분류 모델
- 지도학습은 크게 분류와 예측 두 가지로 나눌 수 있음
- 타겟 변수가 범주형 변수인 경우의 모델
- 만약 연속형 변수에 대해 분류 모델로 접근하고 싶으면 타겟 변수를 범주형으로 변환하여 수행 가능
성능 지표
- 혼동 행렬(Confusion Matrix)
- 모델이 예측한 결과와 실제 결과를 비교하여 만들어진 행렬
- 모델의 분류 성능을 한 눈에 알 수 있어서 편리함
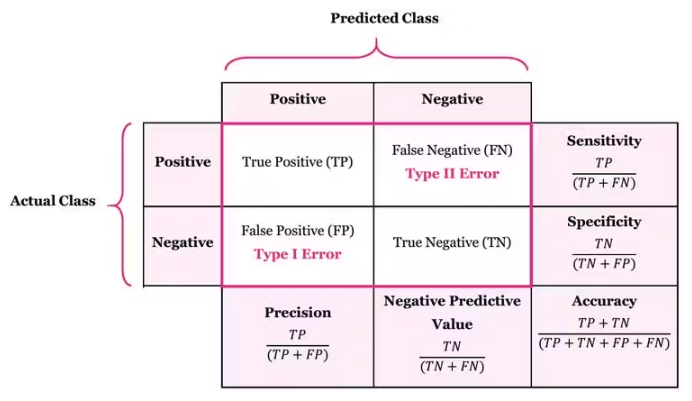
- TP(True Positive): 실제 양성을 양성으로 분류한 경우
- FP(False Positive): 실제 음성을 양성으로 분류한 경우
- TN(True Negative): 실제 음성을 음성으로 분류한 경우
- FN(False Negative): 실제 양성을 음성으로 분류한 경우 - 지표
- 정확도(Accuracy) : 전체 데이터에서 실제 값을 제대로 맞춘 비율
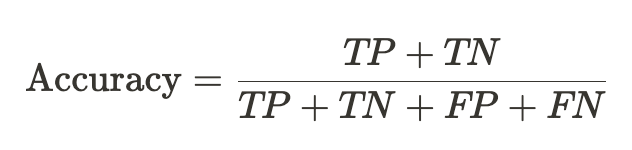
- 정밀도(Precision) : 모델이 양성으로 분류한 값 중에서 실제 양성의 비율

- 민감도(Sensitivity) = 재현율(Recall) : 실제 값이 양성인 데이터 중에서 양성으로 분류한 비율
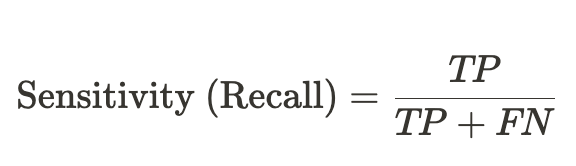
- F1 Score : 정밀도와 재현율의 조화 평균
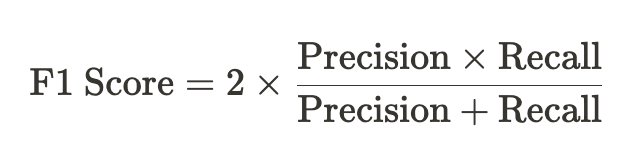
- 정확도(Accuracy) : 전체 데이터에서 실제 값을 제대로 맞춘 비율
모델 종류
- 로지스틱 회귀(Logistic Regression)
- K Nearest(K-NN)
- 나이브 베이즈(Naive Bayes)
- 서포트 벡터 머신(Support Vector Machine)
- 랜덤 포레스트(Random Forest)
- 다층 퍼셉트론 (Multi-Layer Perceptron)
로지스틱 회귀 분석 (Logistic Regression)
- 독립 변수의 선형 결합을 이용해서 사건의 발생 가능성(확률)을 예측하는 데 사용되는 모델
- 타겟 변수가 주로 두 개의 범주(Yes/No)인 경우에 주로 사용
- 오즈 (Odds) : 성공 확률이 실패 확률에 비해 몇 배 더 높은지를 나타냄
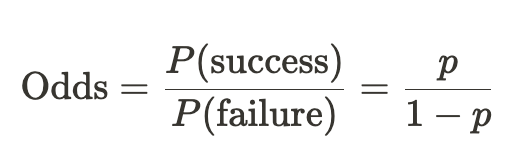
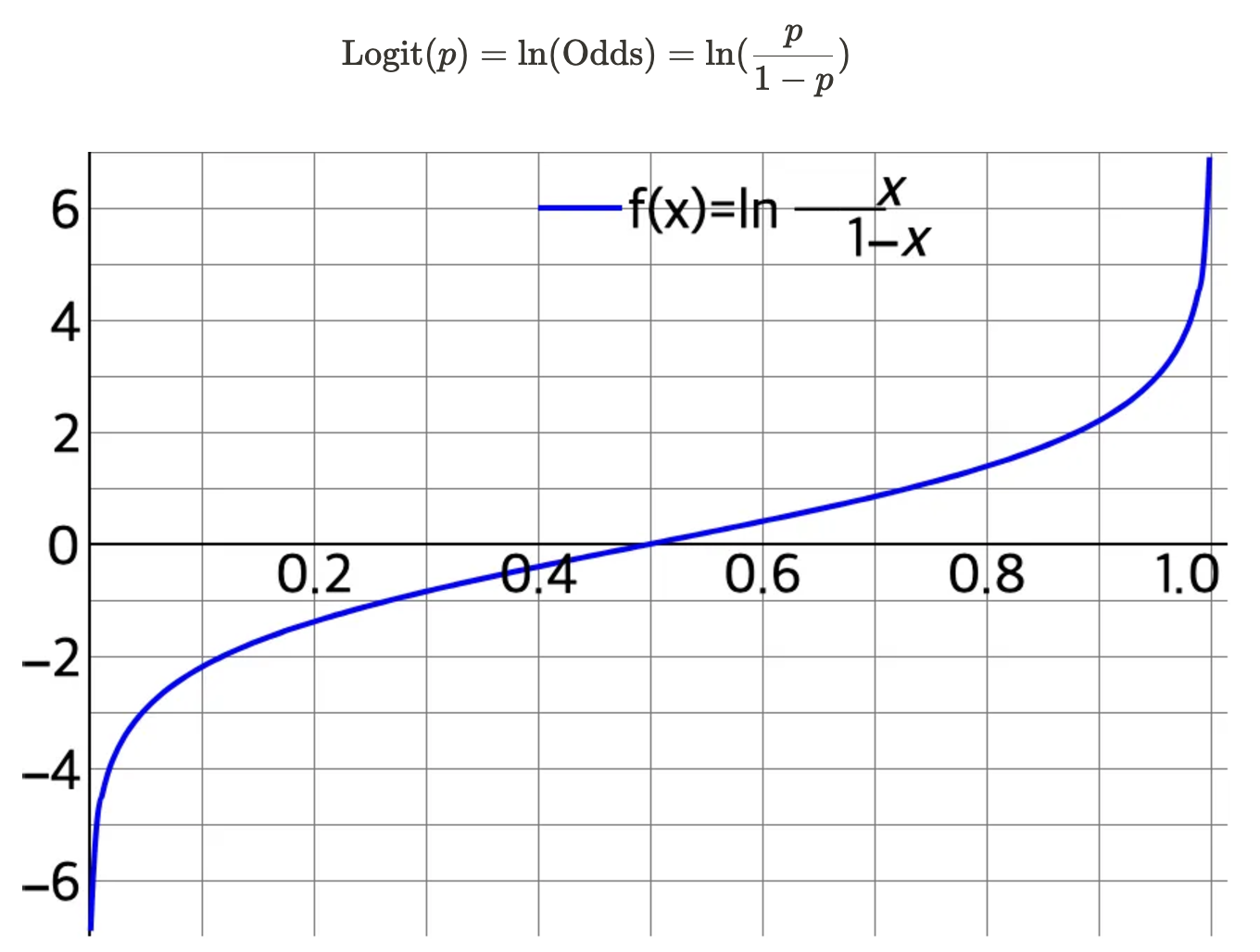
- 로짓 (Logit) : 오즈에 로그를 취한 값, 확률 p에 대해 (−∞,+∞) 범위로 출력값을 조절
- 로지스틱 함수 : 선형 회귀식의 결과를 0과 1 사이의 확률값으로 변환하는 함수
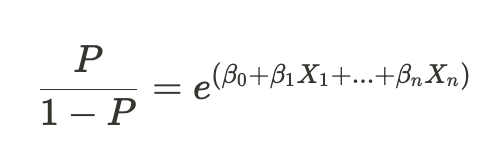
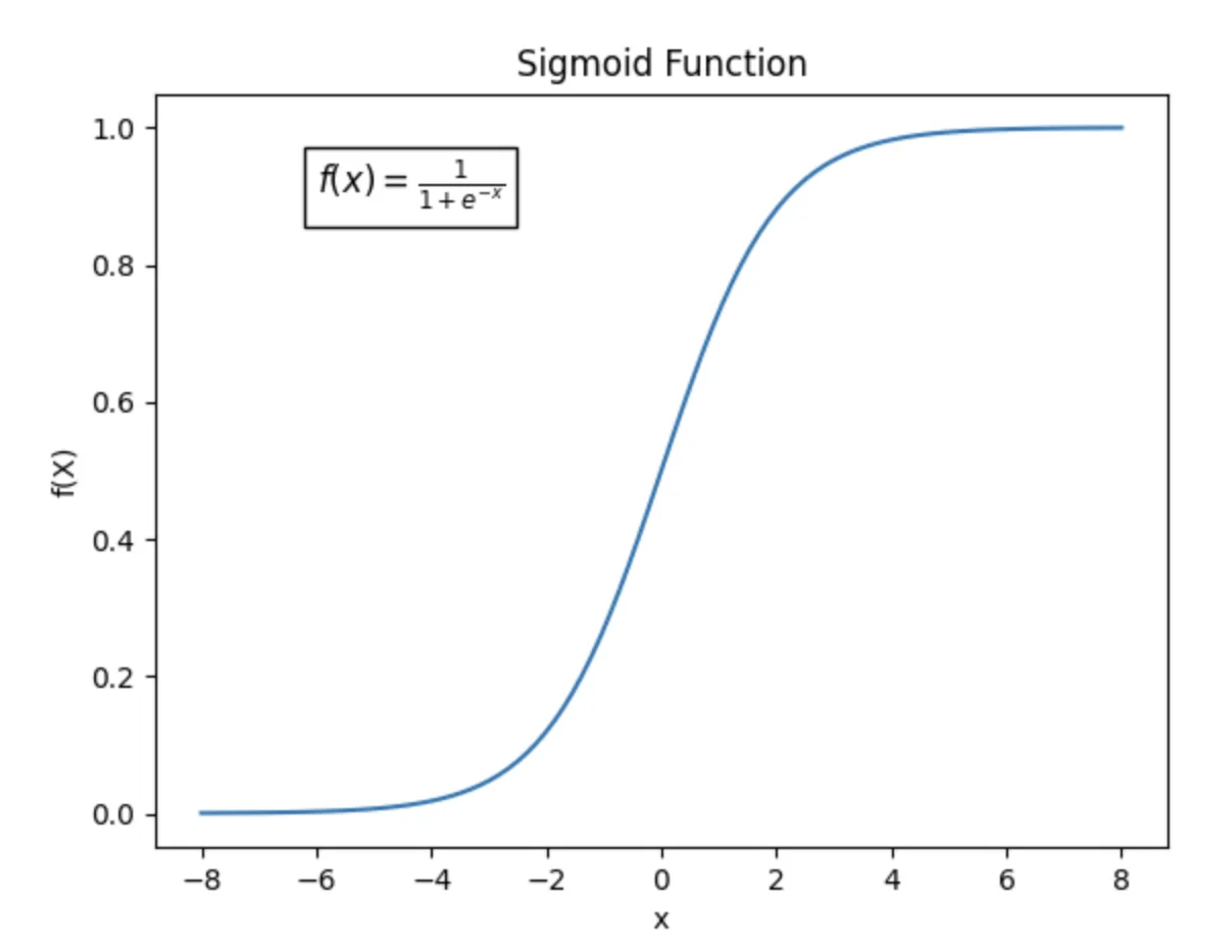
다중 클래스 분류
- 로지스틱 회귀 분석은 이진 분류에 주로 사용되지만, 클래스가 3개 이상인 다중 클래스 분류에도 활용할 수 있음
- 방법
- One-Hot encoding을 통해 N개의 클래스를 N 차원의 벡터로 변환
- 각각의 차원에 대해서 로지스틱 회귀 분석 수행
- 각 차원의 예측값은 해당 클래스에 분류될 확률
- 확률이 가장 높게 나온 클래스로 해당 데이터를 분류 -> Hard Clustering
랜덤 포레스트 (Random Forest)
- 여러 개의 의사결정나무(Decision Tree)를 학습시켜 성능을 높이는 앙상블 학습 방법
의사결정나무(Decision Tree)
- 한 번에 하나의 기준으로 데이터를 두 그룹으로 분류
- 데이터를 분류할 때는 불순도가 낮아지는 방향으로 분류
앙상블 (Ensemble)
- 하나의 모델을 사용하는 것이 아닌, 여러 개의 모델을 결합하여 모델의 성능을 높이는 방식
- ex) 배깅 (Bagging), 부스팅 (Boosting)
랜덤 포레스트 (Random Forest)
- 여러 개의 의사결정나무를 결합하여 분류 및 예측 모델에 활용하는 모델로 대표적인 앙상블 모델 중 하나
- 각각의 트리를 학습할때마다 Feature의 일부만을 랜덤하게 선택하여 사용
- 여러 의사결정나무에서 분류한 결과에서 투표를 통해 최종 결과를 선택
- Feature Importance : 의사결정나무를 학습할 때 어떤 Feature가 많이 사용되었는지에 따라서 모델 생성에 중요하게 동작한 Feature를 선정할 수 있음

👋🏻