
프로그래머스 SQL 고득점 Kit GROUP BY
신기하게도 Level 1 문제는 없었다.. ㅋㅋ
그만큼 GROUP BY 문제는 어렵다는 의미겠지..
1. 자동차 종류 별 특정 옵션이 포함된 자동차 수 구하기 Level 2

1. 자동차 종류별로 그룹화하기
SELECT
CAR_TYPE,
COUNT(CAR_ID)
FROM CAR_RENTAL_COMPANY_CAR
GROUP BY CAR_TYPE;2. 그룹 내에서 조건에 맞게 필터링해서 카운트하기

이 조건대로 해야하는데,
(정답 아님)
혹시나 될까 싶어서
SELECT
CAR_TYPE,
COUNT(CAR_ID) AS CARS
FROM CAR_RENTAL_COMPANY_CAR
WHERE OPTIONS
LIKE '%통풍시트%'
OR '%열선시트%'
OR '%가죽시트%'
GROUP BY CAR_TYPE;웬 걸 정답이 잘 나오는 거 같았다 ㅋㅋㅋ
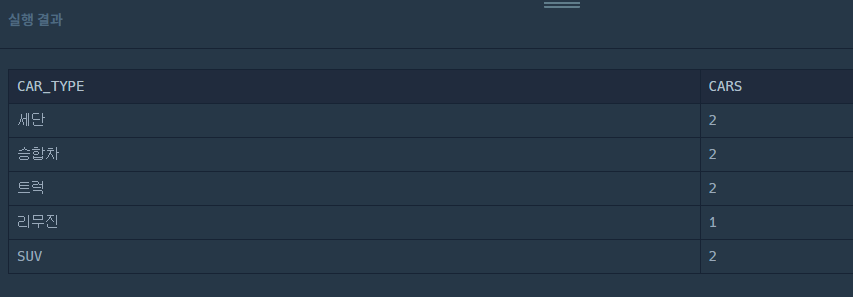
근데 어림도 없지.. 귀찮다고 저렇게 하면 안 되고 각각 비교 대상 컬럼명과 LIKE를 다 붙여줘야 한다...!
그리고 당연히 정렬 조건까지 달아주면 그게 정답이다..!
정답
SELECT
CAR_TYPE,
COUNT(CAR_ID) AS CARS
FROM CAR_RENTAL_COMPANY_CAR
WHERE OPTIONS LIKE '%통풍시트%'
OR OPTIONS LIKE '%열선시트%'
OR OPTIONS LIKE '%가죽시트%'
GROUP BY CAR_TYPE
ORDER BY CAR_TYPE;2. 성분으로 구분한 아이스크림 총 주문량 Level 2

이 문제는 그냥 정석적인 GROUP BY 문제다!
캬 이게 GROUP BY지!
이전 문제는 솔직히 좀 까다로웠다..
먼저 ICECREAM_INFO 테이블을 조회해보자.
SELECT *
FROM ICECREAM_INFO;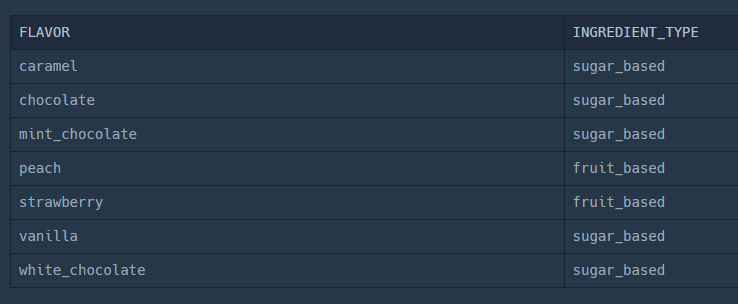
이렇게 나온다.
성분 타입은 두 가지밖에 없다.
SELECT *
FROM ICECREAM_INFO
GROUP BY INGREDIENT_TYPE;즉, 성분 타입으로 그룹화를 해서 보면 이렇게 두 개가 끝이다.

물론 앞에 FLAVOR은 원래 여러 개지만, 제일 위에 있는 값이 대표값으로 하나 나온 것이다.
그리고 이 FLAVOR는 FIRST_HALF 테이블의 기본키를 참조한 것이다.
그래서 외래키인 FLAVOR로 JOIN을 해서 한테이블처럼 연결하고, 문제에서 시킨대로, INGREDIENT_TYPE로 그룹화를 해주면 된다.
1. JOIN으로 테이블 연결하기
SELECT
*
FROM
FIRST_HALF F
JOIN ICECREAM_INFO I ON F.FLAVOR = I.FLAVOR;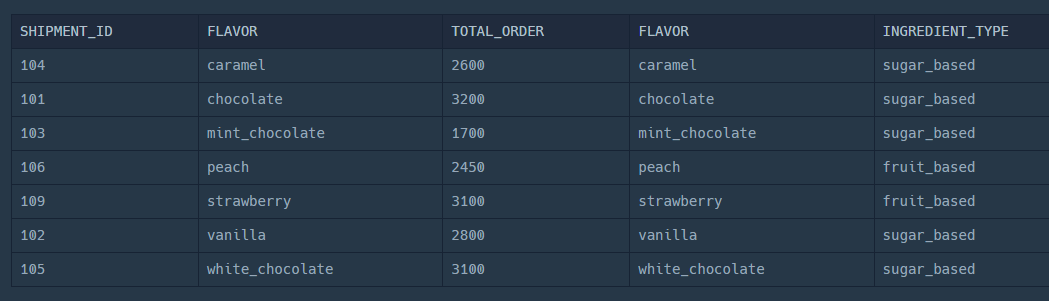
2. INGREDIENT_TYPE로 그룹화하고, 정렬하기
SELECT
I.INGREDIENT_TYPE,
SUM(F.TOTAL_ORDER) AS TOTAL_ORDER
FROM FIRST_HALF F
JOIN ICECREAM_INFO I ON F.FLAVOR = I.FLAVOR
GROUP BY
I.INGREDIENT_TYPE
ORDER BY
F.TOTAL_ORDER;3. 진료과별 총 예약 횟수 출력하기 Level 2

음..
그냥 시키는 대로 작성하면 정답이다..
이게 왜 Level 2?
정답
SELECT
MCDP_CD AS 진료과코드,
COUNT(*) AS 5월예약건수
FROM
APPOINTMENT
WHERE
YEAR (APNT_YMD) = 2022
AND MONTH (APNT_YMD) = 5
GROUP BY
MCDP_CD
ORDER BY
5월예약건수,
진료과코드;4. 고양이와 개는 몇 마리 있을까 Level 2

이 문제도 그냥 시키는 대로 하면 정답이다 ㅋㅋㅋ..
정답
SELECT
ANIMAL_TYPE,
COUNT(ANIMAL_ID) AS count
FROM
ANIMAL_INS
GROUP BY
ANIMAL_TYPE
ORDER BY
ANIMAL_TYPE;다만 문제에서 고양이를 먼저 조회하라고 했는데, C가 알파벳 순서상 앞이라서 오름차순 정렬하면 된다.
하지만, 명시적으로 하려면 CASE WHEN ~ THEN END 를 사용해도 된다.
SELECT
ANIMAL_TYPE,
COUNT(ANIMAL_ID) AS count
FROM
ANIMAL_INS
GROUP BY
ANIMAL_TYPE
ORDER BY
CASE
WHEN ANIMAL_TYPE = 'Cat' THEN 1
ELSE 2
END;이렇게 하면 Cat이 제일 앞에 오고, 나머지는 모두 우선순위가 2가 돼서 오름차순 정렬된다!
5. 동명 동물 수 찾기 Level 2

전형적인 GROUP BY 문제다.
다만, GROUP BY 한 결과에 대해서 조건을 적을 때는 WHERE 절이 아니라 HAVING 절을 사용해야 한다는 것만 주의하면 된다!
정답
SELECT NAME,
COUNT(NAME) AS COUNT
FROM ANIMAL_INS
WHERE NAME IS NOT NULL
GROUP BY NAME
HAVING COUNT >= 2
ORDER BY NAME;6. 입양 시각 구하기(1) Level 2

시간대별로 그룹화를 하는 게 해본 적이 있었는지 기억이 안 났다..
그래도 우선은 해보는 걸루..!
머GROUP BY HOUR(DATETIME) 하면 되니께..
해보니까 잘 됐다!
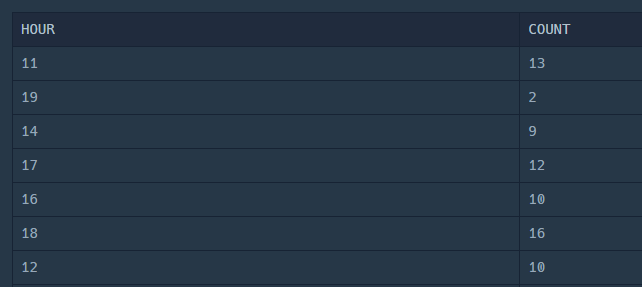
이제 조건만 달아주면 된다.
5번 문제는 그룹화 한 결과에 대한 조건이었으니 HAVING 절이고,
이 문제는 그룹화 하기 전 원본 테이블에 대한 조건이니 WHERE 절이 맞다!
그리고 정렬 조건도 달아주면 정답이다!
정답
SELECT HOUR(DATETIME) AS HOUR,
COUNT(HOUR(DATETIME)) AS COUNT
FROM ANIMAL_OUTS
WHERE HOUR(DATETIME) BETWEEN 9 AND 19
GROUP BY HOUR(DATETIME)
ORDER BY HOUR;7. 가격대 별 상품 개수 구하기 Level 2

10,000원 단위로 그룹화
GROUP BY 부분에 PRICE / 10000을 적었더니 오류가 났다..
그래서 SELECT 문에 적었다.
SELECT PRICE / 10000 AS PRICE_GROUP,
COUNT(*)
FROM PRODUCT
GROUP BY PRICE_GROUP;잘 된다!
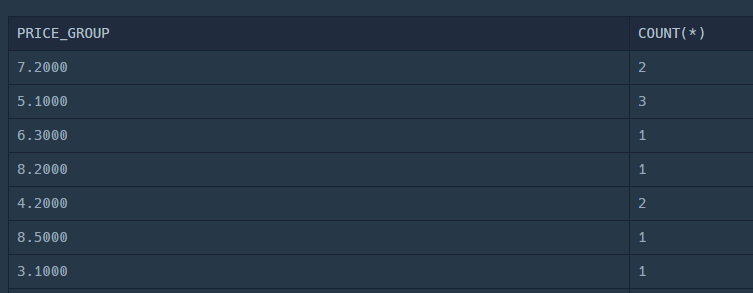
10,000원 단위로 나눠야 하니, FLOOR 함수를 사용해서 버림을 하고, 다시 10000을 곱하면 될 거 같다.
그리고 COUNT 이름 고쳐주고, ORDER BY만 마저 적으면 정답일 듯!
정답
SELECT FLOOR(PRICE / 10000) * 10000 AS PRICE_GROUP,
COUNT(*) AS PRODUCTS
FROM PRODUCT
GROUP BY PRICE_GROUP
ORDER BY PRICE_GROUP;8. 조건에 맞는 사원 정보 조회하기 Level 2

1. 직원들의 2022년 상, 하반기 점수 합치기
SELECT
EMP_NO,
SUM(SCORE) AS SCORE
FROM HR_GRADE
WHERE YEAR = 2022
GROUP BY EMP_NO;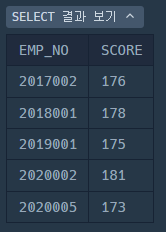
2. 최고 점수를 받은 사원 찾기
전에 많이 해봤던 WITH ~ ()로 정의해서 아래에서 테이블처럼 불러서 사용하면 된다.
WITH EMP_SCORES AS (
SELECT
EMP_NO,
SUM(SCORE) AS SCORE
FROM HR_GRADE
WHERE YEAR = 2022
GROUP BY EMP_NO
)
SELECT EMP_NO, SCORE
FROM EMP_SCORES
WHERE SCORE = (SELECT MAX(SCORE) FROM EMP_SCORES);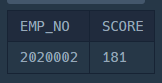
3. HR_EMPLOYEES 테이블과 JOIN하여 상세 정보 가져오기
WITH EMP_SCORES AS (
SELECT EMP_NO,
SUM(SCORE) AS SCORE
FROM HR_GRADE
WHERE YEAR = 2022
GROUP BY EMP_NO
)
SELECT ES.SCORE,
HE.EMP_NO,
HE.EMP_NAME,
HE.POSITION,
HE.EMAIL
FROM EMP_SCORES ES
JOIN HR_EMPLOYEES HE ON ES.EMP_NO = HE.EMP_NO
WHERE ES.SCORE = (
SELECT MAX(SCORE)
FROM EMP_SCORES
);9. 노선별 평균 역 사이 거리 조회하기 Level 2

1. GROUP BY
ROUTE를 기준으로 그륩화한다.
그룹화를 할 때, SELECT에 사용하는 필드들이 GROUP BY 절에 사용된 필드가 아니라면,
집계함수로 감싸야한다.
여기서는 총 누계 거리와 평균 거리를 표시하라고 했으니, 바로 SUM과 AVG를 사용해서 감싸면 된다!
SELECT ROUTE,
SUM(D_BETWEEN_DIST AS TOTAL_DISTANCE,
AVG(D_BETWEEN_DIST AS AVERAGE_DISTANCE
FROM SUBWAY_DISTANCE
GROUP BY ROUTE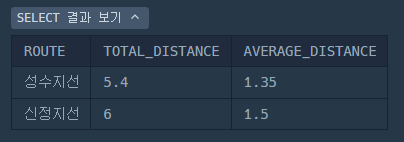
2. ROUND && CONCAT
SELECT ROUTE,
CONCAT(ROUND(SUM(D_BETWEEN_DIST), 1), 'km') AS TOTAL_DISTANCE,
CONCAT(ROUND(AVG(D_BETWEEN_DIST), 2), 'km') AS AVERAGE_DISTANCE
FROM SUBWAY_DISTANCE
GROUP BY ROUTE;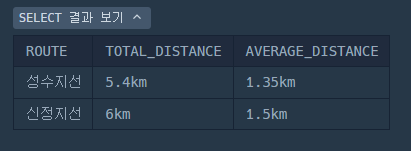
3. ORDER BY
주의할 점이 있다.
CONCAT을 통해서 'km'로 결합하기 위해서 문자열로 변환된 것이기 때문에 올바른 정렬이 되지 않는다. 즉, 숫자 크기의 정렬이 아니라 문자열의 사전순 정렬이 된다.
따라서 ORDER BY 조건을 새로 정의해야 한다!
SELECT ROUTE,
CONCAT(ROUND(SUM(D_BETWEEN_DIST), 1), 'km') AS TOTAL_DISTANCE,
CONCAT(ROUND(AVG(D_BETWEEN_DIST), 2), 'km') AS AVERAGE_DISTANCE
FROM SUBWAY_DISTANCE
GROUP BY ROUTE
ORDER BY SUM(D_BETWEEN_DIST) DESC;이렇게 말이다
10. 물고기 종류 별 잡은 수 구하기 Level 2

1. INNER JOIN
공통 컬럼인 FISH_TYPE으로 두 테이블을 연결한다.
SELECT *
FROM FISH_INFO FI
JOIN FISH_NAME_INFO FN ON FI.FISH_TYPE = FN.FISH_TYPE;2. GROUP BY
FISH_NAME컬럼으로 그룹화하고, 표시할 컬럼을 SELECT 문에 적는다.
추가로 ORDER BY조건도 같이 적어준다.
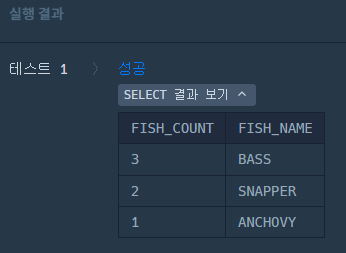
SELECT COUNT(*) AS FISH_COUNT,
FN.FISH_NAME
FROM FISH_INFO FI
JOIN FISH_NAME_INFO FN ON FI.FISH_TYPE = FN.FISH_TYPE
GROUP BY FN.FISH_NAME
ORDER BY FISH_COUNT DESC;++ COUNT(LENGTH)를 하면, 결과값이 다르게 나와서 정답이 아니다
COUNT(*)을 한 결과는 이렇다.
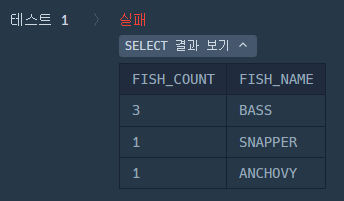
문제에서 10cm이하의 물고기는 NULL로 표시했다고 했다.
그러나 COUNT(*)를 할 때는 집계된다.
하지만 COUNT(LENGTH)를 하면 NULL값은 제외된다.
실제로 결과가 다른 것을 알 수 있다!
11. 월별 잡은 물고기 수 구하기 Level 2

1. GROUP BY
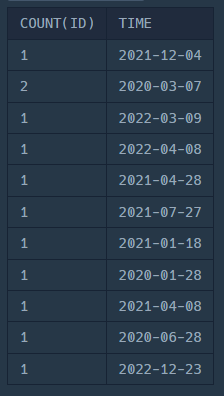
SELECT
COUNT(ID),
TIME
FROM
FISH_INFO
GROUP
BY TIMETIME 컬럼이 날짜 정보를 갖고 있으므로,
TIME 컬럼을 기준으로 GROUP BY를 해보면 이런 결과가 나온다.
월 단위로 그룹화가 필요하므로
MONTH(TIME)을 기준으로 GROUP BY를 해보면 될 것 같다.
SELECT
COUNT(ID),
MONTH(TIME)
FROM
FISH_INFO
GROUP BY
MONTH(TIME);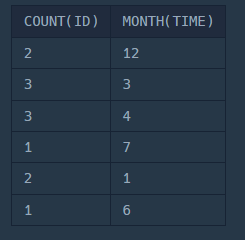
2. 컬럼명 수정, ORDER BY
SELECT
COUNT(ID) AS FISH_COUNT,
MONTH (TIME) AS MONTH
FROM
FISH_INFO
GROUP BY
MONTH (TIME)
ORDER BY
MONTH;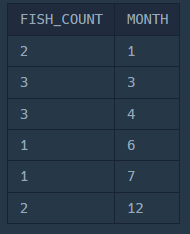
12. 대여 횟수가 많은 자동차들의 월별 대여 횟수 구하기 Level 3
1. WHERE 절로 필터링
대여 시작일을 기준으로 2022년 8월부터 2022년 10월까지
그룹화를 하기 전에 해당 조건의 데이터만 필터링해야 하므로 WHERE 절을 사용해야 한다.
SELECT
*
FROM
CAR_RENTAL_COMPANY_RENTAL_HISTORY
WHERE
YEAR(START_DATE) = 2022
AND MONTH(START_DATE) BETWEEN 8 AND 10;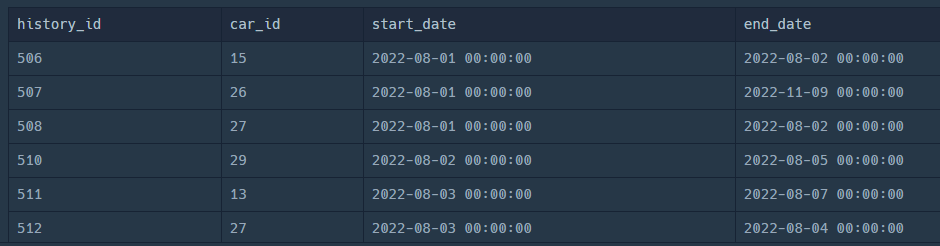
2. CAR_ID를 기준으로 그룹화후 필터링
총 대여 횟수가 5회 이상인 자동차
총 대여 횟수를 구하려면 그룹화를 해야 한다.
그런 다음에 조건을 걸어야 하므로 HAVING절도 사용해야한다.
총 대여 횟수를 월별 자동차 ID 별 총 대여 횟수이므로 CAR_ID컬럼을 기준으로 그룹화하면 된다.
SELECT
CAR_ID,
COUNT(CAR_ID) AS RECORDS
FROM
CAR_RENTAL_COMPANY_RENTAL_HISTORY
WHERE
YEAR(START_DATE) = 2022
AND MONTH(START_DATE) BETWEEN 8 AND 10
GROUP BY
CAR_ID
HAVING
RECORDS >= 5;여기까지 구한 결과는
대여 시작일을 기준으로 2022년 8월부터 2022년 10월까지 총 대여 횟수가 5회 이상인 자동차들이다.
문제에서는 해당 기간 동안의 월별 자동차 ID 별 총 대여 횟수(컬럼명: RECORDS) 리스트를 출력하라고 했다.
즉, 월별, 자동차 ID별 총 대여 횟수를 구해야 한다.
그래서 위에서 구한 데이터를 서브쿼리로 이용해서
월별로 그룹화를 한 번 더 수행해야 한다.
물론 그러려면 서브쿼리가 현재
WHERE절의 IN 에서 사용할 것이기 때문에
RECORDS컬럼 대신 CAR_ID 컬럼만 반환해야 한다.
또한WHERE CAR_ID IN 서브쿼리형태로 사용할 것이기 때문에
날짜에 대한 조건을 다시 한 번 사용해서 필터링해야 한다.
3. 월별로 그룹화
그래서 이렇게 된다.
그룹화를 두 컬럼에 대해서 하는 방법은
GROUP BY 컬럼1, 컬럼2 적어주면 된다.
순서는 상관없다.
SELECT
MONTH(START_DATE) AS MONTH,
CAR_ID,
COUNT(CAR_ID) AS RECORDS
FROM
CAR_RENTAL_COMPANY_RENTAL_HISTORY
WHERE
YEAR(START_DATE) = 2022
AND MONTH(START_DATE) BETWEEN 8 AND 10
AND CAR_ID IN (
SELECT
CAR_ID
FROM
CAR_RENTAL_COMPANY_RENTAL_HISTORY
WHERE
YEAR (START_DATE) = 2022
AND MONTH (START_DATE) BETWEEN 8 AND 10
GROUP BY
CAR_ID
HAVING
COUNT(CAR_ID) >= 5
)
GROUP BY
CAR_ID,
MONTH이제 ORDER BY 절만 작성해주면 정답이 된다.
SELECT
MONTH(START_DATE) AS MONTH,
CAR_ID,
COUNT(CAR_ID) AS RECORDS
FROM
CAR_RENTAL_COMPANY_RENTAL_HISTORY
WHERE
YEAR(START_DATE) = 2022
AND MONTH(START_DATE) BETWEEN 8 AND 10
AND CAR_ID IN (
SELECT
CAR_ID
FROM
CAR_RENTAL_COMPANY_RENTAL_HISTORY
WHERE
YEAR (START_DATE) = 2022
AND MONTH (START_DATE) BETWEEN 8 AND 10
GROUP BY
CAR_ID
HAVING
COUNT(CAR_ID) >= 5
)
GROUP BY
CAR_ID,
MONTH
ORDER BY
MONTH,
CAR_ID DESC;13. 자동차 대여 기록에서 대여중 / 대여 가능 여부 구분하기 Level 3
서브쿼리
SELECT
CAR_ID,
START_DATE,
END_DATE
FROM
CAR_RENTAL_COMPANY_RENTAL_HISTORY
WHERE
START_DATE <= '2022-10-16' AND END_DATE >= '2022-10-16';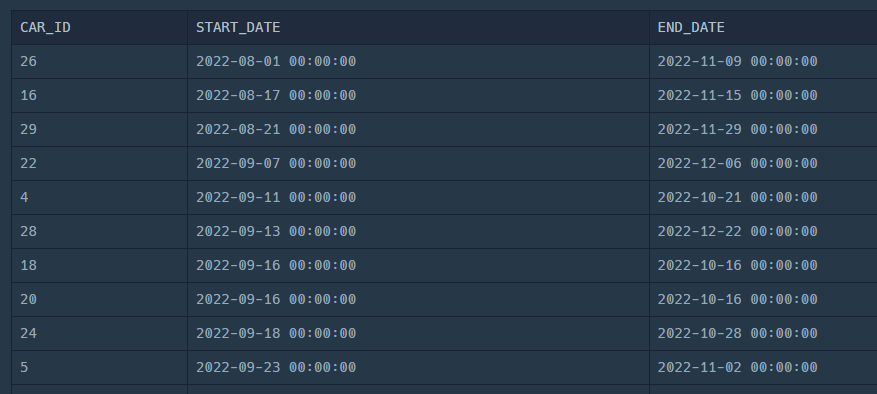
22년 10월 16일에 대여중인 차의 CAR_ID를 조회해보자!
이것을 서브쿼리로 사용할 것이다.
서브쿼리로 반환된 CAR_ID로 필터링
CASE
WHEN 조건 THEN
ELSE
END위 구문을 사용해서 대여중, 대여 가능을 다르게 표시해주면 된다.
여기서 10분 넘게 헤맸는데,,,,
대여 가능을 띄어쓰기 없이대여가능으로 적어서 계속 틀리고 있었다....💦
SELECT
CAR_ID,
CASE
WHEN CAR_ID IN (
SELECT
CAR_ID
FROM
CAR_RENTAL_COMPANY_RENTAL_HISTORY
WHERE
START_DATE <= '2022-10-16'
AND END_DATE >= '2022-10-16'
) THEN '대여중'
ELSE '대여 가능'
END AS AVAILABILITY
FROM
CAR_RENTAL_COMPANY_RENTAL_HISTORY
GROUP BY
CAR_ID
ORDER BY
CAR_ID DESC;성능상 더 좋은 단일 쿼리
위에 코드는 서브 쿼리를 사용한 것이기 때문에 간단하고 쉽지만,
테이블을 두 번 조회해야하기 때문에 성능상 좋다고는 할 수 없다.
조금 복잡하지만 단일 쿼리를 사용하는 효율적인 방법도 익혀보자!
CASE WHEN 조건 THEN ELSE END 구문을 두 번 사용할 것이다.
조건에 맞는 행에 플래그 부여하기(CASE절)
CASE
WHEN '2022-10-16' BETWEEN START_DATE AND END_DATE THEN 1
ELSE 0
END첫 번째 CASE절로 해당 날짜의 데이터들에 1을 부여하고, 그렇지 않으면 0을 반환한다.
집계함수 SUM()으로 감싸서 플래그 합산
SUM(
CASE
WHEN '2022-10-16' BETWEEN START_DATE AND END_DATE THEN 1
ELSE 0
END
)SUM()으로 감싸주었고, CAR_ID를 기준으로 그룹화를 한 것이기 때문에
각 CAR_ID별로 해당 날짜에 대여된 것들에 대해서 플래그를 합산한다.
다시 CASE절로 상태 표시하기
CASE
WHEN SUM(...) > 0 THEN '대여중'
ELSE '대여 가능'
END현재 위와 같은 구조이다.
따라서 플래그들을 합산한 결과가 0이상이면,
해당 날짜에 차가 대여중이라는 의미이고,
그에 따라 대여중이라고 표시한다.
그렇지 않은 경우에는 대여 가능이라고 표시하게 된다.
최종 코드
부차적인 것들을 마저 완성해주면 최종 코드는 이렇게 된다.
SELECT
CAR_ID,
CASE
WHEN SUM(
CASE
WHEN '2022-10-16' BETWEEN START_DATE AND END_DATE THEN 1
ELSE 0
END ) > 0 THEN '대여중'
ELSE '대여 가능'
END AS AVAILABILITY
FROM
CAR_RENTAL_COMPANY_RENTAL_HISTORY
GROUP BY
CAR_ID
ORDER BY
CAR_ID DESC;14. 즐겨찾기가 가장 많은 식당 정보 출력하기 Level 3

이 문제눈 단일 쿼리만으로는 불가능하고 두 번의 서브쿼리를 사용해야한다.
- 음식 종류별 최댓값 구하기
- 최댓값에 해당하는 음식점 정보 출력
음식 종류별 최댓값 구하기
먼저음식종류별로 즐겨찾기수가 가장 많은 식당을 필터링 해야 한다.
SELECT
FOOD_TYPE,
MAX(FAVORITES) AS MAX_FAV
FROM
REST_INFO
GROUP BY
FOOD_TYPE;이렇게 작성하면, 음식 종류별로 가장 많은 FAVORITES가 나온다.

원본 테이블과 JOIN
위에서 만든 쿼리를 서브 쿼리로 사용하여
원본 테이블과 JOIN한다.
이때 이전에 구한 식당 종류별 최대 FAVORITES인 MAX_FAV와
원본 테이블의 FAVORITES를 연결한다.
또한 다른 FOOD_TYPE에도,
FAVORITES가 똑같이 존재할 수도 있으므로
AND로 FOOD_TYPE도 같이 ON절에 연결해서 적어줘야 한다.
SELECT
R.FOOD_TYPE,
R.REST_ID,
R.REST_NAME,
R.FAVORITES
FROM
REST_INFO R
JOIN (
SELECT
FOOD_TYPE,
MAX(FAVORITES) AS MAX_FAV
FROM
REST_INFO
GROUP BY
FOOD_TYPE
) S
ON R.FOOD_TYPE = S.FOOD_TYPE AND R.FAVORITES = S.MAX_FAV
ORDER BY
R.FOOD_TYPE DESC;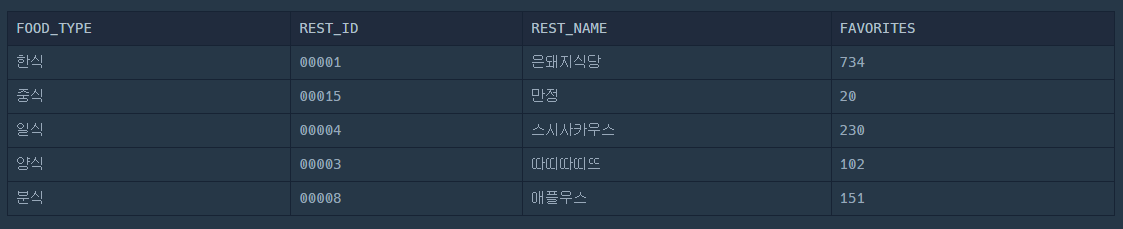
15. 조건에 맞는 사용자와 총 거래금액 조회하기 Level 3
SELECT
U.USER_ID,
U.NICKNAME,
SUM(PRICE) AS TOTAL_SALES
FROM
USED_GOODS_BOARD B
JOIN USED_GOODS_USER U ON B.WRITER_ID = U.USER_ID
WHERE
B.STATUS = 'DONE'
GROUP BY
U.USER_ID
HAVING
TOTAL_SALES >= 700000
ORDER BY
TOTAL_SALES;16. 부서별 평균 연봉 조회하기 Level 3

1. 두 테이블 JOIN
SELECT
*
FROM
HR_DEPARTMENT D
JOIN HR_EMPLOYEES E ON D.DEPT_ID = E.DEPT_ID;우선은 두 테이블을 JOIN해보자
그러면 이렇게 결과가 잘 나온다
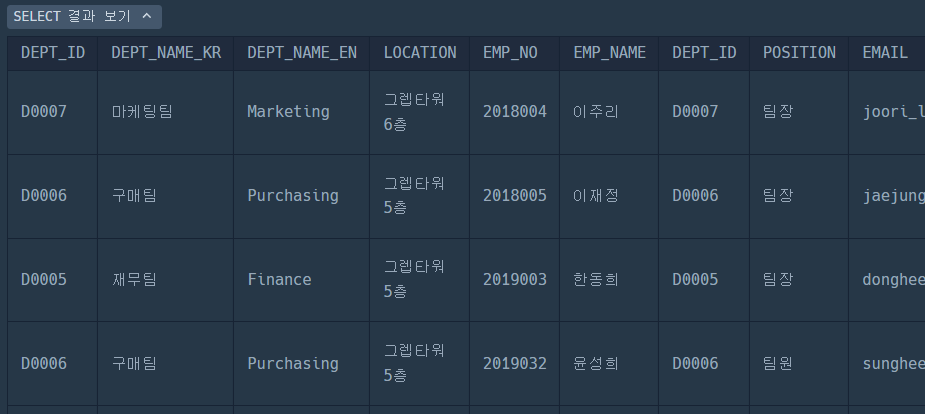
2. DEPT_ID 로 그룹화하기
SELECT
D.DEPT_ID,
ROUND(AVG(SAL)) AS AVG_SAL
FROM
HR_DEPARTMENT D
JOIN HR_EMPLOYEES E ON D.DEPT_ID = E.DEPT_ID
GROUP BY
DEPT_ID;DEPT_ID를 기준으로 그룹화하고,
그 안에서 SAL컬럼을 집계하여 출력하면 된다
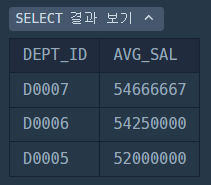
여기에 추가로 출력할 컬럼 D.DEPT_NAME_EN와
ORDER BY절을 추가해주면 끝이다!
SELECT
D.DEPT_ID,
D.DEPT_NAME_EN,
ROUND(AVG(SAL)) AS AVG_SAL
FROM
HR_DEPARTMENT D
JOIN HR_EMPLOYEES E ON D.DEPT_ID = E.DEPT_ID
GROUP BY
DEPT_ID
ORDER BY
AVG_SAL DESC;17. 특정 조건을 만족하는 물고기별 수와 최대 길이 구하기 Level 3

1. 평균 길이가 33cm 이상인 물고기 타입을 반환하는 서브쿼리
CASE WHEN THEN ELSE END와 GROUP BY를 잘 사용하면 간단하게 작성할 수 있다.
SELECT
FISH_TYPE
FROM
FISH_INFO
GROUP BY
FISH_TYPE
HAVING
AVG(
CASE
WHEN LENGTH IS NULL THEN 10
ELSE LENGTH
END
) >= 33이렇게 작성하면 평균 길이가 33cm 이상인 물고기 타입들을 반환한다!
이것을 서브쿼리로 사용해서 요구하는 정보들을 출력하면 된다!
2. 서브뤄리를 사용해서 문제의 요구대로 출력하기
- 서브 쿼리를
WHERE절에 사용해서FISH_TYPE으로 필터링을 하고 - 그룹화 및 요구하는 컬럼과 정렬 조건을 마저 적어주면
완성이다!
SELECT
COUNT(ID) AS FISH_COUNT,
MAX(LENGTH) AS MAX_LENGTH,
FISH_TYPE
FROM
FISH_INFO
WHERE
FISH_TYPE IN (
SELECT
FISH_TYPE
FROM
FISH_INFO
GROUP BY
FISH_TYPE
HAVING
AVG(
CASE
WHEN LENGTH IS NULL THEN 10
ELSE LENGTH
END
) >= 33
)
GROUP BY
FISH_TYPE
HAVING
MAX_LENGTH >= 33
ORDER BY
FISH_TYPE;그러나~..
제출해보니 정답이긴 했지만, 시간이 꽤 오래 걸려서
매우 비효율적으로 작성했다는 걸 알게 됐다.
효율적으로 다시 짜보자..
서브쿼리를 사용하지 않는 방법이 존재할 거 같다..😓
평균 길이 계산 타이밍
나는 평균 길이를 계산하는 타이밍 때문에 고민하다가,
서브쿼리를 사용하기로 했다.
이게 그룹화를 하기는 해야 하는데,
LENGTH가 NULL인 것도 처리를 해주어야 하니까
그 부분을 어떻게 적어야할지가 고민이었다.
결론은 그룹화한 결과에 대해서 평균을 구하는 것이니까
WHERE절에는 적을 수 없기에 HAVING절에 적었는데
사실 저럴 거면 애초부터 서브쿼리를 사용할 필요가 없었다.
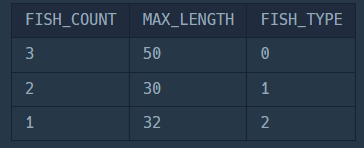
1. 그룹화 먼저 하기
SELECT
COUNT(ID) AS FISH_COUNT,
MAX(LENGTH) AS MAX_LENGTH,
FISH_TYPE
FROM
FISH_INFO
GROUP BY
FISH_TYPE;그룹화와 출력할 컬럼을 먼저 적어보자.
그러면 이런 결과가 나온다.
2. HAVING 절로 평균 33cm 이상인 결과만 출력하기
그런 다음에 HAVING절에 기존에 적었던 조건을 그대로 다시 써주면 끝이다..!
이러면 정답이다😊
SELECT
COUNT(ID) AS FISH_COUNT,
MAX(LENGTH) AS MAX_LENGTH,
FISH_TYPE
FROM
FISH_INFO
GROUP BY
FISH_TYPE
HAVING
AVG(
CASE
WHEN LENGTH IS NULL THEN 10
ELSE LENGTH
END
) >= 33
ORDER BY
FISH_TYPE;