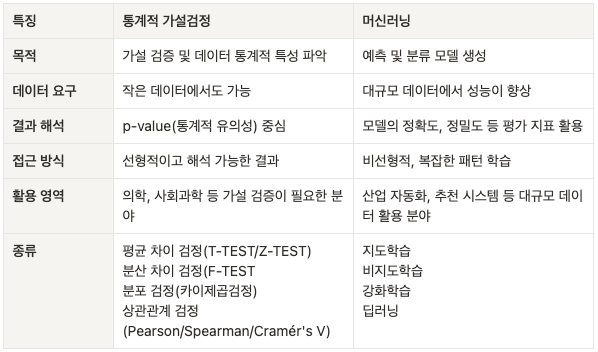
통계와 머신러닝
- 통계적 가설검정이 머신러닝을 보완하는 경우
- 머신러닝 모델의 피처 선택(컬럼 선택)에서 유의미한 변수를 찾기 위해 통계적 가설검정 사용
- 데이터 분포, 이상치 처리 등 데이터 전처리에 유용한 통계적 기법을 제공
- 머신러닝이 가설검정을 보완하는 경우
- 비선형 데이터의 관계를 처리링하거나 대규모 데이터에서 가설 검정의 한계를 보완
- 통계적 가설검정은 변수 간 독립성을 가정하고 진행되지만, 머신러닝은 이러한 제약 없이 상관 및 연관성 탐지
- 두가지 방법론의 융합
- 통계적 가설검정을 사용해 데이터 탐색 및 초기 분석을 수행한 후, 머신러닝을 통해 예측 성능을 극대화
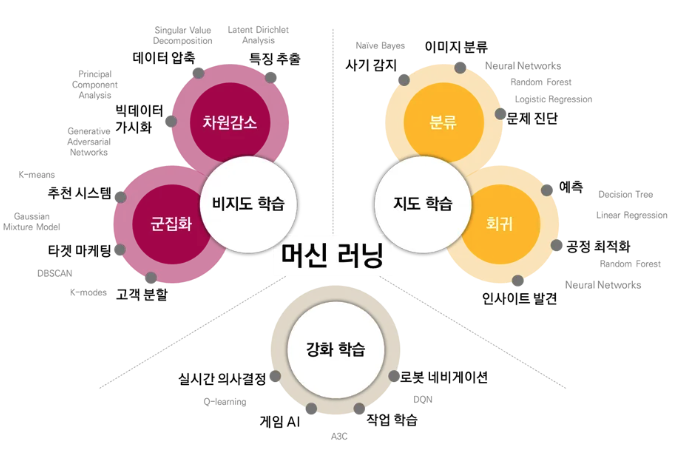
지도학습
- 정답이 있는 데이터(labelled data)를 활용해 훈련 데이터로부터 프로그램 등을 학습시켜 결과에 대한 예측을 만듦
종류
- 회귀 : 예측값으로 연속적인 값 출력
- 분류 : 예측값으로 이산적인 값을 출력
기법
- 선형 회귀(Linear Regression)
- 로지스틱 회귀(Logistic Regression)
- 나이브 베이즈(Naive Bayes)
- K-최근접 이웃(k-Nearest Neighbors)
- 서포트 벡터 머신(SVM, Support Vector Machine)
- 의사결정 트리(Decision Tree)
- 랜덤 포레스트(Random Forest)
- 인공신경망(Neural Network)
RFM(분류) 분석
- Recency(최근성) : 최근에 구매한 고객일수록 더 가치있음
- Frequency(빈도) : 빈도가 높을수록 가치있음
- Monetary(구매금액) : 구매금액이 높을수록 가치있음
비지도학습
- 정답이 없는 데이터(Unlabelled data)를 분석함으로써 그 안에 숨어있는 패턴을 찾아내거나 데이터를 그룹화 시키는 알고리즘
군집화
- 비슷한 특성끼리 묶음
- 프로세스
- 기간 선정
- K값(군집개수), 초기 컬럼(피쳐) 선정
- 이상치 기준 선정 및 제외
- 표준화
- 차원 축소
- PCA PLOT으로 군집 밀도 확인
- 2~7번 과정을 반복하며 최적의 결과 도출
- 모델링(Random Forest)
- 데이터 적재 및 자동화 설정
기법
- 군집(Clustering)
- K-means 클러스터링
- 위계적 군집분석
- 가우시안 혼합모형(Gaussian Mix Texture Model)
- 주성분 분석(PCA)
- LLE(Locally Linear Embedding)
- Isomap
- MDS(Multi Dimensional Scaling
- t-SNE(t-distributed Stochastic Neighbor Embedding)

👋🏻