팀원과 파트를 배분.
로그인
- 로그인확장(회원가입)
- PW 중복방지
- PW 암호화
메인
- 비추천, 랭크(정렬)
- 기본 음식조합 제공
나도추가하기
- 음식 DB 만들기
- 이미지 가져오기
나는 3번째를 담당하기로 함.
크롤링을 통해 음식 이름(키워드)에 대한 db를 만들고,
이미지 url을 함께 저장하기로.
크롤링코드 저장
크롤링된 텍스트도 저장
음식재료가 아닌 것 제거
이미지url 보내기까지
깃허브 메모
로컬
로컬을 먼저 하고 동기화를 한 다음에 풀을 올려
로컬저장소 : 내컴터에서 작업
깃허브저장소 : 공유 < 에서 클론을 해서
클론, 풀, 푸시
클론 을 해서 그대로 갖고와//클론은 맨처음에 저장소 가져올때만
개인은 풀을 자주 함.
누가 푸쉬하면 충돌 가능성
클론하기전에 풀을 해서 내 로컬에서 싱크를 맞추고
커밋
커밋 하기 전에 애드 먼저
깃워크플로우에서
커밋이 현재 상황을 저장하는 느낌
커밋을 하면 내 로컬 래퍼스토리에 그 사진이 저장됨
애드, 커밋
애드랑 커밋은 내 로컬에서 일어나는 일
애드-커밋-> 리모트(공용) 받을때 풀 넘길때 푸시
클론 하는 법
내 컴퓨터로 가져오는 과정
깃배쉬 켜기, 깃허브 로그인
cd '/c/Users/LG/Desktop/Jungle/WEEK 0'
(저장하고싶은 폴더 경로)
참고 ls << 폴더 내 파일 보기
git clone 깃허브 https~.git 코드
기타메모
세션은 로그인을 유지시켜줌
브랜치
공동작업시 메인파일의 사본 만들어서 개인 작업 가능
git branch → 끝에(main) 뜸
$ git checkout -b yerim : -b 는 branch가 없을 경우 새로 생성해서 들어가겠다는 의미 yerim은 파일이름
(main)이 (yerim)으로 바뀜
끝
크롤링
soup.select("title") 👈 태그로 찾기
soup.select("p:nth-of-type(3)") 👈 p태그로 된 3번째 자식
soup.select("body a") 👈 body태그 안에 있는 모든 a태그
soup.select(".sister") 👈 클래스명이 sister인 태그
출처 : https://velog.io/@banana/파이썬으로-텍스트-및-이미지-크롤링하기
작업) 여러페이지 크롤링 - DB
import requests
from bs4 import BeautifulSoup
pageNum = 1
baseUrl1 = f'https://terms.naver.com/list.naver?cid=48158&categoryId=48158&viewType=&categoryType='
baseUrl2 = '&page='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
for i in range(3):
newUrl = baseUrl1 + baseUrl2 + str(pageNum)
data = requests.get(newUrl, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
foods = soup.select('#content > div.list_wrap > ul > li')
for food in foods:
a_tag = food.select_one('div.info_area > div.subject > strong > a').text
pageNum += 1
name = a_tag.split()
print(name)pageNum = 1
baseUrl1 = f'https://terms.naver.com/list.naver?cid=48158&categoryId=48158&viewType=&categoryType='
baseUrl2 = '&page='
본 url과 page부분을 baseUrl1,2로 나눠 여러 페이지를 크롤링 하기로 함
이 과정에서 pageNum에 문자열적용을 해주지 않으니 오류가 났음.
str 적용 후 더하는 방법을 통해 baseUrl1+2를 합쳐 newUrl로 최종 url을 생성함
for i in range(3):
newUrl = baseUrl1 + baseUrl2 + str(pageNum)
data = requests.get(newUrl, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
foods = soup.select('#content > div.list_wrap > ul > li')
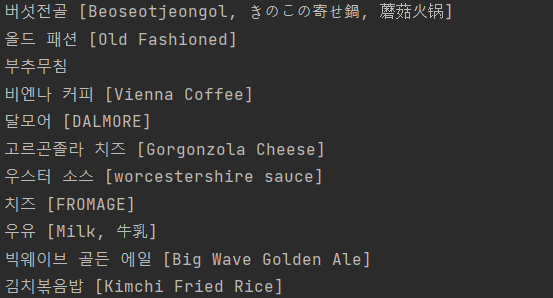
👆 결과물
for food in foods:
a_tag = food.select_one('div.info_area > div.subject > strong > a').text.replace(' ','').replace('[',' ')
pageNum += 1
name = a_tag.split(' ')
print(name)👆 이하에 있는 또 다른 for문.
음식 이름 뒤에 외국어로 번역된 이름이 같이 붙어 분류작업이 필요했음
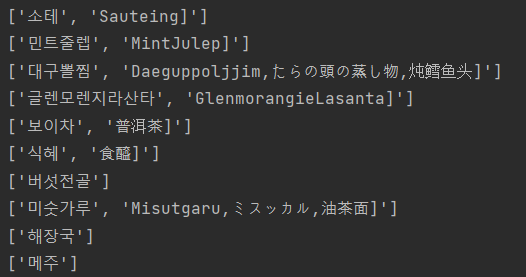
replace(' ','').replace('[',' ')
특수문자는 split('\\[') 처럼 \\ 두개를 붙이면 된다고 하던데
난 적용이 안돼서 [을 공백으로 바꾸는 방법을 생각했다.
name = a_tag.split(' ')
그 후 공백 기준으로 나누기.
for food in foods:
a_tag = food.select_one('div.info_area > div.subject > strong > a').text.replace(' ','').replace('[',' ')
pageNum += 1
name = a_tag.split(' ')
print(name[0])print(name[0])
나누어져 list가 만들어진 상태에서 0번째를 출력하니 정상적으로 음식 이름만 출력되었다.

👆 결과물
이미지 url
imageUrl = food.select_one('div.thumb_area > div.thumb > a > img')['data-src']
이미지 url 가져오기 완료.
1차 완성
import requests
from bs4 import BeautifulSoup
pageNum = 1
baseUrl1 = f'https://terms.naver.com/list.naver?cid=48158&categoryId=48158&viewType=&categoryType='
baseUrl2 = '&page='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
for i in range(3):
newUrl = baseUrl1 + baseUrl2 + str(pageNum)
data = requests.get(newUrl, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
foods = soup.select('#content > div.list_wrap > ul > li')
for food in foods:
a_tag = food.select_one('div.info_area > div.subject > strong > a').text.replace(' ','').replace('[',' ')
imageUrl = food.select_one('div.thumb_area > div.thumb > a > img')['data-src']
pageNum += 1
name = a_tag.split(' ')
print(name[0],imageUrl)
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
from flask import Flask, render_template, jsonify, request
app = Flask(__name__)
client = MongoClient('localhost', 27017)
db = client.swJungle
pageNum = 1
baseUrl1 = f'https://terms.naver.com/list.naver?cid=48158&categoryId=48158&viewType=&categoryType='
baseUrl2 = '&page='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
for i in range(920):
newUrl = baseUrl1 + baseUrl2 + str(pageNum)
data = requests.get(newUrl, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
foods = soup.select('#content > div.list_wrap > ul > li')
for food in foods:
a_tag = food.select_one('div.info_area > div.subject > strong > a').text.replace(' ', '').replace('[', ' ')
imageUrl = food.select_one('div.thumb_area > div.thumb > a > img')['data-src']
pageNum += 1
name = a_tag.split(' ')
print(name[0],imageUrl)
##db에 저장 추가하기!~!!
# # 출처 url로부터 영화인들의 사진, 이름, 최근작 정보를 가져오고 mystar 콜렉션에 저장합니다.
#
# def insert_imageUrl(url):
# pageNum = 1
# baseUrl1 = f'https://terms.naver.com/list.naver?cid=48158&categoryId=48158&viewType=&categoryType='
# baseUrl2 = '&page='
#
# headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# data = requests.get(url, headers=headers)
# soup = BeautifulSoup(data.text, 'html.parser')
#
# foods = soup.select('#content > div.list_wrap > ul > li')
#
# for i in range(3):
# newUrl = baseUrl1 + baseUrl2 + str(pageNum)
#
# imageUrl = food.select_one('div.thumb_area > div.thumb > a > img')['data-src']
#
# pageNum += 1
#
# doc = {
# 'imageUrl': imageUrl
# }
#
# db.worstfoodcombination.insert_one(doc)
# return print('완료!')
#
# # # API 역할을 하는 부분
# # @app.route('/api/list', methods=['GET'])
# # def show_image():
# # # 1. db에서 mystar 목록 전체를 검색합니다. ID는 제외.
# # imageUrl = list(db.worstfoodcombination.find({}, {'_id': False}) #이름 바꾸기
# # # 2. 성공하면 success 메시지와 함께 stars_list 목록을 클라이언트에 전달합니다.
# # return
# # # return jsonify({'result': 'success', 'imageUrl_list': imageUrl})
에러찾기...
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
from flask import Flask, render_template, jsonify, request
app = Flask(__name__)
client = MongoClient('localhost', 27017)
db = client.swJungle
pageNum = 1
baseUrl1 = f'https://terms.naver.com/list.naver?cid=48158&categoryId=48158&viewType=&categoryType='
baseUrl2 = '&page='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
for i in range(920):
newUrl = baseUrl1 + baseUrl2 + str(pageNum)
data = requests.get(newUrl, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
foods = soup.select('#content > div.list_wrap > ul > li')
for food in foods:
a_tag = food.select_one('div.info_area > div.subject > strong > a').text.replace(' ', '').replace('[', ' ')
imageUrl = food.select_one('div.thumb_area > div.thumb > a > img')['data-src']
pageNum += 1
name = a_tag.split(' ')
print(name[0],imageUrl)
doc = {
'name': name[0],
'imageUrl': imageUrl
}
db.worstfoodcombination.insert_one(doc)해결
Nonetype 에러
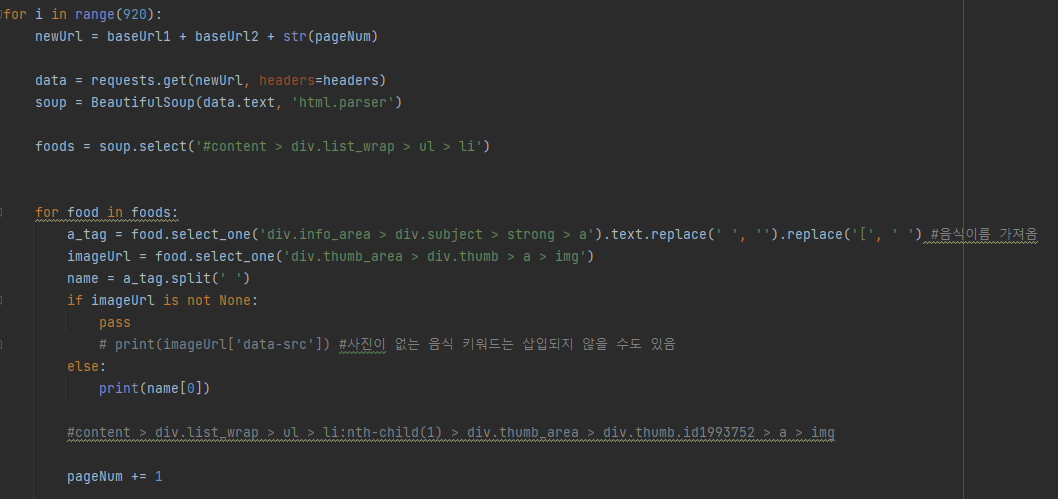
if문을 써서 None으로 나오는 음식 이름들을 구해봄

이정도
for food in foods:
a_tag = food.select_one('div.info_area > div.subject > strong > a').text.replace(' ', '').replace('[', ' ') #음식이름 가져옴
imageUrl = food.select_one('div.thumb_area > div.thumb > a > img')
name = a_tag.split(' ')
if imageUrl is not None:
pass
doc = {
'name': name[0],
'imageUrl': imageUrl['data-src']
}
db.worstfoodcombination.insert_one(doc) #fooddb그 후 바로 db에 저장.
13000여개가 저장 됨.
기타메모
IF data-src가 포함이 안되어있으면 pass(코딩해라)
한 사진당 4개가 있음
img alt에 있는 이미지 주소를 점만한 크기의 이미지 2개이고
data-src가 있는 코드와 중복되는 이미지 2개.
첫 면담 메모
잘 했는지 못 했는지 보다는, 오늘 나의 성장을 중심으로 생각할 것.
각자의 속도가 다르니 비교하지 말고 불안해 하지 말 것!
