SELECT 문
SELECT 문장 실행 순서
FWGHSO (왜 그래쏘)로 암기하기 !!
- FROM : 조회 테이블 확인
- ON : 조인 조건 확인
- JOIN : 테이블 조인 (병합)
- WHERE : 데이터 추출 조건 확인
- GROUP BY : 특정 컬럼 그룹화
- HAVING : 그룹화 이후 데이터 추출 조건
- SELECT : 데이터 추출
- DISTINCT : 중복 제거
- ORDER BY : 데이터 순서 정렬

WHERE 절
- 원하는 자료를 검색하기 위한 조건절이다
- where 절에서는 두 개 이상의 테이블에 대한 조인 조건이나 결과를 제한하기 위한 조건을 기술할 수도 있다
- where절은 조회하려는 데이터에 특정 조건을 부여할 목적으로 사용하기 때문에 다음과 같이 FROM절 뒤에 오게 된다.
연산자의 우선순위
- 괄호()
- 부정연산자(NOT)
- 산술 연산자 : 곱하기, 나누기, 계수, 더하기, 빼기
- 문자열 연결 연산자 : ORACLE의 "||" , SQL Server에서 "+"
- 비교 연산자와 SQL 비교 연산자
- 비교 연산자 : =, >, <, >=, <=, <>, !=, ...
- SQL 비교 연산자 : BETWEEN A AND B, IN, LIKE, IS NULL
- 논리 연산자 중 NOT, AND, OR 순으로 처리
부정 비교 연산자
!=: 같지 않다.^=: 같지 않다.<>: 같지 않다.NOT 칼럼명: ~와 같지 않다.NOT 칼럼명 >: ~보다 크지 않다.
BETWEEN a AND b
a와 b 값 사이에 있으면 된다. (a,b 각각은 포함)
IN 연산자
SELECT *
FROM emp
WHERE job IN ('ANALYST', 'MANAGER', 'SALESMAN')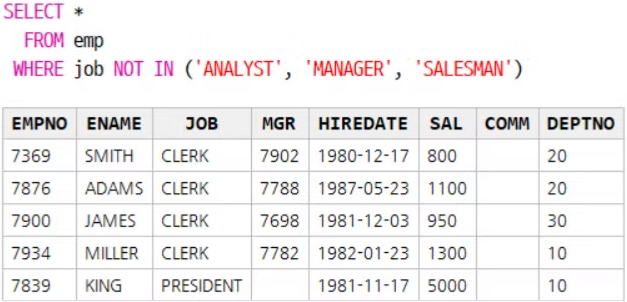
job 칼럼에 IN 연산자에 입력된 직업(ANALYST, MANAGER, SALESMAN) 중 하나라도 일치하면 조회된다.
IN 연산자의 결과와 OR 연산자의 결과가 동일하다.
NOT IN 연산자
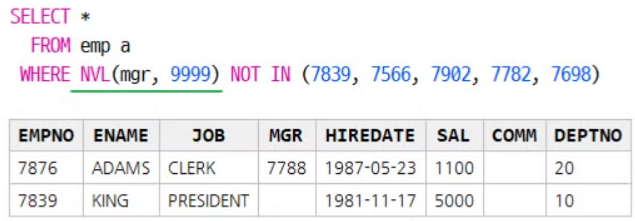
SELECT *
FROM emp a
WHERE mgr NOT IN (7839, 7566, 7902, 7782, 7698)해당 칼럼의 값이 NULL인 것은 제외하고 조회된다.
그룹함수
- 반드시 하나의 값만을 반환한다.
- NULL 값은 무시된다.
- NULL 값이 무시되지 않으려면 NVL, NVL2와 같은 함수를 이용한다.
- GROUP BY 설정 없이 일반 컬럼과 기술될 수 없다.
GROUP BY
WHERE 절을 통해 조건에 맞는 데이터를 조회하고나서, 2차 가공 정보가 필요할 수 있는데 이 때 GROUP BY 절을 사용한다.
GROUP BY 절은 SQL 문에서 FROM 절과, WHERE 절 뒤에 오며, 데이터들을 작은 그룹으로 분류하여 소그룹에 대한 항목별로 통계 정보를 얻을 때 추가로 사용된다.
즉 그룹핑 기준 을 설정 하는 것 이다.
- SELECT 절에 그룹 함수와 컬럼명이 같이 기술된 경우 해당 컬럼은 반드시 GROUP BY절에 그룹화돼야 한다.
- GROUP BY 절은 반드시 그룹함수와 함께 쓰이며 그룹 함수의 결과 값은 GROUP BY 절에 기술된 컬럼의 항목들의 행의 개수에 의해 결정된다.
GROUP BY 절 특징
- GROUP BY 절에서는 alias명 사용 불가
- GROUP BY 절보다 where절이 먼저 수행되기 때문에 집계 함수는 where 절에 올 수 없다.

GROUP BY 절에 DEPTNO 를 사용하면 DEPTNO 가 같은 값끼리 묶여서 요약 정보만 SELECT 절에 표현 가능.
따라서 GROUP BY 컬럼과 집계 함수를 사용한 결과만이 전달 가능
-> GROUP BY 절에 명시되지 않은 컬럼 전달 불가!
HAVING 절
- HAVING 절은 해석상 WHERE 절과 동일하다. 단 조건 내용에 그룹 함수를 포함하는 것만을 포함한다.
- 일반 조건은 WHERE 절에 기술하지만 그룹 함수를 포함한 조건은 HAVING 절에 기술한다.
- GROUP BY절에 의한 집계 데이터에 출력 조건을 건다.
- HAVING 절은 일반적으로 GROUP BY 절 뒤에 위치한다.
SELECT [DISTINCT] 컬럼, 그룹 함수(컬럼)
FROM 테이블명
[WHERE 조건]
[GROUP BY Group대상]
[HAVING 그룹 함수 포함 조건]
[ORDER BY 정렬대상 [ASC/DESC]]ORDER BY 절
특징
- SQL 문장으로 조회된 데이터들을 다양한 목적에 맞게 특정 칼럼을 기준으로 정렬하는데 사용된다.
- DBMS마다 NULL 값에 대한 정렬 순서가 다를 수 있으므로 주의해야한다.
- GROUP BY 절을 사용하는 경우 ORDER BY 절에 집계함수를 사용할 수도 있다.
- 칼럼명 대신 Alias 명이나 칼럼 순서를 나타내는 정수를 혼용해서 사용할 수 있다.
조인
표준조인
일반 집합 연산자
UNION, UNION ALL
INTERSECTION
EXCEPT, MINUS
CROSS PRODUCT
ON과 USING
USING : USING 은 두 테이블간 조인 조건 컬럼의 컬럼명이 동일한 경우 사용할 수 있는 키워드
컬럼명이 같을 경우 ON, USING 모두 사용 가능하나, 컬럼명이 다른 경우는 ON 만 사용 가능한 점
# ON 사용
SELECT EMP.DEPTNO, EMPNO, ENAME, DNAME
FROM EMP INNER JOIN DEPT
ON EMP.DEPTNO = DEPT.DEPTNO;
# USING 사용
SELECT DEPTNO, EMPNO, ENAME, DNAME
FROM EMP INNER JOIN DEPT
USING (DEPTNO);FROM절 JOIN 형태
INNER JOIN
SELECT EMP.DEPTNO, EMPNO, ENAME, DNAME
FROM EMP INNER JOIN DEPT
ON EMP.DEPTNO = DEPT.DEPTNO;NATURAL JOIN
- 두 테이블 간의 동일한 이름을 갖는 모든 칼럼들에 대해 EQUI(=) JOIN을 수행
- NATURAL JOIN이 명시되면, 추가로 USING 조건절, ON 조건절, WHERE 절에서 JOIN 조건을 정의할 수 없다.
- JOIN에 사용된 칼럼들은 같은 데이터 유형이어야 하며, ALIAS나 테이블 명과 같은 접두사를 붙일 수 없다.
→ 모든 칼럼에 OWNER 표시가 없어야 함
CROSS JOIN
- 일반 집합 연산자의 PRODUCT의 개념으로 테 이블 간 JOIN 조건이 없는 경우 생길 수 있는 모든 데이터의 조합
- 두 개의 테이블에 대한 CARTESIAN PRODUCT 또는 CROSS PRODUCT와 같은 표현으로, 결과는 양쪽 집합의 M*N 건의 데이터 조합이 발생한다.
OUTER JOIN
- LEFT OUTER JOIN
- 조인 수행시 먼저 표기된 좌측 테이블에 해당하는 데이터를 먼저 읽은 후, 나중 표기된 우측 테이블에서 JOIN 대상 데이터를 읽어 온다.
- Table A와 B가 있을 때(Table 'A'가 기준이 됨), A와 B를 비교해서 B의 JOIN 칼럼에서 같은 값이 있을 때 그 해당 데이터를 가져오고, B의 JOIN 칼럼에서 같은 값이 없는 경우에는 B 테이블에서 가져오는 칼럼들은 NULL 값으로 채운다.
- LEFT JOIN으로 OUTER 키워드를 생략해서 사용할 수 있다.
- RIGHT OUTER JOIN
- 조인 수행시 LEFT JOIN과 반대로 우측 테이블이 기준이 되어 결과를 생성한다.
- TABLE A와 B가 있을 때(TABLE 'B'가 기준이 됨), A와 B를 비교해서 A의 JOIN 칼럼에 서 같은 값이 있을 때 그 해당 데이터를 가져오고, A의 JOIN 칼럼에서 같은 값이 없는 경 우에는 A 테이블에서 가져오는 칼럼들은 NULL 값으로 채운다.
- RIGHT JOIN으로 OUTER 키워드를 생략해서 사용할 수 있다.
- FULL OUTER JOIN
- 조인 수행시 좌측, 우측 테이블의 모든 데이터를 읽어 JOIN하여 결과를 생성한다.
- TABLE A와 B가 있을 때(TABLE 'A', 'B' 모두 기준이 됨), RIGHT OUTER JOIN과 LEFT OUTER JOIN의 결과를 합집합으로 처리한 결과와 동일하다.
- 단, UNION ALL이 아닌 UNION 기능과 같으므로 중복되는 데이터는 삭제한다.
- FULL JOIN으로 OUTER 키워드를 생략해서 사용할 수 있다.
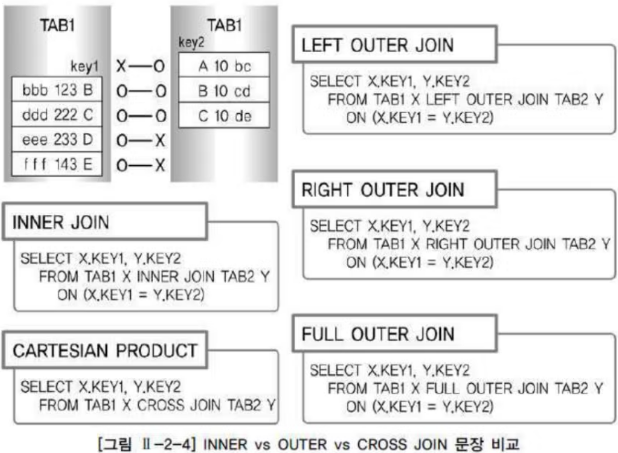
- INNER JOIN의 결과
- 양쪽 테이블에 모두 존재하는 키 값이 B-B, C-C 인 2건이 출력된다.
- LEFT OUTER JOIN의 결과
- TAB1을 기준으로 키 값 조합이 B-B, C-C, D-NULL, E-NULL 인 4건이 출력된다.
- RIGHT OUTER JOIN의 결과
- TAB2를 기준으로 키 값 조합이 NULL-A, B-B, C-C 인 3건이 출력된다.
- FULL OUTER JOIN의 결과
- 양쪽 테이블을 기준으로 키 값 조합이 NULL-A, B-B, C-C, D-NULL, E-NULL 인 5건이 출력된다.
- CROSS JOIN의 결과
- JOIN 가능한 모든 경우의 수를 표시하지만 단, OUTER JOIN은 제외한다.
- 양쪽 테이블 TAB1과 TAB2의 데이터를 곱한 개수인 4 * 3 = 12건이 추출됨
- 키 값 조합이 B-A, B-B, B-C, C-A, C-B, C-C, D-A, D-B, D-C, E-A, E-B, E-C 인 12건이 출력된다.
문제풀이
Q. 조인에 대한 설명으로 적절한 것
- 일반적으로 Join은 PK와 FK 값의 연관성에 의해 성립된다.
- EQUI Join은 Join에 관여하는 테이블 간의 컬럼 값들이 정확하게 일치하는 경우에 사용되는 방법이다.
- EQUI Join은 ‘=’ 연산자에 의해서만 수행되며, 그 이외의 비교 연산자를 사용하는 경우에는 모두 Non EQUI Join이다
- 대부분 Non EQUI Join을 수행할 수 있지만, 때로는 설계상의 이유로 수행이 불가능한 경우도 있다.
Q. 다음 중 아래에서 조인(JOIN)에 대한 설명으로 올바르지 않은 것은 ?
가) 마스터 테이블과 슬레이브 테이블 간의 조인은 일반적으로 기본키와 외래키 사이에서 발생한다.
나) EQUI Join은 두 개의 테이블 간에 칼럼 값이 일치하는 것을 조회한다.
다) EQUI Join은 >, < ≥, ≤를 사용한다.
라) EQUI Join은 두 개의 테이블에서 교집합을 찾는다.
함수
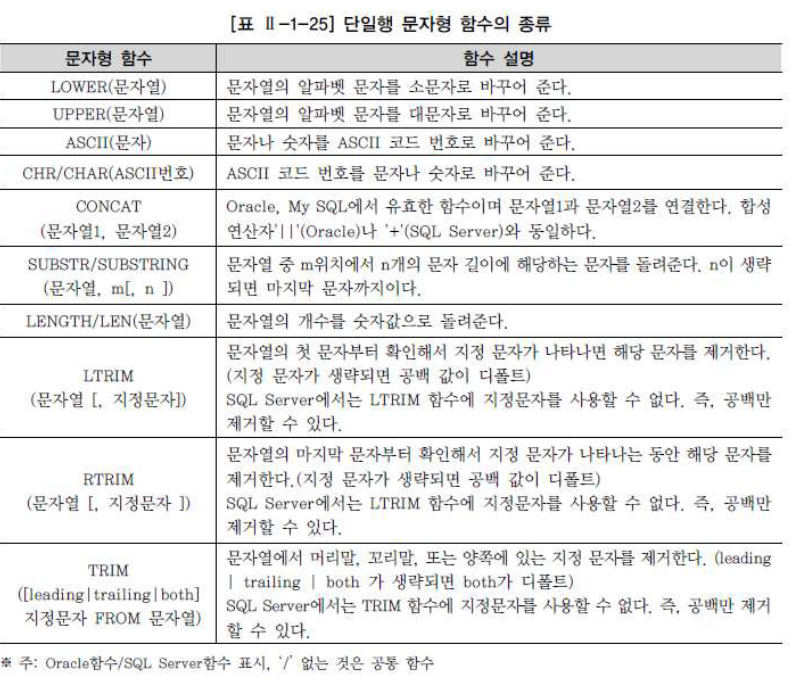
문자형 함수
: 입력 문자열을 소문자로 변환
-
CHR(ASCII 코드) : 코드 값에 따른 문자 출력
-
UPPER(문자열) → 대문자
: 입력 문자열을 대문자로 변환
-
LTRIM(문자열, [특정문자] ) → 문자 사이에 있는 공백은 제거 안됨
: 왼쪽 공백 제거, 특정문자 제거(제거 되면 멈춤)
: 특정 문자로 여러 문자를 입력하면 그 안에 있는 모든 문자가 사라짐
ex) LTRIM(’SQL’, ‘LE’) → SQ
: ‘LE’ 에 ‘L’, ‘E’ 가 있기 때문에 L, E를 날리는 것 대신 바로 멈춘다.
-
RTRIM(문자열, [특정문자]) → 문자 사이에 있는 공백은 제거 안됨
: 오른쪽 공백 제거, 특정문자 제거(제거 되면 멈춤)
-
TRIM([위치값][특정문자] [FROM] 문자열) → , 없어도 됨 + 특정문자는 문자열 안됨
: 왼쪽, 오른쪽 공백 제거하고 특정 문자 제거
: 위치값은 LEADING=왼쪽부터, TRAILING=오른쪽부터, BOTH=둘 다
-
SUBSTR(문자열, 시작점, [길이] ) → 0부터 시작 X, 1부터 시작임
: 문자열의 원하는 부분만 잘라서 반환(추출), 시작점 부터 자르기 시작해서, 길이 만큼 자른다.
: 더 잘라질 수 없으면 최대한의 값으로 출력
ex) SUBSTR(’블랙핑크제니’, 3, 2) → ‘핑크’
ex) SUBSTR(’블랙핑’, 3, 3) → ‘핑’
SELECT SUBSTR('DATABASE', 7) FROM DUAL;
SELECT SUBSTR('DATABASE', -2) FROM DUAL;
SELECT SUBSTR('DATABASE', 8, -2) FROM DUAL;
SELECT SUBSTR('DATABASE', INSTR('DATABASE', 'S'), 2) FROM DUAL;
// 3번째 줄은 NULL 반환하고, 나머지는 SE- INSTR(문자열, 찾고싶은 문자열, [시작점], [몇번째에 발견]) : 문자열에서 원하는 문자 찾아서 위치 반환, 여러개 찾아지면 몇번째 문자의 위치를 반환 → 시작 위치와 발견 인덱스는 생략 가능 → 찾고자 하는 문자가 여러 개인 경우 4번째 인자인 순서를 통해 결정 ex) INSTR(’A#B#C#’, ‘#’, 3, 2) → 6
- LENGTH(문자열) : 문자열의 길이를 반환
- REPLACE(문자열, 찾는 문자열, [변경 할 문자열]) : 문자열에서 특정 문자열을 찾아서 이를 변경 → 변경 할 문자 입력 안하면 없앰
- LPAD(문자열, 길이, 특정 문자) : 문자열이 설정한 길이가 될 떄 까지 왼쪽을 특정 문자로 채움
- RPAD(문자열, 길이, 특정 문자) : 위와 동일
- CONCAT(문자, 문자) → 결합 : 두 문자를 결합하는 함수
숫자형 함수
- ABS(수) : 절댓값 반환
- SIGN(수) : 부호를 반환 → 양수 = 1 / 음수 = -1 / 0 = 0
- CEIL(수) → 올림 : 소수점 이하의 수를 올림 한 정수로 반환 : 음수인 소수를 넣으면 버리게 되면 커진다. ex) CEIL(72.86) → 73 ex) CEIL(-33.4) → -33
- ROUND(수, [자릿수]) → 반올림 : 수를 지정한 소수점 자릿수까지 반올림, Default = 정수로 만듬 = 0 : 음수는 해당 자릿수의 정수를 반올림(-1 = 1의 자리를 반올림, -2 = 10자리) ex) ROUND(163.76, 1) → 163.8 ex) ROUND(163.76, -2) → 200
- TRUNC(수, [자릿수]) → 버림 : 수를 지정한 소수점 자릿수까지 버림, Default = 0 : 음수는 해당 자릿수의 정수까지 버림 ex) TRUNC(54.29, 1) → 54.2 ex) TRUNC(54.29, -1) → 50
- FLOOR(수) → 소수점 이하 버림 : 소수점 이하의 수를 버림 ex) FLOOR(22.3) → 22 ex) FLOOR(-22.3) → -23
- MOD(수1, 수2) → 나머지 : 수1을 수2로 나눈 나머지를 반환 : 수2가 0일 경우 수1을 그대로 반환 ex) MOD(15, 7) → 1 ex) MOD(15, -4) → 3

날짜 함수
- SYSDATE : 현재의 연, 월, 일, 시, 분, 초를 반환 : nls_date_format에 따라 출력 포맷 달라질 수 있음)
- EXTRACT(특정 단위 FROM 날짜데이터 or SYSDATE) : 특정 단위의 날짜를 반환 ex) EXTRACT(YEAR FROM SYSDATE) → 2024 ex) EXTRACT(MONTH FROM SYSDATE) → 3
- ADD_MONTHS(날짜 데이터, 특정 개월 수) : 입력한 날짜 데이터에 특정 개월 수를 더한 날짜를 반환해주는 함수 : 날짜의 이전 달이나 다음 달에 기준 날짜의 일자가 존재하지 않으면 해당 월의 마지막 일자 반환 ex) ADD_MONTHS( TO_DATE(’2021-12-31’), 1) → 2022-01-31 ex) ADD_MONTHS( DATE ‘2022-01-31’, 1) → 2022-02-28
변환 함수
명시적 형변환 : 변환 함수를 사용하여 데이터 유형을 명시적으로 나타냄
암시적 형변환 : DB가 내부적으로 알아서 데이터 유형을 변환함
- TO_NUMBER(문자열) : 문자열을 숫자로 변환 : 숫자로 변환 안되는 진짜 문자가 들어가면 에러 발생
- TO_CHAR(수 or 날짜, [포맷]) : 수나 날짜 데이터를 문자형 또는 입력 포맷으로 변환
- TO_DATE(문자열, 포맷) : 포맷 형식의 문자 데이터를 YYYY-MM-DD 형식의 날짜 데이터로 바꿈
CASE
함수가 아닌 CASE 구문형식으로도 특정 값을 치환 가능
- CASE 구문 & WHEN 조건 & ELSE 처리 : 별도의 ELSE가 없으면 NULL 값이 ELSE의 DEFAULT가 된다.
- DECODE(대상, 값1, 리턴1, 값2, 리턴2, 값3, 리턴3……, ESLE 값) : CASE 구문과 같은 역할 조건의 구분은 없다.
SELECT CASE WHEN 조건1 THEN 결과1
WHEN 조건2 THEN 결과2
.....
ELSE 결과
END
FROM 테이블명;
# 예시
SELECT email,
CASE
WHEN age >= 20 AND age < 30 THEN '이십 대'
WHEN age BETWEEN 30 AND 39 THEN '삼십 대'
ELSE "기타"
END as "나이 대"
FROM main_database.member;