의사결정나무
- 의사결정 규칙을 나무 구조로 나타내 전체 자로를 몇개의 소집단으로 분류하거나 예측하는 분석
- 쉽고 해석이 용이하며 다중 분류와 회귀 모두 적용 가능
- 이상치에 견고하며 데이터 스케일링 불필요
- 나무가 많이 성장하면 과대적합의 오류에 빠질 수 있음
- 훈련 데이터에 민감하며, 작은 변화에도 나무의 구조게 크게 달라짐(불안정성)
-
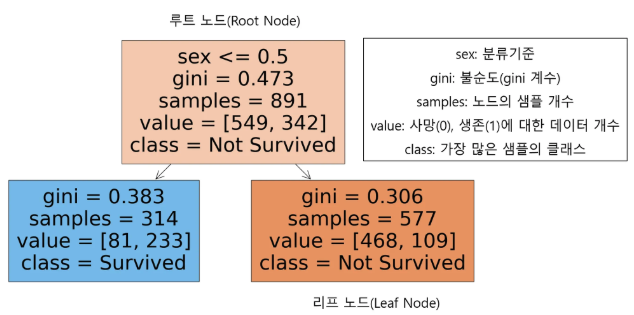
명칭
- 루트 노드(Root Node) : 의사결정나무의 시작점, 최초의 분할조건
- 리프 노드(Leaf Node) : 루트 노드로부터 파생된 중간 혹은 최종 노드
- 분류기준(criteria) : sex는 여성인 경우 0, 남성인 경우 1로 인코딩, 여성인 경우 좌측 노드로 남성인 경우 우측 노드로 분류
- 불순도(impurity)
- 불순도 측정 방법 중 하나 인 지니 계수는 0과 1사이 값으로 0이 완벽한 순도(모든 샘플이 하나의 클래스), 1은 완전한 불순도(노드의 샘플의 균등하게 분포)
- 리프 노드로 갈수록 불순도가 작아지는(한쪽으로 클래스가 분류가 잘되는)방향으로 나무가 자람
- 샘플(samples) : 해당 노드의 샘플 개수
- 값(value) : Y변수에 대한 배열
- 클래스(class) : 가장 많은 샘플을 차지하는 클래스를 표현
-
라이브러리 :
sklearn.tree.DecisionTreeClassifier,sklearn.tree.DecisionTreeRegressor
# 라이브러리
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier,plot_tree
# 데이터
titaninc_df = pd.read_csv('C:/Users/user/Documents/ML/titanic/train.csv')
titaninc_df.info()
# 분석 컬럼 설정
X_features = ['Pclass','Sex','Age','Fare','Embarked']
# 인코딩, 결측치 처리
le = LabelEncoder()
titaninc_df['Sex'] = le.fit_transform(titaninc_df['Sex'])
le2 = LabelEncoder()
titaninc_df['Pclass'] = le2.fit_transform(titaninc_df['Pclass'])
age_mean = titaninc_df['Age'].mean()
titaninc_df['Age'] = titaninc_df['Age'].fillna(age_mean)
le3 = LabelEncoder()
titaninc_df['Embarked'] = titaninc_df['Embarked'].fillna('S')
titaninc_df['Embarked'] = le3.fit_transform(titaninc_df['Embarked'])
# 모델 학습
X = titaninc_df[X_features]
y = titaninc_df['Survived']
model_dt = DecisionTreeClassifier()
model_dt.fit(X,y)
# 시각화
plt.figure(figsize = (10,5))
plot_tree(model_dt, feature_names=X_features, class_names=['Not Survived','Survived'], filled= True)
plt.show()랜덤 포레스트
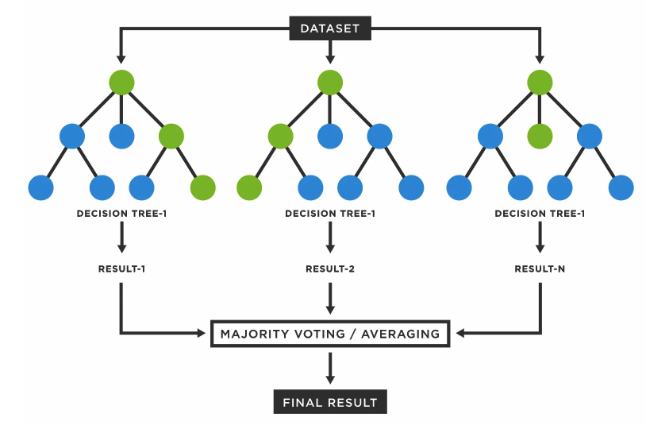
- 나무를 여러개 만들어 숲을 만드는 것
- 의사결정나무의 장점은 수용하고 단점을 보완해, 일반적으로 굉장히 뛰어난 성능을 보임
- Bagging 과정을 통해 과적합을 피함
- 변수 중요도를 추출하여 모델 해석에 중요한 특징을 파악할 수 있음
- 다만 컴퓨터 리소스 비용이 크고, 앙상블 적용으로 해석이 어려움
Bagging
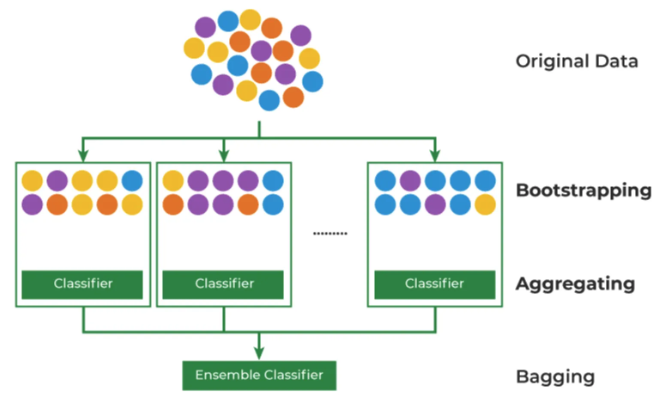
- 데이터 부족을 해결하기 위해 Bootstrapping + Aggregating 방법론을 합침
- Bootstrapping: 데이터를 복원 추출해서 유사하지만 다른 데이터 집단을 생성하는 것
- Aggregating: 데이터의 예측,분류 결과를 합치는 것
- Ensemble(앙상블): 여러 개의 모델을 만들어 결과를 합치는 것
# 라이브러리
from sklearn.linear_model import LogisticRegression # 로지스틱회귀
from sklearn.tree import DecisionTreeClassifier # 의사결정나무
from sklearn.ensemble import RandomForestClassifier # 랜덤포레스트
from sklearn.metrics import accuracy_score,f1_score # 평가
# 모델 정리
model_lor = LogisticRegression()
model_dt = DecisionTreeClassifier(random_state=42)
model_rf = RandomForestClassifier(random_state=42)
# 데이터 설정
X_features = ['Pclass','Sex','Age','Fare','Embarked']
X = titaninc_df[X_features]
y = titaninc_df['Survived']
# 훈련
model_lor.fit(X,y)
model_dt.fit(X,y)
model_rf.fit(X,y)
# 예측
y_lor_pred = model_lor.predict(X)
y_dt_pred = model_dt.predict(X)
y_rf_pred = model_rf.predict(X)
# 평가 함수 정의
def get_score(model_name, y_true, y_pred):
acc = accuracy_score(y_true, y_pred).round(3)
f1 = f1_score(y_true,y_pred).round(3)
print(model_name, 'acc 스코어 : ',acc, 'f1_score : ', f1)
# 평가
get_score('lor',y,y_lor_pred)
get_score('dt ',y,y_dt_pred)
get_score('rf ',y,y_rf_pred)
# 변수 중요도 추출
model_rf.feature_importances_최근접 이웃(K-Nearest Neighbor, KNN)
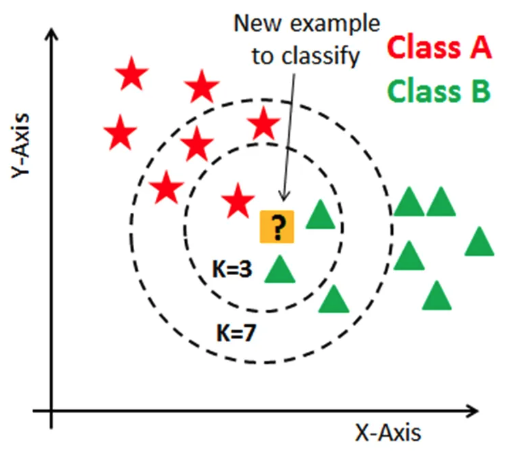
- 주변의 데이터를 보고 내가 알고 싶은 데이터를 예측하는 방식
- 이해하기 쉽고 직관적임
- 모집단의 가정이나 형태를 고려하지 않으며 회귀, 분류 모두 가능
- 차원 수가 많을수록 계산 량이 많아짐
- 거리 기반의 알고리즘이기 때문에 피처의 표준화 필요
- 라이브러리 :
sklearn.neighbors.KNeighborsClassifier,sklearn.neighbors.KNeighborsRegressor - 하이퍼 파라미터 : 기계 학습 모델 훈련을 관리하는데 사용하는 외부 구성 변수이며 모델 학습 과정이나 구조에 영향을 미침
- 유클리드 거리 : 두 점의 좌표를 피타고라스 정리로 거리 계산
# 라이브러리
from sklearn.neighbors import KNeighborsClassifier
# 모델링
model_knn = KNeighborsClassifier()
# 데이터 설정
X_features = ['Pclass','Sex','Age','Fare','Embarked']
X = titaninc_df[X_features]
y = titaninc_df['Survived']
# 학습
model_knn.fit(X,y)
# 예측
y_knn_pred = model_knn.predict(X)
# 평가 함수 정의
def get_score(model_name, y_true, y_pred):
acc = accuracy_score(y_true, y_pred).round(3)
f1 = f1_score(y_true,y_pred).round(3)
print(model_name, 'acc 스코어 : ',acc, 'f1_score : ', f1)
# 평가
get_score('knn',y,y_knn_pred)부스팅 알고리즘
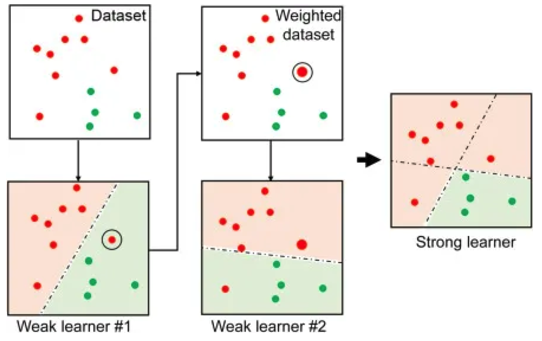
- 여러개의 약한 학습기를 순차적으로 학습하면서 잘못 예측한 데이터에 가중치를 부여해 오류를 개선해 나가는 학습 방식
종류
- Gradient Boosting Model : 가중치 업데이트를 경사하강법 방법을 통해 진행
- 라이브러리 :
sklearn.ensemble.GradientBoostingClassifier,sklearn.ensemble.GradientBoostingRegressor
- 라이브러리 :
- XGBoost : 트리기반 앙상블 기법으로 병렬학습이 가능해 속도가 빠름
- 라이브러리 : -
xgboost.XGBRegressor
- 라이브러리 : -
- LightGBM : XGBoost보다 학습시간이 짧고 메모리 사용량이 작음, 작은 데이터(10,000건 이하)의 경우 과적합 발생
- 라이브러리 :
lightgbm.LGBMClassifier,lightgbm.LGBMRegressor
- 라이브러리 :
# 라이브러리
!pip install xgboost
!pip install lightgbm
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
# 모델링
model_gbm = GradientBoostingClassifier(random_state= 42)
model_xgb = XGBClassifier(random_state= 42)
model_lgb = LGBMClassifier(random_state= 42)
# 데이터 설정
X_features = ['Pclass','Sex','Age','Fare','Embarked']
X = titaninc_df[X_features]
y = titaninc_df['Survived']
# 학습
model_gbm.fit(X,y)
model_xgb.fit(X,y)
model_lgb.fit(X,y)
# 예측
y_gbm_pred = model_gbm.predict(X)
y_xgb_pred = model_xgb.predict(X)
y_lgb_pred = model_lgb.predict(X)
# 평가 함수 정의
def get_score(model_name, y_true, y_pred):
acc = accuracy_score(y_true, y_pred).round(3)
f1 = f1_score(y_true,y_pred).round(3)
print(model_name, 'acc 스코어 : ',acc, 'f1_score : ', f1)
# 평가
get_score('gbm ',y,y_gbm_pred)
get_score('xgb ',y,y_xgb_pred)
get_score('lgb ',y,y_lgb_pred)
👋🏻