계층형 데이터란 ?
테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해서 계층형 질의를 사용한다.
계층형 데이터 : 동일 테이블에 계층적으로 상위와 하위 데이터가 포함된 데이터
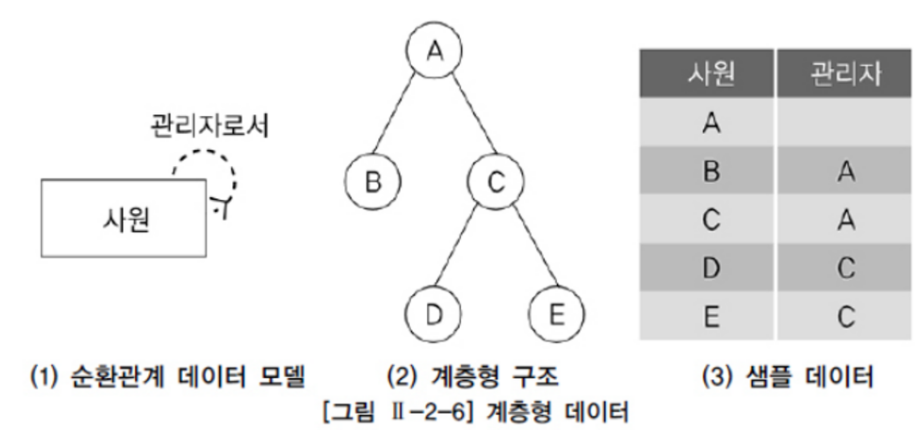
ex) 사원 테이블에서는 사원들 사이에 상위 사원(관리자)과 하위 사원관계가 존재하고 조직 테이블에서는 조직들 사이에 상위 조직과 하위 조직 관계가 존재
계층형 질의
SELECT ...
FROM 테이블
WHERE condition AND condition ...
START WITH condirion
CONNECT BY [NOCYCLE] condition AND condition ...
[ORDER SIBILINGS BY column, column, ... ]START WITH 절 : 계층 구조 전개 시작 위치를 정하는 구문, 즉, 루트 데이터를 지정
CONNECT BY 절 : 자식 데이터를 지정하는 구문, 자식 데이터는 CONNECT BY 절에 주어진 조건을 만족
PRIOR
다음에 전개될 자식 데이터를 지정. 자식 데이터는 CONNECT BY에 주어진 조건을 만족해야함.
** PRIOR 키워드 : 바로 직전에 출력된 레코드(행)를 의미
- PRIOR 자식 = 부모:
계층 구조가 부모데이터에서 자식 데이터(부모 → 자식), 방향으로 전개되는 순방향 전개를 함.
- PRIOR 부모 = 자식;
계층 구조가 자식 데이터에서 부모 데이터(자식 → 부모), 방향으로 전개되는 역방향 전개를 함.
- NOCYCLE : 데이터를 전개하면서 이미 나타났던 동일한 데이터가 다시 나타난다면 이것을 가리켜 사이클이 형성되었다고 한다. 사이클이 발생하면 런타임 오류가 발생함. 하지만 NOCYCLE을 추가하면 사이클이 발생한 이후의 데이터는 전개하지 않는다.
자-부-순 / 부-자-역
NOCYCLE
데이터를 전개하면서 이미 나타났던 동일한 데이터가 전개 중에 다시 나타나면 이것을 가리켜 사이클(CYCLE))이 형성되었다고 하며, 사이클이 발생한 데이터는 런타임 오류가 발생
하지만 NOCYCLE를 추가하면 사이클이 발생한 이후의 데이터는 전개하지 않음
ORDER SIBLING BY : 형제 노드 (동일 LEVEL )사이에서 정렬을 수행
WHERE : 모든 전개를 수행한 후에 지정된 조건을 만족하는 데이터만 추출
LEVEL :루트 데이터이면 1, 그 하위 데이터이면 2 이다. 리프(Leaf) 데이터까지 1씩 증가
CONNECT_BY_ISLEAF : 전개 과정에서 해당 데이터가 리프 데이터이면 1, 그렇지 않으면 0
CONNECT_BY_ISCYCLE : 전개 과정에서 자식을 갖는데, 해당 데이터가 조상으로서 존재하면 1, 그렇지 않으면 0 .여기서 조상이란 자신으로부터 루트까지의 경로에 존재하는 데이터를 말함. CYCLE 옵션을 사용했을 때만 사용할 수 있음.
계층형 질의 특징
- 루트노드의 LEVEL 은 1이다.
순방향(부모->자식) 계층형 질의
SELECT
LEVET,
사원,
관리자,
CONNECT_BY_ISLEAF ISLEAF
FROM 사원
START WITH 관리자 IS NULL
CONNECT BY PRIOR 사원 = 관리자;- A는 루트 데이터이기 때문에 레벨이 1이다.
- A의 하위 데이터인 B, C는 레벨이 2이다.
- C의 하위 데이터인 D, E는 레벨이 3이다.
- 리프 데이터는 B, D, E이다.
- 관리자 -> 사원 방향의 전개이기 때문에 순방향 전개이다.
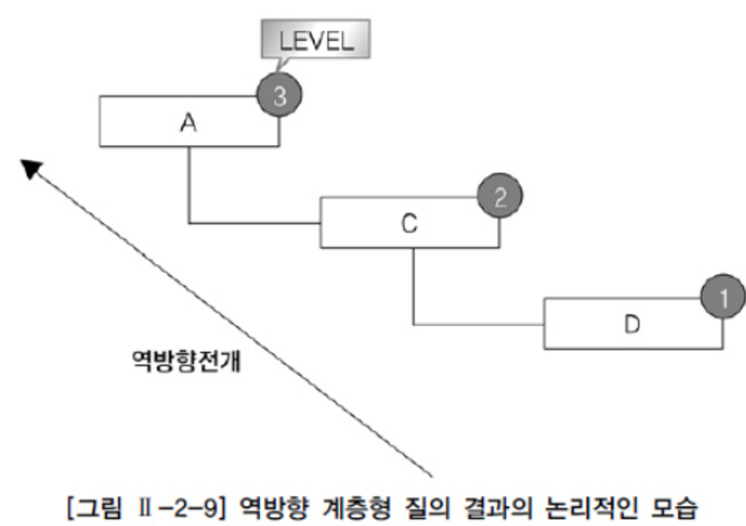
역방향(자식->부모) 계층형 질의
SELECT
LEVET,
사원,
관리자,
CONNECT_BY_ISLEAF ISLEAF
FROM 사원
START WITH 사원 = 'D'
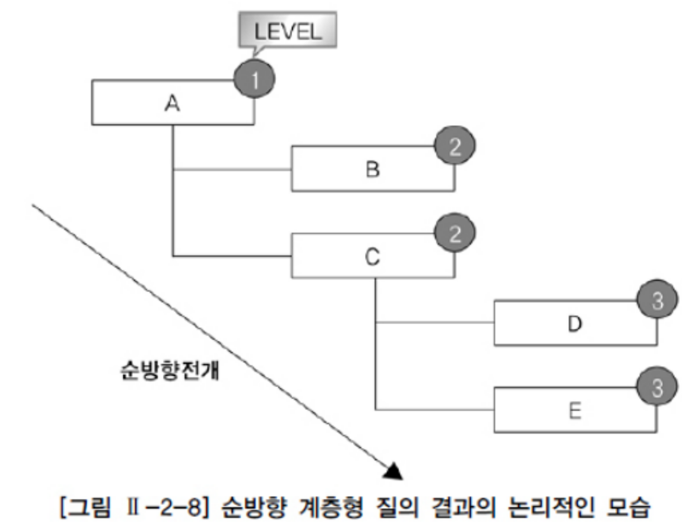
CONNECT BY PRIOR 관리자 = 사원;- D는 루트 데이터이기 때문에 레벨이 1이다.
- D의 상위 데이터인 C는 레벨이 2이다.
- C의 상위 데이터인 A는 레벨이 3이다.
- 리프 데이터는 A이다.
- 역방향 전개이기 때문에 하위 데이터에서 상위 데이터로 전개이다.
셀프조인
동일 테이블 사이의 조인
FROM 절에 동일 테이블이 두 번 이상 나타난다.
동일 테이블 사이의 조인을 수행하면 테이블과 칼럼 이름이 모두 동일하기 때문에 식별을 위해 반드시 테이블 별칭(Alias)를 사용해야 한다
** 하나의 테이블에서 두 개의 칼럼이 연관 관계를 가지고 있는 경우에 사용한다.
계층형 질의에서 살펴보았던 사원이라는 테이블 속에는 사원과 관리자가 모두 하나의 사원이라는 개념으로 동일시하여 같이 입력되어 있다
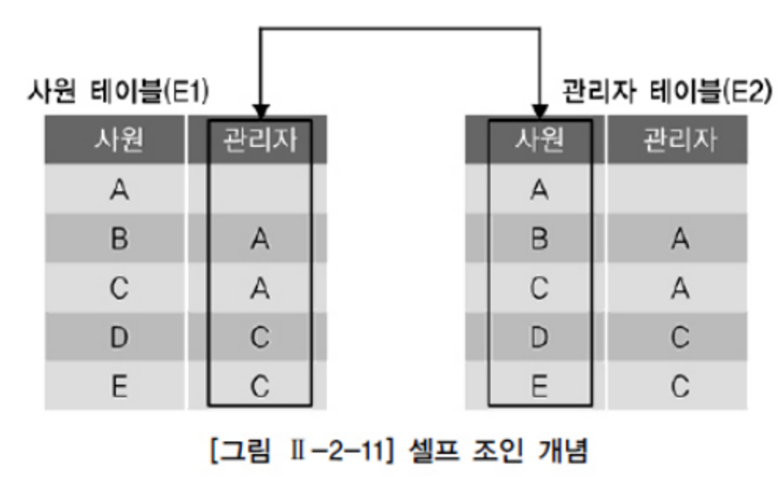
셀프 조인은 동일한 테이블(사원)이지만 개념적으로는 두 개의 서로 다른 테이블(사원, 관리자)을 사용하는 것과 동일하다.
SELECT
E1.사원,
E1.관리자,
E2.관리자 차상위_관리자
FROM
사원 E1,
사원 E2
WHERE E1.관리자 = E2.사원;
ORDER BY E1.사원;자신과 자신의 직속 관리자는 동일한 행에서 데이터를 구할 수 있으나
차상위 관리자는 바로 구할 수 없다.
차상위 관리자를 구하기 위해서는 자신의 직속 관리자를 기준으로 사원 테이블과 한번 더 조인(셀프 조인)을 수행해야 한다.
PIVOT의 개요
PIVOT은 회전시킨다는 의미를 갖고 있다. PIVOT 절은 행을 열로 회전시키고, UNPIVOT 절은 열을 행으로 회전시킨다.
피벗 = 펼치는 것!!!
PIVOT : 행으로 나열되어 있는 데이터를 열로 나열하여 보기 쉽게 가공하는 것
- 교차표를 만드는 기능
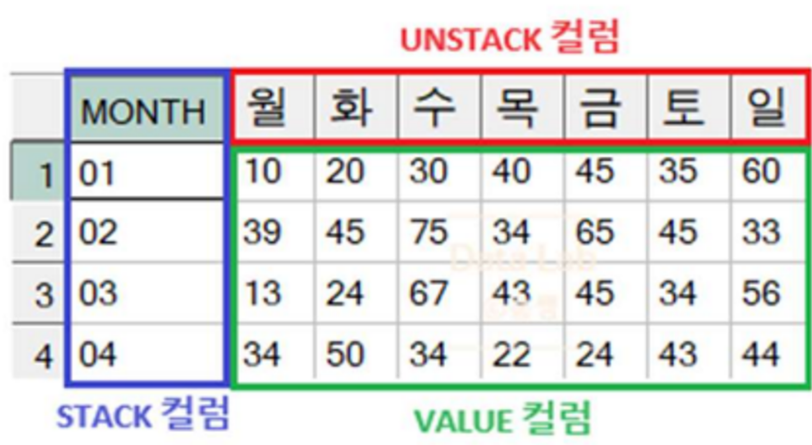
- STACK 컬럼, UNSTACK 컬럼, VALUE 컬럼의 정의가 중요!
- FROM 절에 STACK, UNSTACK, VALUE 컬럼명만 정의 필요(필요 시 서브쿼리 사용하여 필요 컬럼 제한)
- PIVOT 절에 UNSTACK, VALUE 컬럼명 정의
- PIVOT 절 IN 연산자에 UNSTACK 컬럼 값을 정의
- FROM 절에 선언된 컬럼중 PIVOT 절에서 선언한 VALUE 컬럼, UNSTACK 컬럼을 제외한 모든 컬럼은
STACK 컬럼이 됨
SELECT *
FROM 테이블명 또는 서브쿼리
PIVOT (VALUE 칼럼명 FOR UNSTACK 칼럼명 IN (값1, 값2, 값3));
SELECT *
FROM 원하는 데이터 값
PIVOT (VALUE 칼럼명 FOR 펼치고 싶은 데이터 IN (값1, 값2, 값3));
// 펼치고 싶은 데이터가 위로 들어감
/* Oracle */
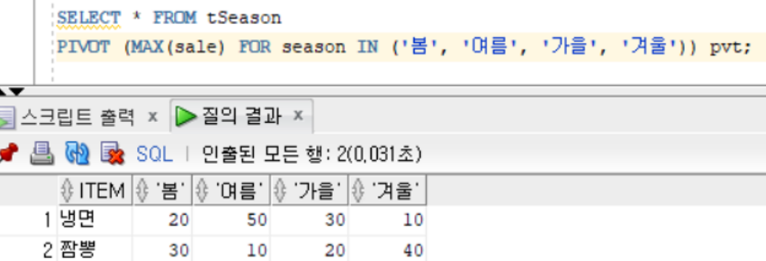
SELECT * FROM tSeason
PIVOT (MAX(sale) FOR season IN ('봄', '여름', '가을', '겨울')) pvt;
// FROM절 뒤에 오고 SELECT보다 먼저 수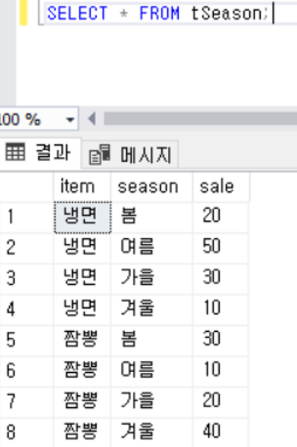
UNPIVOT
UNPIVOT은 이름과 같이 피봇의 반대 동작을 수행합니다.
피봇이 값을 열로 바꾸는데 비해 언피봇은 열을 값으로 변환하여 레코드에 기록한다.
- STACK 칼럼 : 이미 UNSTACK되어 있는 여러 컬럼을 하나의 컬럼으로 stack시 새로 만들 컬럼이름(사용자 정의)
- VALUE 칼럼 : 교차표에서 셀 자리(VALUE)값을 하나의 컬럼으로 표현하고자 할 때 새로 만들 컬럼명(사용자 정의)
- 값1, 값2 … : 실제 UNSTACK되어 있는 컬럼 이름들
- * IN 뒤에 값은 UNSTACK 데이터 칼럼명이 숫자이지만 컬럼명은 문자로 지정되므로 쌍따옴표 전달 필요**
FROM 절에 데이터를 제한할 필요가 없음.
정규 표현식의 개요
정규표현식 : 특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 언어
정규 표현식(regular expression)은 문자열의 규칙을 표현하는 검색 패턴으로 주로 문자열 검색과 치환에 사용한다.
특정한 범위 나타내기
[a-c] a~c 까지의 알파벳을 포함한다면 추출
[cmf] 연속된 알파벳이 아니고 그냥 있기만 하면 추출
패턴 위치 제한 걸어주기
맨 앞 위치로 제한 : ^
맨 마지막 위치로 제한 : $
자리 하나를 차지 : .
