
0. Abstract
전통적 statistical machine translation과는 달리, neural machine translation은 single, large neural network(하나의 큰 신경망)를 세우는 것을 목적으로함.
nmt에서 사용하는 encoder-decoder 구조
- source sentence →(encoding) fixed-length vector →(decoder) generate translation
- 이 fixed-length vector의 사용: 성능 향상의 bottleneck 문제 발생 (← 정보의 표현력에 한계)
- bottleneck: 마치 병의 목이 좁아서 액체의 흐름을 제한하는 것처럼, 정보의 흐름이나 처리 능력이 제한된다는 의미.
→ <해당 논문에서 제안하는 방법>
- 자동적으로 source sentence에서 target word와 관련있는 부분을 (soft-) 검색
- 이 new approach로, 프랑스어 번역에서 가장 우수한 성능을 가진 번역에 견주는 성능 달성함!
- 질적 분석 → 모델이 의도한대로 학습되어 (soft-)alignment도 되는 것을 찾음
- alignment: 출력 토큰을 생성하는 데에 관련있는 입력 문장의 토큰을 찾아내는 것
1. Introduction
기존에 대부분의 제안된 neural translation system들
- 각 언어에 대해 encoder와 decoder를 가지고 있거나,
- 각 문장에 대해 language-specific encoder를 적용 → 출력값들끼리 비교하는 방식 → 이게 몬데
이 방식들은 모두
- encoder: source sentence를 fixed-length vector(고정된 길이의 벡터)로 인코딩
- decoder: encoded vector로부터 번역
→ the whole encoder-decoder system: 주어진 source sentence가 맞게 번역될 확률을 높이기 위해 jointly하게 학습됨.
( jointly하게 학습된다는 것은 그냥 인코더와 디코더가 별도로 학습되는 것이 아니라 하나의 통합된 시스템으로 학습된다는 의미임! )
해당 encoder-decoder의 문제점
- nn이 source sentence의 모든 정보를 압축하여 고정된 크기의 벡터에 넣어야한다는 점
- nn이 long sentence를 다루기가 어려워짐. 특히, 문장이 training corpus 안의 문장보다 길어질 경우에 !
- → 즉, input sentence의 길이가 길어질수록 encoder-decoder의 성능은 급격히 악화된다 ㅠ.ㅠ
이를 해결하기 위해서, 해당 논문은 align(정렬)과 translate(번역)을 같이 학습하는 encoder-decoder model 의 확장을 제안
- 모델이 번역된 단어를 생성할 때마다, source sentence에서 가장 관련된 정보가 담겨있는 위치를 검색함
- 그리고 이 입력 위치와 연관된 context vector, 이전에 생성된 target word → target word 예측
- 기존 encoder-decoder 구조와 가장 큰 차이:
- 입력 문장을 a single fixed-length vector로 인코딩하지 않고
- a sequence of vectors(벡터의 시퀀스)로 인코딩함
- 그리고 디코딩할 때, 이 벡터의 일부 벡터를 고름.
→ 특히 long sentences에 대해 더 잘 대응할 수 있음 !! (성능 good)
qualitative analysis → 모델이 입력 문장과 대응하는 target 문장 사이에서 언어학적으로 타당한 정렬(alignment)을 발견함
(모델이 입력 문장과 목표 문장 사이의 단어 및 구문 간의 적절한 대응 관계를 학습하여, 사람이 번역할 때 자연스럽게 느끼는 것과 유사한 정렬을 자동으로 찾아내는 능력을 갖추었다는 의미)
2. Background: Neural Machine Translation
통계적 관점에서 번역 = 입력 문장 가 주어졌을 때, 의 조건부 확률을 maxmize 시키는 것
NMT에서는, 매개변수를 가진 모델을 훈련시켜서 병렬 학습 코퍼스를 사용해 문장 쌍의 조건부 확률을 극대화함.
번역 모델이 조건부 분포를 학습한 후에 → 주어진 입력 문장에 대응하는 번역이 생성됨 (조건부 확률을 가장 최대로 만드는 문장을 검색함으로써..)
최근 여러 논문에서 이러한 조건부 분포를 직접 학습하는 방법이 제안되었음.
이렇게 조건부 확률을 학습하는 NMT는 보통 인코더와 디코더로 이루어짐.
[구조]
variable-length 입력 문장 → (인코딩) fixed-length vector → (디코딩) variable-length 타겟 문장
새로운 접근법임에도, NMT는 유망한 결과를 보여줌.
- LSTM을 이용한 RNN은 영-프 번역에서 기존의 phrase-based 기계 번역의 성능에 거의 근접
- (기존) phrase-based 기계 번역: 문장을 여러개의 구문(phrase)으로 나누고, 각 구문을 번역한 후에 이들을 조합하여 전체 문장 번역하는 방법
- 기존의 번역 시스템에 neural component를 추가하여, 이전의 sota 성능을 넘어섬
- 예를 들면, 신경망을 사용하여 기존 mt의 구문 표에서 각 구문 쌍의 score를 매기기 → 원문 구문과 번역 구문간의 대응 관계 평가 후 그 점수를 구문 표에 반영

- 그리고 기존의 phrase-based 번역 시스템에서 여러 후보 번역을 생성한 후에, 신경망을 이용하여 각 후보 번역들의 순위 매기기
- 예를 들면, 신경망을 사용하여 기존 mt의 구문 표에서 각 구문 쌍의 score를 매기기 → 원문 구문과 번역 구문간의 대응 관계 평가 후 그 점수를 구문 표에 반영
2.1 RNN encoder-decoder (기존)
이전 연구에서 제안된 align과 translate를 동시에 학습하는 새로운 아키텍처
Encoder
-
시간 t에 대해,
-
- 입력 문장 (벡터 시퀀스)
- 각 시간 t의 입력 토큰
-
- t에서의 hidden state
- 각 시간 t에서 현재 입력 토큰 와 이전 시점의 hidden state() 사용 → 현재 hidden state 계산
- : RNN의 활성화함수 (ex) LSTM, …)
-
- 컨텍스트 벡터
- 인코더는 모든 은닉상태 사용하여 컨텍스트 벡터 만듦.
- : 은닉 상태 시퀀스에 비선형 함수 적용
- LSTM에서는 마지막 은닉 상태를 context vector로 사용하여 로 설정함
Decoder
-
타겟 값 의 확률은 이전에 예측된 모든 단어들과 context vector 를 사용하여 구함
-
번역된 문장들의 전체 확률 를 계산하는 방법
-
전체 확률을 직접 계산하는 대신, 이를 조건부 확률의 곱으로 분해하여 계산함

-
문장을 단어 단위로 나누고, 각 단어가 이전 단어들에 조건부로 결정된다고 가정 → 즉, 각 단어의 확률은 이전에 나온 단어들에 의해 결정됨
-
이러한 방법을 통해 더 효율적으로 번역 확률 계산 가능

-
-
RNN을 사용하여 각 단어의 조건부 확률 구하는 방법
-
: RNN의 hidden state
-
: 비선형 함수(다층 신경망일수 있음)
→ 이전 단어, 현재 은닉 상태, 컨텍스트 벡터를 입력으로 받아서 현재 단어 의 확률을 계산함!
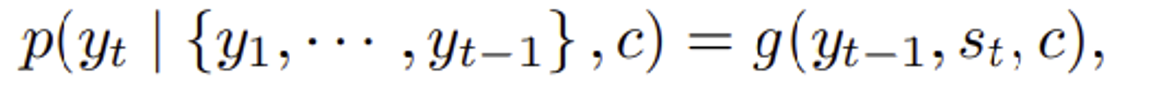
-
3. Learning to align and translate
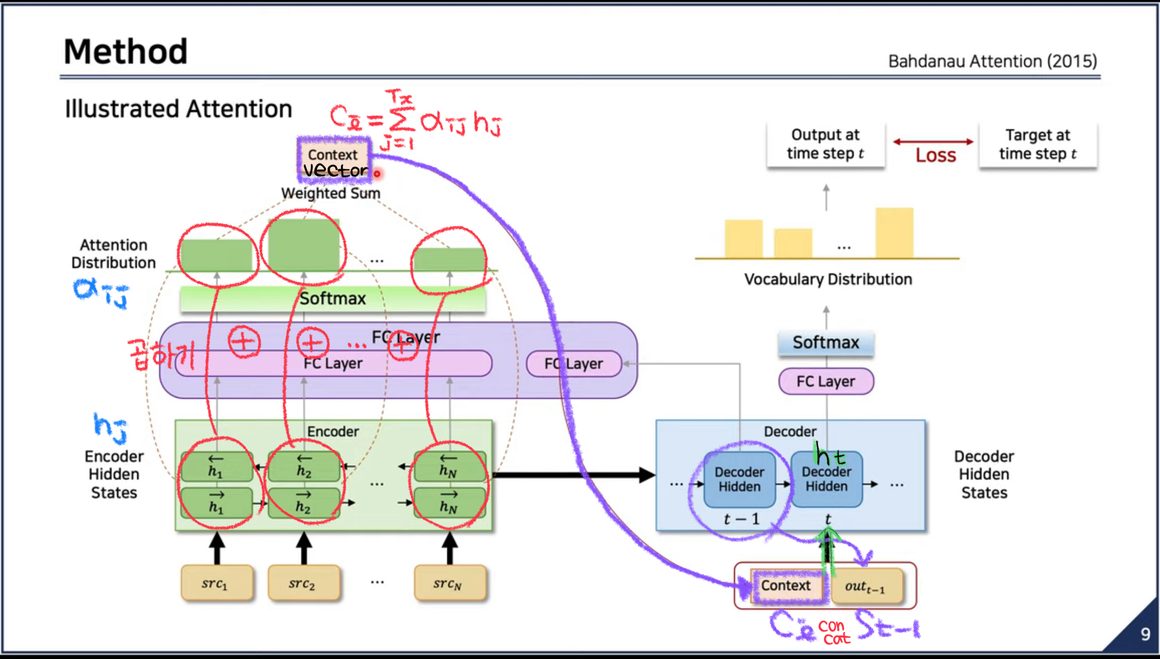
해당 섹션에서는 논문에서 제안하는 새로운 RNN architecture를 소개함.
-양방향 RNN을 인코더로 사용 (sec 3.2)
-번역문을 생성하는 동안 입력 문장을 검색하는 흉내를 내는 디코더 (sec 3.1)
3.1 Decoder
새로운 모델 아키텍처에서는 각 조건부 확률 이렇게 정의

그리고 여기서 (RNN hiddens state)를 구하기 위해서는,
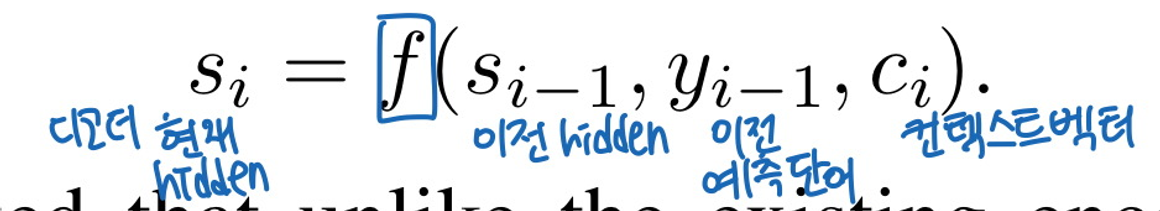
그리고 기존의 인코더-디코더 접근법과는 달리, 여기서는 타겟 단어 마다 각자만의 고유한 컨텍스트 벡터 를 가짐. (distinct한 context vector)
디코더는 예측 단어를 생성하기 위해 필요한 정보를 에서 얻음
-
는 인코더가 생성한 annotation sequence (주석 시퀀스) 로 계산됨
-
인코더의 hidden state = 주석(annotation)
-
번역 모델에서 각 단어를 번역할때 필요한 정보가 인코더가 생성한 주석 시퀀스()에 포함돼있다는 의미
-
-
는 어텐션이 적용된 컨텍스트 벡터로, 와 의 가중합으로 만들어짐.
→ 디코더가 현재 시점 에서의 타겟 단어 를 만들때 참고하는 벡터
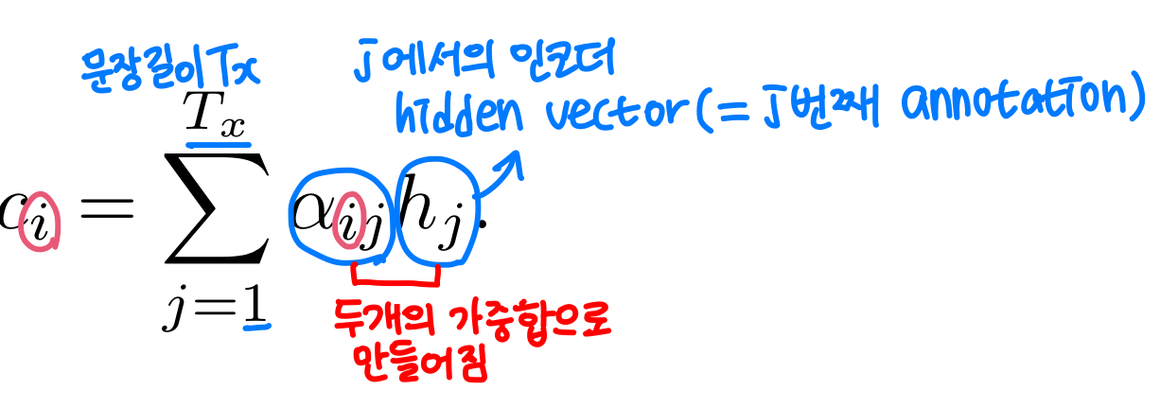
(입력 문장 길이 )
- (정렬 가중치)
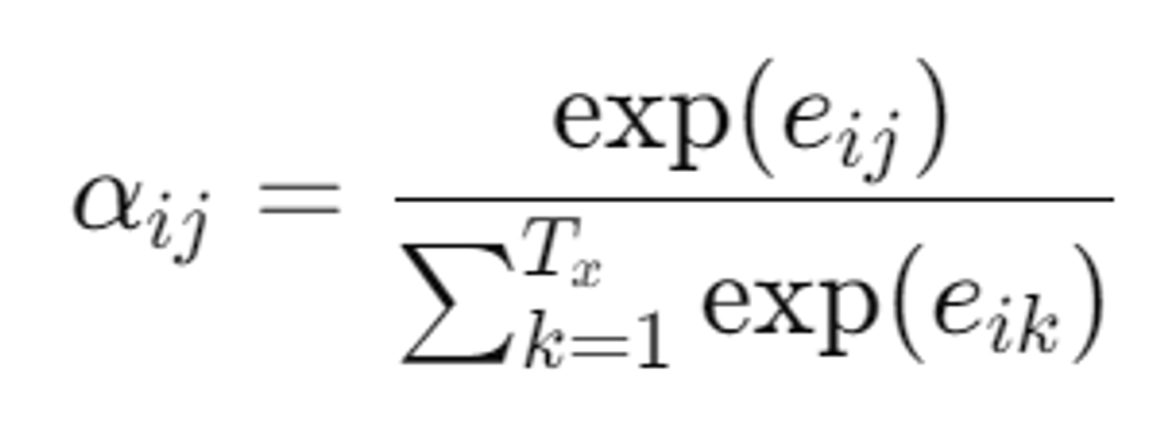
- 소프트맥스 함수를 통해 정규화하여 주석 의 가중치 구하기
- 타겟 단어가 입력 단어에 얼마나 강하게 정렬되는지 나타내는 값 → 확률로 나타나며, softmax함수 이용하여 계산됨
- (에너지 값)
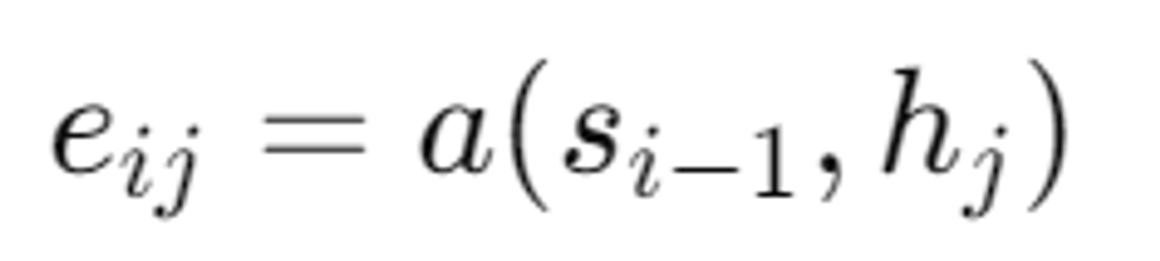
- 타겟 단어 가 입력 단어 와 얼마나 잘 맞는지(정렬 점수)를 나타내는 점수
- : feedforward neural network ← 과
👉이 과정은 디코더가 입력 문장의 특정 부분에 집중하여 타겟 단어를 생성할 수 있도록 돕는 어텐션 매커니즘을 구현한다.
→ 이를 통해 인코더가 전체 입력 문장을 고정된 길이의 벡터에 압축해야하는 부담을 줄이고, 디코더가 필요한 정보를 더 효과적으로 사용할 수 있게 해줌.
(추가 설명)
전통적인 기계 번역 (SMT) 에서의 정렬
- 소스 문장과 타겟 문장 사이에 어떤 단어들이 서로 대응하는지 결정한다.
- ex) 영어 문장 "I love you"와 프랑스어 문장 "Je t'aime"가 있을 때, "I"는 "Je", "love"는 "t'aime"에 대응
- 잠재 변수: 이 정렬 정보는 종종 학습 과정에서 숨겨진 상태 (latent variable) 로 취급된다. 즉, 학습 데이터로부터 직접 관찰되지 않지만 모델이 추정
신경망 기반 번역에서의 정렬 (**soft alignment 소프트 정렬**)
- 타겟 문장의 각 단어를 생성할 때, 입력 문장의 특정 부분에 얼마나 주목해야하는지를 결정
- 정렬 가중치 : 각 타겟 단어 를 생성할 때, 소스 문장의 각 단어 가 얼마나 중요한지를 나타내는 가중치. 이 가중치는 소스 문장의 각 단어에 대한 주목의 정도를 나타냄.
(본론)
→ 전통적 기계 번역에서는 alignemnt가 잠재 변수로 간주되지만, 이 논문에서는 alignment model이 직접 soft alignment를 계산
→ soft alignment을 통해 cost function의 gradient를 backpropagation 할 수 있음.
(soft alignment 매커니즘이 신경망 학습 과정에서 cost function의 오차를 줄이기 위해 사용하는 gradient를 효율적으로 계산하고 전파할 수 있도록 한다는 뜻)
→ 계산된 gradient를 정렬 모델과 번역 모델 전체를 학습시키는 데에 사용 가능!
3.2 Encoder: 양방향 RNN for annotating sequence (,…)
- 일반적인 RNN: 부터 까지 순서대로 입력 시퀀스 를 읽음
- (new) 논문에서 제안된 방식:
- preceding words + following words 모두 요약할 수 있길 원함.
- → bidirectional RNN (BiRNN 양방향 RNN) 제안 !
BiRNN : forward RNN + backward RNN
- 순방향 RNN
- 입력 시퀀스를 순서대로 읽고,
- 순방향 hidden states 을 계산
- 역방향 RNN
- 입력 시퀀스를 역순으로 읽고,
- 역방향 hidden states 을 계산
각 단어 에 대한 annotation (인코더의 hidden state) (= ) 를 얻기 위해 와 를 concat 시키기
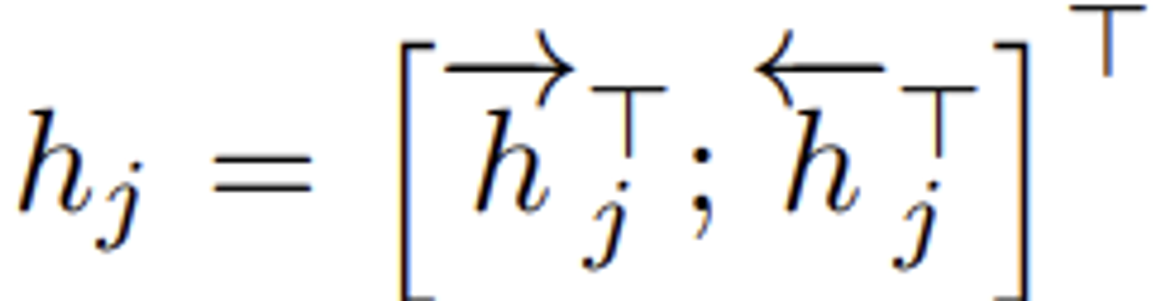
- 수식 이해하기
- 이렇게 두 벡터를 concat시켜주기 위해 transpose 계속 해주는 이유
→ 전치 과정을 통해 각 hidden vector의 차원과 방향을 맞추어서 올바르게 결합 가능. 전치 과정 없이 결합할 경우, 차원 불일치나 벡터의 방향 문제로 인해 결합이 제대로 이루어지지 못함 !!
- 이렇게 두 벡터를 concat시켜주기 위해 transpose 계속 해주는 이유
- h_j는 앞 단어들과 뒤 단어들의 요약을 모두 포함하게 됨
- RNN은 recent input을 더 잘 나타내는 경향이 있기 때문에, h_j는 x_j 주변에 대한 단어들에 대한 정보를 더 많이 포함하게 됨.
ex) 단어 "학교"에 대한 주석은 "학교" 주변의 단어들(예: "나는", "갑니다")에 대한 정보를 더 잘 담음
이렇게 생성된 annotation들은 디코더가 번역을 생성할 때 사용됨
디코더는 이 annotation을 통해 context vector를 계산 (주석 시퀀스를 기반으로 각 단어의 중요도를 계산하고, 이를 통해 context vector를 생성함)
이 주석 시퀀스 (sequence of annotation) : 디코더, 정렬 모델이 나중에 context vector를 계산하는 데에 사용됨.
4. Experiment Settings
-
제안된 방식을 English-to-French translation 테스크로 평가
-
데이터셋으로 ACL WMT ’14에서 제공하는 bilingual(이중언어), parallel corpora(병렬 코퍼스) 사용
- 병렬 코퍼스 이용해서 →기계 번역 모델 훈련 시 입력 언어와 타겟 언어 사이의 관계를 학습
-
비교 위해, Cho et al. (2014a)에서 제안한 RNN 인코더-디코더의 성능도 조사 ( 두 모델 모두 동일한 훈련 절차와 동일한 데이터셋을 사용)
4.1 Dataset
WMT ‘14 : 총 8억 5000만 단어 → 결합된 코퍼스의 크기를 3억 4800만 단어로 축소
- 검증 세트: news-test 2012와 news-test-2013을 결합
- 테스트 세트 : news-test-2014 (훈련 데이터에 없는 3003개의 문장으로 구성)
→ 모델 평가
보통의 토크나이제이션을 거친 후, 각 언어에서 가장 빈번하게 등장하는 30,000개의 단어로 단어 목록을 만들어 모델을 훈련시킴
-
tockenization: 텍스트를 단어, 구두점, 기호 등의 토큰으로 나누는 과정
-
각 언어(예: 영어와 프랑스어)에서 가장 자주 등장하는 단어 30,000개를 선택해서 목록 만들기
-
목록에 포함되지 않는 드문 단어는 특수 토큰([UNK])으로 매핑
- 모델이 학습하지 않은 단어를 처리할 수 있도록 하기 위한 방법
→ 모델은 자주 등장하는 단어들에 집중하여 더 효과적으로 학습할 수 있게 되고, 드문 단어들도 "[UNK]"로 처리하여 어느 정도의 일반화 능력을 가지게 됨
- ex)
- 원문: "The aardvark is on the mat."
- 토크나이제이션 후: ["The", "aardvark", "is", "on", "the", "mat", "."]
- 30,000 단어 목록에 "aardvark"가 없을 경우: ["The", "[UNK]", "is", "on", "the", "mat", "."]
데이터에 소문자 변환이나 스테밍과 같은 다른 특별한 전처리 x
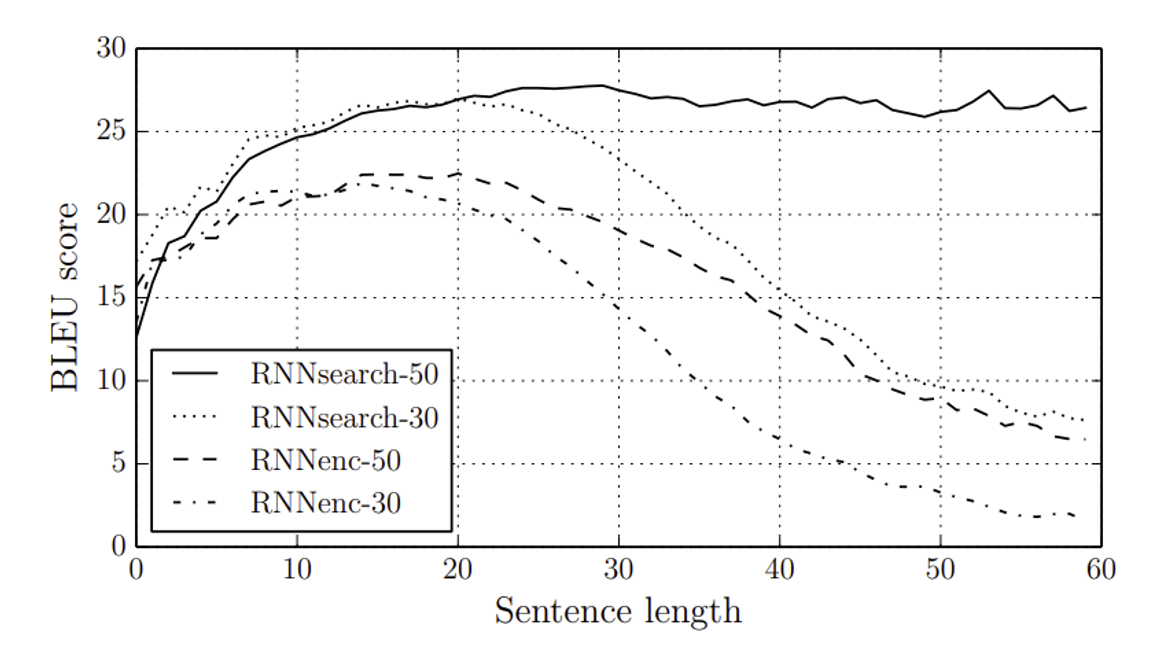 (그림2: 문장 길이에 따른 testset에서 생성된 번역의 BLEU 점수, 모델이 모르는 단어도 같이 포함)
(그림2: 문장 길이에 따른 testset에서 생성된 번역의 BLEU 점수, 모델이 모르는 단어도 같이 포함)
-
BLEU 점수: 기계 번역의 품질을 평가하는 지표, 생성된 번역과 인간이 작성한 참조 번역을 비교하여 점수를 매기고 이 점수가 높을수록 번역 품질이 좋음
-
테스트 셋에는 모델이 학습하지 않은 단어를 포함한 문장도 있음. 이러한 단어는 특수 토큰 ([UNK])으로 처리
-
해당 그림에서 볼 수 있듯이, RNNencoder의 성능은 문장 길이가 길어질수록 급격히 낮아짐. 애초에 기존의 인코더-디코더 접근 방식에서 사용하는 fixed length context vector로 인해 문장 길이가 길어질수록 성능이 낮아진다는 것이 문제라서 이 논문에서 이를 해결하기 위해서 새로운 접근 방식을 제안한 것임. 표에서 볼 수 있듯이 해당 논문에서 제안한 RNNsearch 방식은 문장 길이가 길어짐에도 성능 저하 없이 유지됨 (우수함을 알 수 있음 !)
4.2 Models
모델 유형
두가지 유형 모델 훈련시킴. 각 모델 당 두번씩 훈련 (첫번째는 최대 30단어 길이의 문장, 두번째는 최대 50단어 길이의 문장)
- RNN 인코더-디코더 (RNNencdec)
- RNNencdec-30
- RNNencdec-50
- 논문에서 제안된 모델 (RNNsearch)
- RNNsearch-30
- RNNsearch-50
모델 구조
-
RNNencdec: 인코더와 디코더 각각 1000개의 hidden units 가짐
-
RNNsearch
- 인코더: 각각 1000개의 은닉 유닛을 가진 순방향 및 역방향(bidirectional) 순환 신경망(RNN)으로 구성
- 디코더: 1000개의 은닉 유닛
- 두 경우에서 모두, 단일 maxout 은닉 레이어를 가진 multilayer network 사용하여 각 타겟 단어의 조건부 확률 계산
- maxout 네트워크
- maxout은 ReLU나 sigmoid 같은 전통적인 활성화 함수 대신, 여러 선형 함수 중 최댓값을 선택하는 활성화 함수를 사용하는 신경망 아키텍처
- 사용 이유: 비선형성 도입, 오버피팅 줄이면서도 강력한 표현력 가짐
- 단일 maxout 은닉 레이어를 가진 multilayer network는 여러 layer로 구성된 신경망이며, 그 중 하나의 레이어가 maxout 활성화 함수를 사용함
- 이전 단어, 디코더의 현재 은닉 상태, context vector를 입력으로 받아, 타겟 단어가 다음에 나올 조건부 확률을 계산함
- maxout 네트워크
훈련 과정
알고리즘: minibatch SGD, Adadelta
- minibatch SGD:
- 전체 학습 데이터셋을 여러 작은 그룹 (minibatch) 로 나눈 후에, 각 minibatch 에 대해 모델의 파라미터를 업데이트
- minibatch의 크기를 문장 80개로 두고 계산 → (각 minibatch에 속한 80개 문장 기반으로) 각 SGD의 방향 (gradient) 업데이트

-
Adadelta
-
얘를 알려면 그 전에 AdaGrad에 대하여 알아야함
-
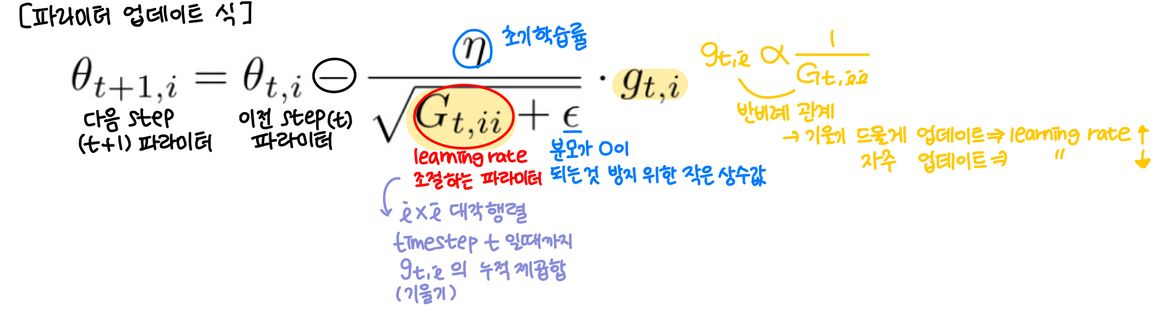
AdaGrad: 각 가중치(weight)에 각각의 learning rate를 사용하는 것. 많이 업데이트된 가중치는 학습률을 줄이고, 적게 업데이트된 가중치는 학습률을 높임 → 한 모델에 가 개면 learning rate도 개임
-
AdaGrad의 문제점: 학습이 진행됨에 따라 학습률이 급격히 감소
-
→ Adadelta는 AdaGrad의 이러한 문제점을 해결하기 위해 제안된 방법
-
Adadelta: 학습률을 적응적으로 조절하여 학습이 진행됨에 따라 지나치게 학습률이 감소되는 것을 막아줌 (AdaGrad의 값이 계속 커지는 현상 방지 위해 고안)
-
→ 얘를 사용하면 학습률을 수동으로 조정할 필요 없음
-
G를 구할 때 합을 구하는 대신에 지수 이동 평균 (Exponentia Moving Average) 를 사용하여 학습률을 적응적으로 조정
-
지수 이동 평균: 최근 데이터에 더 높은 가중치를 부여하며 과거 데이터를 점차적으로 덜 중요하게 취급하는 방식 → 학습률이 시간에 따라 적절하게 변화하면서 안정적인 학습이 가능해짐

-
- 모델 훈련된 후에, beam search를 사용하여 조건부 확률을 최대화하는 번역 찾기
- Beam search: greedy search (매 단계에서 가장 높은 확률을 가진 단어를 선택하는 방법) 의 개선된 방법으로, 매 단계에서 단 하나의 단어만을 선택하는 대신에 여러개의 후보 (상위 k개) 를 동시에 고려함
5. Results
5.1 Quantitative results
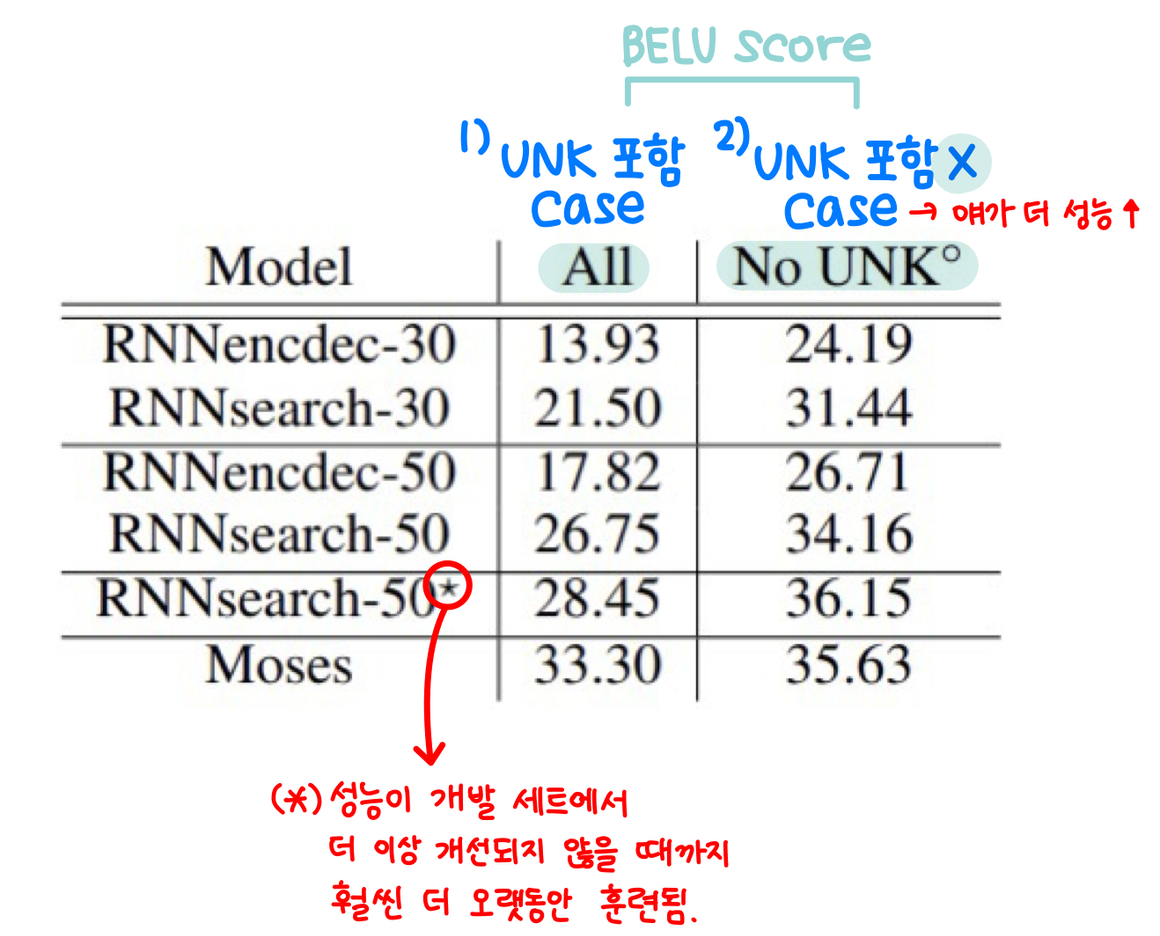 (위 그림: Table 1)
(위 그림: Table 1)
위의 표: 번역 성능을 BELU 점수로 측정한 결과를 나열한 것
-
모든 경우에서 RNNsearch > RNNencdec
-
중요한 점: RNNsearch의 성능이 Moses라는 전통적 phrase-based 시스템의 성능만큼 높음!
- only known words로만 구성된 문장 고려했을 경우임
- Moses는 RNNsearch와 RNNencdec을 훈련하는 데 사용한 병렬 코퍼스 외에도 단일 언어 코퍼스(418M 단어)를 사용한 것과 비교했을때 매우 우수한 성능임을 알 수 있음
- Moses
- SMT (통계적 기계 번역 시스템), beam search 알고리즘을 사용하여 번역 생성함
-
RNNsearch-50 > RNNsearch-30 성능 → 이 사실을 통해 제안된 모델이 기존 encoder-decoder 모델보다 뛰어남을 한번 더 확인 가능
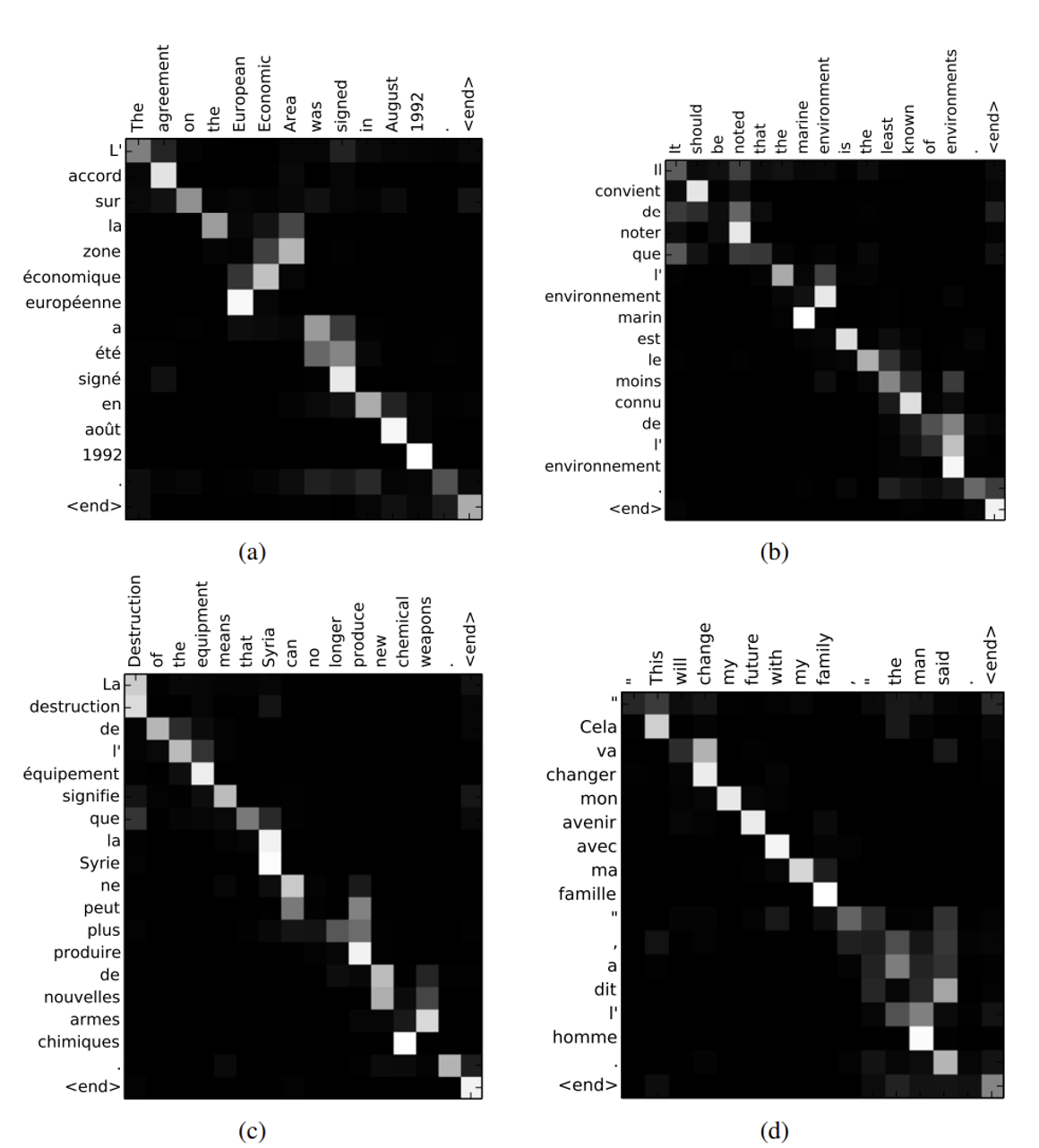
-> Figure3
위 사진: RNNsearch-50으로 나온 sample 4개
-
x축, y축 : 각각 입력 문장(영어) / 번역 (프랑스어) 단어 나타냄
-
각 픽셀은 번째 타겟 단어에 대해 번째 입력 단어의 annotation의 가중치 를 grayscale 색상으로 나타냄
- 이 정렬은 각 입력 단어가 각 입력 단어와 얼마나 잘 맞는지를 보여줌
- 0: 검정 (정렬 강도 낮음, 해당 입력 단어가 타겟 단어에 거의 기여 x)
- 1: 흰색 (정렬 강도 높음)
- → 이러한 색상 표현을 통해 각 타겟 단어가 어떤 소스 단어와 강하게 연결되어 있는지를 쉽게 시각화 가능
5.2 Qualitative Analysis
5.2.1 정렬 (Alignment)
그림 3 봤을 때,
- 제안된 접근 방식은 생성된 번역의 단어와 원본 문장의 단어 사이의 (소프트) 정렬을 검사하는 직관적인 방법을 제공함
- ←
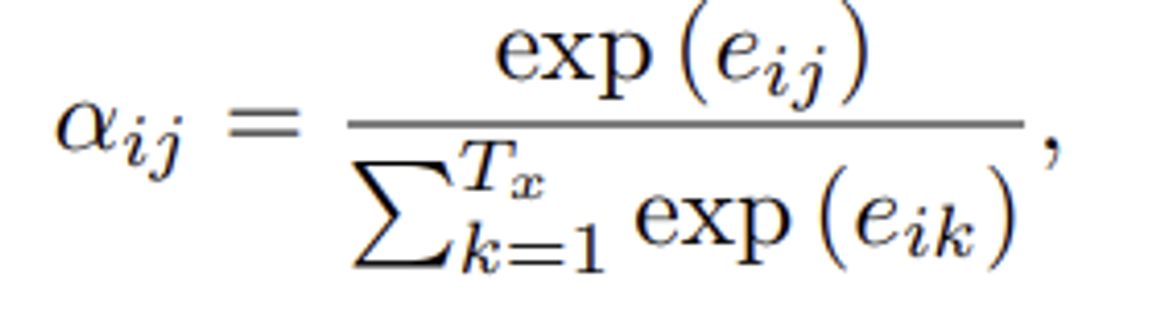
여기서의 를 시각화함으로써 .. !
-
각 플롯의 행은 annotation과 관련된 가중치 나타냄 → 타겟 단어 생성할때 원본 문장에서 어떤 위치가 더 중요한지 파악 가능
-
그림 3의 정렬을 보면, 영어와 프랑스어 간의 단어 정렬은 대체로 단조로움. 각 행렬의 대각선에 강한 가중치가 나타남. (diagonal of each matrix에서 strong weights 확인 가능)
-
그러나 비단조적인 정렬(non-trivial, non-monotonic alignments)도 여러개 관찰됨 → 형용사(Adjectives)나 명사(nouns)
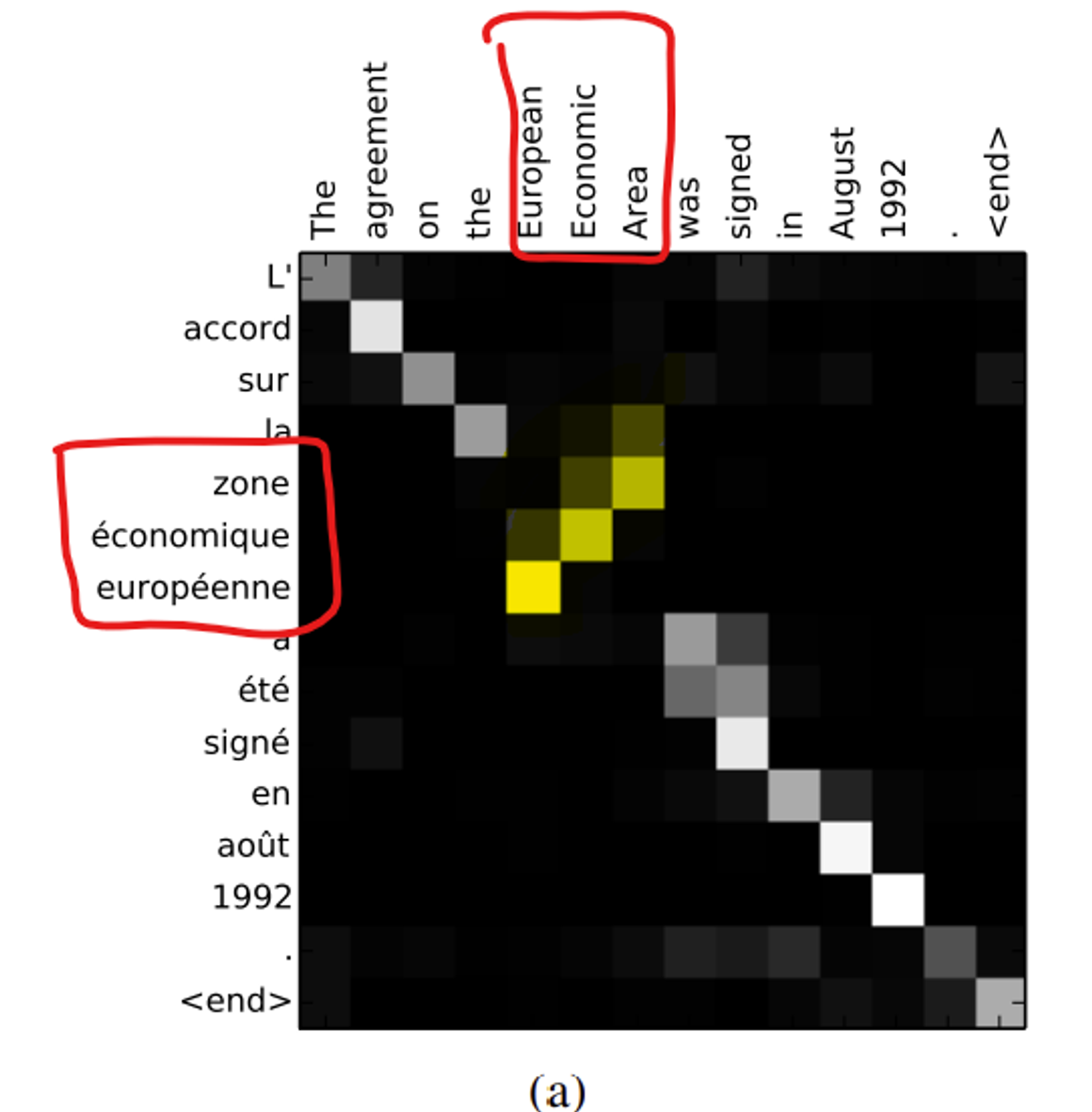
-
3(a)에서 확인 가능
-
영어-프랑스어는 형용사, 명사에서 다른 순서로 배치됨. 그러나 이 모델에서는 [European Economic Area] → [zone economique europ ´ een] 로 올바르게 번역함.
-
correctly align [zone] with [Area]
-
전체 phrase 완성 위해, [European]과 [Economic] 두 단어 jumping함.
-
-
이러한 soft-alignment 의 장점은 hard-alignment와 비교 시 더욱 명백

-
그림 3(d)
-
[the man] → [l’ homme] 번역
-
hard-alignment
- 입력 문장과 타겟 문장의 단어를 1:1로 직접 매핑 (즉, 각 단어가 하나의 대응 단어로 정확히 매핑됨)
- [the]가 [l’]로 매핑
- [man]이 [homme]으로 매핑
-
soft-alignment
- 각 소스 단어가 타겟 문장의 여러 단어에 대해 가중치를 가질 수 있음 → 각 단어의 중요도 평가
- [the]와 [man]을 동시에 고려하여 번역을 결정 가능
- [the man]이 [l’homme]으로 번역될 때, 모델이 [the]와 [man] 두개를 동시에 참조하여 [l’]로 번역할지 결정 (전체 문맥 고려하여 번역 생성)
-
-
soft-alignment의 추가 장점
- 소스와 타겟 구문이 다른 길이를 가질 때도 자연스럽게 처리 가능
- hard 정렬은 소스와 타겟 구문이 다른 길이를 가지고 있으면 1:1로 매핑이 불가능하니까 제대로 번역못하는거임 ㅜㅜ
5.2.2 long sentence
제안된 모델(RNNsearch)은 기존 모델(RNNencdec)보다 긴 문장을 번역하는 데 훨씬 더 우수함. 이는 RNNsearch가 긴 문장을 고정 길이 벡터로 완벽하게 인코딩할 필요가 없고, 특정 단어를 둘러싼 입력 문장의 부분만 정확히 인코딩하면 되기 때문.
RNNencdec은 약 30단어를 번역한 후부터는 원본 의미에서 벗어나기 시작했습니다. 그 이후로 번역 품질이 저하되었으며, 종료 인용부호가 누락되는 등의 기본적인 실수가 있었습니다. (예시 ppt에 넣기)
→ quantitative results와 함께, 이러한 qualitative observations은 RNNsearch 아키텍처가 기존 RNNencdec 모델보다 긴 문장을 훨씬 더 신뢰성 있게 번역할 수 있다는 가설을 확인시켜줌
6. Related Work
6.1 Learning to align
-
최근 Graves(연구자 이름)는 문자 시퀀스 주어지면 → 손글씨 생성 작업을 다루었고, 이 작업에서 aligning an output symbol with an input symbol (출력 기호와 입력 기호를 정렬)하는 유사한 접근 방식을 제안함
-
손글씨 합성(handwriting synthesis)의 맥락에서 나온 접근법임
-
입력 문자와 출력 문자 간의 annotation의 weight 계산 위해서 가우시안 커널 혼합(mixture of Gaussian kernels) 사용. 즉, 각 입력 문자가 출력 문자의 어느 위치와 관련이 있는지를 결정하기 위해 커널 함수를 사용
-
-
제약 조건
- annotation 가중치의 mode를 one direction으로만 제한함 (기계 번역과 같은 복잡한 작업에서 한계) 기계 번역에서는 단순히 한 방향으로의 정렬이 아니라, 문법적으로 올바른 번역을 위해 reordering이 필요할 때가 많아서 한계를 가짐
- annotation 가중치의 mode를 one direction으로만 제한함 (기계 번역과 같은 복잡한 작업에서 한계) 기계 번역에서는 단순히 한 방향으로의 정렬이 아니라, 문법적으로 올바른 번역을 위해 reordering이 필요할 때가 많아서 한계를 가짐
-
논문에서 제안한 접근법은 source sentence의 모든 단어에 대해 annotation weight를 계산하도록 함. 해당 drawback은 문장이 15-40 단어일때는 큰 문제가 되지 않지만, 문장이 더 길어지거나 복잡해진다면 문제가 생길 수 있음을 지적.
6.2 Neural networks for machine translation (신경망을 이용한 기계 번역)
기존 접근 방식과의 차별점
-
기존 접근 방식 한계:
- 기존의 기계 번역 시스템에 신경망을 추가적인 기능으로 사용한 것으로 기존 시스템의 성능을 개선하는 데 기여하기는 했지만, 이러한 접근 방식은 기존 시스템의 일부로서 신경망을 사용한다는 한계 가짐
-
논문 new system:
- 기존의 시스템과는 전혀 다른 방식
- 기존 시스템의 일부가 아닌 독립적인 모델임 !! : 기존 시스템의 일부로 작동하지 않고, 독립적으로 입력 문장에서 직접 번역을 생성함.
- 즉, 기존의 기계 번역 시스템에 신경망을 추가하는 것이 아니라, 신경망만을 사용하여 번역을 수행함
7. Conclusion
기존 NMT encoder-decoder 접근법:
전체 입력 문장을 고정 길이 벡터로 인코딩 (문제 발생 지점 ! ) -> 이 벡터를 디코딩함으로써 번역 출력
논문에서 제안하는 new architecture:
기존의 encoder-decoder 구조 확장
-
soft-search: 모델이 각 target word를 생성할 때, 입력 단어와 인코더의 hidden vector를 soft-search
- 이 방식 사용하면, 모델은 입력 문장을 고정 길이 벡터로 인코딩하지 않아도 됨. 다음 타겟 단어 생성에만 관련된 정보에 집중 가능.
- -> NMT가 긴 문장에서도 좋은 성능 얻을 수 있도록 해줌
-
new 모델 RNNsearch -> English-French task 결과
- 문장 길이에 관계없이 기존 인코더-디코더 모델(RNNencdec)보다 성능 좋음
- 정확한 번역 + 각 타겟 단어를 입력 문장에서 관련 단어나 주석과 올바르게 alignment 할 수 있음을 확인
-
기존의 구문 기반 통계적 기계 번역과 동등한 번역 성능을 달성
- 새로운 아키텍처가 제안된지 얼마 안됐음을 고려할 때, 이는 놀라운 결과임
-
모델 발전 위해 미래에 남은 과제: 알려지지 않거나 드문 단어를 잘 처리하는 것 ,,
