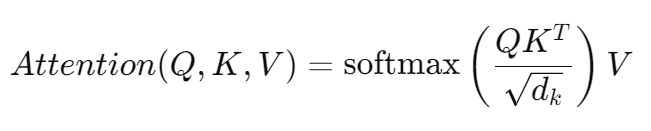
여기서 Key 의 값을 전치시킵니다.
그럼 Query (1*2) * Key (2*1) = (1*1) -> 결과값이 스칼라로 나온다 (Attention Score)
여기서 Attention Score를 √d_k로 나눠줍니다. 여기서 d는 size of embedding, 즉 임베딩 벡터 총 차원의 수 입니다.
- √( d_k )로 나누는 이유는 임베딩 차원이 클 때 내적 값이 지나치게 커지는 것을 방지하기 위해서입니다.
- 이를 통해 Attention 계산 시 Softmax가 과도하게 편향되는 것을 방지하고, 모델이 모든 단어에 균형 잡힌 주의를 기울일 수 있도록 돕습니다.
-> Attention은 단어와 단어 사이의 관계에 의해서 결정이 나야 하는 건데, 임베딩 차원이 너무 커버리면 값이 편향될 수 있습니다. 그래서 정규화해주는 것.
Query * Key 를 계산한 값은 스칼라인데, 연산하기 좋은 형태는 벡터입니다. 그렇게 만들어 주기 위해 Attention Score 와 Value (1*2)를 곱해주면 결국 (1*2)의 최종 결과값이 나오는데 이게 바로 Attention Value Matrix 입니다.
(Value는 그냥 값을 벡터로 조정해주는 역할)
Q_I, original = [1, 1, 1, 1] • W^Q = | 0 0 0 | Q_I = [1, 1, 1, 1]
| 1 1 1 |
| 0 0 0 |
K_I, original = [1, 1, 1, 1] • W^K = | 0 0 0 | K_I = [1, 0, 1, 1]
| 1 0 1 |
| 0 0 0 |
V_I, original = [1, 1, 1, 1] • W^V = | 0 0 0 | V_I = [1, 1, 1, 0]
| 1 1 1 |
| 0 0 0 |- 문장 내의 각각의 단어들에 대해 벡터들과 가중치 행렬을 곱하여 최종적으로 변환된 Query, Key, Value 벡터를 구하는 과정입니다.
- Q_I, K_I, V_I는 각각 Query, Key, Value 벡터이며, W^Q, W^K, W^V는 해당 벡터들에 곱해지는 가중치 행렬입니다.
모든 단어들에 대해 Query * Key 곱해서 Softmax 취했더니 아래와 같은 표가 나왔다고 하자.
아래에 대각선은 자기자신이니까 1.0으로 높게 나온다. 그건 당연한 것. 표에서 I 와 연관도가 제일 높은 단어: student
-> I랑 student랑 똑같은 애구나!
| | I | am | a | student |
|-------------|-------|------|-------|---------|
| **I** | 1.0 | 0.5 | 0.3 | 1.0 |
| **am** | 0.5 | 1.0 | 0.4 | 0.2 |
| **a** | 0.3 | 0.4 | 1.0 | 0.1 |
| **student** | 1.0 | 0.2 | 0.1 | 1.0 |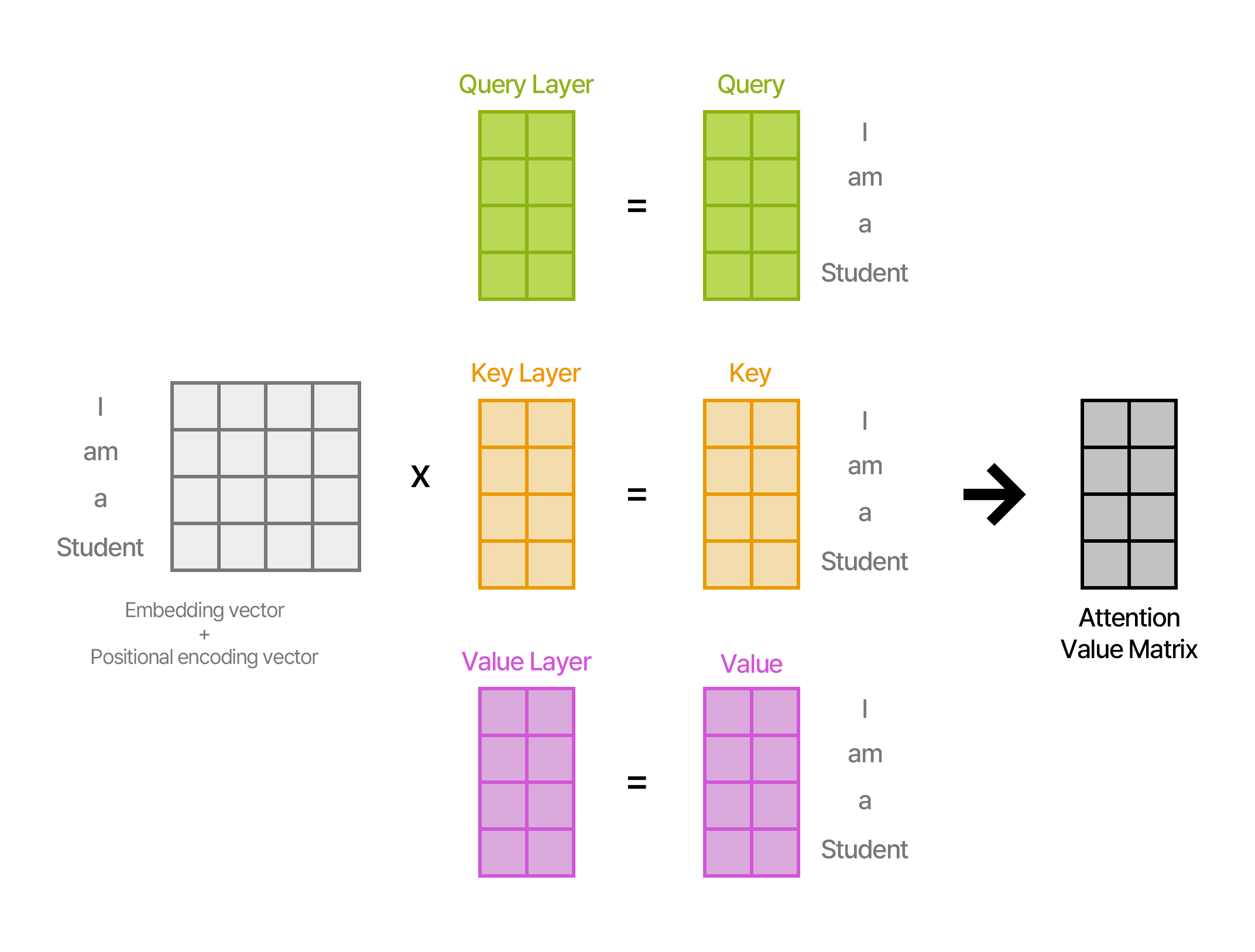
지금까지는 student 하나만 가지고 예시를 든 것이다.
하지만 실제로는 트랜스포머가 병렬이기 때문에, 그리고 계산속도도 더 빠르니까 문장을 통째로 넣는다.
I am a student (4*4)
Query Layer (4*2)
곱하면 (4*2)
결국 Attention Value Matrix 도 (4*2)가 된다.
Attention Value Matrix
Attention Value Matrix는 어텐션 메커니즘의 최종 출력입니다. 이 값은 주어진 Query와 Key를 기반으로 각 Value에 가중치를 부여하여 계산한 값입니다. 이를 단계별로 살펴보면 다음과 같은 과정을 거칩니다:
-
Query-Key 유사도 계산:
Query ( Q )와 Key ( K )의 내적(즉, ( QK^T ))을 통해 두 벡터 간의 유사도를 계산합니다. 이 유사도는 각 Query가 각 Key에 얼마나 주의를 기울여야 하는지(즉, 어느 정도의 중요도를 부여해야 하는지)를 나타냅니다. -
유사도 정규화:
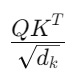 를 통해 Key 차원의 루트로 나누어 정규화를 해 줍니다. 이는 큰 차원의 벡터들이 내적 시 큰 값을 가지는 것을 방지하기 위한 조치입니다.
를 통해 Key 차원의 루트로 나누어 정규화를 해 줍니다. 이는 큰 차원의 벡터들이 내적 시 큰 값을 가지는 것을 방지하기 위한 조치입니다. -
Softmax 적용:
정규화된 유사도에 softmax 함수를 적용해 가중치를 구합니다. 이때 Softmax는 값들을 0에서 1 사이로 변환하며, 이 값들의 합은 1이 됩니다. 각 Query와 Key 간의 상호작용 정도를 확률 분포 형태로 표현한 것입니다. -
Value와의 가중합:
구한 가중치를 각 Value 벡터에 곱해 가중합을 계산합니다. 이때 Value ( V )는 정보를 담고 있는 데이터이고, Attention Score는 이 데이터를 얼마나 반영할지를 결정하는 역할을 합니다. 최종적으로는 아래와 같은 계산이 됩니다:
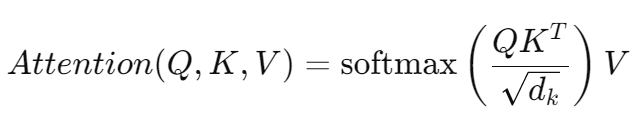
이 결과로 나온 행렬이 바로 Attention Value Matrix입니다.
요약:
Attention Value Matrix는 Query와 Key의 관계에 기반하여 Value에 가중치를 부여한 결과입니다. 이를 통해 모델은 입력 값에서 중요한 정보를 뽑아내어 최종 출력으로 내보냅니다. Attention Value Matrix는 특정 입력에 대해 다른 입력에 얼마나 주의를 기울여야 하는지를 반영하는 값입니다.
-
Student의 자기 자신에 대한 query, key, value 를 곱해줘서 다른 단어들 간의 관계를 figure out 했다 -> self attention
-
Self attention은 query, key, value에 같은 값들이 들어간다 (input 값이 똑같다). 하지만 Layer 값들 (가중치와 활성화 함수) 이 다르기 때문에 query, key, value layer의 결과값은 다르다.
추가 설명:
-
정규화: Attention Score에서 √d_k로 나누는 이유는 임베딩 차원이 클 경우 내적 값이 지나치게 커져서 Softmax 함수가 극단적인 값을 출력하지 않도록 하기 위함입니다. 이를 통해 모델이 모든 단어에 균형 잡힌 주의를 기울일 수 있게 합니다.
-
포지셔널 인코딩에서 삼각함수의 사용 이유: 삼각함수는 주기성을 갖고 있어, 긴 문장에서도 안정적으로 위치 정보를 표현할 수 있습니다. 차수가 커지면 수치적으로 매우 큰 값이나 작은 값이 발생하는 선형함수와 달리, sin, cos 함수는 일정 범위 내에서 값이 변동하기 때문에 안정적입니다.
--
참고 자료
https://www.youtube.com/watch?v=-z2oBUZfL2o&list=LL&index=18
https://www.youtube.com/watch?v=SR4F6WMqZ0s&list=LL&index=13
https://lilianweng.github.io/posts/2018-06-24-attention/
