클러스터링(Clustering)
- 정답이 없을 때 정답을 찾아가는 과정으로, 피쳐(컬럼) 유사성의 개념을 기반으로 전체 데이터셋을 그룹으로 나누는 그룹핑 기법
- 의미있는 특징(컬럼)을 찾고, 최적의 그룹 개수를 찾아 그룹별 인사이트를 도출해야 함
프로세스
pre-processing
-
기간 설정 : 데이터 기간 설정, 의미있는 패턴을 도출하기 위해 최소 3개월 이상의 데이터셋 권장
-
이상치 기준 선정 및 제외 : IQR, Z-SCORE 등 다양한 이상치 기법 사용 및 기록
- Z-Score
- 데이터 분포가 정규 분포를 이룰 때, 데이터의 표준 편차를 이용해 이상치를 탐지하는 방법
- Z값은 X에서 평균을 뺀 데이터를 표준편차로 나눈 값이며, 표준 점수라고 함
- 표준 점수는 평균으로부터 얼마나 멀리 떨어져 있는지를 보여주며, 일반적으로 -3에서 3 사이의 값을 가지고 있어 ±3 이상이면 이상치로 간주
- Z-Score가 0이면 해당 데이터는 평균과 같음을 의미함
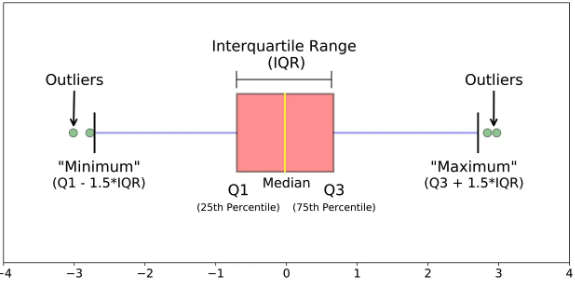
- IQR(Interquartile Range)
- 데이터 분포가 정규 분포를 이루지 않을 때 사용
- 데이터의 25% 지점과 75% 지점 사이의 범위를 사용 함
- 제 3사분위 값 - 제 1 사분위 값
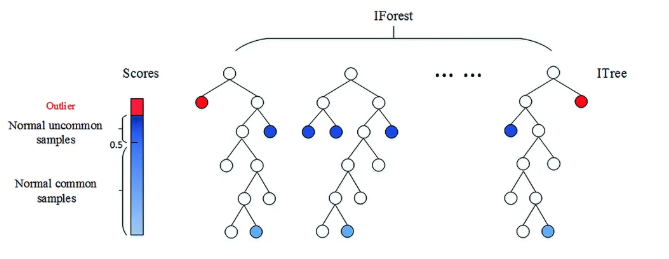
- Isolation Forest
- 머신러닝 기법 중 하나로 컬럼 개수가 많을 때 이상치를 판별하기 용이함
- 데이터셋을 결정트리 형태로 표현
- 경로 길이로 점수는 0에서 1사이로 산출되며, 결과가 1에 가까울수록 이상치로 간주
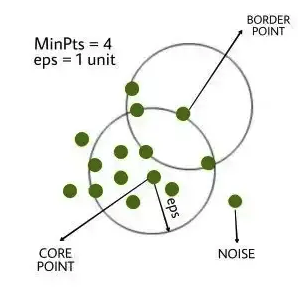
- DBScan
- 밀도 기반의 클러스터링 알고리즘으로 어떠한 클러스터에도 포함되지 않는 데이터를 이상치로 탐지하는 방법
- 복잡한 구조의 데이터에서 유용
- 주로 지리 데이터, 이미지 데이터 분석에서 사용
- 표준화 : 데이터 크기가 너무 크거나 컬럼간 데이터 range에 차이가 많을 때 일부 컬럼에 대해 진행
- minmax scale
- 모든 데이터의 값을 0과 1사이에 배치함
- 이상치에 약함
- standard scale
- 평균을 0, 표준편차를 1로 변환
- 평균으로부터 얼마나 떨어져 있는지에 대한 수치를 변환
- 군집 분석 시 가장 많이 쓰이는 표준화 기법
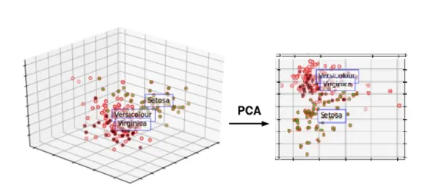
- 차원 축소(PCA)
- 많은 컬럼으로 구성된 다차원 데이터 세트의 차원을 축소해 새로운 차원의 데이터 세트를 생성하는 것
- 여러 변수 간에 존재하는 상관관계를 이용해 이를 대표하는 주성분을 추출해 차원을 축소하는 기법
- 가장 높은 분산을 가지는 데이터의 축을 찾아 그 축으로 차원을 축소하는 것이며, 이 축을 주성분이라고 함
Experiment
- K값(군집개수), 초기 컬럼(피쳐) 선정
-
Silhouette Coefficient : 각 군집간의 거리가 얼마나 효율적으로 분리되어 있는지
- 실루엣 계수는 -1에서 1사이의 값을 가짐
- -1이나 1에 가까울수록 근처의 군집과 멀리 떨어져 있는 것으로 군집간 거리가 유의미하게 구분된다는 것을 의미함
- 0에 가까울수록 근처 군집과 가깝다는 뜻
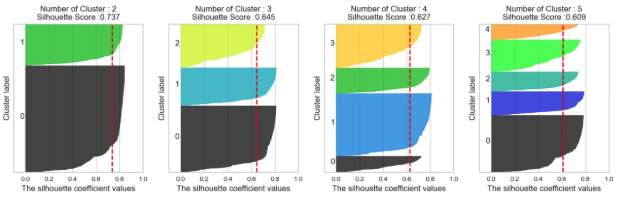
-
scree plot 의 elbow-point : 알고리즘이 군집이 나뉘는 시간까지 고려한 k값 도출
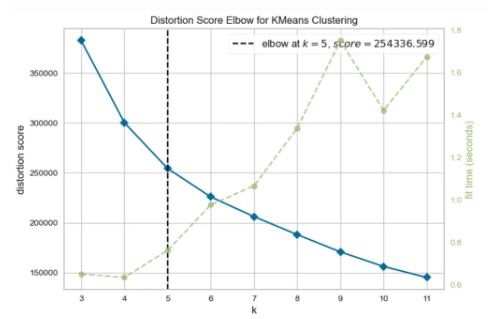
-
Distance Map : 군집 간 거리를 시각화 해주는 기법
- 실행마다 다르게 보여질 수 있으나, 군집이 떨어져 있는 거리를 가시적으로 확인하기 위한 참고치일뿐
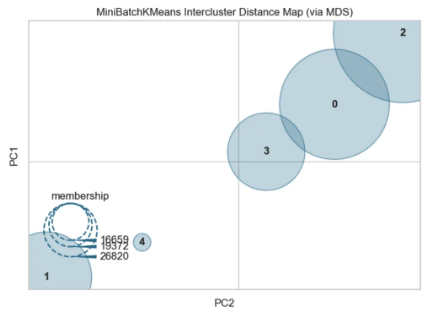
- 실행마다 다르게 보여질 수 있으나, 군집이 떨어져 있는 거리를 가시적으로 확인하기 위한 참고치일뿐
- k-means clustering 시행 : 데이터를 거리기반 K개의 군집(Cluster)으로 묶는(Clusting) 알고리즘
- 알고리즘 : 군집수 K 설정 -> 초기 중심점 K개 설정 -> 중심점을 기준으로 data point들의 거리를 비교하고 더 가까운 중심점에 군집 할당 -> 할당된 점들의 중심점으로 위치 조정 -> 중심점의 위치가 변하지 않을때까지 반복
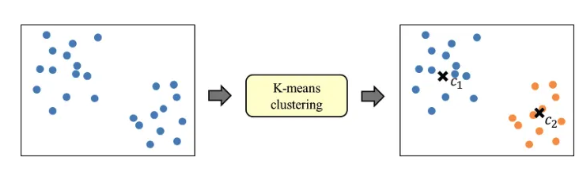
-
군집 분포 확인 : 데이터셋을 기반으로 데이터가 얼마나 밀도있게 나뉘었는지 확인하는 과정
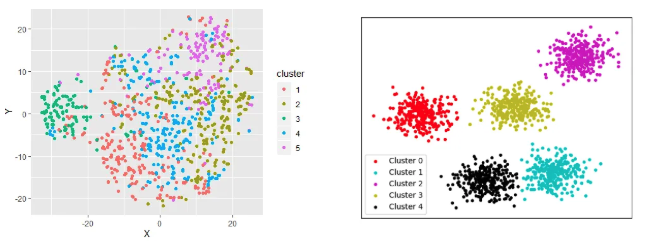
-> 왼쪽은 군집이 잘 나눠지지 않았고, 오른쪽은 군집별 특성이 명확함 -
2~7번 과정을 반복하며 최적의 결과 도출 : 다양한 기준 고려
- 데이터에 결측이 많지는 않은지?
- 데이터가 결측은 아니나, value가 0인 경우가 많은지?
- 데이터의 전반적인 분포는 어떠한지? 컬럼 간 상관계수는 어떤지?
- 데이터가 불규칙한지?
- 컬럼이 가지는 개념적인 의미는 무엇인지?
- 컬럼값이 이진형인지?
- 클러스터 비중이 지나치게 편향되어 있는지?
-
모델링 : 클러스터링 결과를 가지고 모델에 학습
-
데이터 적재 및 자동화 설정 : python을 통해 클러스터별로 나뉜 고객들을 별도 테이블에 저장, 스케줄 기능을 통해 주기별로 라이브한 데이터를 자동 테이블에 적재
-
인사이트 도출 : 적제된 테이블을 통해 클러스터별 인사이트 도출
코드
# 기본 라이브러리 import
import pandas as pd
import numpy as np
# 시각화 라이브러리 import
import seaborn as sns
import matplotlib.pyplot as plt
# 표준화 라이브러리 import
from sklearn.preprocessing import StandardScaler
# k 값 참고: scree plot을 통한 k 값 확인을 위한 라이브러리 import
from yellowbrick.cluster import KElbowVisualizer
# k 값 참고: distance map 라이브러리 import
from yellowbrick.cluster import intercluster_distance
from sklearn.cluster import MiniBatchKMeans
# k 값 참고: 실루엣 계수 확인을 위한 라이브러리 import
from sklearn.metrics import silhouette_score
# 데이터셋 주성분 분석중 하나인 pca 를 수행하기 위한 라이브러리 import
from sklearn.decomposition import PCA
# k-means 알고리즘 활용을 위한 라이브러리 import
from sklearn.cluster import KMeans
import warnings
warnings.filterwarnings('ignore')
# 데이터셋 로드
base_df = pd.read_csv('merge_df.csv')
# 결측치 확인
base_df.isnull().sum()
# 클러스터링 할 컬럼 지정
feature_names=['customer_zip_code_prefix','price','shipping_charges','payment_sequential','payment_value']
# 지정된 컬럼으로 새로운 dataframe 생성
base_df = pd.DataFrame(base_df, columns=feature_names)
# 표준화
# 표준화 방식: standard scaler (평균0, 분산1)
scale_df = StandardScaler().fit_transform(base_df)
# 주성분 개수를 판단하기 위한 pca임의 시행
pca = PCA(n_components=3)
pca.fit(scale_df)
# 설정한 주성분의 갯수로 전체 데이터 분산을 얼만큼 설명 가능한지
pca.explained_variance_ratio_.sum()
# pca 시행
pca_df = pca.fit_transform(scale_df)
pca_df = pd.DataFrame(data = pca_df, columns = ['PC1','PC2','PC3'])
# Show the first 5 firms
pca_df.head()
# 초기 k 값 참고를 위한 scree plot 을 그리고, 군집이 나뉘는 시간까지 고려한 k 값 확인
model = KMeans()
# k 값의 범위를 조정해 줄 수 있습니다.
visualizer = KElbowVisualizer(model, k=(3,12))
# 데이터 적용
visualizer.fit(pca_df)
visualizer.show()
# 초기 k 값 참고를 위한 distance map 시각화
# 그룹의 갯수를 지정해 줄 수 있습니다. 저는 5로 적어두었습니다.
intercluster_distance(MiniBatchKMeans(5, random_state=42), pca_df)
# KMEANS
# 군집개수(n_cluster)는 5,초기 중심 설정방식 랜덤,
kmeans = KMeans(n_clusters=5, random_state=42,init='random')
# pca df 를 이용한 kmeans 알고리즘 적용
kmeans.fit(pca_df)
# 클러스터 번호 가져오기
labels = kmeans.labels_
# 클러스터 번호가 할당된 데이터셋 생성
kmeans_df = pd.concat([pca_df, pd.DataFrame({'Cluster':labels})],axis = 1)
# 클러스터 번호가 할당된 데이터셋 생성
kmeans_df
# 3차원으로 시각화
x =kmeans_df["PC1"]
y =kmeans_df["PC2"]
z =kmeans_df["PC3"]
fig = plt.figure(figsize=(12,10))
ax = plt.subplot(111, projection='3d')
ax.scatter(x, y, z, s=40, c=kmeans_df["Cluster"], marker='o', alpha = 0.5, cmap = 'Spectral')
ax.set_title("The Plot Of The Clusters(3D)")
plt.show()
# 2차원으로 시각화
plt.figure(figsize=(8,6))
sns.scatterplot(data = kmeans_df, x = 'PC1', y='PC2', hue='Cluster')
plt.title('The Plot Of The Clusters(2D)')
plt.show()
👋🏻