
read_csv()
- CSV 파일을 Pandas DataFrame 형태로 불러올 때 사용
CSV란?
CSV(Comma-Separated Values)는 몇 가지 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일
- pd.read_csv('C:/Directory/file.csv', names=['column 1', 'column 2'])
import pandas as pd
price_df = pd.read_csv(
'C:/Code/prices.csv',
names=[
'ticker', 'date', 'open', 'high', 'low', 'close',
'volume', 'adj_close', 'adj_volume'
]
)
print(price_df)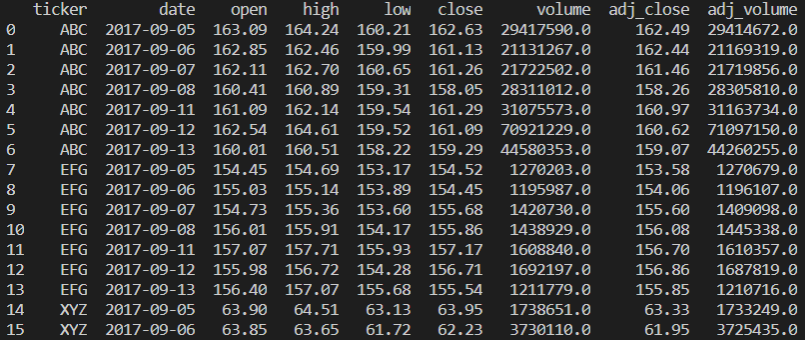
groupby()
- 특정 index(row)를 기준으로 데이터 값들을 그룹화하는 함수
Intermediate Object 중간 객체
print(price_df.groupby('ticker')) # intermediate object <pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000021B5DF65BC8>
ex. 1) 종목별 data의 중앙값
- group index: 'ticker'
- value: 전체
print(price_df.groupby('ticker').median())
ex. 2) 일일 총 거래량
- group index: 'date'
- value name: 'volume'
print(price_df.groupby('date')['volume'].sum())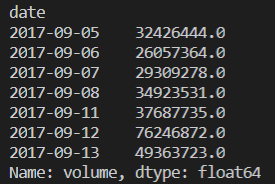
ex. 3) 종목별 최고 종가
- group index: 'ticker'
- value name: 'close'
print(price_df.groupby('ticker')['close'].max())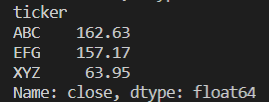
두 가지 기준으로 그룹화된 값들을 보고 싶을 땐 어떻게 해야 할까?
예를 들어, "일일 종목별 종가"를 확인하고 싶은 경우.
pivot()
- 특정 index(row)와 column을 기준으로 데이터 값들을 보여주는 함수
open_prices = price_df.pivot(
index='date', columns='ticker', values='open'
)
print(open_prices)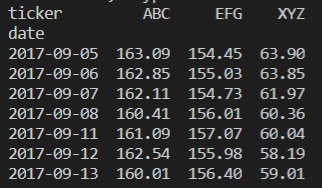
원본 DB와 pivot 테이블의 차이
입력을 받는 데이터베이스 테이블 예시
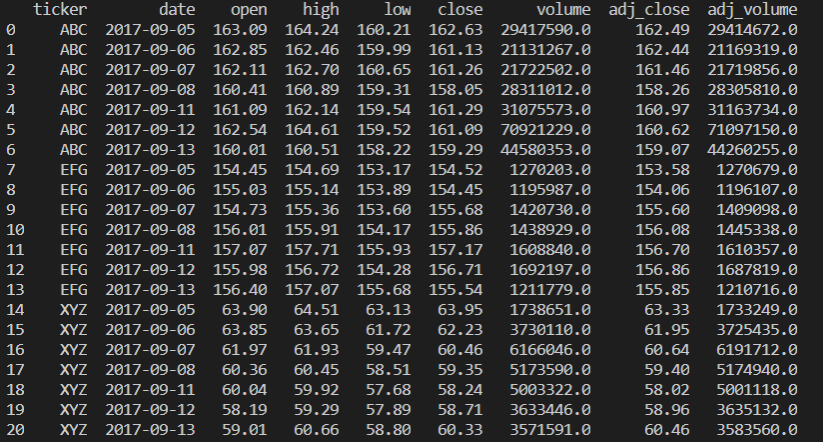
피벗 테이블 예시 (index='date', columns='ticker')

참고: pivot(피벗)이란?
- pivot: 축을 기준으로 회전하는 일
- Pivot Table에서 pivot의 정확한 의미는?
- 원본 데이터셋을 필요에 따라 취합할 때, 기준이 되는 지표

- 모든 요소는 기준이 될 수 있다.
- 그러나 좋은 데이터 분석을 위해서는 좋은 기준을 찾는 것이 무엇보다 중요하다.
