1. 문제정의
- 모델로 해결하고 싶은 문제가 무엇인지 확실하게 정의함
- 타겟이 있는 데이터인지?
- 타겟이 있다면 분류 문제인지? 예측인지?
- 타겟이 없다면 어떤 가치를 뽑아내고 싶은지?
- 문제에 대한 접근 방식 설정
- 가설설정
- 모델설정
2. 데이터 전처리
데이터 수집
- 문제 해결에 사용하기 위한 데이터 수집
- 바로 확보 가능한지?
- 노력하면 획득 가능한 데이터인지? ex) api, 크롤링 등
- 확보하기 어려운 데이터인지?
데이터 클리닝
- 분석에 적합한 형태로 데이터 정제 및 가공
- 데이터 타입 확인
- 결측치 처리 및 이상치 제거
- 정규화(Normalization)가 필요하다면 정규화 진행
피쳐 엔지니어링(Feature Engineering)
- 다양한 독립변수 중에서 분석에 활용하기 위한 변수를 선택하거나, 필요에 따라 새로운 변수를 생성하는 과정
- 도메인 지식 활용
- 탐색적 데이터 분석(EDA)을 통해 변수 상관관계 분석
데이터 분할
- 분석에 사용하기 위한 데이터를 나누는 작섭
- Train/Test 데이터로 구분하거나, Train/Validation/Test로 구분
- Train과 Test 비중은 보통 6:4 혹은 7:3 수준
- 시계열 데이터의 경우 특정 시점을 기준으로 데이터를 나눔
- 한 번에 학습하기에 양이 많으면 batch 단위로 구분
3. 모델링
과정
- 학습에 사용할 모델을 선택 및 생성
- 학습 데이터를 통해 모델 학습
- 테스트 데이터를 이용해 모델을 이용한 예측 진행
- 성능 지표를 통해 모델의 성능 평가
- 모델 성능을 끌어올리기 위해 하이퍼 파라미터 값을 변경하며 위 과정 반복
모델 종류
- 지도학습 - 분류 및 예측
- 선영 회귀(예측)
- 로지스틱 회귀(분류)
- 나이브 베이즈(분류)
- 서포트 벡터 머신(분류, 예측)
- 랜덤 포레스트(분류, 예측)
- 다중 퍼셉틑론(분류, 예측)
- 비지도학습 - 군집분석
- 주성분 분석(PCA)
- 계층적 군집화
- K-means
- DBSCAN
- 대부분의 머신러닝 모델은 sklearn을 활용해 구현 가능
성능 지표
- 분류 모델
- 정확도(Accuracy)
- 정밀도(Precision)
- 재현율(Recall)
- 예측 모델
- MSE(Mean Squared Error)
- RMSE(Root Mean Squared Error)
- MAE(Mean Absolute Error)
- 군집 분석의 경우 군집화된 결과물을 확인하며 성능 평가
하이퍼 파라미터(Hyper Parameter)
- 모델을 학습하기 전 사용자가 직접 값을 설정해줘야 하는 변수
- 동일한 모델이라도 어떤 값을 설정하느냐에 따라 모델 성능이 달라짐
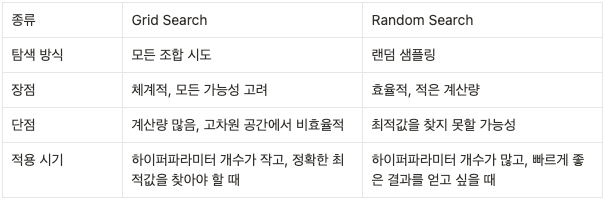
- 탐색 방식 : Grid Search, Random Search
주의점 : 오버피팅(Overfitting)
- 오버피팅(과적합) : 머신 러닝 모델이 학습 데이터에 과도하게 맞춰져 새로운 데이터에 대해 일반화가 떨어지는 현상
- 방지법
- 모델 단순화 : 독립변수를 일부만 추려 일반화 성능을 높임
- 데이터 증강 : 보다 많은 데이터를 활용해 일반화 성능을 높임
- 규제 적용 : L1, L2 규제를 활용해 오버피팅 방지
- L1 규제(Lasso) : 일부 변수의 가중치를 0으로 만들어 피쳐 선택 효과를 가짐
- L2 규제(Ridge) : 모든 변수의 가중치를 작게 만들어 과적합을 방지하고 일반화 성능을 향상시킴
- 교차검증 사용 : K-Fold 교차 검증(전체 데이터를 K개의 서로 다른 조각으로 나눠서 이를 학습 데이터와 검증 데이터로 번갈아 사용하는 방식)
4. 배포
- 학습된 모델을 서비스화 하는 것

👋🏻