Project4는 설날 명절도 겹치고 하다보니 운영체제 책을 통해 전체적인 File System의 흐름을 이해하고, Keywords에 해당하는 개념들을 공부하고, 그 다음으로 깃북을 읽으며 코드작성보다는 어떤 식으로 운영체제가 작동이 되는지 흐름 위주로 공부를 했다.
Project 4: File systems
- Keyword
Type of file system
- FAT(File Allocation Table)
- Berkley FFS
- EXT
File system component
- file
- extensible file
- directory
- working directory
- link
- hard link vs soft link
File system implementation
- sector & cluster
- super block
- disk inode
- in-memory inode
- open inode table
Buffer cache
filesystem mount
Journaling
- Introduction
앞의 두 가지 과제에서 파일 시스템이 어떻게 구현되었는지 실제로 걱정하지 않고 파일 시스템을 광범위하게 사용했습니다. 이 마지막 과제에서는 파일 시스템의 구현을 개선할 것입니다. 주로 filesys디렉토리에서 작업하게 됩니다.
프로젝트 2 또는 프로젝트 3 위에 프로젝트 4를 빌드할 수 있습니다. 두 경우 모두 프로젝트 2에 필요한 모든 기능이 파일 시스템 제출에서 작동해야 합니다. 프로젝트 3에서 빌드하는 경우 모든 프로젝트 3 기능도 작동해야 하며 VM 기능을 활성화하려면 filesys/Make.vars를 편집해야 합니다. VM을 비활성화하면 10% 크레딧(extra 포함)이 차감됩니다.
- Background
- New Code
다음은 아마도 새로운 파일입니다. 다음은 표시된 경우를 제외하고 filesys 디렉토리에 있습니다.
filesys/fsutil.c커널 명령줄에서 액세스할 수 있는 파일 시스템용 단순 유틸리티입니다.
include/filesys/filesys.h,filesys/filesys.c파일 시스템에 대한 최상위 인터페이스입니다. 자세한 내용은 파일 시스템 사용을 참조하십시오.
include/filesys/directory.h,filesys/directory.c파일 이름을 inode로 변환합니다. 디렉토리 데이터 구조는 파일로 저장됩니다.
include/filesys/inode.h,filesys/inode.c디스크에 있는 파일 데이터의 레이아웃을 나타내는 데이터 구조를 관리합니다.
include/filesys/fat.h,filesys/fat.cFAT 파일 시스템을 관리합니다.
include/filesys/file.h,filesys/file.c파일 읽기 및 쓰기를 디스크 섹터 읽기 및 쓰기로 변환합니다.
include/filesys/page_cache.h,filesys/page_cache.cVM 기능을 활용하는 페이지 캐시 구현입니다. 이 템플릿을 사용하는 것이 좋습니다. 그러나 자신의 코드를 기록할 수도 있습니다. vm 플래그를 끄면 이 템플릿을 사용할 수 없습니다.
include/lib/kernel/bitmap.h,lib/kernel/bitmap.c비트맵 데이터 구조와 디스크 파일에 비트맵을 읽고 쓰는 루틴입니다.
우리 파일 시스템은 유닉스와 유사한 인터페이스를 가지고 있으므로 , creat, open, close, read, write, lseek 및 unlink에 대한 유닉스 매뉴얼 페이지를 읽을 수도 있습니다. 우리 파일 시스템에는 이와 유사하지만 동일하지는 않은 호출들을 가지고 있습니다. 파일 시스템은 이러한 호출을 디스크 작업으로 변환합니다.
모든 기본 기능은 위의 코드에 있으므로 이전 두 프로젝트에서 본 것처럼 파일 시스템을 처음부터 사용할 수 있습니다. 그러나 제거해야 할 심각한 제한 사항이 있습니다.
대부분의 작업이 filesys 에 있는 동안, 모든 이전 부품과의 상호 작용에 대비해야 합니다.
- Testing File System Persistence
파일 시스템 지속성 테스트
지금까지 각 테스트는 Pintos를 한 번만 호출했습니다. 그러나 파일 시스템의 중요한 목적은 한 부팅에서 다른 부팅으로 데이터에 계속 액세스할 수 있도록 하는 것입니다. 따라서 파일 시스템 프로젝트의 일부인 테스트는 Pintos를 두 번째로 호출합니다. 두 번째 실행은 파일 시스템의 모든 파일과 디렉토리를 단일 파일로 결합한 다음 Pintos 파일 시스템에서 해당 파일을 호스트(Unix) 파일 시스템으로 복사합니다.
채점 스크립트는 두 번째 실행에서 복사된 파일의 내용을 기반으로 파일 시스템의 정확성을 확인합니다. 이것은 파일 시스템이 복사된 파일을 생성하는 Pintos 사용자 프로그램인 tar을 지원할 만큼 충분히 구현될 때까지 / 프로젝트가 확장 파일 시스템 테스트를 통과하지 않는다는 것을 의미합니다.
이 tar 프로그램은 상당히 까다롭기 때문에(확장 가능한 파일과 하위 디렉토리 지원이 모두 필요함), 약간의 작업이 필요합니다. 그때까지는 추출된 파일 시스템에 관한 make check오류를 무시할 수 있습니다.
덧붙여서, 당신이 짐작할 수 있듯이 파일 시스템 내용을 복사하는 데 사용되는 파일 형식은 표준 Unix "tar" 형식입니다. Unix tar 프로그램을 사용하여 검사할 수 있습니다. 테스트 t에 대한 tar 파일의 이름은 t.tar입니다.
- Indexed and Extensible Files
- Indexed and Extensible Files
인덱싱된 파일 및 확장 가능한 파일
기본 파일 시스템은 파일을 단일 익스텐트로 할당하므로 외부 단편화에 취약합니다. 즉, n개의 블록이 비어 있어도 n개의 블록 파일이 할당되지 않을 수 있습니다(외부 단편화). 디스크상의 inode 구조를 수정하여 이 문제를 제거하십시오.
실제로 이것은 직접, 간접 및 이중 간접 블록이 있는 인덱스 구조를 사용하는 것을 의미합니다.
이전 학기에 대부분의 학생들은 multi-level 인덱싱을 사용 하는 Berkeley UNIX FFS 로 배운 것과 같은 것을 채택했습니다. 그러나 당신의 삶을 더 쉽게 만들기 위해 우리는 당신이 그것을 더 쉽게 구현하도록 만듭니다: FAT.
주어진 스켈레톤 코드로 FAT를 구현해야 합니다. 귀하의 코드에는 multi-level indexing(강의의 FFS)을 위한 코드가 포함되어서는 안 됩니다. file growth 부분에 대해서는 0pt를 받게 됩니다.
참고: 파일 시스템 파티션이 8MB보다 크지 않을 것이라고 가정할 수 있습니다. 파티션만큼 큰 파일을 지원해야 합니다(메타데이터 제외).
각 inode는 하나의 디스크 섹터에 저장되어 포함할 수 있는 블록 포인터의 수를 제한합니다.
- Indexing large files with FAT (File Allocation Table)
FAT(파일 할당 테이블)로 대용량 파일 인덱싱
경고: 이 문서는 강의에서 일반 파일 시스템과 FAT의 기본 원리를 이미 이해했다고 가정합니다. 그렇지 않다면 강의 노트로 돌아가서 파일 시스템과 FAT가 무엇인지 이해하십시오.
이전 프로젝트에서 사용한 기본 파일 시스템에서 파일은 여러 디스크 섹터에 연속적인 단일 청크로 저장되었습니다. 클러스터(청크)는 하나 이상의 연속 디스크 섹터를 포함할 수 있으므로 인접(연속) 청크 를 클러스터 라고 합시다. 이 관점에서 보면 기본 파일 시스템에서 클러스터의 크기는 클러스터에 저장된 파일의 크기와 같다.
외부 단편화를 완화하기 위해 클러스터의 크기를 줄일 수 있습니다(가상 메모리의 페이지 크기 불러오기). 단순화를 위해 스켈레톤 코드에서 클러스터의 섹터 수를 1로 고정했습니다. 이와 같은 더 작은 클러스터를 사용할 때 클러스터는 전체 파일을 저장하기에 충분하지 않을 수 있습니다. 이 경우 파일에 대해 여러 클러스터가 필요하므로, inode에 있는 파일에 대한 클러스터를 인덱싱하는 데이터 구조가 필요합니다.
가장 쉬운 방법 중 하나는 linked-list(일명 체인). inode는 파일의 첫 번째 블록의 섹터 번호를 포함할 수 있고 첫 번째 블록은 두 번째 블록의 섹터 번호를 포함할 수 있습니다. 그러나 이 순진한 접근 방식은 파일의 모든 블록을 읽어야 하기 때문에 너무 느립니다. 실제로 필요한 것은 마지막 블록뿐입니다.
이를 극복하기 위해 FAT(File Allocation Table)는 블록 자체가 아닌 고정된 크기의 파일 할당 테이블에 블록의 연결성을 넣습니다. FAT는 실제 데이터가 아닌 연결 값만 포함하기 때문에 그 크기가 DRAM에 캐시될 만큼 작습니다. 결과적으로 테이블에서 해당 항목을 읽을 수 있습니다.
filesys/fat.c에 제공된 스켈레톤 코드를 사용하여 inode 인덱싱을 구현합니다. 이 섹션에서는 fat.c에 이미 구현된 기능과 구현해야 하는 기능에 대해 간략하게 설명합니다.
먼저 fat.c의 6가지 기능(즉 fat_init(), fat_open(), fat_close(), fat_create(), 및 fat_boot_create())은 부팅 시 디스크를 초기화하고 포맷하므로 수정할 필요가 없습니다. 그러나 fat_fs_init()을 작성해야 하며, 이 기능이 무엇을 하는지 간략하게 이해하면 도움이 될 수 있습니다.
- 구현1.
cluster_t fat_fs_init (void);FAT 파일 시스템을 초기화합니다.
fat_fs의fat_length와data_start필드를 초기화해야합니다.fat_length는 파일 시스템과data_start에서 얼마나 많은 클러스터가 있는지 저장하고, 파일 저장을 시작할 수 있는 섹터를 저장합니다.fat_fs->bs에 저장된 일부 값을 악용할 수 있습니다. 또한 이 함수에서 다른 유용한 데이터를 초기화할 수 있습니다.
- 코드
- 구현2.
cluster_t fat_create_chain (cluster_t clst);
clst(클러스터 인덱싱 번호)에 지정된 클러스터 뒤에 클러스터를 추가하여 체인을 확장합니다 .
만약clst가 0이면, 새 체인을 만듭니다. 새로 할당된 클러스터의 클러스터 번호를 반환합니다.
- 코드
- 구현3.
void fat_remove_chain (cluster_t clst, cluster_t pclst);
clst에서 시작하여 체인에서 클러스터를 제거합니다.pclst는 체인의 직접 이전 클러스터여야 합니다. 즉, 이 함수를 실행한 후,pclst는 업데이트된 체인의 마지막 요소가 되어야 합니다.clst가 체인의 첫 번째 요소인 경우,pclst는 0이어야 합니다.
- 코드
- 구현4.
void fat_put (cluster_t clst, cluster_t val);클러스터 번호
clst가 가리키는 FAT 항목을val로 업데이트하십시오. FAT의 각 항목(entry)은 체인의 다음 클러스터를 가리키기 때문에(존재하는 경우; 그렇지 않은 경우 :EOChain), 연결을 업데이트하는 데 사용할 수 있습니다.
- 코드
- 구현5.
cluster_t fat_get (cluster_t clst);주어진 클러스터가 가리키는 클러스터
clst번호를 반환합니다.
- 코드
- 구현6.
disk_sector_t cluster_to_sector (cluster_t clst);클러스터 번호
clst를 해당 섹터 번호로 변환하고 섹터 번호를 반환합니다.
- 코드
filesys.c와 inode.c에서 이러한 함수를 이용하여 기본 파일 시스템을 확장할 수 있습니다.
- File Growth
확장 가능한 파일(extensible files)을 구현합니다. 기본 파일 시스템에서는 파일이 생성될 때 파일 크기가 지정됩니다. 그러나 대부분의 최신 파일 시스템에서 파일은 처음에 크기 0으로 생성되고 파일 끝에서 쓰기가 이루어질 때마다 확장됩니다. 파일 시스템에서 이를 허용해야 합니다.
파일이 파일 시스템의 크기(메타데이터 제외)를 초과할 수 없다는 점을 제외하고 파일 크기에는 미리 정해진 제한이 없어야 합니다. 이것은 루트 디렉토리 파일에도 적용되며, 이제 초기 제한인 16개 파일을 초과하여 확장할 수 있어야 합니다.
사용자 프로그램은 현재 EOF(파일 끝)를 넘어 탐색(seek)할 수 있습니다. 탐색 자체는 파일을 확장하지 않습니다.
EOF를 지난 위치에서 쓰면 파일이 기록 중인 위치로 확장되며, 이전 EOF와 쓰기의 시작 사이의 간격들은 0으로 채워져야 합니다. EOF 이후의 위치(a position past EOF)에서 시작하는 읽기는 바이트를 반환하지 않습니다.
EOF를 훨씬 넘어서 작성하면 많은 블록이 전부 0이 될 수 있습니다. 일부 파일 시스템은 이러한 암시적으로 0인 블록에 대해 실제 데이터 블록을 할당하고 씁니다. 다른 파일 시스템은 명시적으로 기록될 때까지 이러한 블록을 전혀 할당하지 않습니다. 후자의 파일 시스템은 "희소 파일(sparse files)"을 지원한다고 합니다. 우리는 파일 시스템에서 두 할당 전략 중 하나를 채택할 수 있습니다.
- Subdirectories and Soft Links
- Subdirectories
하위 디렉토리
계층적 이름 공간을 구현합니다. 기본 파일 시스템에서 모든 파일은 단일 디렉토리에 있습니다.
디렉토리 항목이 파일이나 다른 디렉토리를 가리킬 수 있도록 수정하십시오.
디렉토리가 다른 파일과 마찬가지로 원래 크기 이상으로 확장될 수 있는지 확인하십시오.
기본 파일 시스템은 파일 이름에 14자 제한이 있습니다. 개별 파일 이름 구성 요소에 대해 이 제한을 유지하거나 선택에 따라 확장할 수 있습니다. 전체 경로 이름은 14자보다 훨씬 길어야 합니다.
각 프로세스에 대해 별도의 현재 디렉토리를 유지하십시오. 시작할 때 루트를 초기 프로세스의 현재 디렉터리로 설정합니다.
한 프로세스가 fork 시스템콜로 다른 프로세스를 시작하면, 자식 프로세스는 부모의 현재 디렉터리를 상속합니다.
그 후 두 프로세스의 현재 디렉토리는 독립적이므로 자신의 현재 디렉토리를 변경해도 다른 프로세스에는 영향을 미치지 않습니다. (이것이 유닉스에서 cd 명령이 외부 프로그램이 아닌 내장 쉘인 이유입니다.)
호출자가 파일 이름을 제공하는 모든 위치에서 / 절대 또는 상대 경로 이름을 사용할 수 있도록 / 기존 시스템콜을 업데이트하십시오. 디렉토리 구분 문자는 슬래시('/')입니다. Unix에서와 동일한 의미를 갖는 특수 파일 이름 '.' 및 '..'도 지원해야 합니다.
디렉토리도 열 수 있도록 시스템 호출 open을 업데이트하십시오.
기존 시스템 호출 중 닫기만 디렉토리에 대한 파일 설명자(file descriptor)를 수락하면 됩니다.
일반 파일 외에 빈 디렉터리(루트 제외)를 삭제할 수 있도록 시스템 호출 remove를 업데이트 합니다.
디렉토리는 파일이나 하위 디렉토리('.' 및 '..' 제외)를 포함하지 않는 경우에만 삭제할 수 있습니다. 프로세스에 의해 열려 있는 디렉토리의 삭제를 허용할지 또는 프로세스의 현재 작업 디렉토리로 사용할지 결정할 수 있습니다. 허용되는 경우, 파일('.' 및 '..' 포함)을 열거나 삭제된 디렉터리에 새 파일을 만들려는 시도는 허용되지 않아야 합니다. 다음과 같은 새 시스템 호출을 구현합니다.
- 구현1.
bool chdir (const char *dir);프로세스의 현재 작업 디렉터리를 상대 또는 절대 디렉터리로 변경합니다. 성공하면 true를, 실패하면 false를 반환합니다.
- 코드
- 구현2.
bool mkdir (const char *dir);상대 또는 절대일 수 있는 dir이라는 디렉터리를 만듭니다. 성공하면 true를, 실패하면 false를 반환합니다. dir이 이미 존재하거나 dir의 마지막 이름 외에 디렉토리 이름이 이미 존재하지 않는 경우(?) 실패합니다. 즉,
mkdir("/a/b/c")는/a/b가 이미 존재하고,/a/b/c가 존재 하지 않는 경우에만 성공합니다.
- 코드
- 구현3.
bool readdir (int fd, char *name);디렉토리를 나타내야 하는 파일 설명자인 fd에서 디렉토리 항목(directory entry)을 읽습니다. 만약 성공하면,
READDIR_MAX_LEN + 1만큼의 바이트 공간을 가진(가져야 하는) name에 / null로 끝나는 파일 이름을 저장하고, true를 반환합니다. 디렉토리에 항목이 남아 있지 않으면 false를 반환합니다.. 및 .. 이
readdir에 의해 반환되어서는 안 됩니다. 디렉토리가 열려 있는 동안 변경된 경우, 일부 항목은 전혀 읽지 않거나, 여러 번 읽는 것이 허용됩니다.
그렇지 않으면 각 디렉토리 항목은 순서에 관계없이 한 번만 읽어야 합니다.
READDIR_MAX_LEN은lib/user/syscall.h에 정의되어 있습니다.
파일 시스템이 기본 파일 시스템보다 긴 파일 이름을 지원하는 경우, 이 값을 기본값인 14에서 늘려야 합니다.
- 코드
- 구현4.
bool isdir (int fd);fd가 디렉토리를 나타내는 경우 true를 반환하고, 일반 파일을 나타내는 경우 false를 반환합니다.
- 코드
- 구현5.
int inumber (int fd);일반 파일이나 디렉토리를 나타낼 수 있는 fd와 관련된 inode의 inode number를 반환합니다.
inode number는 파일이나 디렉토리를 지속적으로 식별합니다. 파일이 존재하는 동안 고유합니다. Pintos에서 inode의 섹터 번호는 inode 번호로 사용하기에 적합합니다.
- 코드
- Soft Link
소프트링크
핀토스에서 소프트 링크 메커니즘을 구현합니다. 소프트 링크(일명 심볼릭 링크)는 다른 파일이나 디렉토리를 참조하는 의사(pseudo) 파일 객체입니다.
이 파일은 절대경로나 상대경로로 가리키는 파일의 경로 정보를 담고 있습니다. 다음과 같은 상황을 가정해 봅시다.
/
├── a
│ ├── link1 -> /file
│ │
│ └── link2 -> ../file
└── file소프트 링크는 /a points /file에 link1로 명명되었고(절대 경로로),
/a points ../file 에 link2라는 이름을 붙였습니다.(상대 경로로).
link1 또는 link2 파일을 읽는 것은 /file을 읽는 것과 같습니다.
- 구현
int symlink (const char *target, const char *linkpath);문자열(string) target을 포함하는 linkpath라는 심볼릭 링크를 만듭니다. 성공하면 0이 반환됩니다. 그렇지 않으면 -1이 반환됩니다.
- 코드
- Buffer Cache
- Buffer Cache
버퍼 캐시
파일 블록의 캐시를 유지하도록 파일 시스템을 수정합니다. 블록을 읽거나 쓰도록 요청하면 캐시에 있는지 확인하고, 그렇다면 디스크로 이동하지 않고 캐시된 데이터를 사용합니다.
그렇지 않으면 디스크에서 캐시로 블록을 가져와 필요한 경우 이전 항목을 제거합니다. 크기가 64섹터 이하인 캐시로 제한됩니다.
최소한 "clock" 알고리즘만큼 우수한 캐시 교체 알고리즘을 구현해야 합니다. 일반적으로 데이터에 비해 메타데이터의 가치가 더 크다는 점을 고려하시기 바랍니다.
디스크 액세스 수로 측정했을 때 액세스된 정보, 더티 정보 및 기타 정보의 어떤 조합이 최상의 성능을 내는지 실험해 보십시오.
원하는 경우 free map의 캐시된 복사본(cached copy)을 메모리에 영구적으로 보관할 수 있습니다. 캐시 크기에 대해 계산할 필요가 없습니다.
제공된 inode 코드는 디스크의 섹터별 인터페이스를 시스템콜 인터페이스의 바이트별 인터페이스로 변환하기 위해 malloc() 으로 할당된 "바운스 버퍼"를 사용합니다.
이러한 바운스 버퍼를 제거해야 합니다. 대신 버퍼 캐시의 섹터 안팎으로 데이터를 직접 복사하십시오.
캐시는 수정된 데이터를 디스크에 즉시 쓰는 대신, 쓰기 뒤에 기록해야 합니다. 즉, 캐시에 더티 블록을 유지해야 합니다.
제거될 때마다 더티 블록을 디스크에 씁니다. write-behind는 충돌에 직면하여 파일 시스템을 더 취약하게 만들기 때문에, 추가로 모든 dirty, cached 블록을 디스크에 주기적으로 다시 써야 합니다. 캐시는 또한 filesys_done()으로 디스크에 다시 기록되어야 하며, 핀토스를 중지하면 캐시가 플러시된다.
첫 번째 프로젝트의 timer_sleep()가 작동하는 경우, write-behind는 훌륭한 응용 프로그램입니다. 그렇지 않으면 덜 일반적인 기능을 구현할 수 있지만, busy-waiting를 표시하지 않는지 확인하십시오.
또한 미리 읽기(read-ahead)를 구현해야 합니다.
즉, 파일의 한 블록을 읽을 때 파일의 다음 블록을 캐시로 자동으로 가져와야 합니다.
read-ahead는 비동기식으로 수행될 때만 정말 유용합니다. 즉, 프로세스가 파일에서 디스크 블록1을 요청하면 디스크 블록 1을 읽을 때까지 차단해야 하지만, 해당 읽기가 완료되면 제어(control)가 즉시 프로세스에 반환되어야 합니다.
디스크 블록2에 대한 미리 읽기 요청은 백그라운드에서 비동기적으로 처리되어야 합니다.
이렇게 하려면 IO에 대한 전용 스레드를 만들어야 할 수도 있습니다. 디스크 IO가 필요할 때 스레드는 요청을 전용 요청으로 전달합니다.
- Hint for implementation
구현 힌트
Linux처럼 가상 메모리 하위 시스템을 통해 이 기능을 구현할 수 있습니다.
새로운 vm 유형을 도입할 수 있습니다.(예: "pagecache") 및 swap_in, swap_out및 destroy 인터페이스를 통해 버퍼 캐시를 관리할 수 있습니다.
이 디자인을 선택하면 SECTOR_SIZE 단위가 아닌 PAGE_SIZE 단위로 캐시를 관리할 수 있습니다.
파일 백업 페이지의 동기화 문제의 경우 mmaped 영역을 캐시로 사용할 수 있습니다.
캐시를 초기 디자인에 통합하는 것이 좋습니다. 과거에는 많은 그룹이 디자인 프로세스 후반부에 가서 캐시를 디자인에 추가하려고 시도했습니다. 이것은 매우 어렵습니다. 이 그룹은 대부분 또는 모든 테스트에 실패한 프로젝트를 제출한 경우가 많습니다.
- Synchronization
동기화
제공된 파일 시스템에는 외부 동기화가 필요합니다. 즉, 호출자는 파일 시스템 코드에서 한 번에 하나의 스레드만 실행할 수 있는지 확인해야 합니다.
제출물은 외부 동기화가 필요없는 세분화된 동기화 전략을 채택해야 합니다.
가능한 한 독립적인 독립체들(entities)에 대한 작업은 서로를 기다릴 필요가 없도록 독립적이어야 합니다.
다른 캐시 블록에 대한 작업은 독립적이어야 합니다. 특히 특정 블록에 I/O가 필요한 경우 I/O가 완료될 때까지 기다리지 않고 I/O가 필요하지 않은 다른 블록에 대한 작업을 진행해야 합니다.
여러 프로세스가 한 번에 단일 파일에 액세스할 수 있어야 합니다.
단일 파일에 대한 다중 읽기는 서로를 기다리지 않고 완료할 수 있어야 합니다.
파일에 쓰더라도 파일이 확장되지 않으면 여러 프로세스에서 한 번에 하나의 파일을 쓸 수 있어야 합니다. 파일이 다른 프로세스에 의해 쓰여지고 있을 때, 한 프로세스가 파일을 읽는 것은 쓰기의 전부 또는 일부가 완료되지 않았음을 나타내기 위해 허용됩니다. (그러나 write 시스템 호출이 호출자에게 반환된 후, 모든 후속 독자(subsequent readers)는 변경 사항을 확인해야 합니다.)
마찬가지로 두 프로세스가 동시에 파일의 동일한 부분에 쓸 때 데이터가 끼어들기(be interleaved)될 수 있습니다.
반면에 파일을 확장하고 새 섹션에 데이터를 쓰는 것은 원자적(atomic)이어야 합니다.
프로세스 A와 B 모두에 주어진 파일이 열려 있고, 둘 다 파일 끝에 위치한다고 가정합니다.
A가 파일을 읽고 B가 동시에 파일을 쓰는 경우, A는 B가 쓰는 것의 전부 또는 일부를 읽거나 전혀 읽지 않을 수 있습니다. 그러나 A는 B가 쓰는 것 이외의 데이터를 읽을 수 없습니다. 예를 들어 B의 데이터가 모두 0이 아닌 바이트인 경우, A는 0을 볼 수 없습니다.
다른 디렉토리에 대한 작업은 동시에 이루어져야 합니다. 동일한 디렉토리에 대한 작업이 서로 대기할 수 있습니다.
여러 스레드에서 공유하는 데이터만 동기화해야 합니다. 기본 파일 시스템의 struct file과 struct dir만 단일스레드에 의해 액세스됩니다.
- Mount (Extra)
- Filesystem Journaling (Extra)
FAT(File Allocation Table)
컴퓨터 파일 시스템 구조 중 하나이다. 상대적으로 간단해 플로피 디스크와 같은 휴대용 기기들에서 자주 볼 수 있다.
기본적인 아이디어는 파일의 데이터를 여러 개의 링크드 리스트 블록들로 나누는 것에 있다. 디렉터리 구조에는 파일의 첫 데이터 블록의 시작 주소만 놔두고, 각각의 데이터 블록에 같은 파일의 그 다음 데이터 블록의 주소를 저장해 놓는 식이다.
링크드 리스트 형태로 파일의 데이터 블록을 관리하는 것의 단점은, 내가 어떤 특정한 데이터 블록에 접근하기 위해서는 그 앞의 데이터 블록부터 훑어야 한다는 것이다. 그렇기 때문에 디스크를 Random Access하는 데에는 좋지 않다.
Random Access & Sequential Access
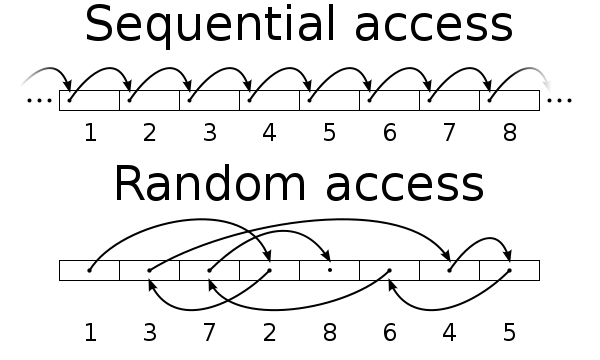
Sequential하게 디스크의 데이터에 접근하는 것이 Random하게 접근하는 것보다 더 빠르다. 디스크 I/O 시간 중에 탐색SEEK 시간(알맞은 트랙으로 디스크 암이 위치하는 데까지 걸리는 시간)이 가장 오래 걸리는 경우가 많다. Random하게 디스크에 접근한다는 것은 Sequential하게 디스크에 접근하는 것보다 더 많은 트랙들을 왔다갔다 해야 하므로, 디스크의 THROUGHPUT(시간당 처리량)이 낮아지게 된다.
따라서 각 데이터 블록에 대한 정보를 테이블 형태로 만들어 관리하는 방안을 생각해 냈다.
💡 빈 sector들을 찾아 데이터를 기록한 뒤, 파일들이 연결된 정보를 File Allocation Table에 기록해 놓는다. 이 FAT를 메모리에 올려서 사용한다.
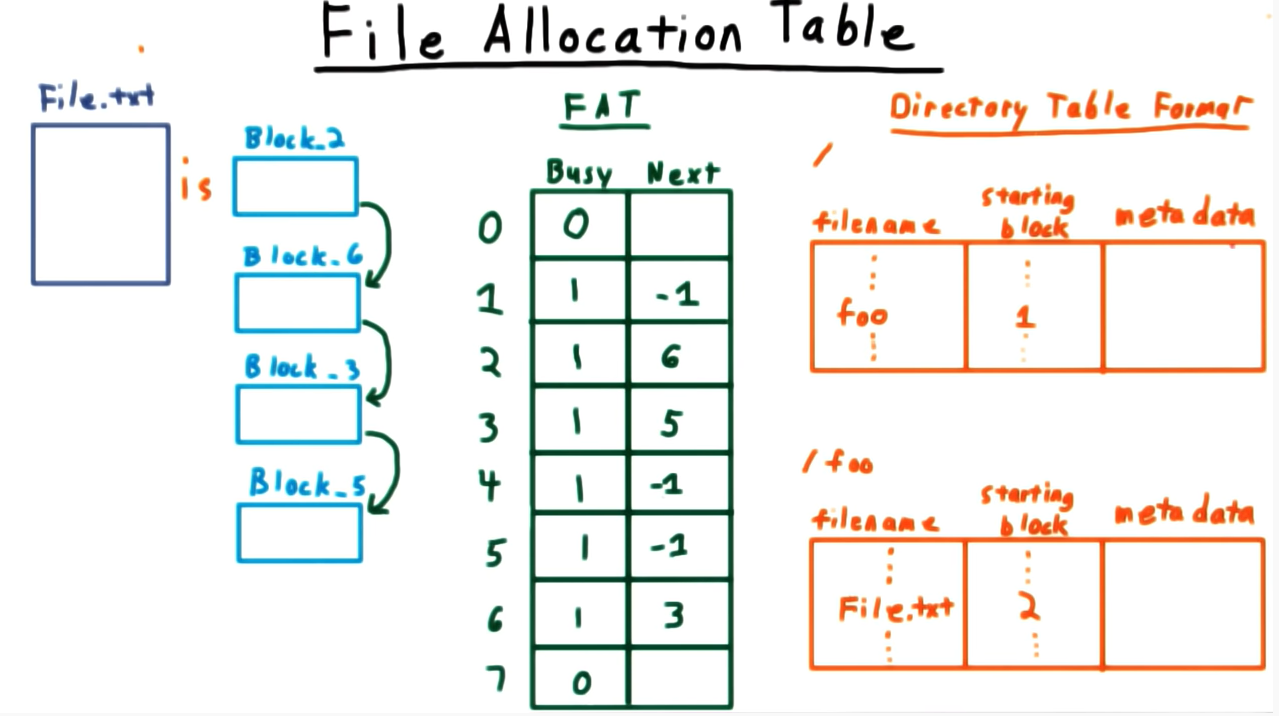
우선 Directory Table을 통해 해당 디렉토리 안의 파일 각각의 시작 데이터 블록 주소를 저장한다. 그 후 File Allocation Table에 디스크의 클러스터들을 인덱스로 해서 각각의 섹터에 저장된 파일 데이터 블록들의 정보를 나타낸다. FAT에 담긴 정보들은 해당 섹터가 사용중인지 여부와 다음 데이터 블록의 주소 등이 있다.
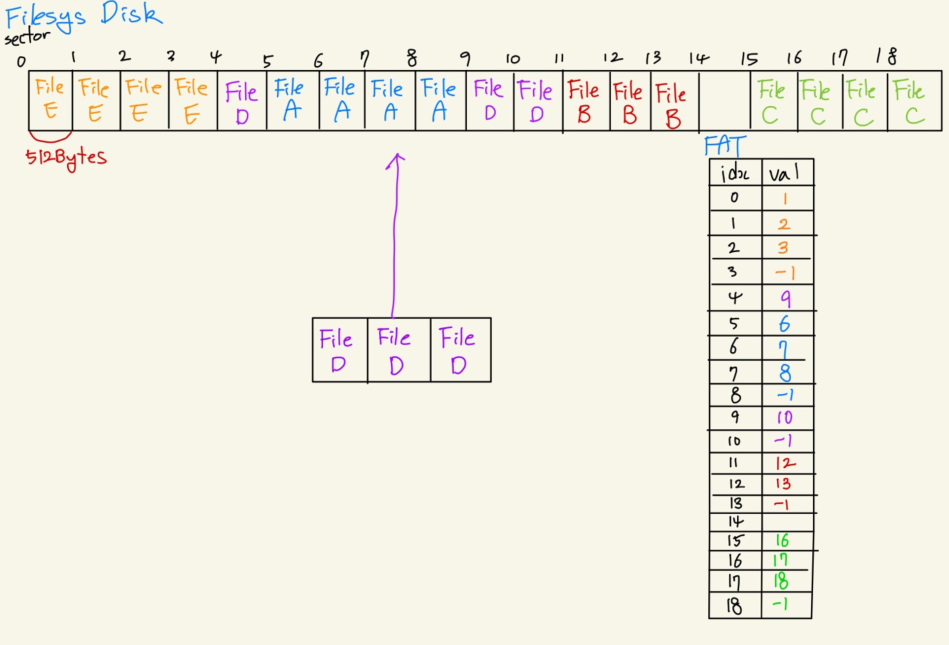 참고 : https://one-step-a-day.tistory.com/133
참고 : https://one-step-a-day.tistory.com/133
파일 D를 예로 들자면, 섹터 4, 9, 10에 나뉘어서 저장되어 있다. 이 때 FAT[4], FAT[9], FAT[10]에 파일 D의 정보들이 나뉘어 들어가 있는 것을 확인할 수 있다. 이 때 각 파일의 마지막 섹터에는 -1이나 NULL 등의 구분될 수 있는 데이터를 집어넣어 다음 데이터 블록이 없다는 것을 알려준다.
FAT 자체도 메모리에 올려서 사용하지만, 기본적으로 디스크에 저장되어 있다. 디스크의 맨 처음 섹터인 sector 0에 저장된다. 때문에 컴퓨터를 끄고 다시 켤 때에도 파일들에 대한 저장 정보가 남아있을 수 있다.
장점과 단점
장점
- 새로운 파일을 만들기가 쉽다. 부모 디렉토리 테이블과 FAT의 Busy 필드 내용만 수정하면 된다.
- 파일의 크기를 키우는 것도 쉽다. FAT의 Next 필드만 수정해주면 된다.
- 공간 활용성도 높아진다. 파일을 섹터 단위로 쪼개어 활용할 수 있어서 외부 단편화를 예방할 수 있다.
- 막 그렇게 빠르진 않더라도 Random Access가 가능하다.
단점
- 모든 디스크 블록들이 각각 하나의 FAT 항목을 가지고 있으므로, 만약 굉장히 용량이 큰 디스크의 경우에는 FAT의 크기도 굉장히 커질 수 있다.
- 이를 막기 위해서 블록 하나의 크기를 키울 수 있지만, 그렇게 되면 내부 단편화가 심해질 수 있다.
[출처 : 최고 도경 노션]
