1. WOODS: BENCHMARKS FOR OUT-OF-DISTRIBUTION GENERALIZATION IN TIME SERIES (2022, 7회 인용) Code
- 시계열에서는 distribution shifts 문제로 딥러닝 모델을 일반화하는 데 어려움을 겪음
- 특히 학습한 데이터에 대한 low empirical risk로 새로운 데이터에 대한 generalization 능력 부족함
- 딥 러닝 모델의 OOD 일반화 실패와 이를 극복하기 위한 연구에 대해 언급하고, 이 연구가 주로 정적인 컴퓨터 비전 작업에 초점을 맞추어 왔으며, 시계열 데이터에 대한 연구는 부족하다는 점을 지적하고 있음
- 이를 보완하기 위해 새로운 시계열 데이터셋과 알고리즘 평가 프레임워크를 제안하고, 다양한 실험을 통해 OOD 일반화의 도전과 향상 가능성에 대해 논의함.
최근 10년 동안 딥 러닝의 성공이 많은 분야에 걸쳐 영향력 있는 응용 프로그램을 가져다 주었음을 언급하고 있습니다. 그러나 이와 동시에 데이터의 선택적 편향, 혼동 요소 및 기타 편향으로 인해 딥 러닝 모델이 원하지 않는 상관 관계를 이용하는 경향이 있다는 증거가 늘고 있다는 사실도 제기되고 있습니다. 이러한 편향은 종종 모델이 데이터셋에서 낮은 경험적 위험에 도달하는 데 도움이 되는 바이어스를 만들어냅니다. 그러나 이러한 바이어스를 사용하는 예측 규칙은 인과 요인 대신 표적 상관 요소를 사용하므로 훈련 분포 외부로 일반화되지 않습니다. 이러한 실패는 의학이나 자율주행 자동차와 같이 인간의 생명에 직접적으로 영향을 미치는 현실적인 응용 프로그램에서 매우 우려스럽습니다.
Beery 등의 작업에서 설명하는 중요한 실패 모드를 공통 예로 사용하여 설명합니다. 사진에서 소와 낙타를 구별하는 작업을 생각해 봅시다. 훈련 데이터셋은 선택적 편향으로 심각하게 오염되어 있으며, 소 이미지 대부분은 초록 초원에서 촬영되었고, 낙타 이미지 대부분은 모래 지역에서 촬영되었습니다. 훈련 데이터셋의 경험적 위험을 최소화하기 위해 훈련된 모델은 선택적 편향을 활용하여 소를 구분하기 위해 녹색 배경을 사용하고, 낙타를 구분하기 위해 베이지 배경을 사용하게 됩니다. 딥 러닝 모델의 다양한 실패를 포착하기 위해, 분포 시프트가 있는 데이터셋을 찾고 표준화하기 위해 많은 노력이 기울여졌습니다. 이러한 데이터셋은 OOD(Out-of-Distribution) 일반화의 연구 노력을 위한 방향을 제공합니다.
이전 작업들은 딥 러닝에서 OOD 일반화 실패에 대한 핵심적인 경험적 및 이론적 통찰력을 제공했습니다. 그러나 이 작업들은 주로 정적인 컴퓨터 비전 작업에 초점을 맞추어 왔으며, 시계열에 대한 연구는 심각하게 탐구되지 않은 분야로 남아 있었습니다. 시계열은 의학, 자연 과학, 금융, 기후, 소매업, 생태학, 에너지 등 다양한 응용 프로그램에 필수적이지만, 이러한 분야에서는 시계열의 분포 시프트를 이해하는 데 더 깊이 들어갈 필요성이 있습니다.
해당 연구에서는 시계열 데이터의 분포 시프트에 대한 깊은 이해를 위한 첫 번째 단계를 취합니다. 주요 기여 사항은 다음과 같습니다:
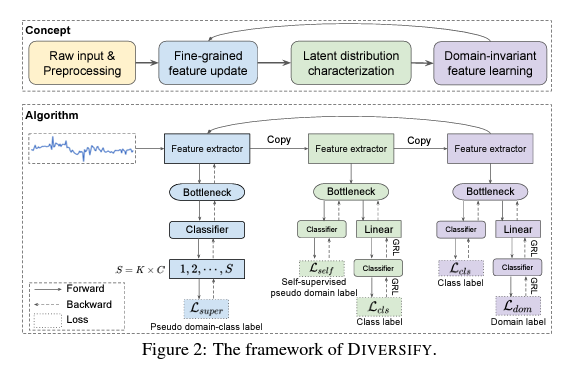
- WOODS(Wide Array Of Distribution Shifts)라는 합성 도전과 7개의 실제 데이터셋으로 구성된 벤치마크를 제안합니다. 이로써 비디오, 뇌 기록 및 스마트 기기 감각 신호와 같은 다양한 문제 및 데이터 모달리티를 다룹니다.
- 새로운 시계열 데이터셋과 알고리즘의 쉬운 평가를 위한 체계적인 프레임워크를 개발합니다. 이 프레임워크에는 시계열 데이터셋을 위해 기존의 OOD 일반화 알고리즘을 적용하는 것이 포함됩니다.
- 위의 데이터셋에 대한 ERM(경험적 위험 최소화) 및 다양한 OOD 일반화 알고리즘과의 광범위한 실험을 수행합니다. 우리의 연구 결과는 시계열에서의 OOD 일반화가 독특한 도전을 가지고 있으며, 향상의 큰 여지가 있다는 결론을 도출합니다.
2. Out-of-Distribution Detection in Time-Series Domain: A Novel Seasonal Ratio Scoring Approach (TIST 2022)
- STL과 DTW 활용한 모델
3. Out-of-distribution representation learning for time series classification (ICLR 2023, 1회 인용)
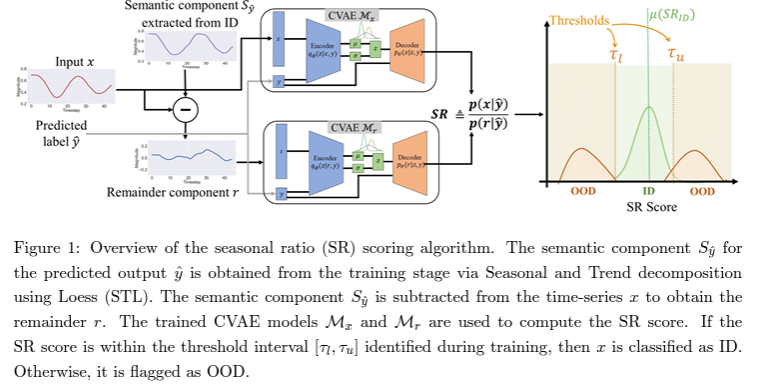
- 하나의 class에도 여러 domain의 distribution이 있다는 것을 고려한 모델
- S = K(분포종류) * C(클래스종류) 만큼 분류모델 학습 → 도메인별 라벨 만들기 + 도메인 분류 및 GRL을 활용한 클래스 분류 → GRL을 활용한 도메인 분류 및 클래스 분류